Latent semantic analysis: implementation
- Tutorial
As mentioned in the previous article , latent-semantic analysis (LSA / LSA) allows you to identify latent relationships of the studied phenomena or objects, which is an important criterion for modeling the processes of understanding and thinking.
Now I will write a little about the implementation of LSA.
LSA was patented in 1988 by a group of American research engineers S. Deerwester at al [US Patent 4,839,853].
In the field of information retrieval, this approach is called latent-semantic indexing (LSI).
For the first time, LSA was used for automatic indexing of texts, revealing the semantic structure of text and obtaining pseudo-documents. Then this method was quite successfully used to represent knowledge bases and build cognitive models. In the USA, this method was patented to test the knowledge of schoolchildren and students, as well as to check the quality of teaching methods.
As initial information, LSA uses a term-on-documents matrix (terms — words, phrases or n-grams; documents — texts classified either according to some criterion or separated arbitrarily — this depends on the problem being solved) that describes the data set used to train the system. The elements of this matrix contain, as a rule, weights taking into account the frequency of use of each term in each document or probabilistic measures (PLSA - probabilistic latent-semantic analysis) based on an independent multimodal distribution.
The most common version of LSA is based on the use of decomposition of a real-valued matrix into singular values or SVD decomposition (SVD - Singular Value Decomposition). Using it, any matrix can be expanded into many orthogonal matrices, the linear combination of which is a fairly accurate approximation to the original matrix.
According to the singular decomposition theorem, in the simplest case, the matrix can be decomposed into the product of three matrices:

where the matrices U and V are orthogonal, and S is the diagonal matrix, the values on the diagonal of which are called the singular values of the matrix A.
The symbol T in the matrix designation means transposition of the matrix .
means transposition of the matrix .
The peculiarity of this expansion is that if only k of the largest singular values are left in the matrix S, then a linear combination of the resulting matrices will be the best approximation of the original matrix A to the Ă matrix of rank k:
will be the best approximation of the original matrix A to the Ă matrix of rank k:
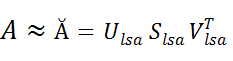
The main idea of the latent-semantic analysis is as follows:
after the matrices are multiplied, the resulting matrix Ă, containing only k first linearly independent components of the original matrix A, reflects the structure of dependencies (in this case, associative) latently present in the original matrix. The structure of dependencies is determined by the weight functions of the terms for each document.
The choice of k depends on the task and is selected empirically. It depends on the number of source documents.
If there are not many documents, for example, a hundred, then k can be taken 5-10% of the total number of diagonal values; if there are hundreds of thousands of documents, then they take 0.1-2%. It should be remembered that if the selected value of k is too large, then the method loses its power and approaches the standard vector methods in terms of characteristics. A too small value of k does not allow to catch the differences between similar terms or documents: there will be only one main component that will “drag the blanket over itself”, i.e. all weak and even unrelated terms.

Figure 1. SVD decomposition of dimension matrix A (TXD) into a term matrix U of dimension (TX k), a document matrix of dimension V (k XD), and dimension diagonal matrix S (k X k), where k is the number of singular values of the diagonal matrix S .
The volume of the case for building the model should be large - preferably about three to five million word usage. But the method also works on smaller collections, although it is somewhat worse.
An arbitrary breakdown of the text into documents usually produces from a thousand to several tens of thousands of parts of approximately the same volume. Thus, the term-on-document matrix is rectangular and can be very pronounced. For example, with a volume of 5 million word forms, a matrix of 30-50 thousand documents for 200-300 thousand, and sometimes more, terms is obtained. In fact, low-frequency terms can be omitted because this will significantly reduce the dimension of the matrix (say, if you do not use 5% of the total volume of low-frequency terms, then the dimension will be reduced by half), which will lead to a reduction in computing resources and time.
The choice of reducing the singular values of the diagonal matrix (dimension k) for the inverse multiplication of matrices, as I wrote, is arbitrary. With the above dimension of the matrix, several hundred (100-300) major components are left. In this case, as practice shows, the dependence of the number of components and the accuracy change nonlinearly: for example, if you start to increase their number, then the accuracy will fall, but at a certain value, say, 10,000, it will again increase to the optimal case.
The following is an example of the occurrence and change of the main factors while reducing the number of singular elements of the diagonal matrix.
Accuracy can be evaluated on marked-up material, for example, by adjusting the result in advance by matching the answers to the questions.
For more information on this method, see, for example, review articles [see list of references].
Those who want to try the LSA can download the binaries for building models and for testing and using them.
The program for SVD decomposition of the matrix when building models used open source (Copyright Sergey Bochkanov (ALGLIB project).), So the programs are distributed without restrictions.
Also, sometimes this method is used to find the “nearest neighbor” - the terms closest in weight, associated with the original one. This property is used to search for terms that are close in meaning.
It should be clarified that closeness in meaning is a context-dependent quantity, therefore not every close term will correspond to an association (it can be a synonym, antonym, or just a word or phrase often found together with the sought term).
The advantage of the method can be considered its remarkable ability to identify dependencies between words, when conventional statistical methods are powerless. LSA can also be applied both with training (with preliminary thematic classification of documents) and without training (arbitrary splitting of arbitrary text), which depends on the problem being solved.
I wrote about the main shortcomings in a previous article. A significant decrease in the computation speed can be added to them with an increase in the amount of input data (in particular, with SVD conversion).
As shown in [Deerwester et al.], The calculation speed corresponds to the order , where
, where  is the sum of the number of documents and terms, k is the dimension of the factor space.
is the sum of the number of documents and terms, k is the dimension of the factor space.

The figures show the occurrence and change of the main factors while reducing the number of singular elements of the diagonal matrix from 100% to ~ 12%. Three-dimensional drawings are a symmetric matrix obtained by calculating the scalar product of the vectors of each reference document with each test person. The reference set of vectors is a text pre-marked for 30 documents; tested - with a decrease in the number of singular values of the diagonal matrix obtained by SVD analysis. On the X and Y axes, the number of documents (reference and tested) is plotted, on the Z axis is the volume of the lexicon.
The figures clearly show that with a decrease in the number of singular diagonal elements by 20-30%, factors are not yet clearly enough identified, but correlations of similar documents arise (small peaks outside the diagonal), which first increase slightly, and then, with a decrease in the number of singular values (up to 70-80%) - disappear. With automatic clustering, such peaks are noise, so it is advisable to minimize them. If the goal is to obtain associative relationships within documents, then you should find the optimal ratio of preservation of the main vocabulary and mixing of associative.
Now I will write a little about the implementation of LSA.
A bit of history
LSA was patented in 1988 by a group of American research engineers S. Deerwester at al [US Patent 4,839,853].
In the field of information retrieval, this approach is called latent-semantic indexing (LSI).
For the first time, LSA was used for automatic indexing of texts, revealing the semantic structure of text and obtaining pseudo-documents. Then this method was quite successfully used to represent knowledge bases and build cognitive models. In the USA, this method was patented to test the knowledge of schoolchildren and students, as well as to check the quality of teaching methods.
LSA job description
As initial information, LSA uses a term-on-documents matrix (terms — words, phrases or n-grams; documents — texts classified either according to some criterion or separated arbitrarily — this depends on the problem being solved) that describes the data set used to train the system. The elements of this matrix contain, as a rule, weights taking into account the frequency of use of each term in each document or probabilistic measures (PLSA - probabilistic latent-semantic analysis) based on an independent multimodal distribution.
The most common version of LSA is based on the use of decomposition of a real-valued matrix into singular values or SVD decomposition (SVD - Singular Value Decomposition). Using it, any matrix can be expanded into many orthogonal matrices, the linear combination of which is a fairly accurate approximation to the original matrix.
According to the singular decomposition theorem, in the simplest case, the matrix can be decomposed into the product of three matrices:
where the matrices U and V are orthogonal, and S is the diagonal matrix, the values on the diagonal of which are called the singular values of the matrix A.
The symbol T in the matrix designation
The peculiarity of this expansion is that if only k of the largest singular values are left in the matrix S, then a linear combination of the resulting matrices
will be the best approximation of the original matrix A to the Ă matrix of rank k: The main idea of the latent-semantic analysis is as follows:
after the matrices are multiplied, the resulting matrix Ă, containing only k first linearly independent components of the original matrix A, reflects the structure of dependencies (in this case, associative) latently present in the original matrix. The structure of dependencies is determined by the weight functions of the terms for each document.
The choice of k depends on the task and is selected empirically. It depends on the number of source documents.
If there are not many documents, for example, a hundred, then k can be taken 5-10% of the total number of diagonal values; if there are hundreds of thousands of documents, then they take 0.1-2%. It should be remembered that if the selected value of k is too large, then the method loses its power and approaches the standard vector methods in terms of characteristics. A too small value of k does not allow to catch the differences between similar terms or documents: there will be only one main component that will “drag the blanket over itself”, i.e. all weak and even unrelated terms.
Figure 1. SVD decomposition of dimension matrix A (TXD) into a term matrix U of dimension (TX k), a document matrix of dimension V (k XD), and dimension diagonal matrix S (k X k), where k is the number of singular values of the diagonal matrix S .
The volume of the case for building the model should be large - preferably about three to five million word usage. But the method also works on smaller collections, although it is somewhat worse.
An arbitrary breakdown of the text into documents usually produces from a thousand to several tens of thousands of parts of approximately the same volume. Thus, the term-on-document matrix is rectangular and can be very pronounced. For example, with a volume of 5 million word forms, a matrix of 30-50 thousand documents for 200-300 thousand, and sometimes more, terms is obtained. In fact, low-frequency terms can be omitted because this will significantly reduce the dimension of the matrix (say, if you do not use 5% of the total volume of low-frequency terms, then the dimension will be reduced by half), which will lead to a reduction in computing resources and time.
The choice of reducing the singular values of the diagonal matrix (dimension k) for the inverse multiplication of matrices, as I wrote, is arbitrary. With the above dimension of the matrix, several hundred (100-300) major components are left. In this case, as practice shows, the dependence of the number of components and the accuracy change nonlinearly: for example, if you start to increase their number, then the accuracy will fall, but at a certain value, say, 10,000, it will again increase to the optimal case.
The following is an example of the occurrence and change of the main factors while reducing the number of singular elements of the diagonal matrix.
Accuracy can be evaluated on marked-up material, for example, by adjusting the result in advance by matching the answers to the questions.
For more information on this method, see, for example, review articles [see list of references].
Those who want to try the LSA can download the binaries for building models and for testing and using them.
The program for SVD decomposition of the matrix when building models used open source (Copyright Sergey Bochkanov (ALGLIB project).), So the programs are distributed without restrictions.
Application
- comparison of two terms among themselves;
- comparison of two documents among themselves;
- comparison of term and document.
Also, sometimes this method is used to find the “nearest neighbor” - the terms closest in weight, associated with the original one. This property is used to search for terms that are close in meaning.
It should be clarified that closeness in meaning is a context-dependent quantity, therefore not every close term will correspond to an association (it can be a synonym, antonym, or just a word or phrase often found together with the sought term).
Advantages and disadvantages of LSA
The advantage of the method can be considered its remarkable ability to identify dependencies between words, when conventional statistical methods are powerless. LSA can also be applied both with training (with preliminary thematic classification of documents) and without training (arbitrary splitting of arbitrary text), which depends on the problem being solved.
I wrote about the main shortcomings in a previous article. A significant decrease in the computation speed can be added to them with an increase in the amount of input data (in particular, with SVD conversion).
As shown in [Deerwester et al.], The calculation speed corresponds to the order
, where is the sum of the number of documents and terms, k is the dimension of the factor space.A small demo example of calculating the proximity matrix of full-text documents with a different number of singular elements of the diagonal matrix in the SVD transform
The figures show the occurrence and change of the main factors while reducing the number of singular elements of the diagonal matrix from 100% to ~ 12%. Three-dimensional drawings are a symmetric matrix obtained by calculating the scalar product of the vectors of each reference document with each test person. The reference set of vectors is a text pre-marked for 30 documents; tested - with a decrease in the number of singular values of the diagonal matrix obtained by SVD analysis. On the X and Y axes, the number of documents (reference and tested) is plotted, on the Z axis is the volume of the lexicon.
The figures clearly show that with a decrease in the number of singular diagonal elements by 20-30%, factors are not yet clearly enough identified, but correlations of similar documents arise (small peaks outside the diagonal), which first increase slightly, and then, with a decrease in the number of singular values (up to 70-80%) - disappear. With automatic clustering, such peaks are noise, so it is advisable to minimize them. If the goal is to obtain associative relationships within documents, then you should find the optimal ratio of preservation of the main vocabulary and mixing of associative.
LITERATURE
- Thomas Landauer, Peter W. Foltz, & Darrell Laham (1998). “Introduction to Latent Semantic Analysis” (PDF). Discourse Processes 25: 259–284. US Patent 4,839,853
- Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, Richard Harshman (1990). Indexing by Latent Semantic Analysis (PDF). Journal of the American Society for Information Science 41 (6): 391–407.
- Thomas Landauer, Susan T. Dumais A Solution to Plato's Problem: The Latent Semantic Analysis Theory of Acquisition, Induction, and Representation of Knowledge 211–240 (1997). Retrieved July 2, 2007.
- B. Lemaire, G. Denhière Cognitive Models based on Latent Semantic Analysis (2003).
- Nekrestyanov I.S. Subject-oriented methods of information retrieval / Thesis for the degree of Ph.D. SPbSU, 2000.
- Soloviev A.N. Modeling of speech understanding processes using latent-semantic analysis / Thesis for the degree of Ph.D. SPbSU, 2008.
- Golub J., Van Lone C. Matrix calculations. M .: "World", 1999.
References
- webcom.upmf-grenoble.fr/LPNC/resources/benoit_lemaire/lsa.html - Readings in Latent Semantic Analysis for Cognitive Science and Education. - A collection of articles and links about LSA.
- lsa.colorado.edu is a site dedicated to modeling LSA.
- www.cs.utk.edu/%7Elsi - Latent Semantic Indexing.
- archive.today/1AnaN - Telcordia Latent Semantic Indexing (LSI). Demo Machine - A demo site for latent semantic indexing.
- cran.at.r-project.org/web/packages/lsa/index.html - Open Source LSA Package