Text editor - this is not your highest mathematics, then you have to think
Modern text editors are able not only to bibikat and not to give out of the program. It turns out that a very complex metabolism boils inside them. Want to find out what tricks are being taken to quickly recalculate the coordinates, how styles, foldings and softwraps are attached to the text and how it is all updated, what’s the functional data structures and priority queues, and how to cheat the user - welcome under the cat!

The article is based on Alexey Kudryavtsev's report with Joker 2017. Alexey has been writing Intellij IDEA in JetBrains for 10 years already. Under the cut you will find the video and text transcript of the report.
To understand how the editor works, let's write it.

Everything, our elementary editor is ready.
Inside the editor, the text is easiest to store in an array of characters, or, equivalently (in terms of memory organization), in the StringBuffer Java class. To get any character by offset, we call the StringBuffer.charAt (i) method. And to insert into it the character that we typed on the keyboard, call the StringBuffer.insert () method, which will insert the character somewhere in the middle.
What is most interesting, despite the simplicity and idiocy of this editor, is the best presentation that you can imagine. It is simple and almost always fast.
Unfortunately, there is a scale problem with this editor. Imagine that we typed a lot of text in it and are going to insert another letter in the middle. The following will occur. We urgently need to free up some space for this letter by moving all the other letters one character forward. To do this, we shift this letter by one position, then the next, and so on, until the very end of the text.
This is how it will look like in memory:
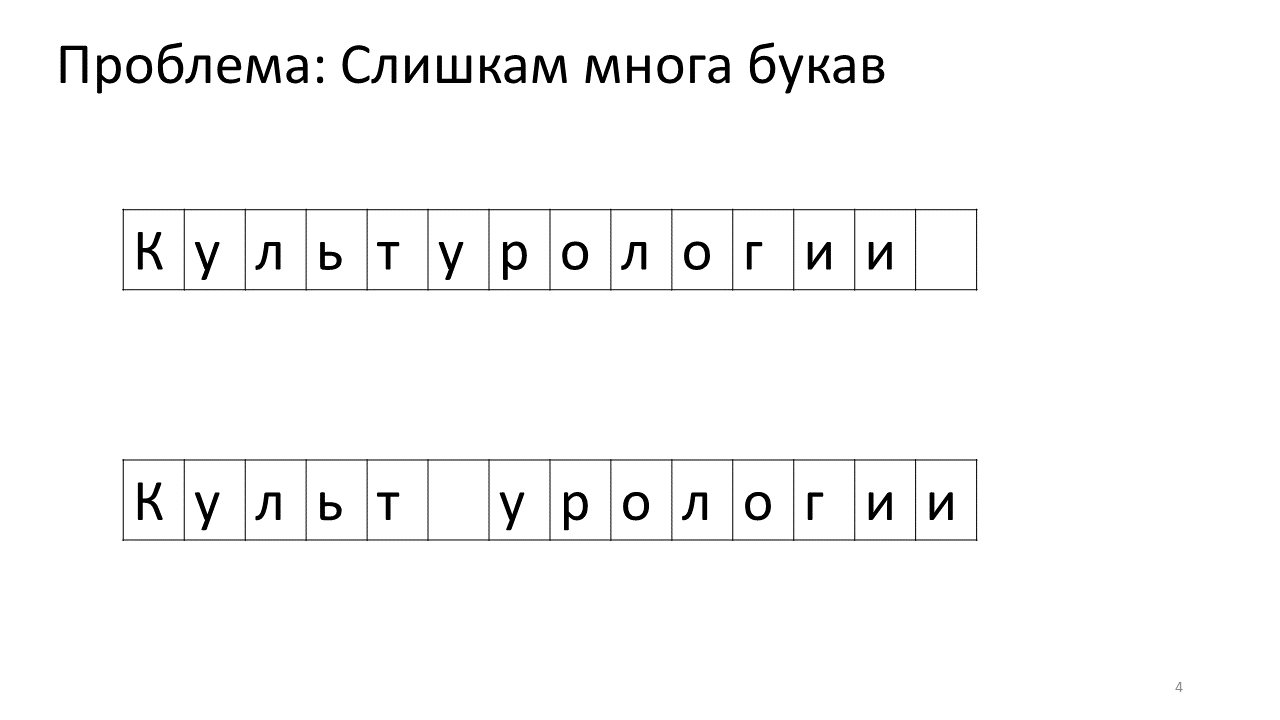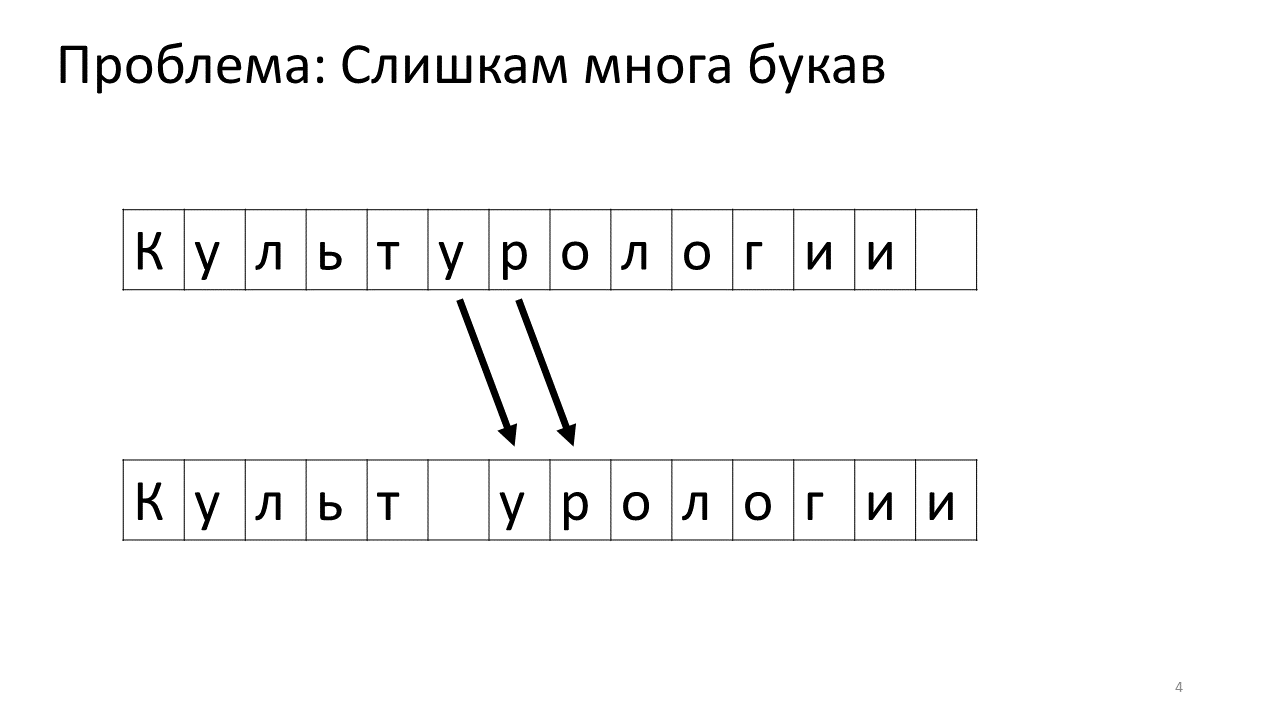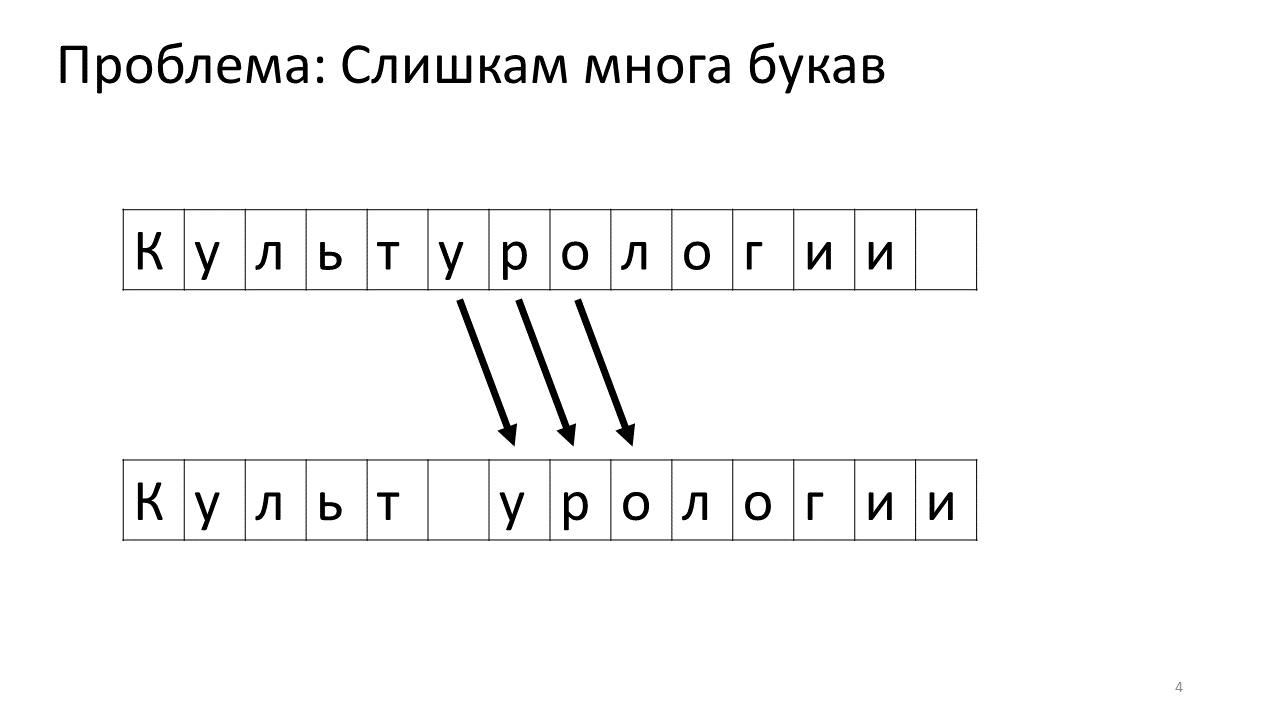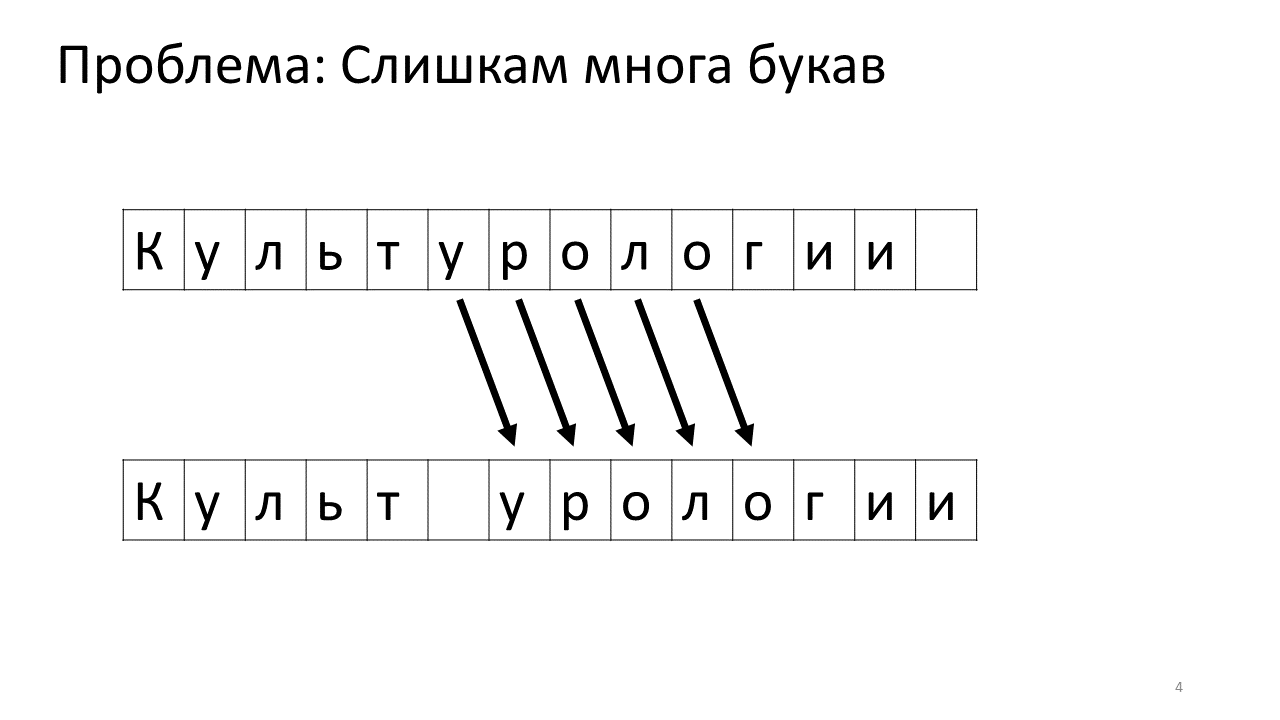
Shifting all these numerous megabytes is not very good: it is slow. Of course, for a modern computer this is a trivial matter - move some miserable megabytes back and forth. But for a very active text change this can be noticeable.
In order to solve this problem of inserting a symbol in the middle, a bypass maneuver called “Gap Buffer” was invented long ago.
Gap is a gap. Buffer is, as you might guess, a buffer. The “Gap Buffer” data structure is such an empty buffer that we store in the middle of our text, just in case. If we needed to print something, we use this text small buffer for quick typing.

The data structure has changed a little bit - the array remained in place, but two pointers appeared: at the beginning of the buffer and at its end. In order to take a character from the editor at some offset, we need to understand whether it is before or after this buffer and correct the offset a little. To insert a symbol, we first need to push the Gap Buffer to this place and fill it with these symbols. And, of course, if we go beyond our buffer, it will somehow be re-created. Here is how it looks in the picture.

As you can see, we first move a long time to a small gap-buffer (a blue rectangle) to the editing site (simply swapping characters from its left and right edges in turns). Then we use this buffer, typing in the characters there.
As you can see, there is no movement of megabytes of characters, insertion happens very quickly, at a time constant, and everything seems to be happy. Everything seems to be fine, but if we have a very slow processor, then the gap-buffer and the text are spent quite noticeably moving back and forth. This was especially noticeable in times of very small megahertz.
Just at this time, a corporation called Microsoft was writing a word-processor Word. They decided to use another idea to speed up editing under the name “Piece Table”, that is, the “Piece Table”. And they proposed to save the text of the editor in the same simplest array of characters, which will not change, and to add all its changes into a separate table of these most edited pieces.

Thus, if we need to find some symbol by offset, we need to find this piece, which we have edited, and extract this symbol from it, and if it is not there, then go to the original text. Inserting a symbol becomes easier; we just need to create and add this new piece to the table. Here is what it looks like in the picture:
Here we wanted to remove the space at offset 5. To do this, we add two new pieces to the table of pieces: one points to the first fragment (“Bummer”), and the second points to the fragment after editing (“sheep”). It turns out that the space of them disappears, these two pieces are glued together, and we get a new text without a space: “Oblomovtsy”. Then we add a new text (“those suffering from oblomovism”) to the end. Use the additional buffer and add a new piece to the table of pieces (piece table), which points to this newest added text.
As you can see, there is no movement back and forth, the whole text remains in place. The bad thing is that it becomes harder to get to the character, because sorting through all these pieces is pretty hard.
Let's sum up.
What is good inPiece Table :
What is wrong:
Let's see who generally uses what we have.
NetBeans, Eclipse and Emacs use Gap Buffer - great! Vi doesn't bother and just uses the list of lines. Word uses the Piece Table (they recently laid out their ancient sorcerers and there they could even understand something).
With Atom more interesting. Until recently, they did not bother and used a JavaScript list of lines. And then we decided to rewrite everything in C ++ and fiddled with a rather complex structure that seems to be similar to the Piece Table. But these pieces they have are not stored in the list, but in a tree, and in the so-called splay tree, this is a tree that self-regulates when inserted into it so that recent insertions are faster. They are very complicated stuff.
What does Intellij IDEA use?
No, not gap-buffer. No, you're wrong, too, not a piece table.
Yes, that's right, your own bike.
The fact is that the IDE's requirements for storing text are slightly different than in a regular text editor. IDE needs support for various tricky things like concurrency, that is, parallel access to text from the editor. For example, so many different questions could be read and done. (Inspection is a small piece of code that analyzes a program in some way or another — for example, looking for places throwing a NullPointerException). The IDE also needs support for editable text versions. Several versions are simultaneously in memory while you are working with a document so that these long processes continue to analyze the old version.
In order to maintain parallelism, text operations are usually wrapped in “synchronized”, or in Read- / Write-locks. Unfortunately, this is not very well scaled. The other approach is Immutable Text, that is, unchangeable text storage.

Here’s what an editor looks like with an immutable document as a supporting data structure.
How is the data structure itself?
Instead of an array of characters, we will have a new ImmutableText object that stores text in the form of a tree, where sheets are stored in small podstrochki. When addressing by some kind of displacement, he tries to reach the lowest leaf in this tree, and he already has to ask the symbol to which we addressed. And when inserting text, it creates a new tree and saves it in the old place.

For example, we have a document with the text "Calorie-free". It is implemented as a tree with two sheets of pods "Demon" and "high-calorie." When we want to insert the “pretty” line in the middle, a new version of our document is created. And precisely, a new root is being created, to which three sheets are already attached: "Bes", "enough" and "high-calorie". And two of these new sheets can refer to the first version of our document. And for the sheet, in which we inserted the line “pretty”, a new vertex is assigned. Here both the first version and the second version are available simultaneously and they are all immutable, unchangeable. Everything looks good.
Who uses what tricky structures?

For example, in GNOME, some standard widget uses a structure called Rope. Xi-Editor is a brilliant new editor fromRafa Leviena - uses Persistent Rope. And Intellij IDEA uses this same Immutable Tree. Behind all these names, in fact, hides more or less the same data structure with a tree view of the text. Except that GtkTextBuffer uses Mutable Rope, that is, a tree with variable vertices, and Intellij IDEA and Xi-Editor - Immutable.
The next thing to consider when developing a symbol repository in modern IDEs is called “multi-calendars.” This feature allows you to print in several places at once, using several carriages.

We can print something and at the same time in several places of the document we insert what we typed there. If we look at how our data structures that we reviewed react to multicaret, we will see something interesting.
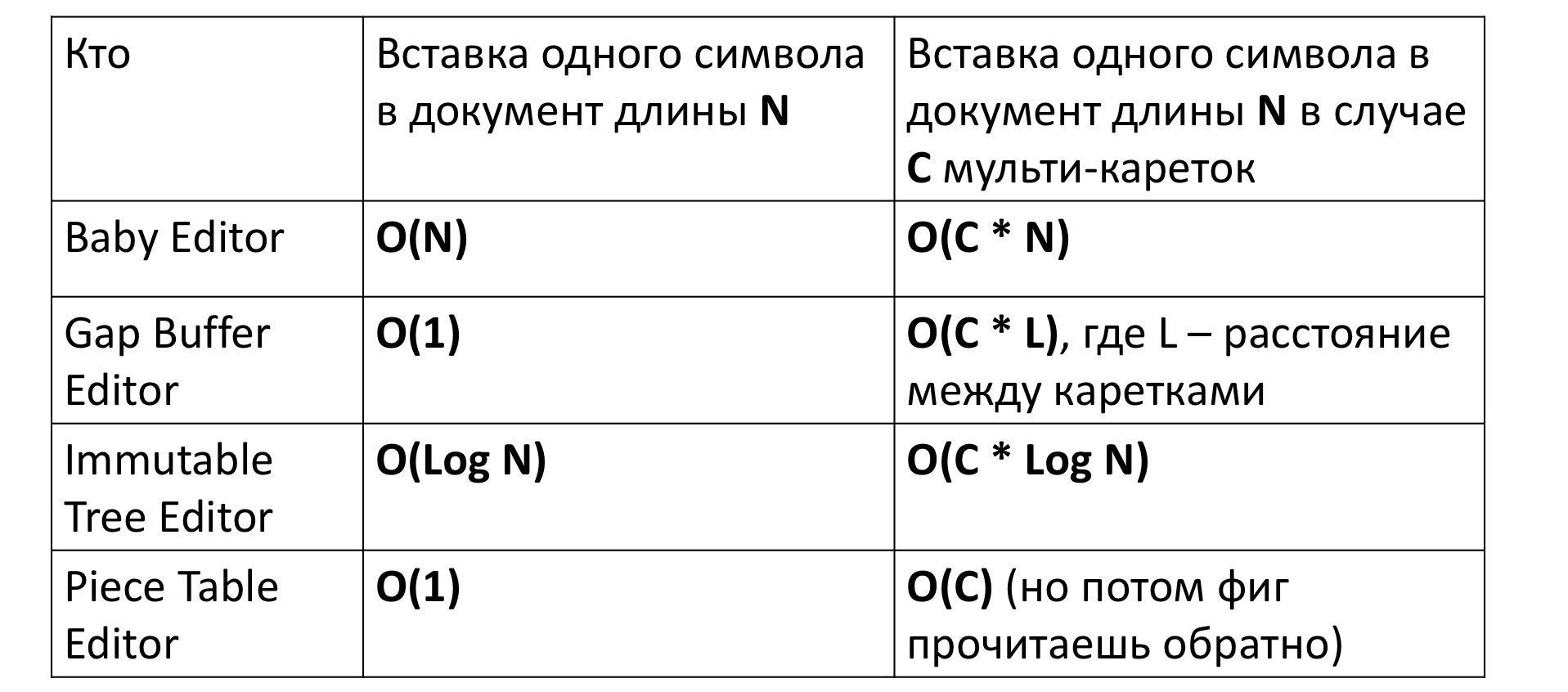
If we insert a character into our very first primitive editor, it will take, naturally, a linear amount of time to move a bunch of characters back and forth. This is written as O (N). For the editor based on Gap Buffer, in turn, it takes already constant time, for which he was invented.
For an immutable tree, time depends logarithmically on the size, because you must first go from the top of the tree to its leaf — this is the logarithm, and then for all the vertices on the way, create new vertices for the new tree — this is again the logarithm. Piece Table also requires a constant.
But everything changes a little bit, if we try to measure the time of inserting a symbol into the editor with multi-carriages, that is, inserts simultaneously in several places. At first glance, time seems to increase proportionally by C times - the number of places where the symbol is inserted. Everything is happening, with the exception of Gap Buffer. In his case, the time, instead of C times, is unexpectedly increased by some incomprehensible C * L time, where L is the average distance between carriages. Why it happens?
Imagine that we need to insert the line ", to" in two places in our document.
This is what happens in the editor at this time.
Feel what all goes?
Yes, it turns out that because of these numerous buffer movements back and forth, our total time increases. Honestly, it’s not that it’s as horrible as it’s increased - it’s not a problem to move miserable mega-gigabytes back and forth for a modern computer, but it’s still interesting that this data structure works radically differently in the case of multicarets.
What other problems are there in a regular text editor? The most difficult problem is scrolling, that is, redrawing the editor while moving the carriage to the next line.

When the editor scrolls, we need to understand from which line, from which character we need to start drawing the text in our little window. To do this, we need to quickly understand which line corresponds to which offset.
There is an obvious interface for this, when we need to understand its offset in the text by the line number. Conversely, by the offset in the text to understand in which line it is. How can this be done quickly?
For example:
Arrange these lines into a tree and mark each vertex of this tree with the offset of the beginning of the line and the offset of the end of the line. And then, in order to understand by offset, what line it is in, just need to run a logarithmic search in this tree and find it.
Another way is even easier.
Write in the table the offset of the beginning of the lines and the end of the lines. And then, in order to find the beginning and end offset by the line number, you will need to refer to the index.
Interestingly, in the real world, both are used.

For example, Eclipse uses a wooden structure that, as you can see, works in logarithmic time for both reading and updating. And IDEA uses a table structure, for which reading is a fast constant, is an index call in the table, but rebuilding is rather slow, because you need to rebuild the entire table when you change the length of a line.
What else is bad, what stumble on in text editors? For example, folding. These are pieces of text that can be “collapsed” and show something else instead.

These ellipses on a green background in the picture hide many characters behind us, but if we don’t look at them interestingly (as is the case, for example, with the longest boring Java docs or import lists), we hide them, collapse them into this dots.
And here again you need to understand when the region ends and when the region begins, which we need to show, and how to update all this quickly? How it is organized, I will tell a little later.

Also, modern editors can not live without Soft wrap. The picture shows that the developer opened the JavaScript file after minimization and immediately regretted it. This huge JavaScript string, when we try to show it in the editor, won't fit into any screen. Therefore, soft wrap it forcibly breaks into several lines and cram into the screen.
How it is organized - later.

And finally, I still want to bring beauty in text editors. For example, highlight some words. In the picture above, the keywords are highlighted in bold blue, some static methods by the Italian, some annotations are also in a different color.
So how do you still keep and handle foldings, soft wraps and highlighting?
It turns out that all this, in principle, is one and the same task.

To support all these features, all that we need to be able to do is to attach some text attributes, for example, color, font, or text for folding, according to a given offset in the text. Moreover, these text attributes need to be updated all the time in this place, so that they experience all sorts of insertions and deletions.
How is this usually implemented? Naturally, in the form of a tree.

For example, here we have some yellow highlights that we want to keep in the text. We add these highlight intervals to the search tree, the so-called interval tree. This is the same search tree, but a bit trickier, because we need to store intervals instead of numbers.
And since there are both healthy and small intervals, then sorting them out, comparing with each other and folding into a tree is a rather trivial task. Although very widely known in computer science. Look then somehow at your leisure, as it is arranged. So, we take and put all our intervals into a tree, and then every text change somewhere in the middle leads to a logarithmic change of this tree. For example, inserting a symbol should result in updating all intervals to the right of this symbol. To do this, we find all the dominant vertices for this symbol and indicate that all their sub-bushes must be moved one character to the right.

There is also such a terrible thing - ligatures, which I would also like to support. These are different beauties like how the “! =” Sign is drawn in the form of a large “not equal” glyph and so on. Fortunately, here we look forward to a swing mechanism supporting these ligatures. And, in our experience, he apparently works in the simplest way. Inside the font is a list of all these pairs of characters that, when joined together, form some kind of clever ligature. Then, when drawing a line, Swing simply iterates over all these pairs, finds the necessary ones and draws them accordingly. If you have a lot of ligatures in the font, then, apparently, its display will proportionally slow down.
And most importantly, another problem that occurs in modern complex editors is the optimization of taiping, that is, pressing the keys and displaying the result.

If you get inside Intellij IDEA and see what happens when you press a button, the next horror happens there:
Hooray!
Hell no, that's not all. Delete the character if our buffer is full. For example, in the console, call a listener so that everyone knows that something has changed. Scroll editor view. Call some more stupid listeners.
And what happens now in the editor when he found out that the document had changed and DocumentListener had volunteered to us?
In Editor.documentChanged (), this is what happens:
This repaint () is just an indication for Swing that the region on the screen should be redrawn. A real redraw will occur when the Repaint event is processed by a Swing message queue.
That is, somewhere in half an hour, the processing queue of our event will come up, the corresponding component's repaint method will be

called , which will do the following: A bunch of different paint-methods are called that paint everything that is possible in this case.
Well, can we optimize all this?

This is all, to put it mildly, quite difficult. Therefore, we at Intellij IDEA decided to deceive the user.

Before all these horrors that count and write something down, we call a small method that draws this unfortunate letter right on the place where the user imprints it. And that's it! The user is happy, because he thinks that everything has already changed, but in actual fact - no! It is still just beginning under the hood, but the little letter is already burning in front of it. And so everyone is happy. This feature is called “Zero latency typing”.
Now there is such a fashionable thing - the so-called collaborative editors.
What it is? This is when one user is sitting in India, another - in Japan, they are trying to type something into the same Google Docs and want some predictable result.
What is special:
The peculiarity here is that a huge number of users can do this at the same time, and the signal can go from India to Japan for a very long time.
And because of this, usually in collaborative editors they use newfangled things like immobility. And they came up with different things, how to make sure that everything works as it should. These are a few criteria. The first criterion is the preservation of intention, the intention preservation. This means that if someone has imprinted the symbol, then sooner or later the symbol from India will come to Japan, and the Japanese will see exactly what the Indian intended. And the second criterion is convergence. This means that symbols from India and Japan will sooner or later be transformed into something the same for Japan and for India.
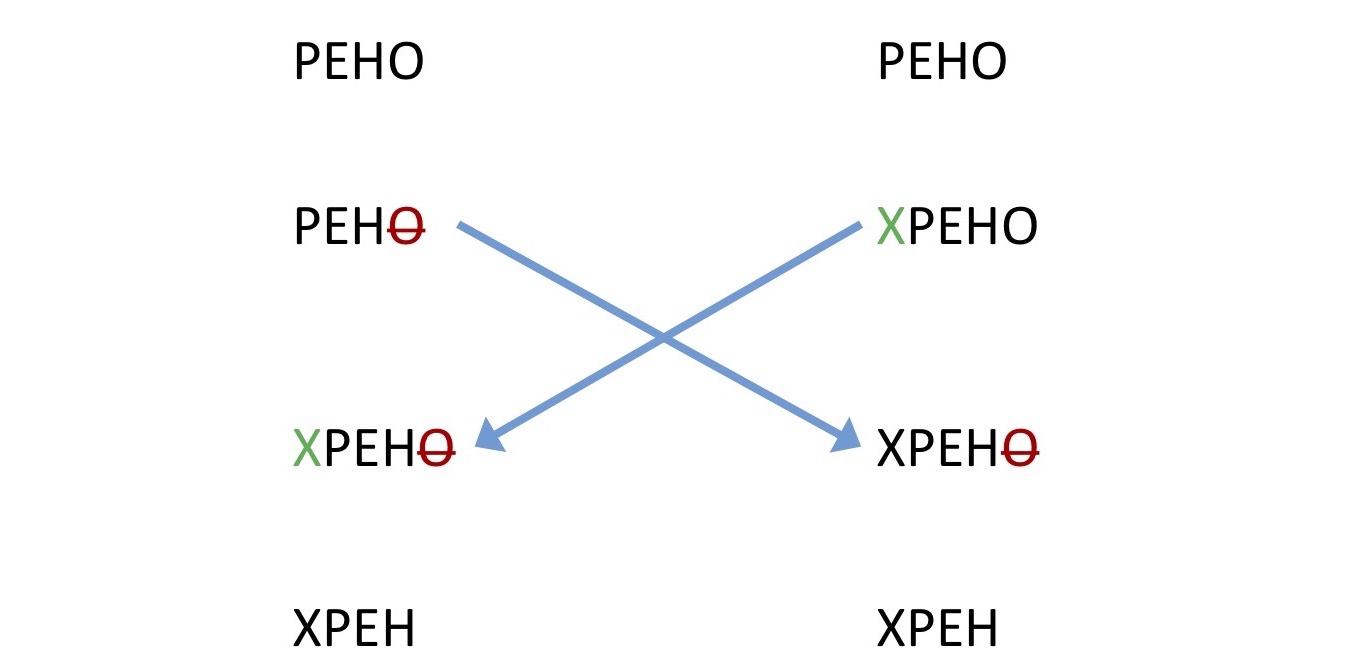
The first algorithm that was invented to support this thing is called the “operation transformation”. It works like this. An Indian and a Japanese are sitting, typing something: one deletes a letter from the end, another draws a letter to the beginning. The Operation transformation framework sends these operations to all other places. He must understand how to surmount the operations that come to him in order to get at least something sensible. For example, when you simultaneously have a letter deleted and appeared. It should work more or less consistently both there and there, and come to the same line. Unfortunately, as can be seen from my confused explanation, this is a rather complicated matter.
When the first implementations of this framework began to appear, astonished developers discovered that there is a universal example that breaks everything. This unfortunate example was called the “TP2 puzzle”.
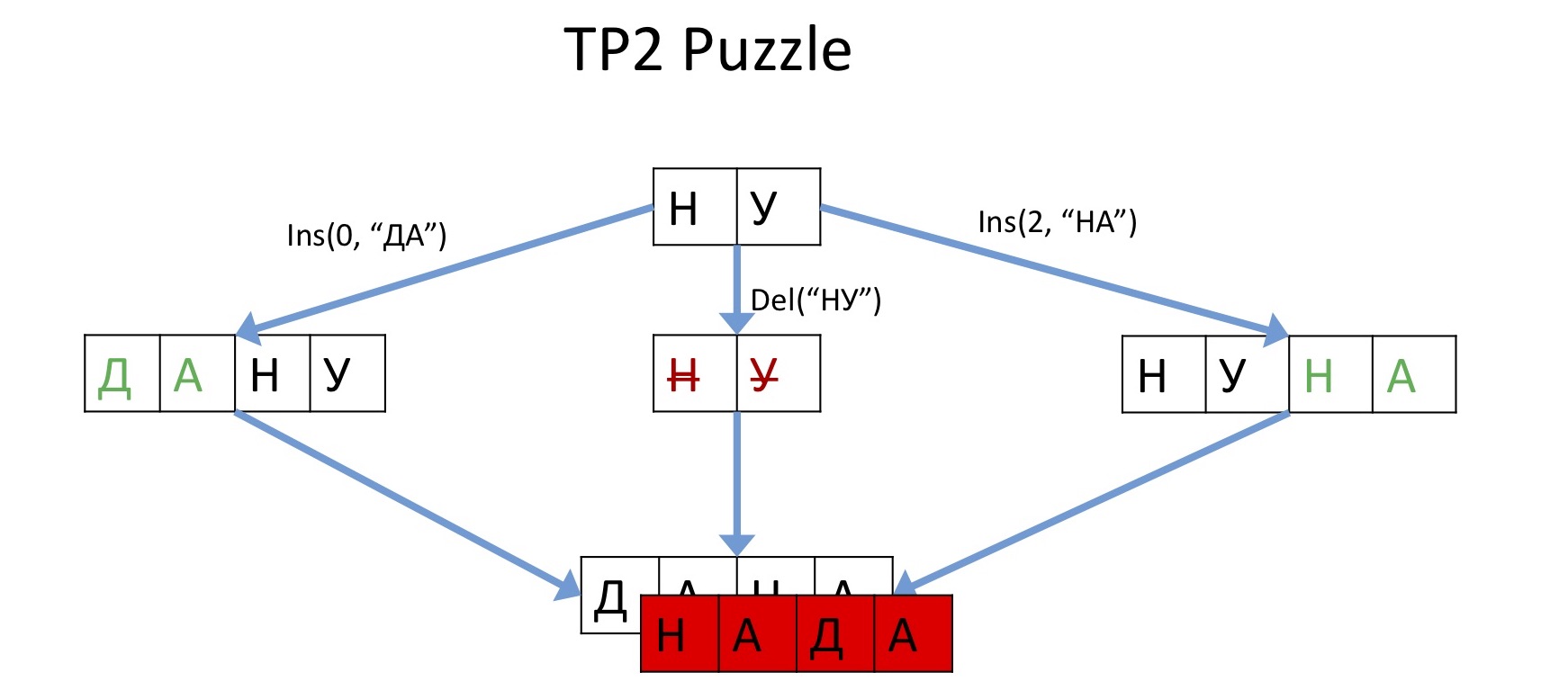
One user draws some characters to the beginning of the line, another one removes all this, and the third draws to the end. After all this Operation transformation tries to merge into one and the same, then this line should, in theory, be obtained here (“DANA”). However, some implementations did this (“NADA”). Because it is not clear where to insert it. The picture above shows at what level this whole science is about the Operation transformation, if because of such a primitive example, everything broke.
But despite this, some people still do it, like Google Docs, Google Wave and some distributed editor of Etherpad. They use the Operation transformation despite the problems listed.
The people here had their heads brained and decided: “Let's make it easier than OT!” The number of any tricky combinations of operations that need to be processed and merged together grows quadratically. Therefore, instead of processing all the combinations, we will simply send our status along with the operation to all other hosts so that it can be merged into the same text with a guarantee of 100%. This is called "CRDT" (Conflict-free replicated data type).

For this to work, you need a state and a function, which of the two states together with the operation makes a new state. Moreover, this function should be commutative, associative, idempotent and monotone. And then it is clear that everything will work simply and reinforced. Because of these draconian restrictions on the function, we are no longer afraid of disturbing the order (the function is commutative), priority (associative), and packet loss in the network (idempotency and monotony).

Are there such functions in nature and how can they be applied?
Yes. For example, for the case of so-called G-counter'ov, that is, counters that are only growing. You can write a function for this counter that is truly monotonous, and so on. Because if we have the operation “+1” from Japan, the other “+1” from India, it is clear how to make a new state out of them - just add “2.” But it turns out that in the same way an arbitrary counter can be made, which can be incremented and decremented. To do this, it is enough to take one G-counter, which grows up all the time, and apply all increment operations to it. And all the decrements are applied to another G-counter, which will grow down. To get the current status, you just need to subtract their contents, and we get the same monotony. This is all possible to extend to arbitrary sets. But the most important thing is for arbitrary strings. Yes, editing arbitrary strings can also be made CRDT. Turns out it's pretty easy.
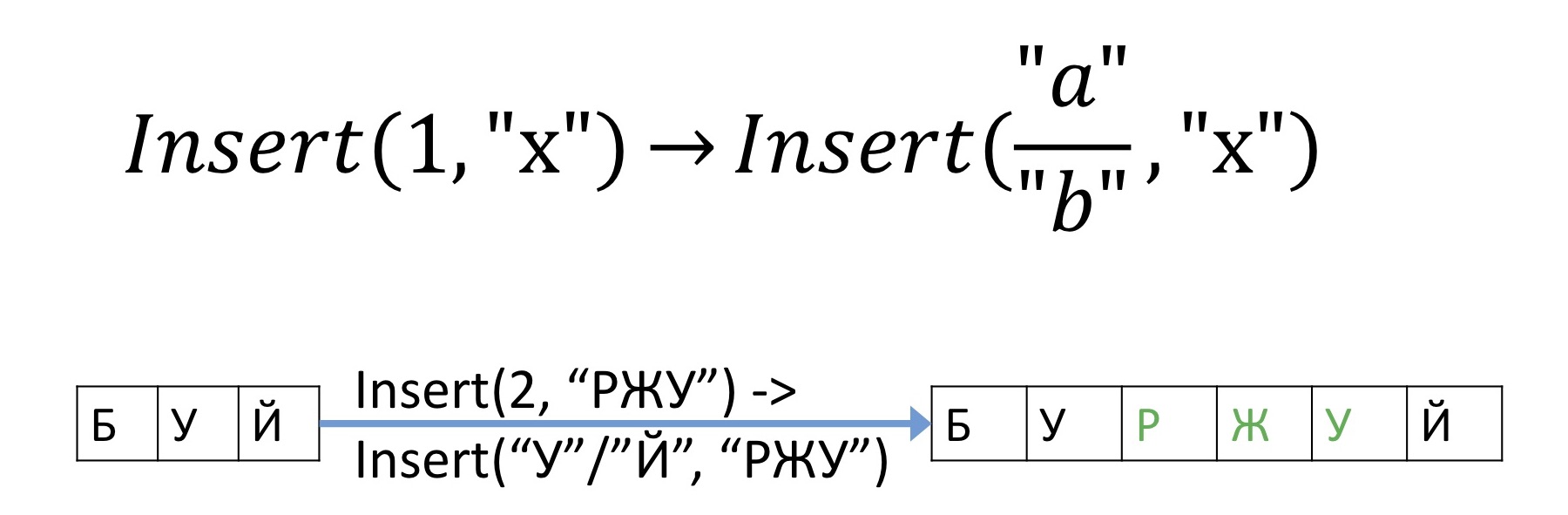
First, let's name all the characters in the document so that they are always uniquely identifiable, even after all edits. Well, for example, together with each letter we will store a unique number.
Now, instead of sending all people the information that we insert a symbol at some offset, we will instead say which symbols we will insert between them. And then it is clear that there can be no discrepancies, wherever we insert, we will definitely know the place, even after any other operations. For example, instead of sending an operation that we want to insert “RLU” at offset 2, we will send information that we insert “RLU” between this “Y” and this “R”.
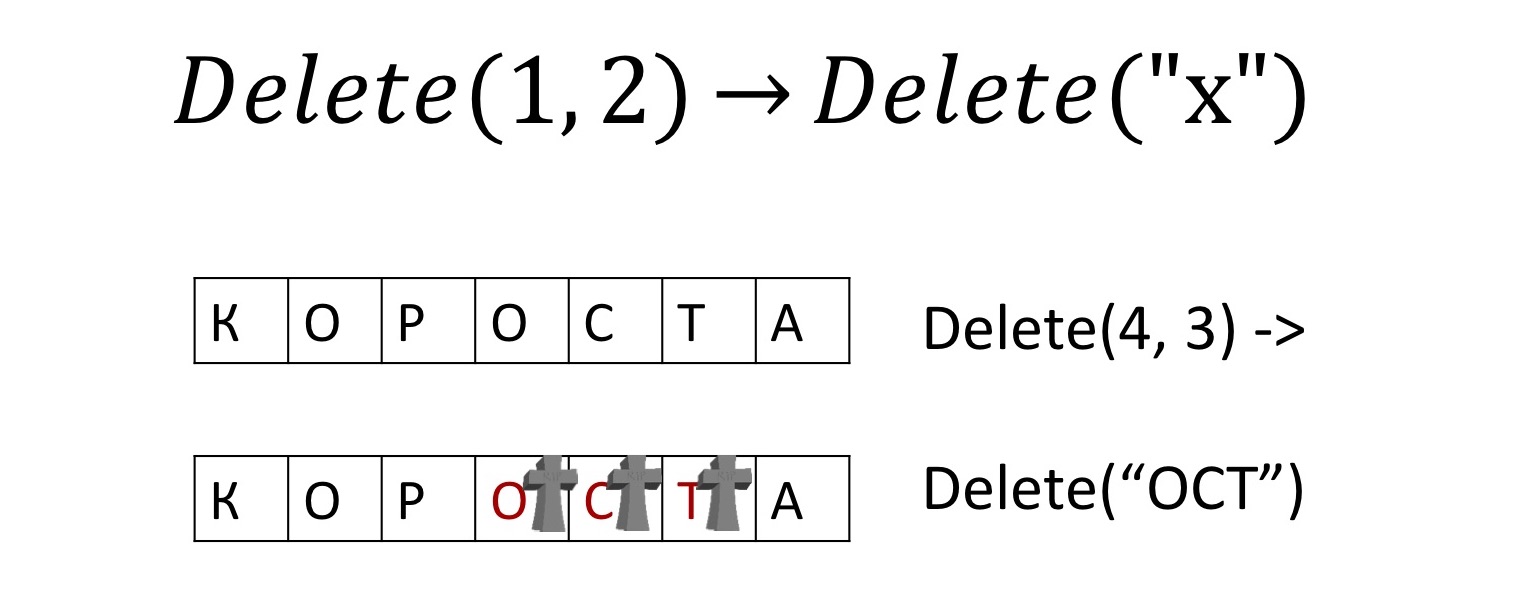
You can also implement and delete characters. Since all of our characters are uniquely renamed, we simply say exactly which character needs to be deleted, instead of some kind of offsets. But instead of physically deleting these characters, we’ll mark them as deleted. In order for subsequent parallel insertions or deletions to know, if they affect these deleted characters, exactly where they should go.
And it turns out that this whole new-fangled science works.
And, in fact, CRDT is even implemented somewhere, for example, in Xi-Editor, which will be inserted into their newfangled Fuchsia secret operating system. To be honest, I don’t know of other examples, but it definitely works.
I would also like to tell you about the thing that is used in this new, immutable world called “Zipper”. After we made our structures immutable, some nuances of working with them appeared. Here, for example, we have our immutable tree with text. We want to change it, (by “change” here, as you understand, I mean “create a new version”). Moreover, we want to change it in a particular place and quite actively. In editors, this is quite common when we constantly print, insert and delete something at the cursor. To do this, the functionaries came up with a structure called Zipper.
It has the concept of the so-called cursor or the current place for editing, while maintaining full immunity. Here is how it is done.
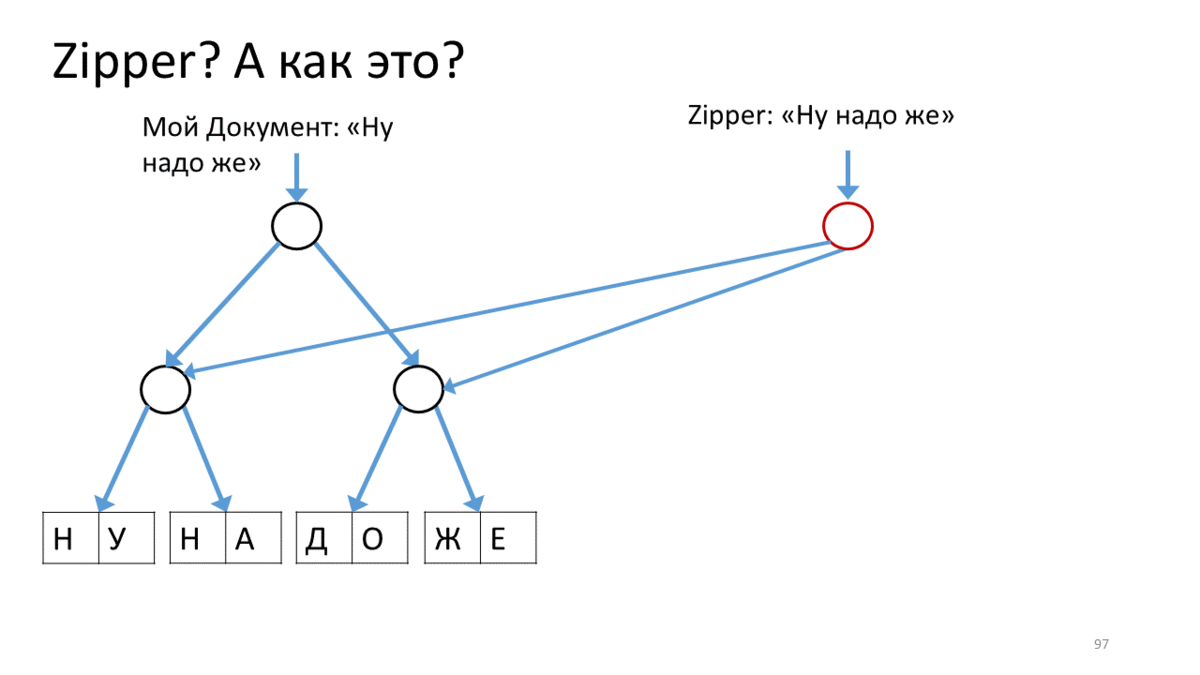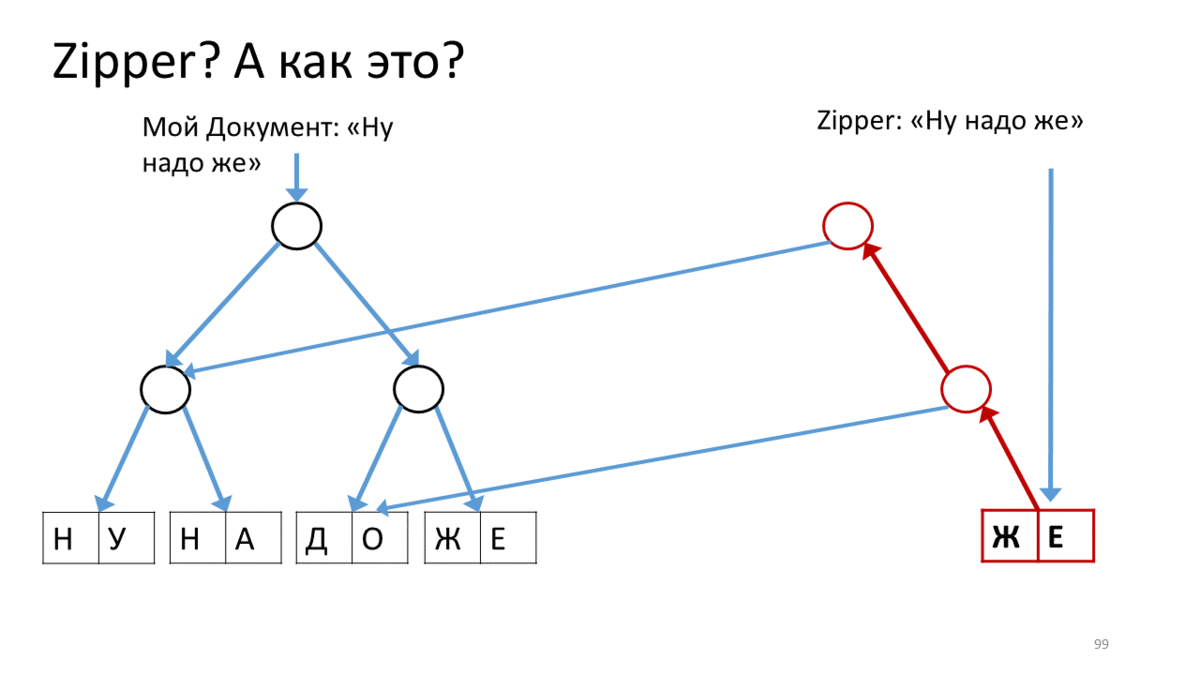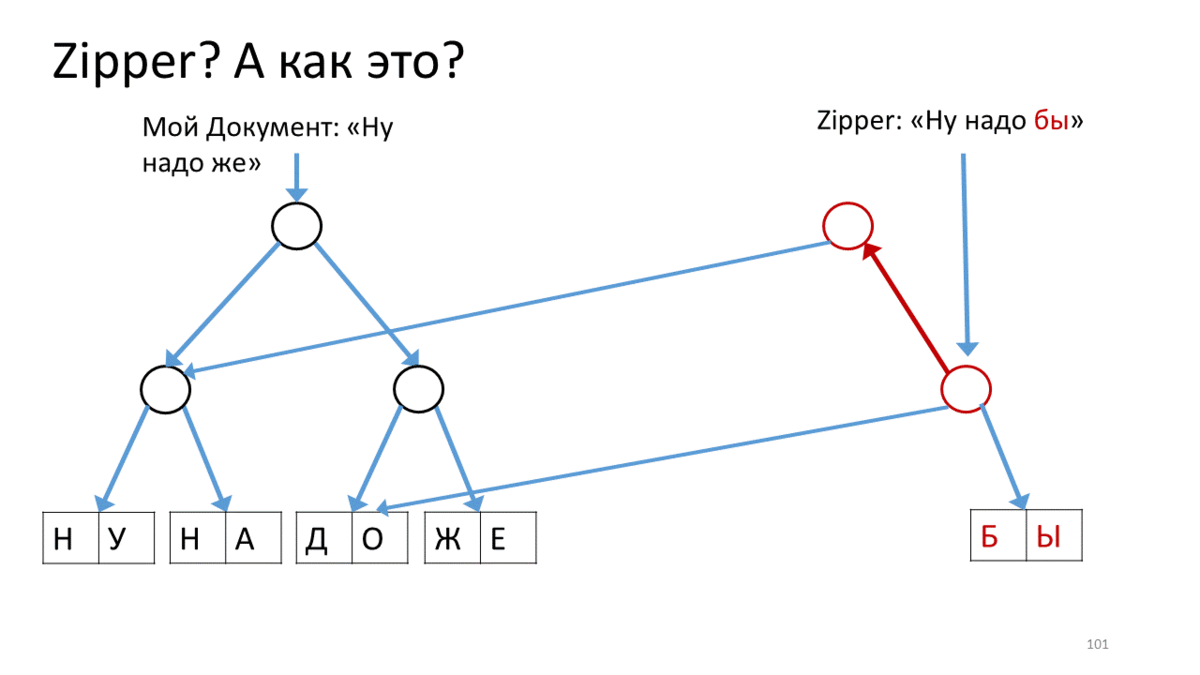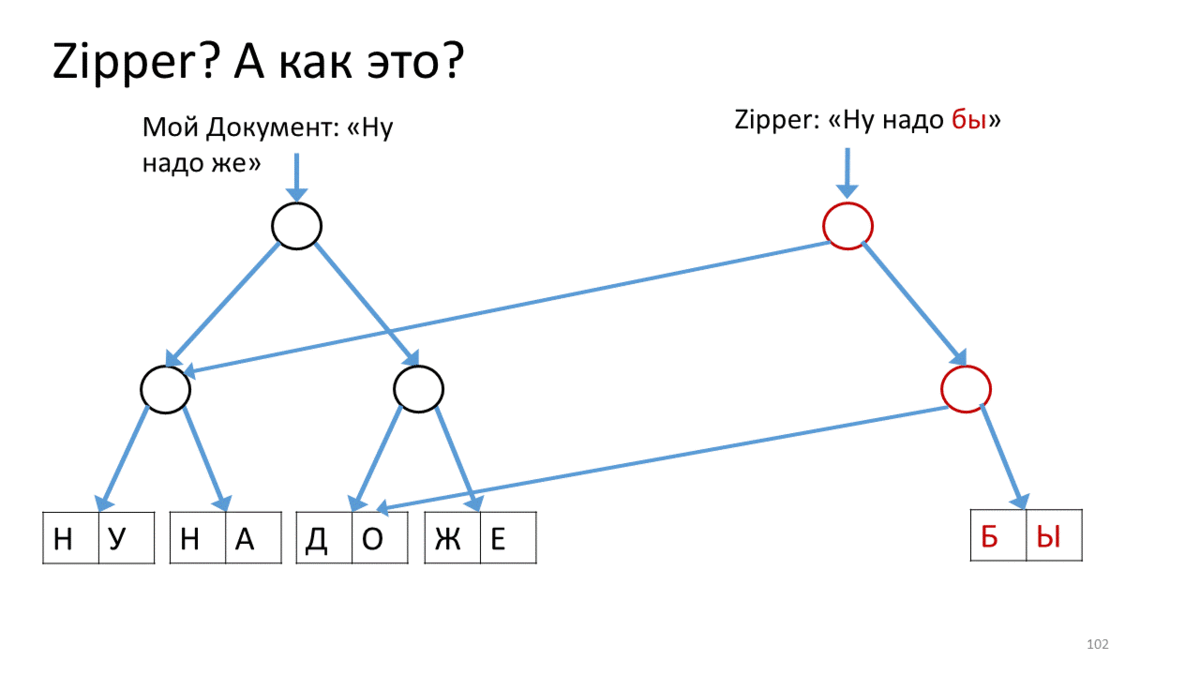
Create a Zipper for our document, which contains a line for editing (“Well need to”). Call the operation on this Zipper to move along the line to the editing place. In our case - go down to the top right down. To do this, we create a new vertex (red) corresponding to the current vertex, attach to it links to the child vertices from our tree. Now, to move the Zipper cursor, we go down and down and create a new vertex instead of the one on which we stood. At the same time, add a link to the top up, so as not to forget where you came from (red arrows). Having thus reached the place of editing, we create a new sheet instead of the edited text (red rectangle). Now go back, going along the red arrows upwards and replacing them on the way to the correct links to the child vertices.
Notice how the cursor helps us edit the current piece of wood.
What conclusions did I want to convey to you? First, oddly enough, in the topic of text editors, despite its stuffiness, there are all sorts of interesting things. Moreover, in the same topic sometimes new, sometimes unexpected discoveries appear. And thirdly, sometimes they are so new that they do not work the first time. But it is interesting and you can warm up. Thank.
→ Repository
→ Mail
Zipper data structure
How does CRDT in Xi Editor
In general, a tree-like data structures for text
What twists in the atom
After the report was a long time, and Microsoft had to remember their roots and to rewrite the Visual Studio Code editor on the Table Piece .
And in general, for some reason, many people were drawn to experiments .
The article is based on Alexey Kudryavtsev's report with Joker 2017. Alexey has been writing Intellij IDEA in JetBrains for 10 years already. Under the cut you will find the video and text transcript of the report.
Data structures within text editors
To understand how the editor works, let's write it.
Everything, our elementary editor is ready.
Inside the editor, the text is easiest to store in an array of characters, or, equivalently (in terms of memory organization), in the StringBuffer Java class. To get any character by offset, we call the StringBuffer.charAt (i) method. And to insert into it the character that we typed on the keyboard, call the StringBuffer.insert () method, which will insert the character somewhere in the middle.
What is most interesting, despite the simplicity and idiocy of this editor, is the best presentation that you can imagine. It is simple and almost always fast.
Unfortunately, there is a scale problem with this editor. Imagine that we typed a lot of text in it and are going to insert another letter in the middle. The following will occur. We urgently need to free up some space for this letter by moving all the other letters one character forward. To do this, we shift this letter by one position, then the next, and so on, until the very end of the text.
This is how it will look like in memory:
Shifting all these numerous megabytes is not very good: it is slow. Of course, for a modern computer this is a trivial matter - move some miserable megabytes back and forth. But for a very active text change this can be noticeable.
In order to solve this problem of inserting a symbol in the middle, a bypass maneuver called “Gap Buffer” was invented long ago.
Gap buffer
Gap is a gap. Buffer is, as you might guess, a buffer. The “Gap Buffer” data structure is such an empty buffer that we store in the middle of our text, just in case. If we needed to print something, we use this text small buffer for quick typing.
The data structure has changed a little bit - the array remained in place, but two pointers appeared: at the beginning of the buffer and at its end. In order to take a character from the editor at some offset, we need to understand whether it is before or after this buffer and correct the offset a little. To insert a symbol, we first need to push the Gap Buffer to this place and fill it with these symbols. And, of course, if we go beyond our buffer, it will somehow be re-created. Here is how it looks in the picture.
As you can see, we first move a long time to a small gap-buffer (a blue rectangle) to the editing site (simply swapping characters from its left and right edges in turns). Then we use this buffer, typing in the characters there.
As you can see, there is no movement of megabytes of characters, insertion happens very quickly, at a time constant, and everything seems to be happy. Everything seems to be fine, but if we have a very slow processor, then the gap-buffer and the text are spent quite noticeably moving back and forth. This was especially noticeable in times of very small megahertz.
Piece table
Just at this time, a corporation called Microsoft was writing a word-processor Word. They decided to use another idea to speed up editing under the name “Piece Table”, that is, the “Piece Table”. And they proposed to save the text of the editor in the same simplest array of characters, which will not change, and to add all its changes into a separate table of these most edited pieces.
Thus, if we need to find some symbol by offset, we need to find this piece, which we have edited, and extract this symbol from it, and if it is not there, then go to the original text. Inserting a symbol becomes easier; we just need to create and add this new piece to the table. Here is what it looks like in the picture:
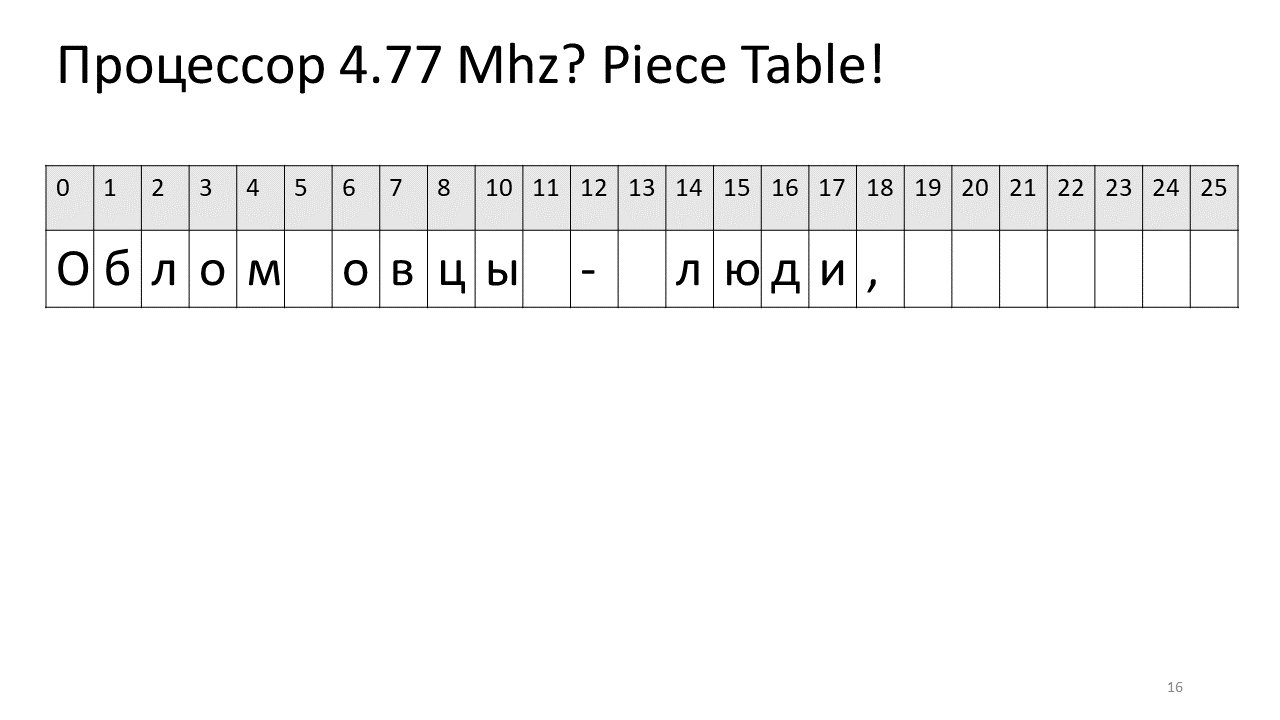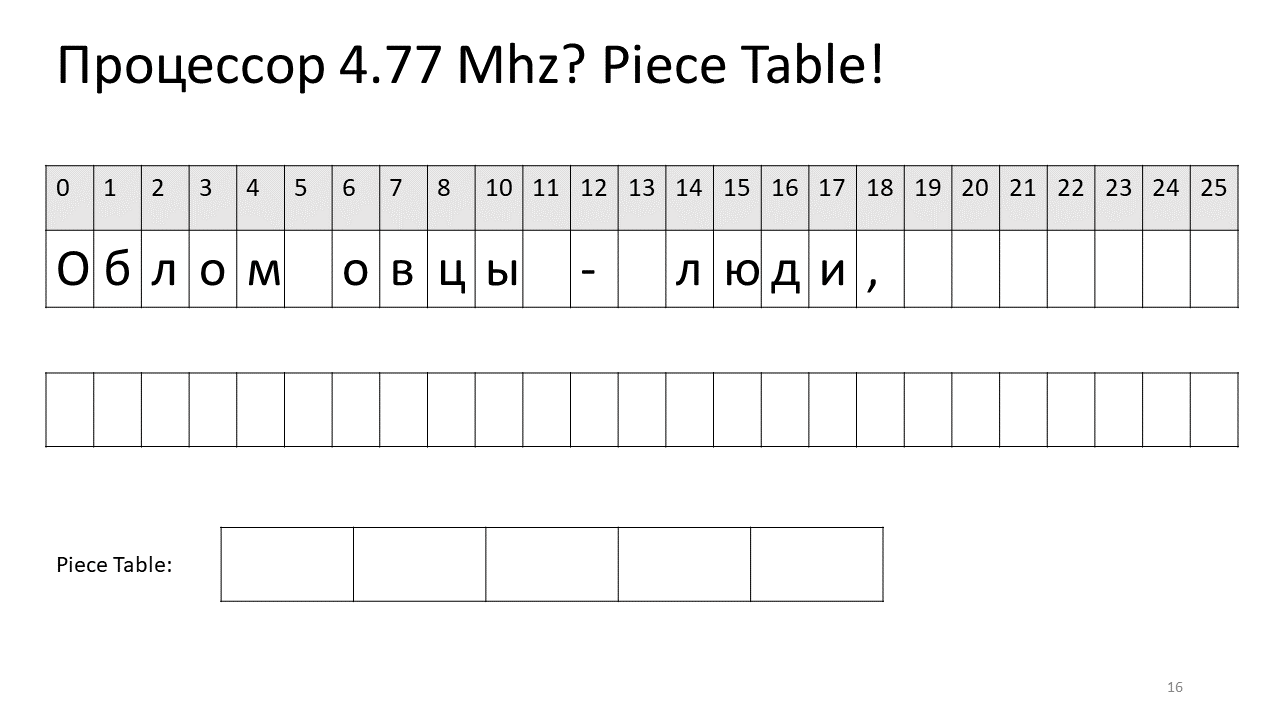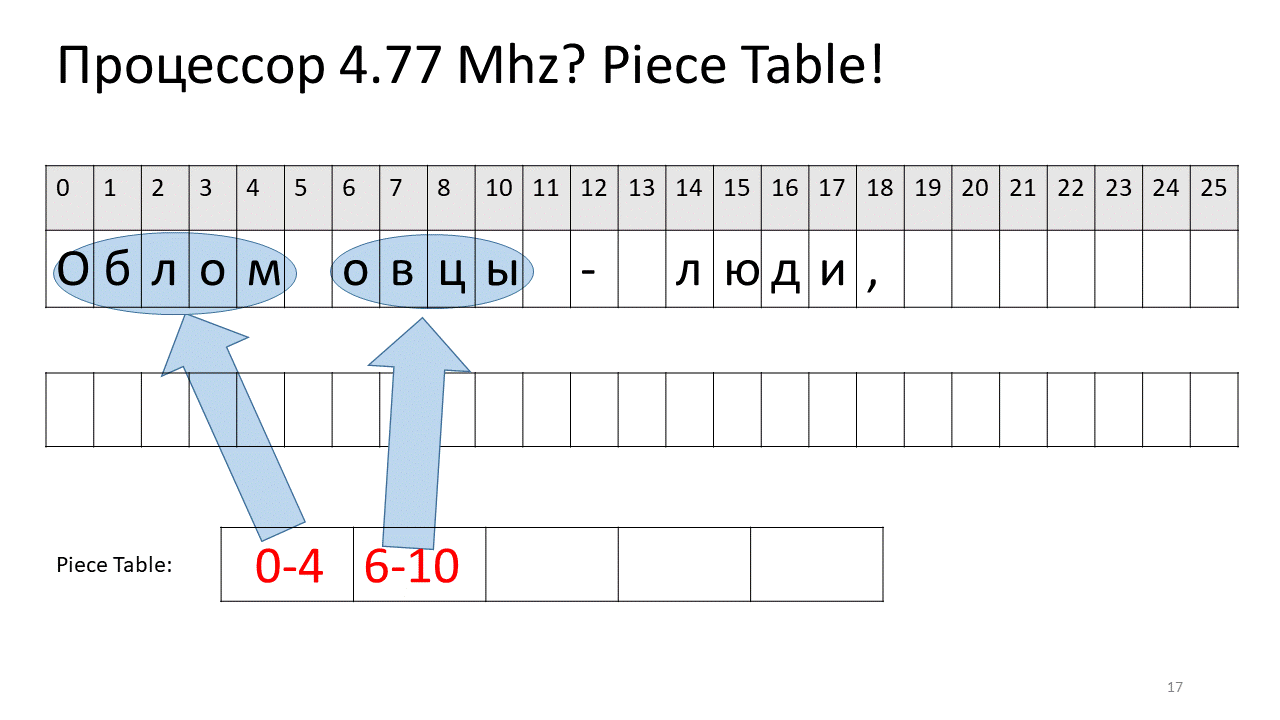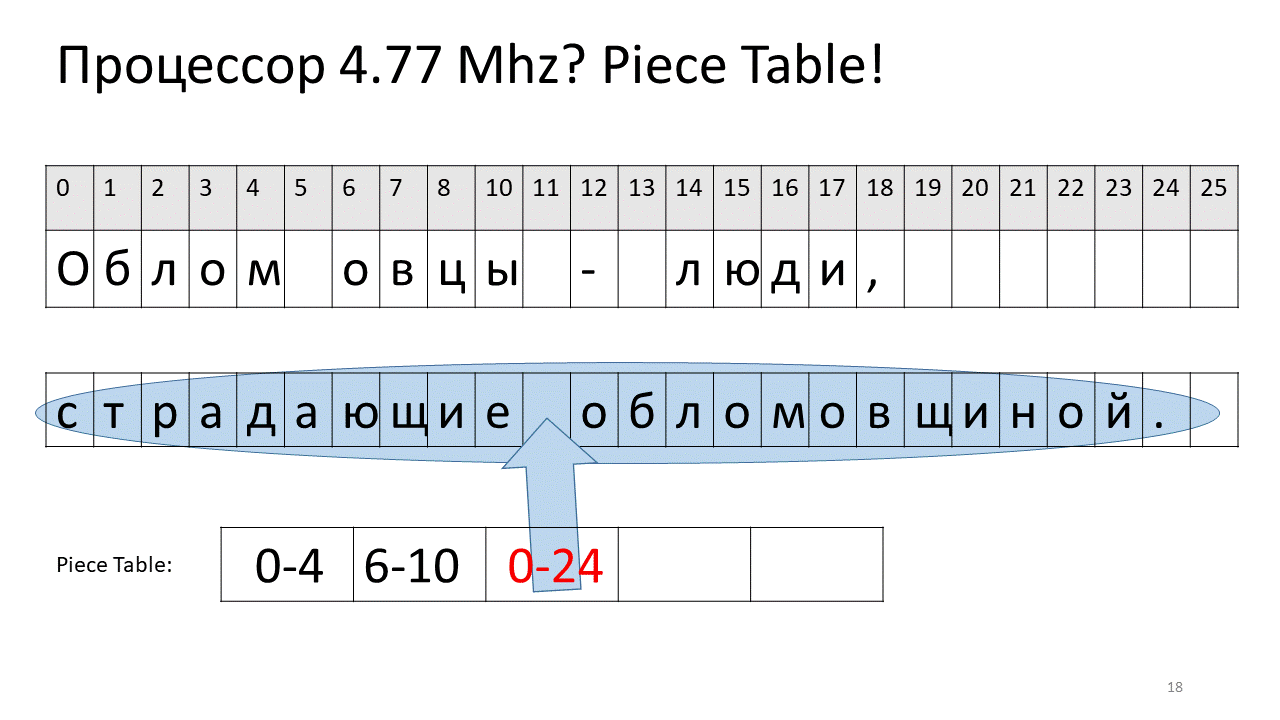
Here we wanted to remove the space at offset 5. To do this, we add two new pieces to the table of pieces: one points to the first fragment (“Bummer”), and the second points to the fragment after editing (“sheep”). It turns out that the space of them disappears, these two pieces are glued together, and we get a new text without a space: “Oblomovtsy”. Then we add a new text (“those suffering from oblomovism”) to the end. Use the additional buffer and add a new piece to the table of pieces (piece table), which points to this newest added text.
As you can see, there is no movement back and forth, the whole text remains in place. The bad thing is that it becomes harder to get to the character, because sorting through all these pieces is pretty hard.
Let's sum up.
What is good inPiece Table :
- Quickly paste;
- Easy to do undo;
- Append-only.
What is wrong:
- Terribly difficult to access the document;
- Terribly difficult to implement.
Let's see who generally uses what we have.
NetBeans, Eclipse and Emacs use Gap Buffer - great! Vi doesn't bother and just uses the list of lines. Word uses the Piece Table (they recently laid out their ancient sorcerers and there they could even understand something).
With Atom more interesting. Until recently, they did not bother and used a JavaScript list of lines. And then we decided to rewrite everything in C ++ and fiddled with a rather complex structure that seems to be similar to the Piece Table. But these pieces they have are not stored in the list, but in a tree, and in the so-called splay tree, this is a tree that self-regulates when inserted into it so that recent insertions are faster. They are very complicated stuff.
What does Intellij IDEA use?
No, not gap-buffer. No, you're wrong, too, not a piece table.
Yes, that's right, your own bike.
The fact is that the IDE's requirements for storing text are slightly different than in a regular text editor. IDE needs support for various tricky things like concurrency, that is, parallel access to text from the editor. For example, so many different questions could be read and done. (Inspection is a small piece of code that analyzes a program in some way or another — for example, looking for places throwing a NullPointerException). The IDE also needs support for editable text versions. Several versions are simultaneously in memory while you are working with a document so that these long processes continue to analyze the old version.
Problems
Competitiveness / Versioning
In order to maintain parallelism, text operations are usually wrapped in “synchronized”, or in Read- / Write-locks. Unfortunately, this is not very well scaled. The other approach is Immutable Text, that is, unchangeable text storage.
Here’s what an editor looks like with an immutable document as a supporting data structure.
How is the data structure itself?
Instead of an array of characters, we will have a new ImmutableText object that stores text in the form of a tree, where sheets are stored in small podstrochki. When addressing by some kind of displacement, he tries to reach the lowest leaf in this tree, and he already has to ask the symbol to which we addressed. And when inserting text, it creates a new tree and saves it in the old place.
For example, we have a document with the text "Calorie-free". It is implemented as a tree with two sheets of pods "Demon" and "high-calorie." When we want to insert the “pretty” line in the middle, a new version of our document is created. And precisely, a new root is being created, to which three sheets are already attached: "Bes", "enough" and "high-calorie". And two of these new sheets can refer to the first version of our document. And for the sheet, in which we inserted the line “pretty”, a new vertex is assigned. Here both the first version and the second version are available simultaneously and they are all immutable, unchangeable. Everything looks good.
Who uses what tricky structures?
For example, in GNOME, some standard widget uses a structure called Rope. Xi-Editor is a brilliant new editor fromRafa Leviena - uses Persistent Rope. And Intellij IDEA uses this same Immutable Tree. Behind all these names, in fact, hides more or less the same data structure with a tree view of the text. Except that GtkTextBuffer uses Mutable Rope, that is, a tree with variable vertices, and Intellij IDEA and Xi-Editor - Immutable.
The next thing to consider when developing a symbol repository in modern IDEs is called “multi-calendars.” This feature allows you to print in several places at once, using several carriages.
We can print something and at the same time in several places of the document we insert what we typed there. If we look at how our data structures that we reviewed react to multicaret, we will see something interesting.
If we insert a character into our very first primitive editor, it will take, naturally, a linear amount of time to move a bunch of characters back and forth. This is written as O (N). For the editor based on Gap Buffer, in turn, it takes already constant time, for which he was invented.
For an immutable tree, time depends logarithmically on the size, because you must first go from the top of the tree to its leaf — this is the logarithm, and then for all the vertices on the way, create new vertices for the new tree — this is again the logarithm. Piece Table also requires a constant.
But everything changes a little bit, if we try to measure the time of inserting a symbol into the editor with multi-carriages, that is, inserts simultaneously in several places. At first glance, time seems to increase proportionally by C times - the number of places where the symbol is inserted. Everything is happening, with the exception of Gap Buffer. In his case, the time, instead of C times, is unexpectedly increased by some incomprehensible C * L time, where L is the average distance between carriages. Why it happens?
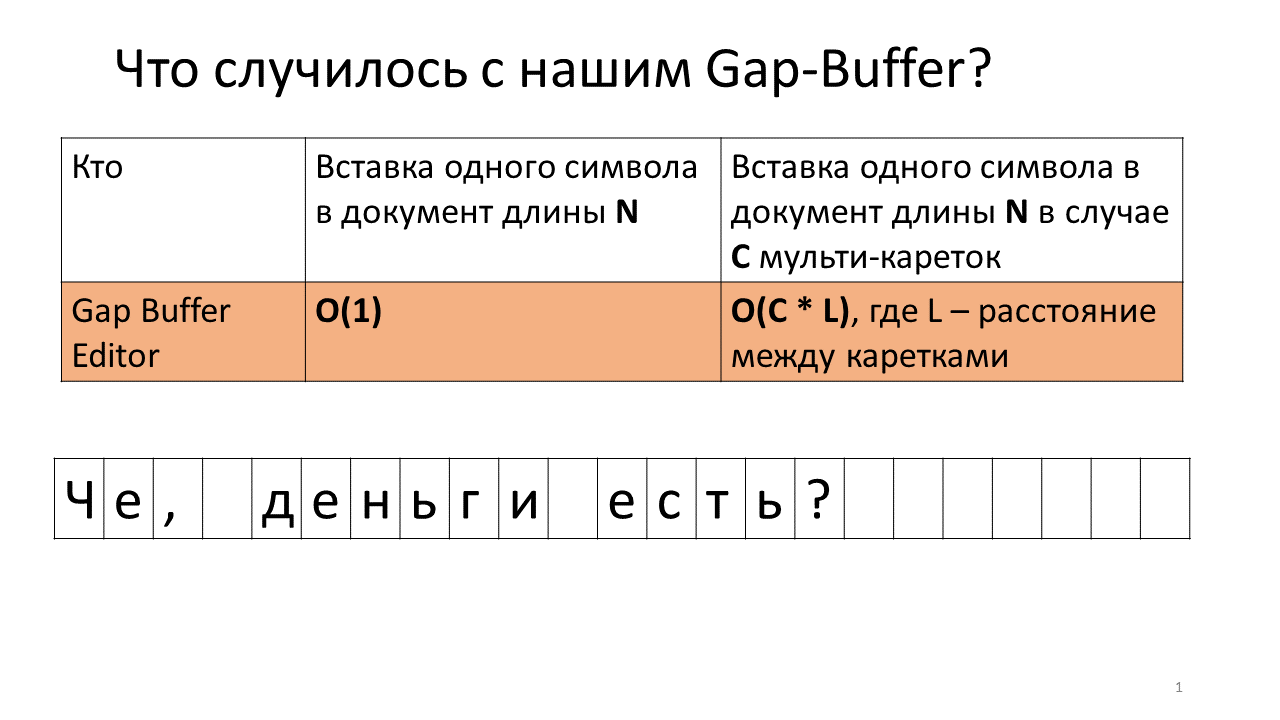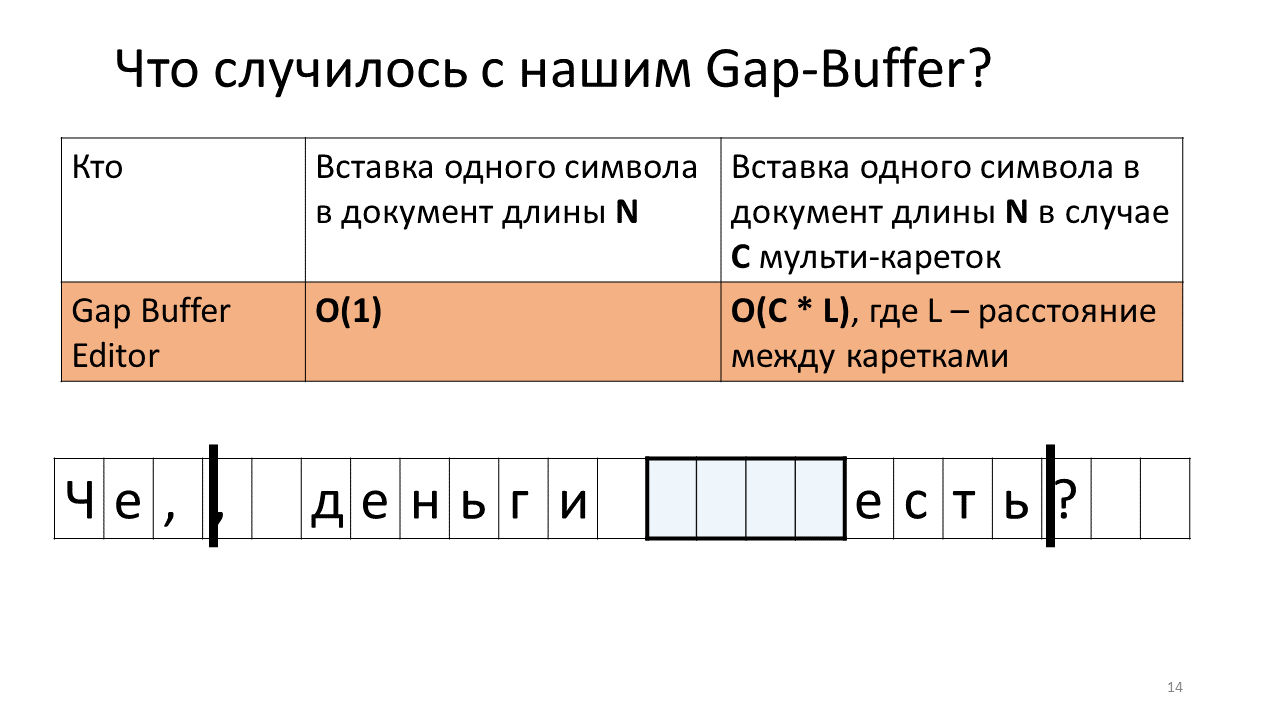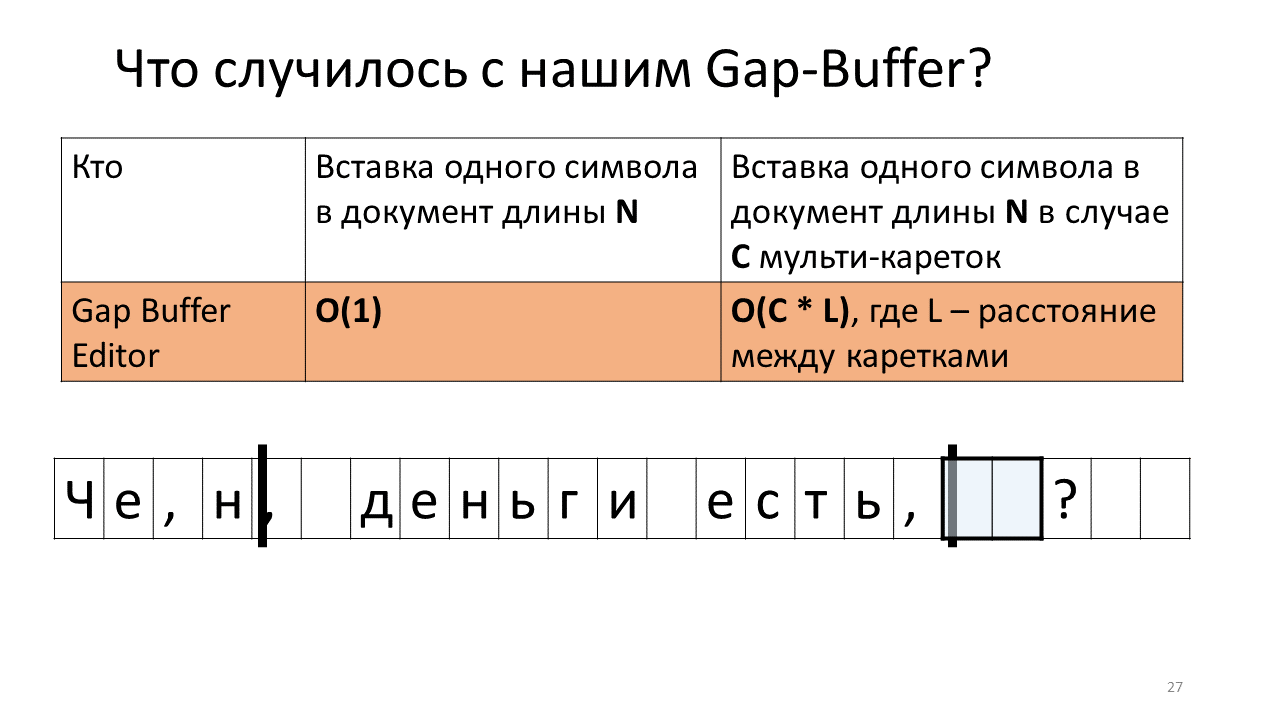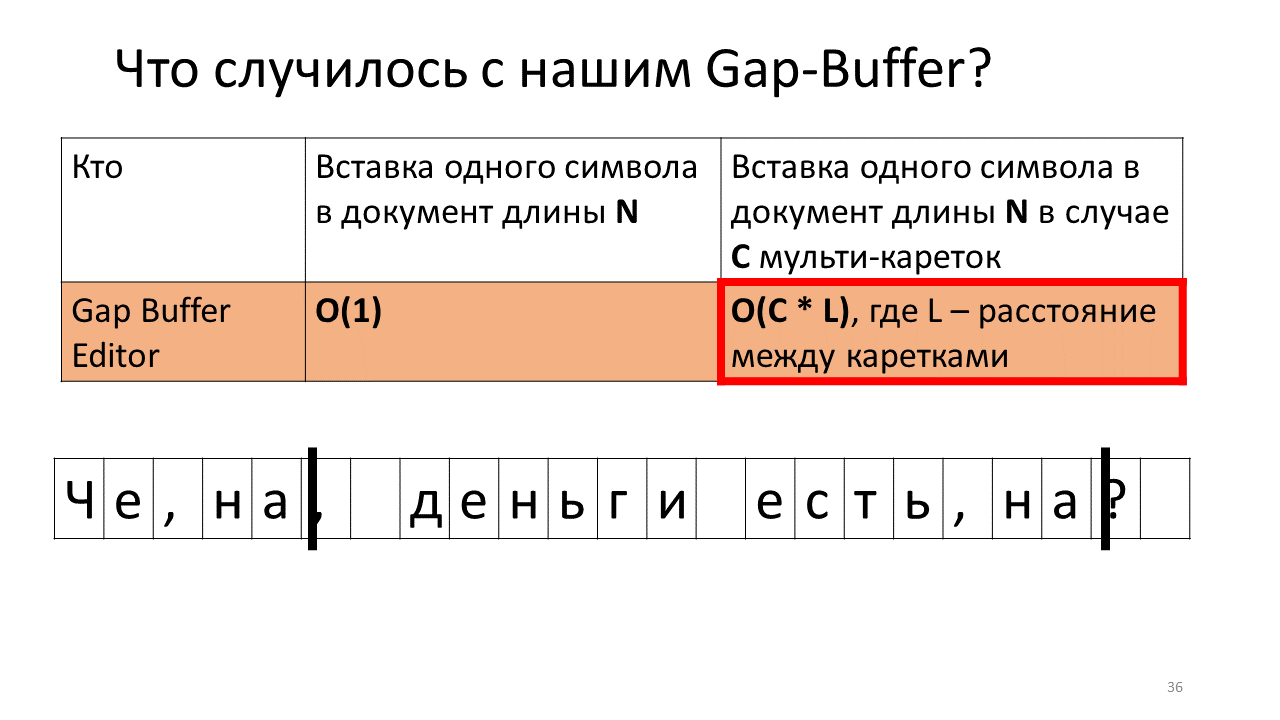
Imagine that we need to insert the line ", to" in two places in our document.
This is what happens in the editor at this time.
- Create a gap-buffer editor (a blue rectangle in the figure);
- We get two carriages (black fat vertical lines);
- We try to print;
- Insert a comma in our Gap Buffer;
- Must now insert it in place of the second carriage;
- To do this, we need to push our Gap Buffer to the position of the next carriage;
- Type comma in second place;
- Now you need to insert the next character in the position of the first carriage;
- And we have to push our Gap Buffer back;
- Insert the letter "n";
- And we move our long-suffering buffer to the place of the second carriage;
- We insert there our "n";
- Move the buffer back to insert the next character.
Feel what all goes?
Yes, it turns out that because of these numerous buffer movements back and forth, our total time increases. Honestly, it’s not that it’s as horrible as it’s increased - it’s not a problem to move miserable mega-gigabytes back and forth for a modern computer, but it’s still interesting that this data structure works radically differently in the case of multicarets.
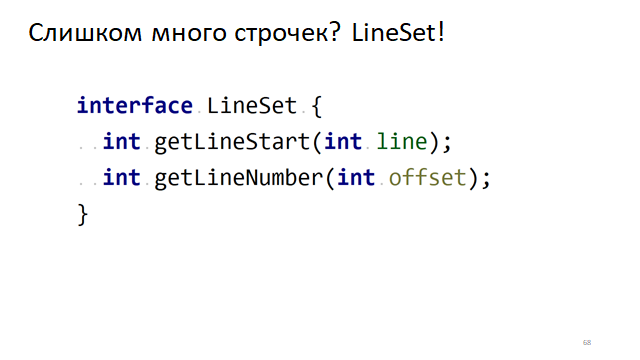
Too many lines? LineSet!
What other problems are there in a regular text editor? The most difficult problem is scrolling, that is, redrawing the editor while moving the carriage to the next line.
When the editor scrolls, we need to understand from which line, from which character we need to start drawing the text in our little window. To do this, we need to quickly understand which line corresponds to which offset.
There is an obvious interface for this, when we need to understand its offset in the text by the line number. Conversely, by the offset in the text to understand in which line it is. How can this be done quickly?
For example:
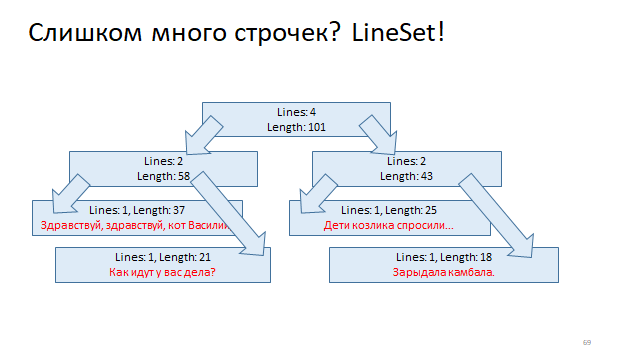
Arrange these lines into a tree and mark each vertex of this tree with the offset of the beginning of the line and the offset of the end of the line. And then, in order to understand by offset, what line it is in, just need to run a logarithmic search in this tree and find it.
Another way is even easier.
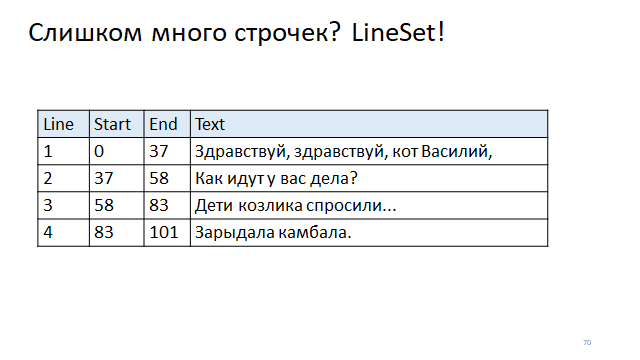
Write in the table the offset of the beginning of the lines and the end of the lines. And then, in order to find the beginning and end offset by the line number, you will need to refer to the index.
Interestingly, in the real world, both are used.
For example, Eclipse uses a wooden structure that, as you can see, works in logarithmic time for both reading and updating. And IDEA uses a table structure, for which reading is a fast constant, is an index call in the table, but rebuilding is rather slow, because you need to rebuild the entire table when you change the length of a line.
Still too many lines? Foldings!
What else is bad, what stumble on in text editors? For example, folding. These are pieces of text that can be “collapsed” and show something else instead.
These ellipses on a green background in the picture hide many characters behind us, but if we don’t look at them interestingly (as is the case, for example, with the longest boring Java docs or import lists), we hide them, collapse them into this dots.
And here again you need to understand when the region ends and when the region begins, which we need to show, and how to update all this quickly? How it is organized, I will tell a little later.
Too long lines? Soft wrap!
Also, modern editors can not live without Soft wrap. The picture shows that the developer opened the JavaScript file after minimization and immediately regretted it. This huge JavaScript string, when we try to show it in the editor, won't fit into any screen. Therefore, soft wrap it forcibly breaks into several lines and cram into the screen.
How it is organized - later.
Too little beauty
And finally, I still want to bring beauty in text editors. For example, highlight some words. In the picture above, the keywords are highlighted in bold blue, some static methods by the Italian, some annotations are also in a different color.
So how do you still keep and handle foldings, soft wraps and highlighting?
It turns out that all this, in principle, is one and the same task.
Too little beauty? Range highlighters!
To support all these features, all that we need to be able to do is to attach some text attributes, for example, color, font, or text for folding, according to a given offset in the text. Moreover, these text attributes need to be updated all the time in this place, so that they experience all sorts of insertions and deletions.
How is this usually implemented? Naturally, in the form of a tree.
Problem: too much beauty? Interval tree!
For example, here we have some yellow highlights that we want to keep in the text. We add these highlight intervals to the search tree, the so-called interval tree. This is the same search tree, but a bit trickier, because we need to store intervals instead of numbers.
And since there are both healthy and small intervals, then sorting them out, comparing with each other and folding into a tree is a rather trivial task. Although very widely known in computer science. Look then somehow at your leisure, as it is arranged. So, we take and put all our intervals into a tree, and then every text change somewhere in the middle leads to a logarithmic change of this tree. For example, inserting a symbol should result in updating all intervals to the right of this symbol. To do this, we find all the dominant vertices for this symbol and indicate that all their sub-bushes must be moved one character to the right.
Still want beauty? Ligatures!
There is also such a terrible thing - ligatures, which I would also like to support. These are different beauties like how the “! =” Sign is drawn in the form of a large “not equal” glyph and so on. Fortunately, here we look forward to a swing mechanism supporting these ligatures. And, in our experience, he apparently works in the simplest way. Inside the font is a list of all these pairs of characters that, when joined together, form some kind of clever ligature. Then, when drawing a line, Swing simply iterates over all these pairs, finds the necessary ones and draws them accordingly. If you have a lot of ligatures in the font, then, apparently, its display will proportionally slow down.
Brakes typing
And most importantly, another problem that occurs in modern complex editors is the optimization of taiping, that is, pressing the keys and displaying the result.
If you get inside Intellij IDEA and see what happens when you press a button, the next horror happens there:
- When we press the button, we need to see if we are in the completion popup to close the menu for the completion, if we, for example, type in some “Enter”.
- We need to see if the file is under some tricky version control system, like Perforce, which has to do some actions to start editing.
- Check if there is any special region in the document that cannot be printed, such as some autogenerated texts.
- If the document is blocked by an operation that has not ended, you need to complete the formatting, and then continue.
- Find an injected-document, if it exists in this place, because the language in it will be different, you need to type everything out completely differently.
- Call all plug-ins auto popup handler, so that they can type, for example, the closing and opening quotes in the right place.
- For info parameters, update the window so that it shows the necessary parameters if we moved there. In these plug-ins, call selection remove, so that they remove the selection as appropriate, depending on the language. And remove this selection physically by removing it from the document.
- Select from all plug-ins typed handler, so that they process the desired character in order to print a bracket on top of another bracket.
- Closing structural bracket handle.
- Run undo, count virtual spaces and start write action.
- Finally, insert a character in our document.
Hooray!
Hell no, that's not all. Delete the character if our buffer is full. For example, in the console, call a listener so that everyone knows that something has changed. Scroll editor view. Call some more stupid listeners.
And what happens now in the editor when he found out that the document had changed and DocumentListener had volunteered to us?
In Editor.documentChanged (), this is what happens:
- Update error stripe;
- Recalculate gutter size, redraw;
- Recount editor component size, send events when changing;
- Calculate the modified lines and their coordinates;
- recalculate soft wrap if the change affected him;
- Call repaint ().
This repaint () is just an indication for Swing that the region on the screen should be redrawn. A real redraw will occur when the Repaint event is processed by a Swing message queue.
That is, somewhere in half an hour, the processing queue of our event will come up, the corresponding component's repaint method will be
called , which will do the following: A bunch of different paint-methods are called that paint everything that is possible in this case.
Well, can we optimize all this?
This is all, to put it mildly, quite difficult. Therefore, we at Intellij IDEA decided to deceive the user.
Before all these horrors that count and write something down, we call a small method that draws this unfortunate letter right on the place where the user imprints it. And that's it! The user is happy, because he thinks that everything has already changed, but in actual fact - no! It is still just beginning under the hood, but the little letter is already burning in front of it. And so everyone is happy. This feature is called “Zero latency typing”.
Collaborative editors
Now there is such a fashionable thing - the so-called collaborative editors.
What it is? This is when one user is sitting in India, another - in Japan, they are trying to type something into the same Google Docs and want some predictable result.
What is special:
- Thousands of users;
- Big delay.
The peculiarity here is that a huge number of users can do this at the same time, and the signal can go from India to Japan for a very long time.
And because of this, usually in collaborative editors they use newfangled things like immobility. And they came up with different things, how to make sure that everything works as it should. These are a few criteria. The first criterion is the preservation of intention, the intention preservation. This means that if someone has imprinted the symbol, then sooner or later the symbol from India will come to Japan, and the Japanese will see exactly what the Indian intended. And the second criterion is convergence. This means that symbols from India and Japan will sooner or later be transformed into something the same for Japan and for India.
Operation transformation
The first algorithm that was invented to support this thing is called the “operation transformation”. It works like this. An Indian and a Japanese are sitting, typing something: one deletes a letter from the end, another draws a letter to the beginning. The Operation transformation framework sends these operations to all other places. He must understand how to surmount the operations that come to him in order to get at least something sensible. For example, when you simultaneously have a letter deleted and appeared. It should work more or less consistently both there and there, and come to the same line. Unfortunately, as can be seen from my confused explanation, this is a rather complicated matter.
When the first implementations of this framework began to appear, astonished developers discovered that there is a universal example that breaks everything. This unfortunate example was called the “TP2 puzzle”.
One user draws some characters to the beginning of the line, another one removes all this, and the third draws to the end. After all this Operation transformation tries to merge into one and the same, then this line should, in theory, be obtained here (“DANA”). However, some implementations did this (“NADA”). Because it is not clear where to insert it. The picture above shows at what level this whole science is about the Operation transformation, if because of such a primitive example, everything broke.
But despite this, some people still do it, like Google Docs, Google Wave and some distributed editor of Etherpad. They use the Operation transformation despite the problems listed.
Conflict-free replicated data type
The people here had their heads brained and decided: “Let's make it easier than OT!” The number of any tricky combinations of operations that need to be processed and merged together grows quadratically. Therefore, instead of processing all the combinations, we will simply send our status along with the operation to all other hosts so that it can be merged into the same text with a guarantee of 100%. This is called "CRDT" (Conflict-free replicated data type).
For this to work, you need a state and a function, which of the two states together with the operation makes a new state. Moreover, this function should be commutative, associative, idempotent and monotone. And then it is clear that everything will work simply and reinforced. Because of these draconian restrictions on the function, we are no longer afraid of disturbing the order (the function is commutative), priority (associative), and packet loss in the network (idempotency and monotony).
Are there such functions in nature and how can they be applied?
Yes. For example, for the case of so-called G-counter'ov, that is, counters that are only growing. You can write a function for this counter that is truly monotonous, and so on. Because if we have the operation “+1” from Japan, the other “+1” from India, it is clear how to make a new state out of them - just add “2.” But it turns out that in the same way an arbitrary counter can be made, which can be incremented and decremented. To do this, it is enough to take one G-counter, which grows up all the time, and apply all increment operations to it. And all the decrements are applied to another G-counter, which will grow down. To get the current status, you just need to subtract their contents, and we get the same monotony. This is all possible to extend to arbitrary sets. But the most important thing is for arbitrary strings. Yes, editing arbitrary strings can also be made CRDT. Turns out it's pretty easy.
Conflict-free replicated inserts
First, let's name all the characters in the document so that they are always uniquely identifiable, even after all edits. Well, for example, together with each letter we will store a unique number.
Now, instead of sending all people the information that we insert a symbol at some offset, we will instead say which symbols we will insert between them. And then it is clear that there can be no discrepancies, wherever we insert, we will definitely know the place, even after any other operations. For example, instead of sending an operation that we want to insert “RLU” at offset 2, we will send information that we insert “RLU” between this “Y” and this “R”.
Conflict-free replicated deletes
You can also implement and delete characters. Since all of our characters are uniquely renamed, we simply say exactly which character needs to be deleted, instead of some kind of offsets. But instead of physically deleting these characters, we’ll mark them as deleted. In order for subsequent parallel insertions or deletions to know, if they affect these deleted characters, exactly where they should go.
And it turns out that this whole new-fangled science works.
Conflict-free replicated edits
And, in fact, CRDT is even implemented somewhere, for example, in Xi-Editor, which will be inserted into their newfangled Fuchsia secret operating system. To be honest, I don’t know of other examples, but it definitely works.
Zipper
I would also like to tell you about the thing that is used in this new, immutable world called “Zipper”. After we made our structures immutable, some nuances of working with them appeared. Here, for example, we have our immutable tree with text. We want to change it, (by “change” here, as you understand, I mean “create a new version”). Moreover, we want to change it in a particular place and quite actively. In editors, this is quite common when we constantly print, insert and delete something at the cursor. To do this, the functionaries came up with a structure called Zipper.
It has the concept of the so-called cursor or the current place for editing, while maintaining full immunity. Here is how it is done.
Create a Zipper for our document, which contains a line for editing (“Well need to”). Call the operation on this Zipper to move along the line to the editing place. In our case - go down to the top right down. To do this, we create a new vertex (red) corresponding to the current vertex, attach to it links to the child vertices from our tree. Now, to move the Zipper cursor, we go down and down and create a new vertex instead of the one on which we stood. At the same time, add a link to the top up, so as not to forget where you came from (red arrows). Having thus reached the place of editing, we create a new sheet instead of the edited text (red rectangle). Now go back, going along the red arrows upwards and replacing them on the way to the correct links to the child vertices.
Notice how the cursor helps us edit the current piece of wood.
What conclusions did I want to convey to you? First, oddly enough, in the topic of text editors, despite its stuffiness, there are all sorts of interesting things. Moreover, in the same topic sometimes new, sometimes unexpected discoveries appear. And thirdly, sometimes they are so new that they do not work the first time. But it is interesting and you can warm up. Thank.
→ Repository
Links
Zipper data structure
How does CRDT in Xi Editor
In general, a tree-like data structures for text
What twists in the atom
After the report was a long time, and Microsoft had to remember their roots and to rewrite the Visual Studio Code editor on the Table Piece .
And in general, for some reason, many people were drawn to experiments .
Want even more powerful reports, including Java 11? Then we are waiting for you on Joker 2018 . Josh Long, John McClean, Marcus Hirt, Robert Scholte and other equally cool speakers will be speaking this year. 17 days left before the conference. Tickets on site.