New drives - what does the coming day bring to us?

If in the autumn they consider chickens in agriculture, then in the IT industry at this time traditionally announce new products. And although by the end of autumn there are far chances that there will still be interesting announcements, the already announced is quite enough to declare it worthy of attention. Moreover, some trends are very curious.
At first glance, everything is pretty obvious: hard drive manufacturers staged another volume race, enthusiastically announcing 6, 8 and even 10 TB models. But everything lies in the details, and to be more precise - in the specifics of the use of these discs. Immediately make a reservation that we will talk about the server aspects of disk usage.
So what is there in the details?
First, a few words about the general trend: all the few remaining hard drive manufacturers are diligently expanding their product lines. More recently, the choice was simple: in addition to the volume, it was enough to determine the speed of rotation of the plates and the interface, after which the choice was reduced to one or two series. What now? Enterprise, Cloud, AV, NAS, Green, Performance. The reason for this diversity is simple: disk manufacturers are moving away from universality in order to reduce their own production costs, leaving only the minimum set of features that is needed in the drives. Well, a bonus of this approach is the storm of marketing materials that continuously pour on the user.
Well, now let's talk about the specifics. Let's start with WD.

Wd ae
Before users had time to discuss the Red Pro series, intended for a very narrow sector of the “not very large NAS” market, the company rolled out the absolutely wonderful Ae series, which became the fourth series of disks for data centers. The “miracle” of the series is that the volume of the disk (and it is only one in the series so far) is floating and currently ranges from 6 to 6.5 TB. As far as they were able to make the party, they did so. Obviously, such an unusual solution can only be sold in “volumes” or in batches, and not “in pieces” at all, otherwise buyers will not understand why a neighbor has more for the same money. The manufacturer itself is talking about the parties "from twenty discs."
The second interesting feature of these discs was what loads they are designed for. Open press releaseand read that MTBF is only 500,000 hours — two to four times less than what is usually claimed for server disks. But the most interesting thing is nearby: for this drive, the annual load is assumed to be 60 TB. Yes, yes, no mistake, 10 rewrites of the total volume per year.

Disk shelf ETegro Fastor JS200 G3
The answer to these values is simple: the disk is designed to store cold, one might even say, ice data. In fact, we have a disk designed to replace tape libraries, whose task is to sleep 95% of the time. The reason for this transition was the cost of data storage, which on disks with 7200 rpm is about 5-6 cents per gigabyte. This is still more expensive than storing data on tapes, but is already reasonably affordable for most for the price. And if the speed of accessing data on a tape will be a few seconds at best, then data can be obtained from a disk in a disk shelf in less than a hundred milliseconds, while there is no difficulty in increasing the number of disks, expanding the shelves by at least an entire rack.

Seagate Enterprise Capasity, 8 TB

HGST, 10 TB The
following “interestingness” was provided to us by Seagate and HGST. The first announced that they were already shipping 8-TB hard drives, to which the second noticed that if you add to this their proprietary technology , which is already used in the Ultrastar He6 and He8 series , to fill disks with helium, then you can also get 10 TB from a standard-sized drive. What unites these two innovations is that they use Shingled Magnetic Recording (SMR) technology.
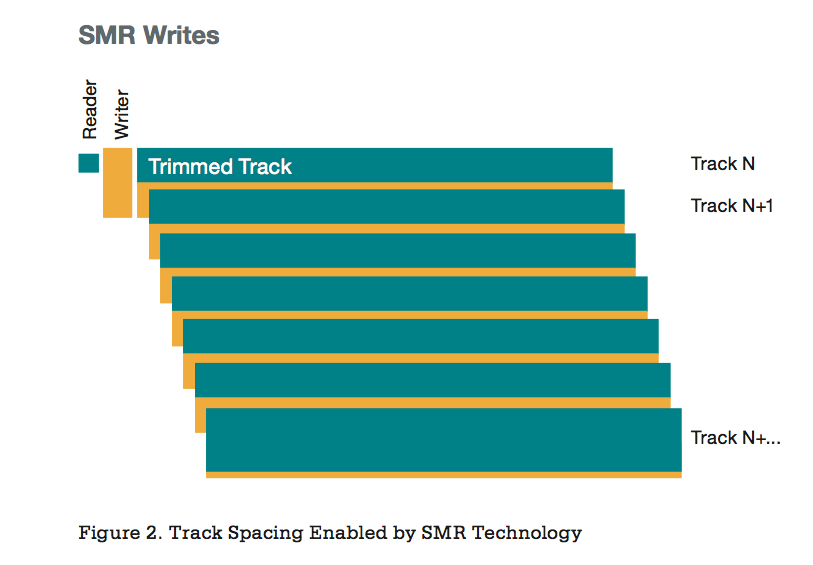
The essence of tiled writing
Recall that SMR technology uses the fact that the width of the head for reading in discs is less than that of the head for writing. Therefore, you can record tracks with overlapping them, leaving “on the surface” only a relatively narrow area of each track, sufficient for reliable reading. At the same time, recording is carried out by tracks of large width with high power fields. In total, this allows to increase the recording density due to the elimination of the track gap while maintaining reliability.
Talk about it has been going on for a very long time, but everything goes to the fact that 2015 will be the year of its real publication. This has been a long time, it’s enough to recall, for example, this rather old schedule:

Development of hard disk technologies
The technology itself is very beautiful, because it allows you to increase the density without a radical change in production equipment, following the same path as it once went through when inserting disks with 4-kB sectors (Advanced Format). But it has one drawback: as soon as you need to modify the data, that is, make a record in the area around which there is data, how you come across the fact that this erases this very neighboring data.
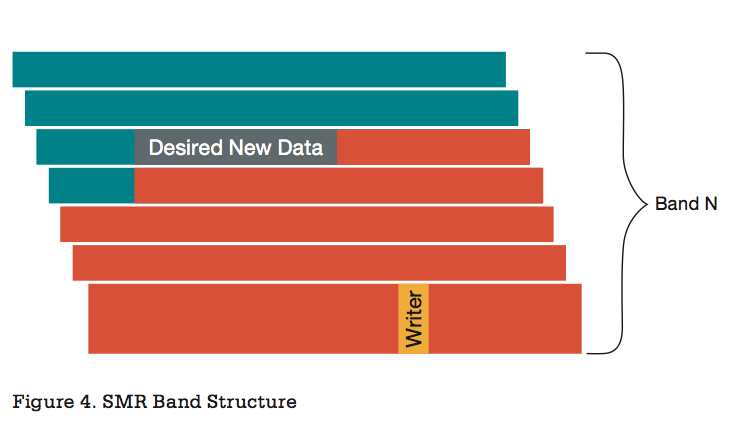
Overlay Recording Area
The way out of this situation is obvious: the tiles are laid with ribbons consisting of several tracks. And between the tapes provide a standard track gap. And when recording, you need to read, modify, and then write back part of the tape (from the modified data to the end of the tape). On the one hand, the tape should be wide enough so that the effect of the tile overlaying of the tracks is still noticeable, and on the other hand, the large tape should be read longer, written longer, and stored somewhere. The manufacturers of hard drives have not yet disclosed implementation details, but presumably the tape size is several tens of tracks, and each track, for a minute, is now more than 1 MB.
A little mathematics to clear: it’s not so difficult to find out the approximate amount of data on a track: take the disk speed in MB / s, divide by the rotation speed and multiply by the same 60 seconds per minute. Get the number of megabytes read per revolution ... that is, per track. So, for the current 4-TB drives at 7200 rpm, these values are about 180 MB / s and 1.5 MB per track, respectively.
I think everyone has already understood what we're getting at. Yes, we get a terrible response to records with random addressing of data, on average we will read several tens of megabytes, and then write them back, which will take tangible fractions of a second. Not as terrible as on tape drives, but you'll have to forget about the usual milliseconds. With reading, of course, everything will be quite traditional, which means that the disks are quite suitable for any use, implying a WORM (Write Once, Read Many) scheme or storage of cold data. Theoretically, disk manufacturers can creatively learn from the experience of using SSDs and adapt TRIM and address translation for themselves, but so far they are only talking about this at the theory level.
There is another important consequence of such an organization of hard drives. And it consists in the fact that it seems that switching to such disks will completely kill RAID arrays with writing checksums. The sizes of the recording blocks there are much smaller than the size of the tape in the SMR, which means that with any overwriting of old data, we get a monstrous penalty. An “excellent” addition to the fact that RAID5 on arrays of modern 7200 rpm drives with a typical bit rate of unrecoverable errors of 1 by 10 ^ 15 already becomes an unreliable storage option with an array size of more than 100 TB - such an error at least once but will happen during rebuilding the array. But such a volume is just one disk shelf. The cherry on the cake is the completely inhuman time of rebuilding such arrays, during which the disk subsystem works with reduced performance. So there is every chance that in the near future the most popular way to store data will be numerous disk shelves with JBODs, the data on the disks of which will be duplicated by the OS forces.
As for the disk subsystem for "hot" data, here for many years now the SSD ball has ruled and no radical changes are expected. Depending on the amount of data, everything will be decided either by local drives for the server, such as the HGST Ultrastar SN100 or Intel SSD DC P3700, fortunately, their volume has already reached 2 TB, or by whole all-flash disk shelves. The first ones moved to the NVMe interface in full, providing minimal delays and more efficient operation under really high loads (for more details, see our previous article) The developers of the NVMe protocol do not waste time and have already announced the development of the NVMe over Fabrics standard, which will allow you to use all the advantages of the NVMe protocol when working on communication media such as Ethernet using RDMA, InfiniBand, and Intel Omni Scale Fabric. And the Fiber Channel Industry Association (FCIA), by the way, has already organized a separate working group for this business. But this is a matter of a somewhat distant future, but in the near future we have seen a clear migration to the SAS 12G standard, under which the infrastructure in the form of controllers and expanders began to appear actively.