Cybercortex System of expanded perception and thinking
Good afternoon!
Cybercortex.org is an open source project. It is at the start-up stage and is seen as an opportunity to concentrate and coordinate the efforts of companies and developers to solve tasks for the development of human intelligence. To introduce new forms of strengthening thinking and accelerating productive communication into everyday life. Therefore, everyone who is somehow interested in the issue is invited to cooperate.
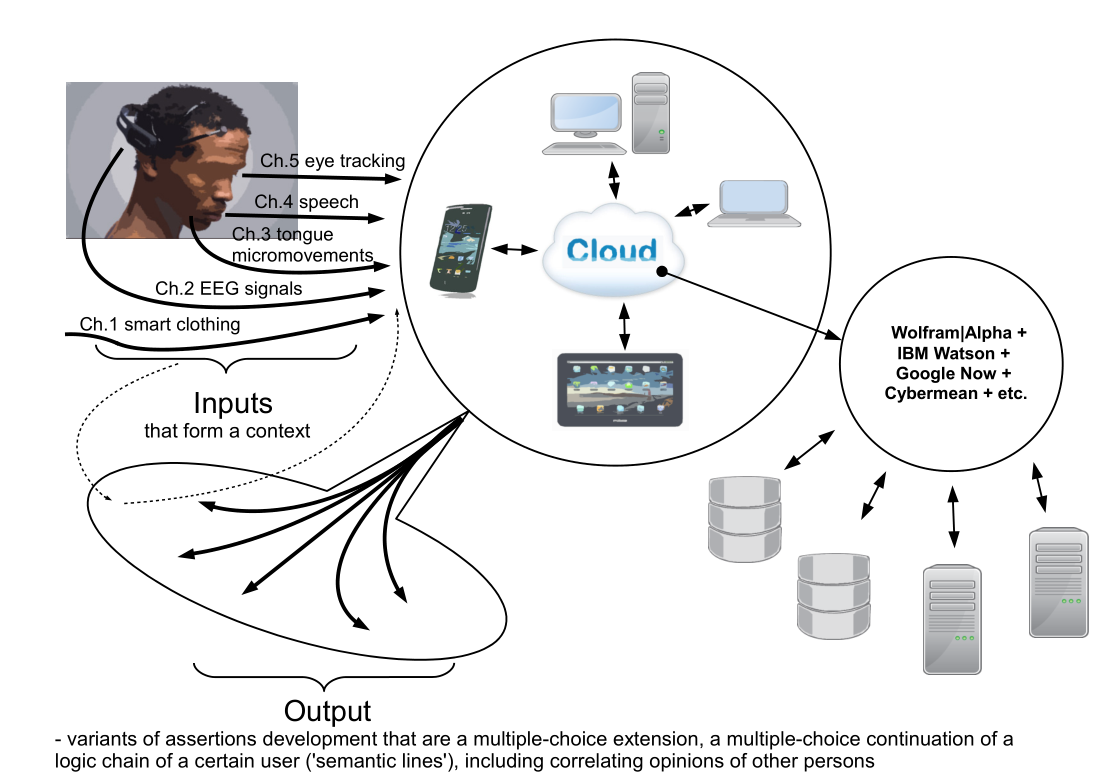
The following is a description of the first module of the Cybermean algorithm, the “core” of Cybercortex. If the logic described below would be adequate to the Habrachians, then we could continue the description and discussion of the Cybermean and Cybercortex modules as a whole. Also, at the end of the post, in addition to the logic of the first module, an image of the communication of interfaces within the framework of Cybercortex is provided as an additional visual material characterizing the subject of the project.


Our task is to obtain the most complete selection of synonyms and definitions of relevant * words included in the compared texts.
So, we make a selection of synonyms and definitions for text 1. Then we do the same for text 2 (hereinafter both texts, since there can be any number of them, are designated as text N).
Then we can compare the obtained samples.
The more matches of words (source words, synonyms and keywords; see below) in these samples, the closer the texts in meaning. Not in terms of statements for or against anything, but in terms of topics, in terms of its subject.
Sampling
We can perform the operation of searching for synonyms for each relevant source word of the text N first in the synonyms dictionaries of the same language (by performing the corresponding operations to normalize the text; first of all, stemming; in scheme 2, this is a separate column of blocks with the same L_number ending). We can also perform a search operation for definitions for each word of the text N. And then perform a search operation for synonyms for keywords definitions (keywords are identified using frequency [for example, similar LSA], morphological and lexical analysis of the maximum possible number of definitions presented in dictionaries ; keywords and synonyms of keywords are presented in scheme 3.1 and 3.2).
At the same time, we can translate each relevant word into a foreign language (from language 1 to language 2 (N)) and only then sequentially perform the same operations, and we can also translate into a foreign language (into 2 (N) language) words, which will appear during operations with language 1. Complementing operations on language 2 (N) on their own. That is, to translate keywords and their synonyms from language 1 into a foreign language (language 2 (N)) and then, if some words would not be there without this operation, to build activity taking into account these words (this logic is presented in Figure 4) .
As a result, for each relevant word of the text N we get a set of samples, the number of which for each word is equal to the number of languages included in the system.
- * prepositions and similar formations can be considered irrelevant; “Words” further in the meaning of “relevant words”


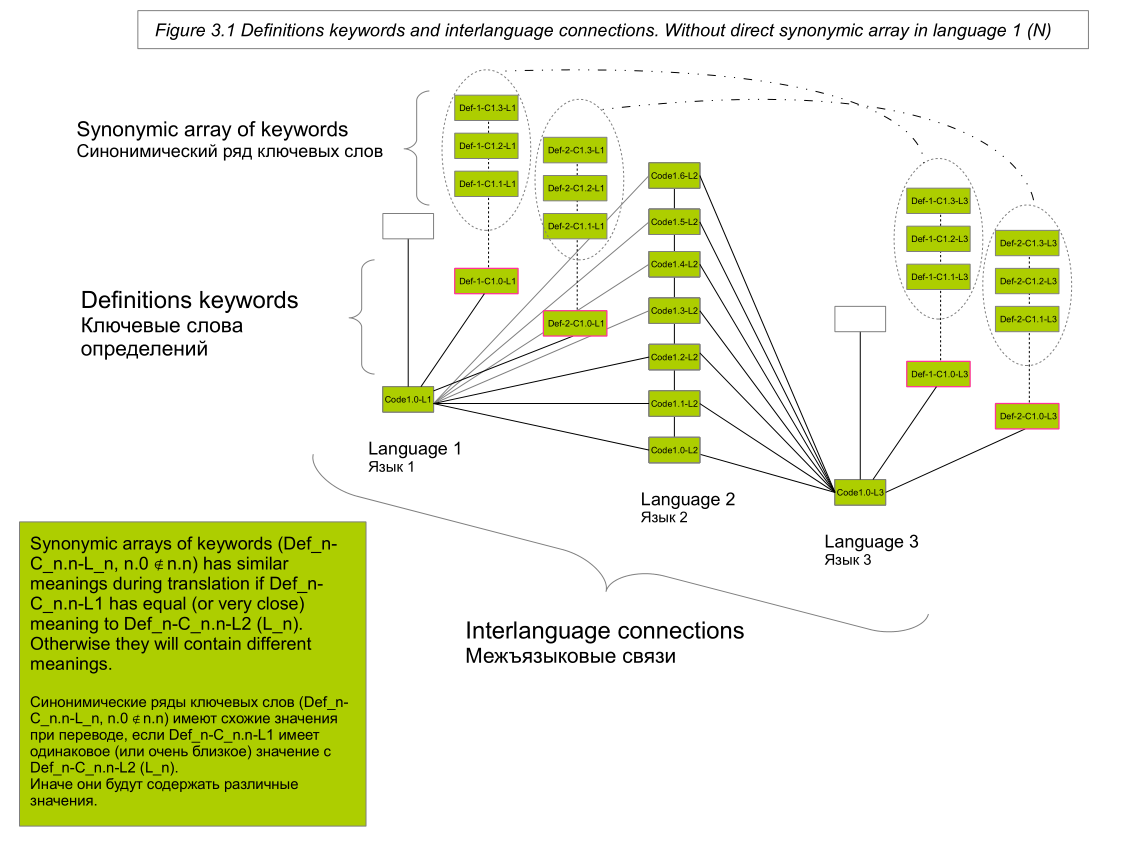
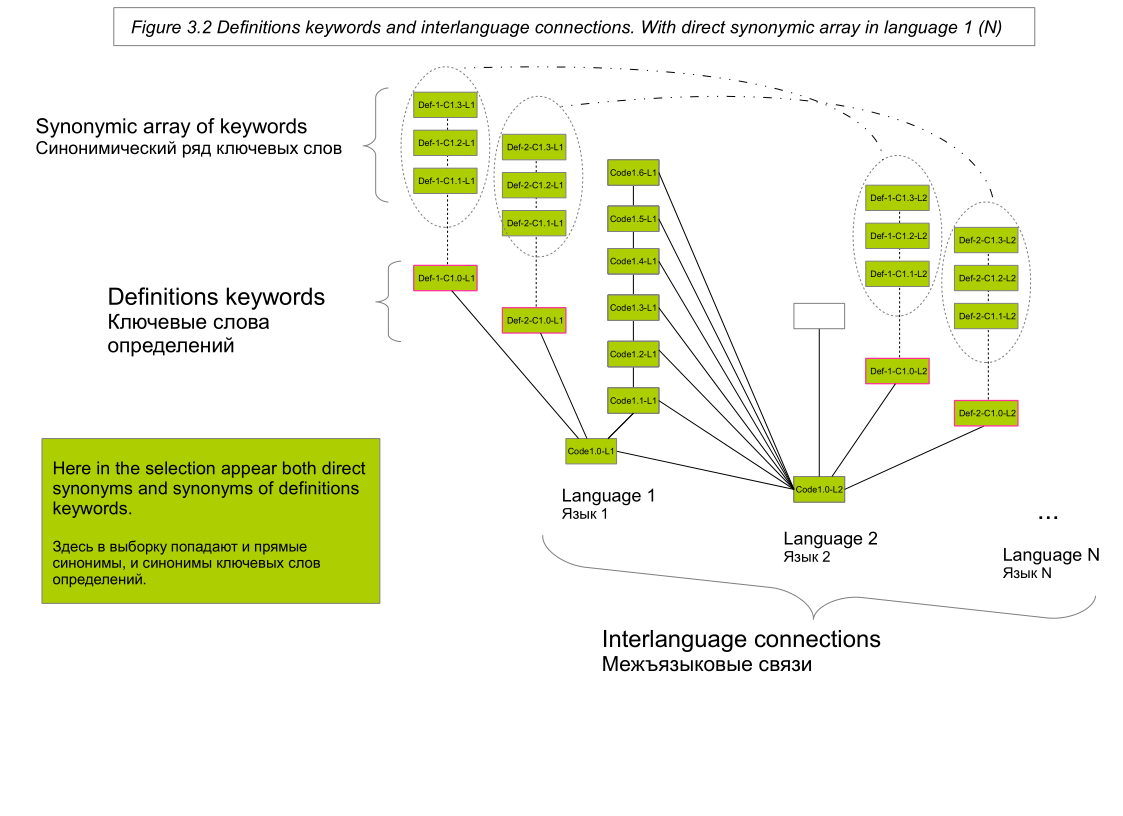
So, when we meet a word in the text, then the given word and all the words that are associated with it through vertical connection (direct synonymic series, keywords of definitions, synonymous series of keywords ) and through horizontal interlanguage communication.
Thus, the sample contains relevant related words from dictionaries around the world (from those that are integrated into the system), and not just dictionaries of the country of the language in which the text is formulated.
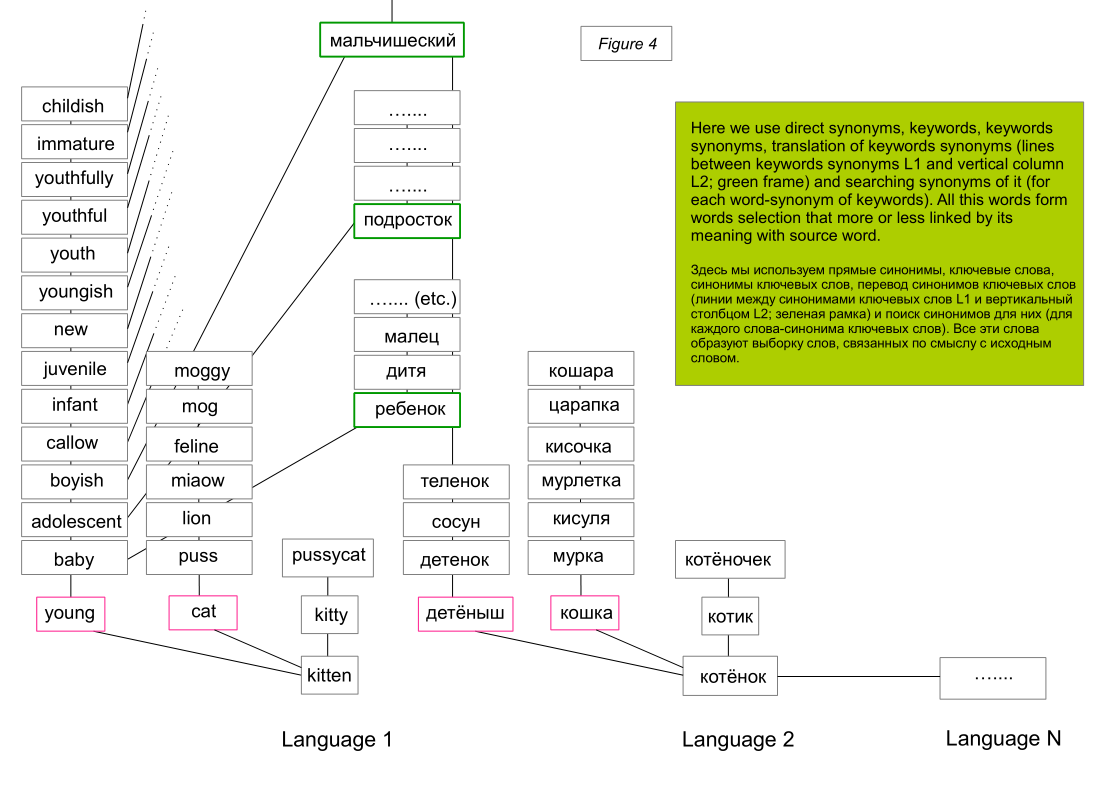
It can be assumed that if a word is found in different languages in the list of synonyms, then it is more synonymous with the original word than if the synonym is found in only one language.
The operations above allow us to refer to the whole spectrum of synonyms that are close in meaning, contained in dictionaries, but placed incorrectly in them. That is, the situation is neutralized when a person sees a synonym, but a typical national dictionary does not.
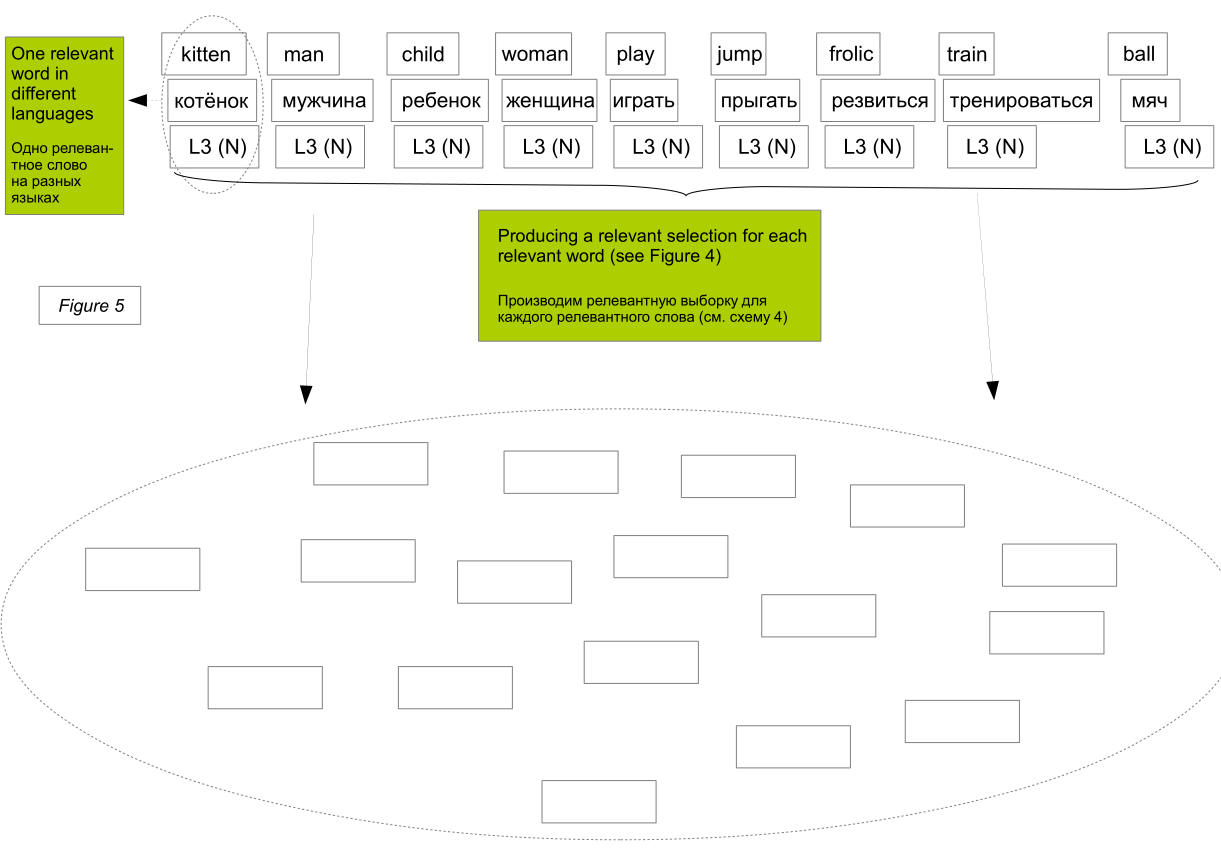
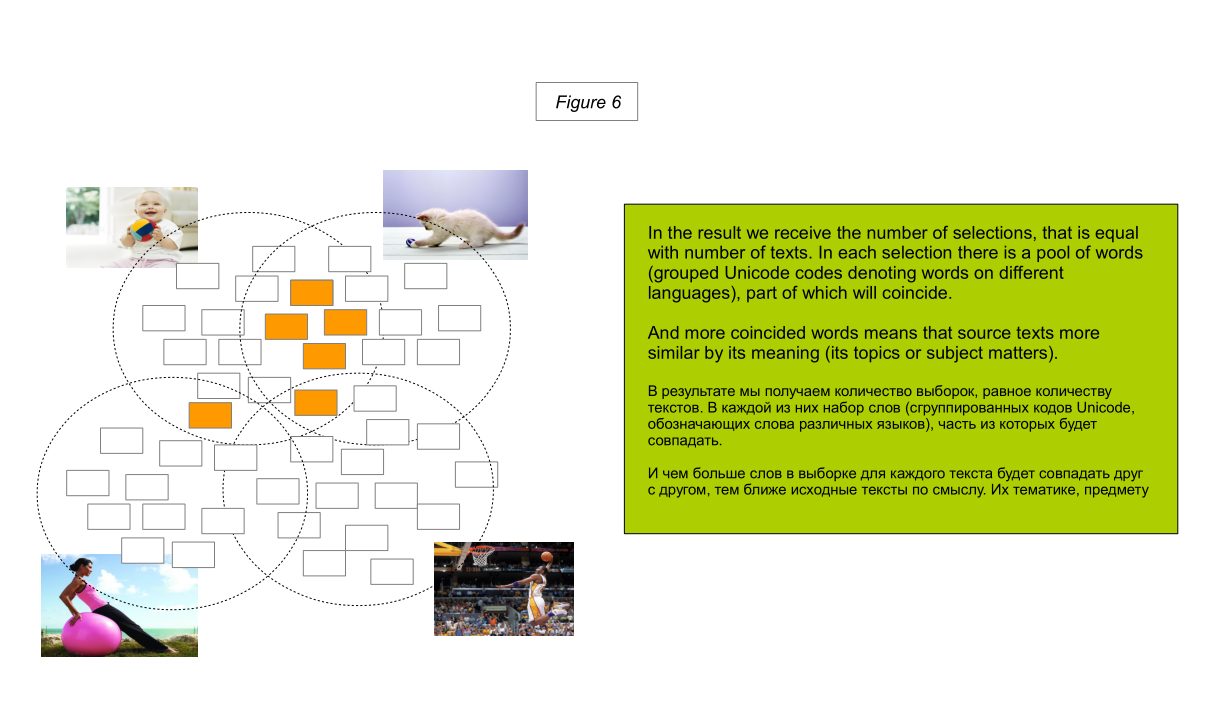
At the same time, “a man jumps with the ball” can be read as “a man plays with the ball”. This is reflected in the algorithm in the fact that in the samples of direct and indirect synonyms (synonyms of keywords, translated synonyms of keywords) of the words “jump”, “frolic” and “play” we find a certain number of identical words.

However, in this case, it is decisive that the words “child” and “kitten” have more coincidences in indirect synonyms than that of a man, a woman - a child or a man, a woman - a kitten.
Moreover, if we applied the operation of finding keywords to synonyms for keywords (i.e., as an iteration of a new level), then we would see that the child, man and woman are people. A kitten is an animal.
That is, in samples of a new level, a child, a man and a woman would have more coincidences than each of them with a sample of a kitten.
This would be the next criterion for the separation of statements according to their meaning, but smaller in their impact, since it was revealed at this additional level of iterations.
Conclusion
This simple example demonstrates the principle of text analysis, which allows us to determine the semantic proximity of texts. The more characters (words) in the text, the easier it is to differentiate texts that are similar in meaning to it. Since the more unique will be the selection of related words.
This principle is the first module of the Cybermean algorithm. Based on this principle, the second and third Cybermean modules can work.
***
Image from interface material:
Website: www.cybercortex.org
Cybercortex.org is an open source project. It is at the start-up stage and is seen as an opportunity to concentrate and coordinate the efforts of companies and developers to solve tasks for the development of human intelligence. To introduce new forms of strengthening thinking and accelerating productive communication into everyday life. Therefore, everyone who is somehow interested in the issue is invited to cooperate.
The following is a description of the first module of the Cybermean algorithm, the “core” of Cybercortex. If the logic described below would be adequate to the Habrachians, then we could continue the description and discussion of the Cybermean and Cybercortex modules as a whole. Also, at the end of the post, in addition to the logic of the first module, an image of the communication of interfaces within the framework of Cybercortex is provided as an additional visual material characterizing the subject of the project.
Our task is to obtain the most complete selection of synonyms and definitions of relevant * words included in the compared texts.
So, we make a selection of synonyms and definitions for text 1. Then we do the same for text 2 (hereinafter both texts, since there can be any number of them, are designated as text N).
Then we can compare the obtained samples.
The more matches of words (source words, synonyms and keywords; see below) in these samples, the closer the texts in meaning. Not in terms of statements for or against anything, but in terms of topics, in terms of its subject.
Sampling
We can perform the operation of searching for synonyms for each relevant source word of the text N first in the synonyms dictionaries of the same language (by performing the corresponding operations to normalize the text; first of all, stemming; in scheme 2, this is a separate column of blocks with the same L_number ending). We can also perform a search operation for definitions for each word of the text N. And then perform a search operation for synonyms for keywords definitions (keywords are identified using frequency [for example, similar LSA], morphological and lexical analysis of the maximum possible number of definitions presented in dictionaries ; keywords and synonyms of keywords are presented in scheme 3.1 and 3.2).
At the same time, we can translate each relevant word into a foreign language (from language 1 to language 2 (N)) and only then sequentially perform the same operations, and we can also translate into a foreign language (into 2 (N) language) words, which will appear during operations with language 1. Complementing operations on language 2 (N) on their own. That is, to translate keywords and their synonyms from language 1 into a foreign language (language 2 (N)) and then, if some words would not be there without this operation, to build activity taking into account these words (this logic is presented in Figure 4) .
As a result, for each relevant word of the text N we get a set of samples, the number of which for each word is equal to the number of languages included in the system.
- * prepositions and similar formations can be considered irrelevant; “Words” further in the meaning of “relevant words”
So, when we meet a word in the text, then the given word and all the words that are associated with it through vertical connection (direct synonymic series, keywords of definitions, synonymous series of keywords ) and through horizontal interlanguage communication.
Thus, the sample contains relevant related words from dictionaries around the world (from those that are integrated into the system), and not just dictionaries of the country of the language in which the text is formulated.
It can be assumed that if a word is found in different languages in the list of synonyms, then it is more synonymous with the original word than if the synonym is found in only one language.
The operations above allow us to refer to the whole spectrum of synonyms that are close in meaning, contained in dictionaries, but placed incorrectly in them. That is, the situation is neutralized when a person sees a synonym, but a typical national dictionary does not.
At the same time, “a man jumps with the ball” can be read as “a man plays with the ball”. This is reflected in the algorithm in the fact that in the samples of direct and indirect synonyms (synonyms of keywords, translated synonyms of keywords) of the words “jump”, “frolic” and “play” we find a certain number of identical words.
However, in this case, it is decisive that the words “child” and “kitten” have more coincidences in indirect synonyms than that of a man, a woman - a child or a man, a woman - a kitten.
Moreover, if we applied the operation of finding keywords to synonyms for keywords (i.e., as an iteration of a new level), then we would see that the child, man and woman are people. A kitten is an animal.
That is, in samples of a new level, a child, a man and a woman would have more coincidences than each of them with a sample of a kitten.
This would be the next criterion for the separation of statements according to their meaning, but smaller in their impact, since it was revealed at this additional level of iterations.
Conclusion
This simple example demonstrates the principle of text analysis, which allows us to determine the semantic proximity of texts. The more characters (words) in the text, the easier it is to differentiate texts that are similar in meaning to it. Since the more unique will be the selection of related words.
This principle is the first module of the Cybermean algorithm. Based on this principle, the second and third Cybermean modules can work.
***
Image from interface material:
Website: www.cybercortex.org