By city and by weight or how we balance between CDN nodes
 When you have grown so much that nodes appeared in different cities, the task of distributing the load between them arises. The tasks of such balancing may be different, but the goal, as a rule, is the same: to make it good. I got around to talk about how it's usually done, and how it is done in ivi.ru .
When you have grown so much that nodes appeared in different cities, the task of distributing the load between them arises. The tasks of such balancing may be different, but the goal, as a rule, is the same: to make it good. I got around to talk about how it's usually done, and how it is done in ivi.ru . In a previous article, I said that we have our own CDN, while carefully avoiding the details. It's time to share. The story will be in the style of finding a solution as it might be.
Looking for an idea
What could be the criteria for geo-balancing? This list comes to my mind:
1) reduction of delays when loading content
2) spreading of load on servers
3) spreading of load on channels
Okay, since in the first place there is a reduction in delays, you need to send the user to the nearest node. How can this be achieved? Well, here we have the Geo-IP base lying around, which we use for regional advertising binding. Maybe adapt it to the case? You can, for example, write a passman who will be in our central data center, determine the region of the user who came to him and answer that redirect to the nearest node. Will it work? It will be, but bad! Why?
Well, firstly, the user has already come to Moscow only to find out what he does not need in Moscow. And then he needs to make a second call already at the local site for the required movie file. And if a movie is cut into chunks (chunk, these are such small small files with small pieces of film)? Then there will be two requests for each chunk. Oh oh oh! You can, of course, try to optimize it all and write a code on the client that will go to Moscow only once per movie, but this will make this code heavier. And then it will have to be duplicated on all types of supported devices. Excess code is bad, so refuse!
Quite a lot of CDNs that I observed (I can’t say that I tested) use redirect balancing. I think an additional reason why they do this is billing. After all, they are commercial people, they need to serve those and only those who paid them. And such a check on the balancer takes extra time. I am sure that it was precisely this approach that led to the result I mentioned last time - sites with CDN load more slowly. And we completely ignored this method from the very beginning.
And if by name?
How can we make geo-balancing so that it would not be necessary to run once again to Moscow? But let me! Anyway, we go to Moscow in any way - in order to break the domain name! But what if the server response takes into account the user's location? Yes easily! How can I do that? You can, of course, manually: create several views and return for different users different IP addresses for the same domain name (we will make a dedicated FQDN for this ). Option? And then! Only have to support manually. It is possible to automate - for bind, for example, there is a module for working with the same MaxMind. I think there are other options.
To my great surprise, DNS balancing is now the most common way. Not only small firms use this method for their needs, but also large reputable manufacturers offer complex hardware solutions based on this method. So, for example, F5 Big IP works. Again, they say that this is how Netflix works. Why amazement? Mentally trace the chain of the DNS query from the user.
Where does the package get from the user PC? As a rule - to the provider DNS server. And in this case, if we assume that this server is close to the user, then the user will be taken to the node closest to him. But in a significant percentage of cases (even a simple sample at our office gives a noticeable result) it will be either a universal evil - Google DNS, or Yandex.DNS, or some other DNS.
Why is this bad? Let's look further: when such a request arrives at your authorized DNS, whose source IP will be? Server! No customer! Accordingly, the balancing DNS will in fact balance not the user, but the server. Given that the user can not use the server in his own region, the choice of a node based on this information will not be optimal. And then worse. Such a Google cache caches the response of our balancing server, and will return it to all clients, already without taking into account the region (view is not configured in it). Those. fiasco. By the way, the manufacturers of such equipment themselves, at a personal meeting, I fully confirmed the presence of these fundamental problems with DNS-balancing.
To tell you the truth, we used this method at the dawn of the construction of our CDN. After all, we did not have experience with our own nodes. System integrators immediately tried to sell many cars of equipment for such an amount for a sum with a large number of zeros. A DNS-based solution is, in principle, understandable and workable. From our operating experience, all these negative aspects have surfaced. In addition, the node’s conclusion to preventive maintenance is damn complicated: you have to wait until the caches on all devices go bad on the way to the user (by the way, it turns out that a huge number of home routers completely ignore TTL in DNS records and store the cache until the power goes out). And what will happen if the node suddenly shuts down - it's so scary to think! And one more thing: it is very difficult to understand from which node the subscriber is serviced when he has a problem. After all, it depends on several factors: in which region it is located, and which DNS it uses. In general, there are a lot of ambiguities.
Ping or not ping?
And here comes the “second” (in case someone wonders why I started first): on the Internet, geographically close elements can be very far from the point of view of traffic flow (remember from last time “from Moscow to Moscow - through Amsterdam "?). Those. geo-IP database is not enough to decide on the direction of the user to any specific node. You must also consider the connectivity between the provider to which the CDN is connected and the user. In my opinion, here, on the hub, I came across an article that mentioned the manual maintenance of a database on connectivity between providers. Of course, it can work for a significant part of the time, but the rationality in such a solution is clearly absent. Channels between providers may fall, may become clogged, may be disconnected due to a break in relations.
How can we evaluate the quality of the channel to the user? By pinging, of course! And we will ping the user from all our nodes - because we need to choose the best option. We’ll save the results somewhere for the next time - because if you wait until all the user nodes are pinged, they just won’t wait for the movie. So the first time the user will always be served from a central site. And if there are bad channels from Chukotka to Moscow - well, that means there will be no second time. By the way, users do not always respond - new home routers and all sorts of Windows 7 do not respond to echo requests by default. So these will also always be served from Moscow. To mask these problems, let's complicate our algorithm for calculating the best node by aggregating users over subnets.
And strangely enough, “industrial” solutions use just such a method of determining a connectivity map - pinging of specific users. I completely ignore the fact that terminal devices do not respond to ICMP pings, and many providers (especially in the west) cut out all ICMP to the root (I myself like to filter it well). And all these industrial solutions fill the Internet with meaningless pings, actually forcing providers to filter ICMP. Not our choice!
At this point, I felt very sad. After all, the geo-balancing methods that I found on the Internet were not very suitable for our goals and objectives. And they at that moment could already be formulated as:
1. The subscriber must first contact the nearest site, and only if there is no necessary content, then to the next, larger
2. The solution should be independent of the settings for a particular user
3. The solution should take into account the current connectivity from the user to the CDN
4. The solution should provide technical staff ivi the opportunity to understand which node the user is servicing
Enlightenment
And then I came across the word anycast. I didn’t know him. It somehow reminded me of unicast, broadcast and my favorite multicast. I started googling and it soon became clear that this was our choice.
If you briefly describe anycast, then it will be like this: "Hack, violation of the principle of uniqueness of an IP address on the Internet." Due to the fact that the same subnet is announced from different places on the Internet, taking into account the interaction of autonomous systems, and if our different nodes come in contact with the same provider’s autonomous network, due to the IGP metric or its equivalent, the nearest node will be selected. See how the assembled system (autonomous numbers are indicated as an example, although not without respect for colleagues) actually looks like:
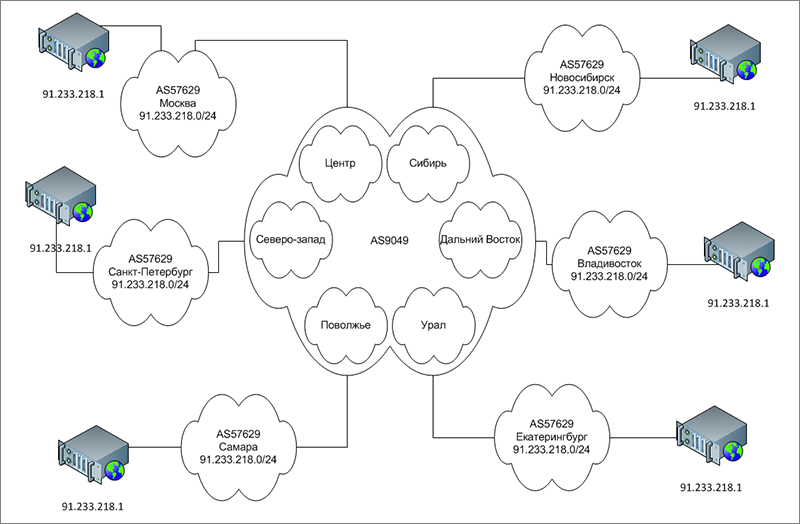
And how does it look from the point of view of BGP routing. It is as if there are no non-unique IP addresses, but there are several communication channels in different cities:

And then let the provider network choose what it is best to do. Since not all telecom operators are enemies of their own network, you can be sure that the user will get to the nearest CDN.
Of course, BGP in the current incarnation does not contain information about congestion channels. But such information is provided by the network engineers of the provider. And if they send their traffic to a particular channel, then they have a reason to do so. Due to the specifics of anycast, our traffic will come from the direction where they sent the packets.
The final diagram looks like this:
1. The user accesses the dedicated FQDN for the content
2. This name resolves to an address from anycast range
3. The user gets to the nearest CDN node (from the network point of view)
4. If there is such content on the node, the user receives it from the node (that is, one request !! !)
5. If there is no such content on the host, then the user receives HTTP-redirect to Moscow
Based on the fact that the localization of content on the host is high (single-server hosts do not count), most of the user requests will be served from the nearest host, t. e. with minimal delays. And although this does not matter to the user (but it is very important for providers) - through non-trunk communication channels.
Anycast and its limitations are very well described in RFC4786. And this was the first and so far the last RFC, which I read to the end. The main limitation is the ability to rebuild routes. Indeed, if packets from the middle of a TCP session suddenly go to another host, then RST will fly back from there. And the longer the TCP session, the higher the likelihood of this. To watch a movie, this is very critical. How did we get around this? In several areas:
1. Part of the content is available in the form of chunks. Accordingly, the time of the TCP session is insignificant
2. If the player could not download a piece of the film due to a session break, the player does not show an error, but makes another attempt. Given the large buffer (10-15 seconds), the user does not notice anything at all.
Another (and at times, an extremely unpleasant limitation) is that the CDN operator based on anycast does not have direct control over which node the user is served from. In most cases, this is good for us (let the operator decide where his channels are thicker). But sometimes you need to push in another direction. And the best part is that it is possible!
Balancing!
There are several ways to achieve the necessary distribution of requests between nodes:
1. Writing to networkers - for a long, painful search for contacts (everyone somehow does not want to run RIPE DB), annoys them and you have to talk a lot about anycast. But in some cases - the only way
2. Add prepend (prepend, this is when we "visually extend the route in BGP") in the announcements. Heavy artillery. It is used only at direct junctions and never at traffic exchange points (IX)
3. Community managers, my favorite. All decent providers have them (yes, the opposite is true: those who do not have it are indecent). It works approximately as a prepend, but granularly, it does not add prepend to all clients through the joint, but only in specific directions, until the announcement is closed.
Naturally, it would be impossible to work with this whole system of black boxes, but there is such a nice thing as Looking Glass (LG, I won’t translate, because all translations are bad). LG allows you to look at the provider’s routing table without access to its equipment. All decent operators have such a thing (we are not an operator, but we also have one). And such a trifle allows you to avoid calls to network operators of telecom operators in a very large number of cases. So I caught my mistakes, and strangers.
For all our three-year operation of anycast based balancing CDN, only one difficult case has surfaced: a network across the country with a centralized route-reflector (RR) in Moscow. In fact, this architecture makes distributed joints useless for the provider: after all, RR will choose the route closest to it as the best. And he will be announced to everyone. However, this network is already being rebuilt due to the shortcomings of such an architecture.
The accidents both on our equipment and on other people's equipment showed very good stability of the CDN: as soon as one node goes out of order, clients run from it to others. And not all for one, which is also very useful. No human mind intervention is required for this. The conclusion of the site to preventive maintenance is also simple: we stop announcing our anycast prefix, and users quickly switch to other sites.
Perhaps I will give one more advice (however, this is also described in the mentioned RFC): if you are building a distributed network node based on anycast, be sure to get this node if not FullView (in those Cisco, which we have in the regions, 500 kiloprefixes doesn’t fit), then the default route is a must! Cases of asymmetric routing on the Internet are very common, and we do not want to leave the user in front of a black screen because of a black hole in routing.
So, it seems I still mentioned in the requirements about the possibility of determining the "sticking" of the user to the node. This is also implemented. :) In order for the provider to be able to determine which node it sends (or can send users to), announcements from all our nodes are marked with a community marking. And their meanings are described in our IRR record in RIPE DB. Accordingly, if you accepted the prefix labeled 57629: 101, know that you go to Moscow.
There is another way that we use it: to ping an IP address into question from a source on anycast network. If the packet returned (we received a response to our ping), then the client is served from this node. In theory, this means that you need to sort through all the nodes, but in practice, we can accurately predict where the subscriber is served. And if the user does not respond at all (I wrote about it myself above, right?)? Not a problem! As a rule, in the same subnet there is a router that responds. And this is quite enough for us.
Well, we came to the site. But after all, no one thinks that we have only one server on one node? And if so, then you need to somehow distribute the requests between them. But this topic is for another article, unless of course you are interested.