Carnegie Mellon University saves old programs from oblivion
- Transfer
Olive's prototype archiving system allows you to run vintage code on modern computers

In early 2010, Harvard economists Carmen Reinhart and Kenneth Rogov published an analysis of the economic data from different countries, and concluded that if the debt exceeds 90% of GDP, it will become a threat to the growth of the country's economy. With such a large debt, in their opinion, growth should become negative.
Their analysis was made shortly after the 2008 recession, so he was directly involved in the work of legislators, many of whom were convinced of the need to increase debt to stimulate national economies. At the same time, conservative politicians, such as Olli Rehn, who was then European Commissioner , and US Congressman Paul Ryan, used the discoveries of Reinhart and Rogow to campaign for financial abstinence.
Three years later, Thomas Herndon, a graduate of the University of Massachusetts, found an error in an Excel spreadsheet that Reinhart and Rogov used for their calculations. Its significance was enormous: with proper analysis, Herndon showed, the level of debt at 90% of GDP correlated with a positive growth of the economy by 2.2%, and not with a negative growth of -0.1%, as Reinhart and Rogov wrote.
Herndon could easily verify the findings of the Harvard economists, because he had access to the software with which they worked - Microsoft Excel. And what about older discoveries using old software that is difficult to find today?
You can decide that the solution to this problem — saving important software for future researchers — should not be difficult. After all, software is just a set of files, and these files are easy to store on a hard disk or on film in digital form. The program code of some programs can even be reproduced on paper, in order to avoid problems with the obsolescence of digital media for which it was written.
Storage of programs in this way is carried out on an ongoing basis, even for programs a few decades old. Online, you can, for example, find the source code for the Apollo Guidance Computer, which helped deliver astronauts to the moon in the 1960s. It was copied from paper media and uploaded to GitHub in 2016.
And although a hardcore programmer might like the careful study of such a vintage code, most people are not interested. They are interested in using software. But keeping the software up and running for long periods of time is extremely difficult, because to run most of the old programs, you need old computers and old operating systems.
You could face such problems yourself, trying to play computer games of your youth. But in the field of scientific and technical research, the inability to start the old program can lead to much more serious consequences.
In addition to economists, many other researchers, such as physicists, chemists, biologists, and engineers, use programs for data processing and visualization of test results on an ongoing basis. They are engaged in the simulation of phenomena using computer models written in various programming languages, and using a large number of software libraries supporting their work and references to data sets. Such investigations and the software on which they rely play a major role in discoveries and search results reports.
Imagine that you are a researcher who wants to check the calculations of another scientist, conducted 25 years ago. Will that old software still be available to you? The company that released it could have closed already. Even if its modern version exists, will it accept the data in its original format? Will all calculations - for example, work with rounding errors - be identical to the old, made on a computer a whole generation ago? Probably not.
The dependence of researchers on computers is growing, and the difficulty in trying to run old software increases, and this prevents them from checking previously published results. The problem of obsolete software negates the notion of reproducibility that underlies science.
This problem may also affect forensic examinations. Suppose, calculations of the engineer showed that the building must stand, and after that the roof of the building falls. Did the engineer make a mistake, or was the software malfunctioning? If many years later the software cannot be launched, it will be very difficult to verify.
Therefore, my colleagues from Carnegie Mellon University and I developed a way to archive programs in such a way that they can be easily launched today and in the future. My colleagues, computer scientists Benjamin Gilbert and Jan Hanks, wrote most of the code. The collaboration was also attended by software archivist Daniel Ryan and librarians Glorian Saint-Claire, Eric Linke and Kif Webster, who, for obvious reasons, have their own keen interest in preserving this part of modern culture.
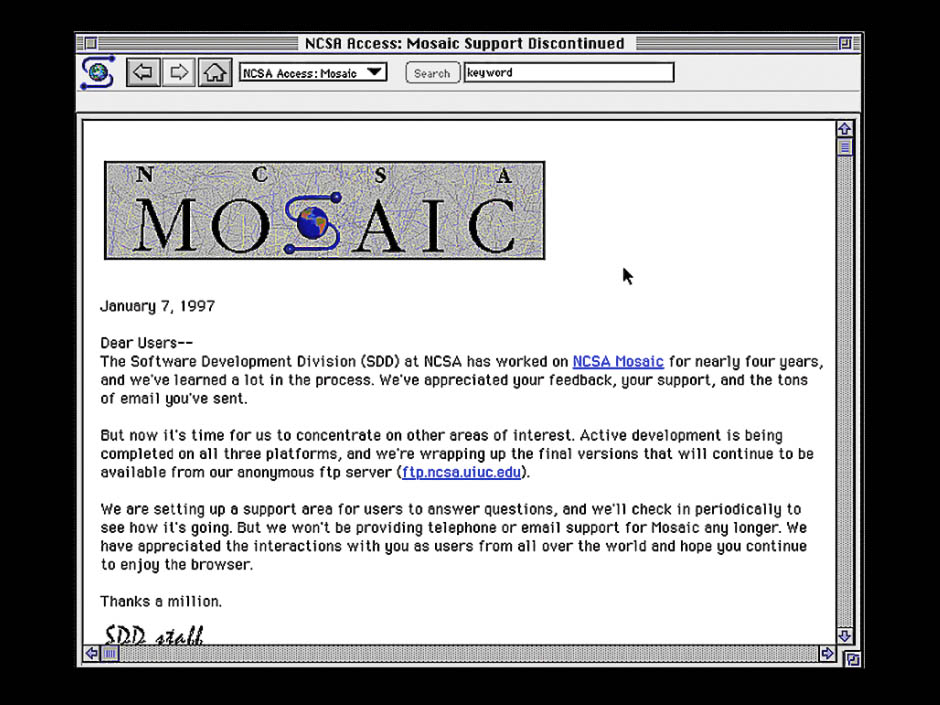
NCSA Mosaic 1.0, one of the first Macintosh browsers, 1993
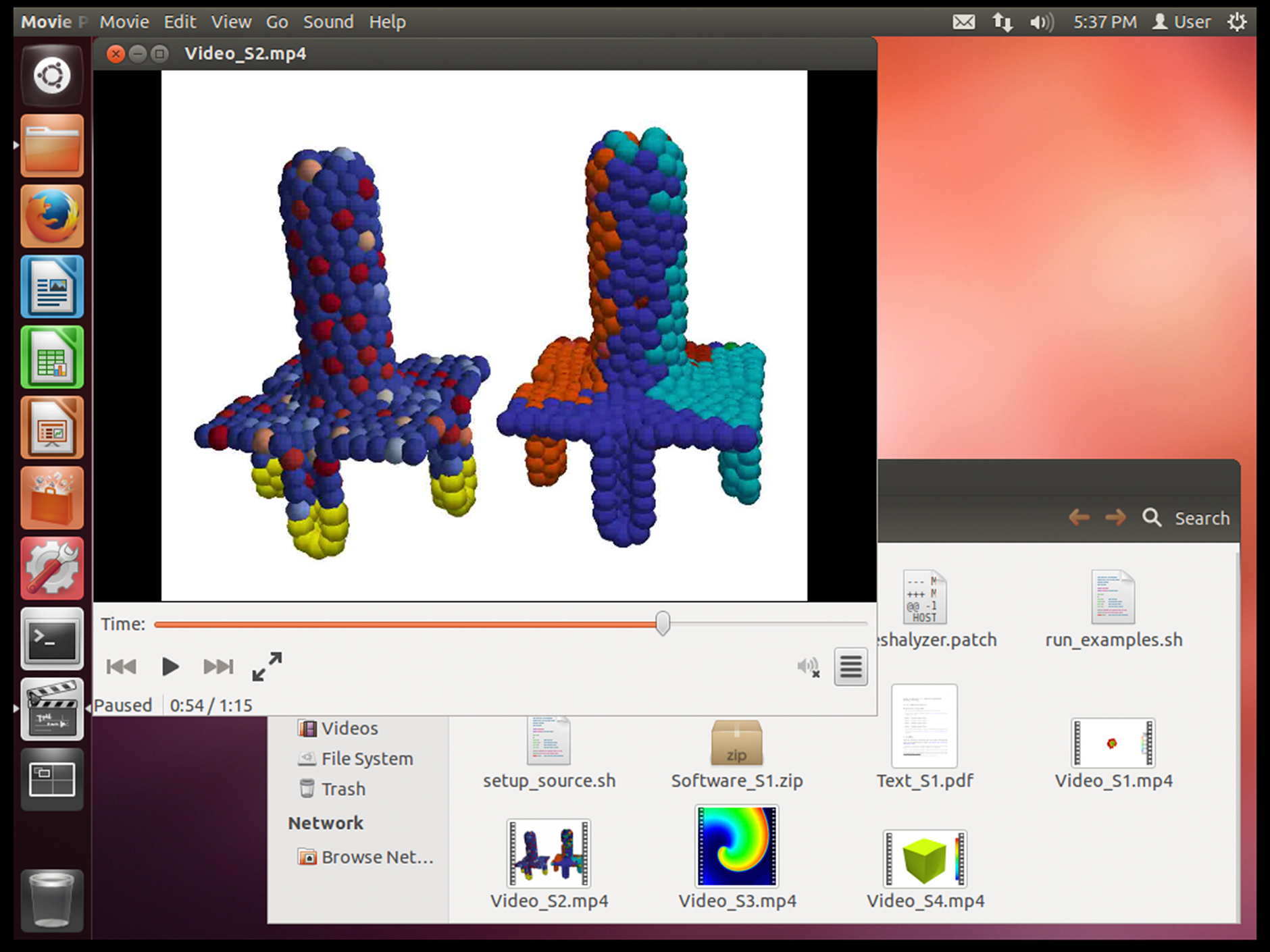
Chaste (Cancer, Heart and Soft Tissue Environment) 3.1 for Linux, 2013

The Oregon Trail 1.1, Macintosh game, 1990

Wanderer, MS-DOS game, 1988
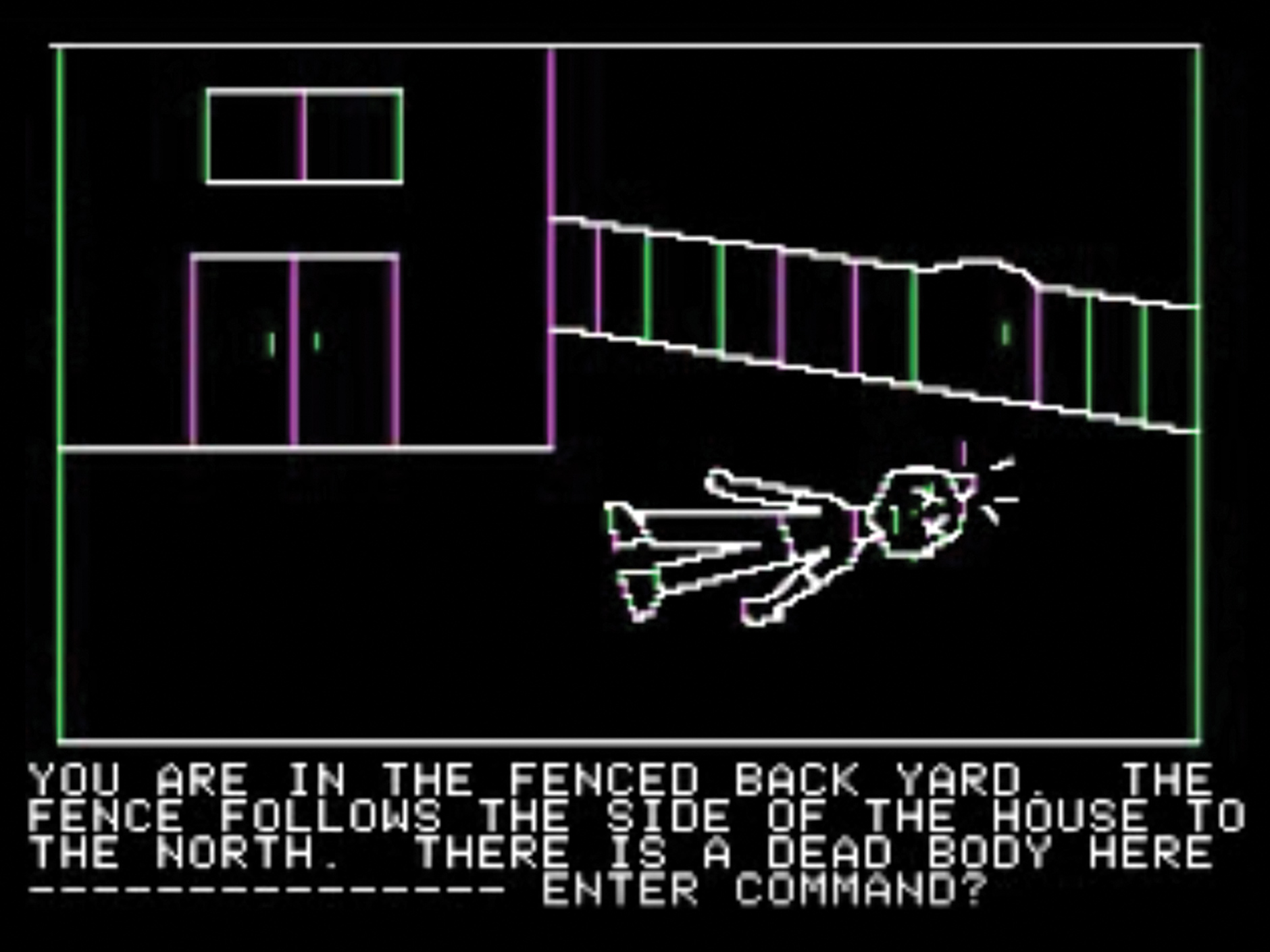
Mystery House, game for Apple II, 1982

The Great American History Machine, interactive educational atlas for Windows 3.1, 1991
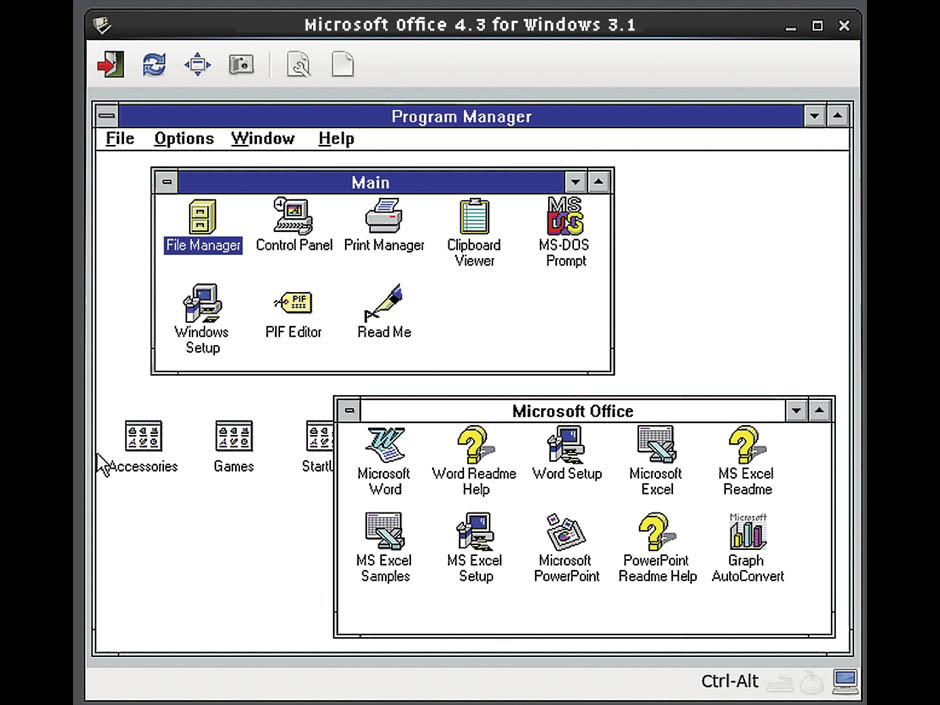
Microsoft Office 4.3 for Windows 3.1, 1994
ChemCollective, educational chemistry software for Linux, 2013
Since this project is related to the preservation of software, and not with popular computer science, we raised funds for it not from ordinary government agencies, but from the Alfred Sloan Foundation and the Institute of Museum and Library Services. With their help, we demonstrated the recovery of long-forgotten computer systems and made them available to everyone online so that any computer user could go back in time with one click of the mouse.
We created the Olive system.- is an acronym for an open library of images for virtual execution [Open Library of Images for Virtualized Execution]. Olive allows you to get through the Internet the same impression that you would get when launching an application, OS or computer from the past. By installing Olive, you can work with very old software as if it were modern. This is something like the Wayback Machine online archive for executable programs.
To understand how Olive can revive an old computer environment, you need to go through several layers of software abstractions. At the very core is the common base of most modern computing technologies: a standard desktop computer or laptop with one or more x86 microprocessors. On it we run the Linux OS, which forms the second layer in the stack.
Above the OS is VMNetX software written in my lab that runs the virtual machine over the [Virtual Machine Network Execution] network. A virtual machine is a computing environment that simulates an environment on a computer that existed on a different type of computer. VMNetX allows you to store virtual machines on a central server and run them on demand remotely. The advantage is that your computer does not need to download the entire disk and memory status from the server to start the virtual machine. Information stored on disk and in memory is downloaded in parts, if necessary, to organize the next layer - a virtual machine monitor (hypervisor), which can support the work of several machines simultaneously.
A hardware emulator is running on each of the virtual loaders - this is the next level in the Olive stack. The emulator pretends that a computer that has long been out of use is working on it - for example, an old Macintosh Quadra with a Motorola 68040 CPU from the 90s. If the archived software can work on a computer with an x86 processor, this virtualization layer can be omitted.
The next layer is an old OS on which archive software can run. It has access to a virtual disk imitating a disk drive and a file system necessary for the operation of the next layers of this software abstraction cake.
Above the old OS is already the program itself. This may be the top of the heap, or there may be another layer on it consisting of data that the program needs to feed to get what you want from it.
Olive tops are different for each of the archived programs, and are stored on a central server. The lower layers are installed on the user's computer as a client part. When launching the archive program, the Olive client downloads the necessary parts of the upper layers on demand from the central server.

This is what the system has under the hood. But what can Olive do? Today, it contains 17 different virtual machines that can run a variety of operating systems and applications. The choice of what to include in the system was based on a mixture of curiosity, accessibility, and personal interests. For example, one member of our team recalled with affection how he played at The Oregon Trail while he was at school in the early 1990s. As a result, we found an old version of the game for Mac and managed to launch it through Olive. After this became known, many people began to come to us with questions about the possibility of reviving their favorite software from the past.
The oldest application we've restored is Mystery House, a graphical game from the early 1980s for the Apple II computer. Another program is NCSA Mosaic, which, as people of a certain age can remember, gave them the wonders of WWW.
Olive has a version of Mosaic written in 1993 for Macintosh System 7.5. This operating system runs on a Motorola 68040 CPU emulator, created using software running on a computer with an x86 processor running Linux. Despite all this virtualization, the speed is not bad, because modern computers work much faster than the original Apple hardware.
It is quite interesting to send the restored Mosaic from Olive to modern sites. It appeared earlier than modern web technologies such as JavaScript, HTTP 1.1, Cascading Style Sheets, and HTML 5, and therefore is unable to display most sites. But you may be interested to look for sites that have been made for so long that they are perfectly visible in this browser.
What else is Olive capable of? You may be wondering what tools were used in the business immediately after the appearance of the Intel Pentium processor. Olive can help with that. Start Microsoft Office 4.3 since 1994 (which, fortunately, was released even before the appearance of an annoying paper clip assistant).
You may want to spend a nostalgic evening, playing Doom for DOS, or understand why in the early 90s first-person shooters became so popular. Or perhaps you need to redo your 1997 taxes, and you cannot find a diskette with that version of the TurboTax program in the attic. Don't worry, Olive will take care of you.
If we talk about more serious things, then Olive stores Chaste3.1. This is short for Cancer, Heart and Soft Tissue Environment (cancer, heart and soft tissue). This is a simulation developed at Oxford University, which allows solving computational problems in biology and physiology. Version 3.1 was related to research work published in March 2013. However, two years after publication, the source code of Chaste 3.1 stopped compiling in new versions of Linux. This is an excellent example of the problems of scientific reproducibility that the Olive system should solve.

To keep Chaste 3.1 running, Olive provides a timeless Linux environment. Recreated in Olive Chaste also contains examples of data published with work from 2013. Processing this data produces a visualization of the work of the muscles. Future physiology researchers who want to study these visualizations, or make corrections to the published software, can use Olive to edit the code in the virtual machine and start it.
Olive is currently available to a limited number of users. Due to licensing restrictions, the set of old software from Olive is available only to people who helped in the development of the project. Software-related companies must provide permission to present revived programs to a wide audience.
In our search for opportunities to support life in the old software, we are not alone. The Internet Archive saves thousands of old programs with an MS-DOS emulator running in a browser. At Yale, they are developing an EaaSI project (emulation as a service infrastructure), hoping to give everyone access to thousands of emulations of the software environment from the past. Scientists and librarians from the Software Preservation Network project are working on this and other projects. They are also working on solving copyright issues that appear when running old software in this way.
Olive has already developed well, but she is still far from a fully finished system. In addition to the licensing problem, it remains to overcome some technical obstacles.
One of the obstacles is the import of new data for processing by the old program. So far, such data must be entered manually, and this method is difficult and error-prone. Also, this method limits the amount of data that can be analyzed. Even if we added a data import mechanism, the amount of data stored would be limited by the size of the virtual disk of the virtual machine. This may seem like a small problem, but it must be remembered that the file systems of old computers sometimes had such volume limits, which are now perceived as strange.
Another obstacle is GPU emulation. For quite a long time, scientists have been using parallel computations to speed up various computations. To archive executable software using a GPU, Olive will have to recreate virtual versions of such chips - and this is a difficult task. This is because the GPU interfaces — what can be entered into them and what they derive — are not standardized.
Obviously, there is still a lot of work to be done before we announce the solution to problems with the archiving of executable programs. But Olive is a good start to creating systems that will be needed to ensure that old programs are kept in such a state that they can be studied, tested and used for a long time.