How we killed ourselves in one click by placing a site and billing on a geocluster or again talking about redundancy
Yes, I am also a moron. But I did not expect this from myself. It seems to be "not married the first year." It seems to read a bunch of smart articles about resiliency, redundancy, etc., something sensible once wrote even himself here. Over 10 years I have been the CEO of a ua-hosting.company brand hosting provider and hosting and server rental services in the Netherlands, USA, and just a week ago in the UK (do not ask why ua, you can find the answer in our autobiographical article ), we provide customers with solutions of varying degrees of complexity, sometimes such that even they themselves find it difficult to understand what they have done.
But damn ... Today I have surpassed myself. We ourselves completely demolished the site and the billing, with all the transactions, customer data on services, and others, and I was to blame for this, I myself said “delete”. Some of you have already noticed this. It happened today, Friday at 11:20 Eastern North American Time (EST). Moreover, our site and billing were placed not on the same server, and not even in the cloud, we left the data center cloud 2 months ago in favor of our own solution. All this was placed on a fault-tolerant geo-cluster of two virtual servers - our new product, VPS (KVM) with dedicated drives , INDEPENDENTVPS, which were located on two continents - in Europe and in the USA. One in Amsterdam, and the other in Manassas, near Washington, by the fact that DC In two of the most reliable data centers. The content on which was constantly and in real time was duplicated, and the fault tolerance is based on the usual DNS cluster, requests could come to any of the servers, anyone would play the role of MASTER, and in the event of unavailability took on the tasks of the second.
I thought that this could kill only a meteorite, or something else similar global, which can disable two data centers simultaneously. But everything turned out to be easier.
It can be ourselves, we, if we are idiots. There are only two limitless things in the world - the Universe and human stupidity, and if the first is debatable, then the second has become obvious.
I have always adhered to the principle of sound redundancy, I am not one of those people who will shout “I lose $ 1000 per hour of inactivity”, but at the same time I pay $ 15 for my entire infrastructure. No, I certainly do not lose so much. Although, perhaps, sometimes I lose. Most of the idiots who shout it out don't even think that sometimes idle times per second can cost $ 1,000, $ 10,000, or even a million dollars in profit in the long run. How? Very simply, at this moment a client can come in, who will make his first order, and in the future will bring you these millions of dollars, because you always have the opportunity to prove your uniqueness to him and earn his recommendations. And if he sees an error 504 or “sorry, but the server is currently unavailable,” the transaction may not take place. It happened to us, no, not 504 error during an important visitor’s visit, but the first one. Purely by chance, I found myself in the right place at the right time, when major customers came to our site, such as Dmitry Sukhanov, the creator of Film Search, although this is not a very good example, because he worked with us only for 2 years. Yandex did not buy it for $ 60 million or how much is there. So millions here were received by Dmitry rather than us, but we were glad to cooperate with such an interesting and useful project and this, in turn, made us advertisements and provided many new and satisfied customers.
In general, what I am all about. Losses and necessary redundancy need to be assessed healthy. Although there is a risk of losing a million + dollars, you need to look at the likelihood of such an event. Most likely, if Dmitriy saw the error 504 once, nothing critical would have happened, and he came back to us again. Why? At that time, we were probably one of the few who could offer the connectivity of 1+ Gbit / s across Ukraine with high quality and minimal latency for inexpensive, which was extremely important for their resource at that time to provide high-quality access for the Ukrainian audience to the portal, as foreign traffic was of poor quality and still expensive. So it is important to ensure that the solution is also unique, then uptime will not be very critical for you. And since we are unique - we can easily allow for ourselves (even now), having thousands of server clients, simple in a few hours or even more. We do not need mega-fault-tolerant clouds that provide 99.9999% uptime for a lot of money, because even they fall, and if they fall, then, as practice has shown, it takes a very long time, because the problem that caused the inaccessibility is probably uncommon. And they will not help in case of vulnerabilities. No help.
So we built our solution for ourselves very simply. We took two VPS (KVM) on the Dell R730xd nodes, the same VPS (KVM) as we offer our customers, because this is our initial principle - to give people what we use ourselves:
VPS (KVM) - 2 x Intel Dodeca-Core Xeon E5- 2650 v4 (24 Cores) / 40GB / 4x240GB SSD RAID10 / Datatraffic - 40TB - from $ 99 / month, and you can get a 30% discount on the first payment if you find the promotional code in our advertising article .
One in the Netherlands and the other in the USA. Yes, on these nodes, in addition to our site and billing, there are still 2 real clients each that can influence the work of our site in theory and cannot do this in practice. Why - it is written in the advertising article, I will not go into details here the second time. Now it's not about that. In general, the solution is not worse than dedicated entry-level servers and can handle a very large load.
Among other things, it is fault tolerant, data is constantly replicated in real time. And if one server is unavailable, the MASTER role will take the second. Ideally, you can also do so that traffic from the American continent will be processed by the American server, and from Europe, Russia and Asia - the server in the Netherlands.
We tied up the servers to our account in our WHMCS billing, a public licensed product, but adapted for us, which is used by many hosting providers around the world, including us, since writing our own accounting system is a frank debilism (in our case) . Especially in cases when the required function is implemented by writing your own module to the existing billing, which increases your fault tolerance, as it reduces the risk of critical vulnerabilities. After all, alone or even a small team you can not write a more reliable system than the existing one, which was written over the years by a bunch of developers, where thousands of bugs have already been cut out and for which developers are now asking for only $ 30 / month for a license and get millions of dollars a year ,
Speaking of critical vulnerabilities, our programmer recently made a mistake when writing one of the service modules, which had read-only access to the billing database, which was discovered by an independent pentester and asked us to pay $ 550 for the found bug, because it was a SQL vulnerability -injection:
Of course, we supported such a start and paid a reward without question. As our programmer studied the data provided and confirmed the existence of the problem, the justification of the pentester. After all, we do not yet keep our own Pentester on staff, and this work requires considerable knowledge and time, as it includes a whole series of studies:
Therefore, yes, the decision was made unequivocally and quickly. Moreover, as noted by Pentester, such research increases the security of the web as a whole:
Therefore, in general, we paid quite a bit, especially if we divide the amount by the number of months that the employee responsible for penetration testing was not contained in the state. Thank you very much to the pentester for the bug found and the fact that he gave us time, we really are very grateful to him. If anyone needs his services - contact us, we will provide contacts with his permission.
But this time we were killed not by vulnerability. It was us and the peculiarity of the WHMCS product. Each node has a convenient virtual container management product — VM Manager, which WHMCS has access to create, suspend, and delete, as well as clients — to manage the created virtual container.
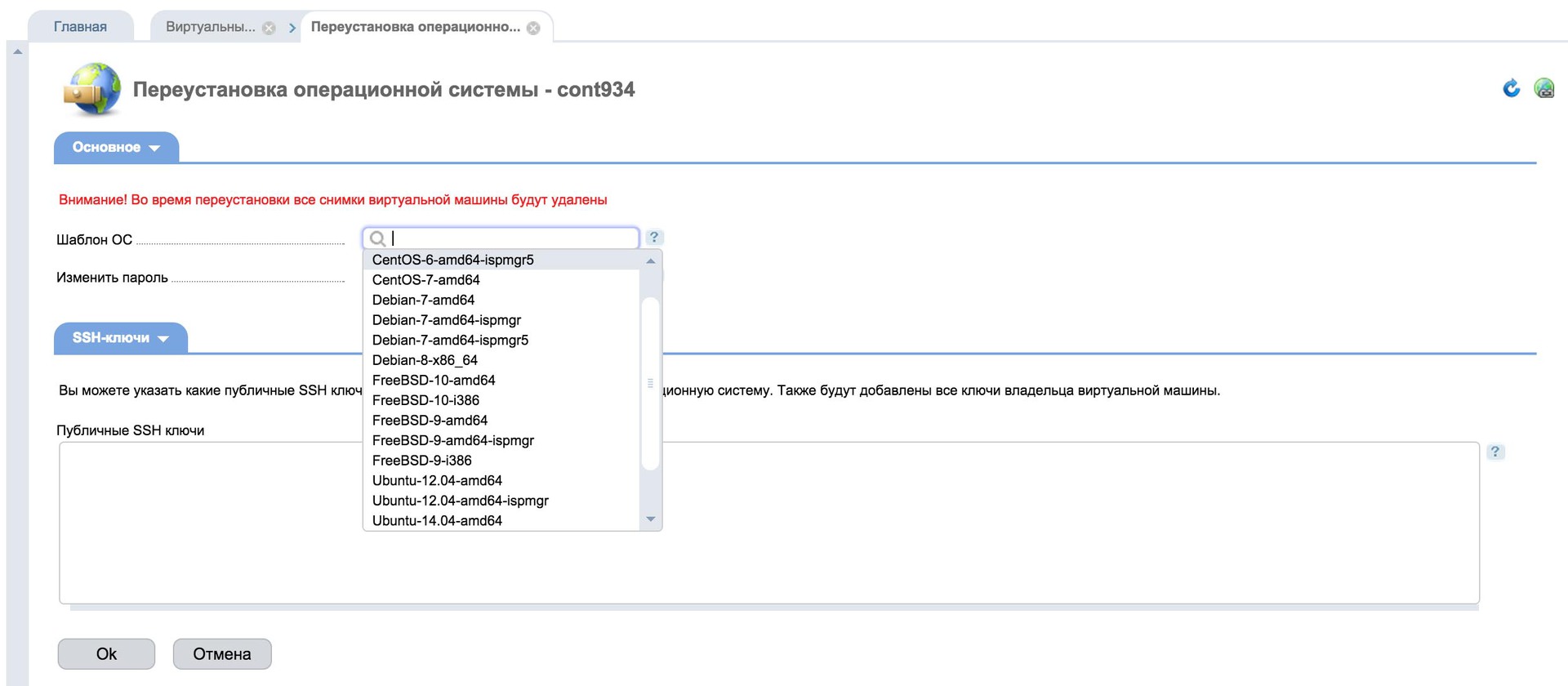
Every day in WHMCS we receive dozens and even hundreds of orders that need to be accepted (accepted), deleted, or marked as Fraud if the customer tries to pay the order with a stolen credit card. Sometimes there is a boom of such orders and we cannot immediately determine what status to assign to it, since we conduct our internal checks or require the user to identify himself properly if his order seemed suspicious to us, and such users, of course, do not always respond or go identification is successful. Therefore, from time to time a thousand or other non-activated orders or orders with an unknown status accumulate that are easier to remove than to process. Who really needs - will re-order.
Two months ago, we decided to completely abandon the cloud product of the data center, as we began to provide our own solution with VM Manager, which allows you to install the system in one click or even from your image:

And even offered it on NVMe PCIe SSD drives, which are faster than ordinary SSDs for reading and up to 3 times for writing, the solution, like a cloud one, is upgradeable, servers cost from $ 15 and include a convenient VM Manager control panel and ISP Manager 5 upon request free of charge, support an upgrade with a minimum step of 5GB DDR4 RAM , 60GB NVMe PCIe SSD and core 3 E5-2650 v4 to pain his tariff plan in Amsterdam, Manassas and London:
the VPS (the KVM) - E5-2650 v4 (3 Cores) / 5GB DDR4 / 60GB NVMe SSD / 1Gbps 5TB - $ 15 / month
VPS (KVM) - E5-2650 v4 (6 Cores) / 10GB DDR4 / 120GB NVMe SSD / 1Gbps 10TB - $ 30 / month
VPS (KVM) - E5-2650 v4 (9 Cores) / 15GB DDR4 / 180GB NVMe SSD / 1Gbps 15TB - $ 45 / month
...
VPS (KVM) - E5-2650 v4 (24 Cores) / 40GB DDR4 / 480GB NVMe SSD / 1Gbps 40TB - $ 120 / month
...
VPS (KVM) - E5-2650 v4 (24 Cores) / 65GB DDR4 / 780GB NVMe SSD / 1Gbps 65TB - $ 195 / month
VPS (KVM) - E5-2650 v4 (24 Cores) / 70GB DDR4 / 840GB NVMe SSD / 1Gbps 70TB - $ 210 / month
VPS (KVM) - E5-2650 v4 (24 Cores) / 75GB DDR4 / 900GB NVMe SSD / 1Gbps 75TB - $ 225 / month
Therefore, it makes no sense to rent a huge part of the data center cloud and offer customers old E3-1230 processors, albeit from $ 3.99 a month has dried up for us. We believe that customers should receive maximum quality and maximum performance, for a minimal price, yes, we cannot offer a product for $ 3.99 and perhaps do not cover the needs of some developers who have enough minimal resources and any performance, but the node costs more than 7000 euros and we can not afford, at least for now, to place on it more than 15 clients, because we are ready to guarantee quality. And quality means not only stability, but also the maximum ratio of performance / price, then cost-efficiency.
To celebrate, we canceled the entire cloud infrastructure (and these are thousands of VPS), ordered 2 independent virtual servers from ourselves (yes, we pay ourselves for our servers), launched a site and billing on a new solution 2 months ago, as described everything above, brought into the Protect group, so that the system does not stop itself, if you suddenly forgot to pay on time ... It seems that they did everything.
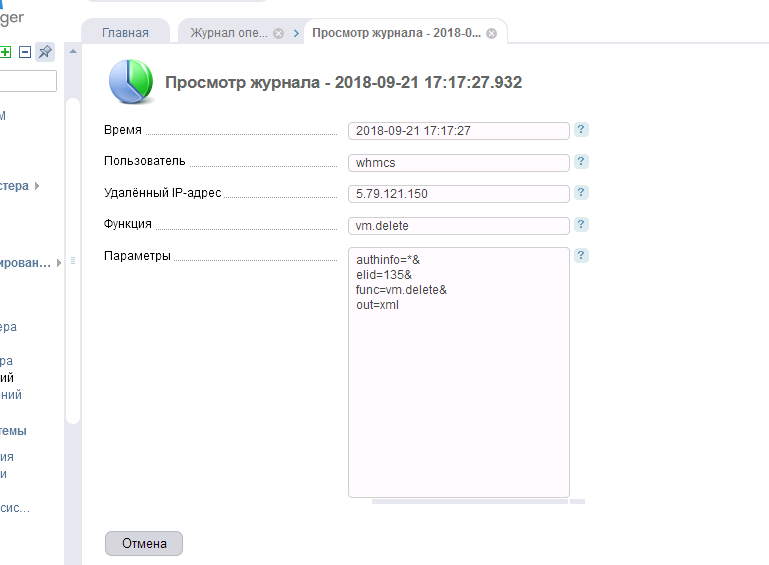
And today, after 2 months, we decided to “Cancel” (do not delete, there is also such a button, but we never try to delete anything so that there is always a story) 1000+ waiting orders, which still have not been assigned a status in the WHMCS billing . Guess? Yes that's it. I was asked - can I cancel? I confirmed "delete."
Sometimes, despite the large amount of resources, since the data selection is large and some process does not fit into the allotted time limit, WHMCS gives 504 error, while everything is done and the billing continues to work, but then we got unavailable. Billing and site ceased to be available. We did not immediately understand the reason. But then realized. The order for our 2 VPSs was not accepted (yes, we did not accept our own order!) And, as a result, was “Canceled” by the system, which led to the launch of the module and the removal of two containers at once, allegedly not created, but still created virtual machines, using our favorite VM Manager. Going to one of the nodes, as expected, our administrators saw the picture "Goodbye":
What is it - a flaw in the WHMCS developers, which leads to the removal of unaccepted orders, and really created with their VPS ID, if they are canceled, or our stupidity (sales department) - is no longer important. The result was the same - "Goodbye site with billing." The panel simply wiped them. And administrators to us (sales), had only one question:
And although we had backups, also in two geographically distributed regions, I felt uneasy. Since I was not sure about the freshness of backups, I was not sure that our administrators did everything correctly, as it was written initially in those. specifying that the database was actually reserved every hour or even more often, and the data was updated and several previous versions of the files were stored. That backups for some program error did not cease to be made at all (after all, I personally did not control this, why should I be sure that our administrators will be worried about our data if I scored on this control?). A bunch of negative thoughts ... Do not let the universe you survive this!
I already thought that at least 1 hour, or even worse, there will be no transactions, and I’ll have to recover customer payments manually, compare data on previous transactions and write to account holders that we have re-created the account and paid it , show yourself from the wrong side, send out a notification that we are fools and made such a software failure ... And if there is no fresh backup, then this is a pipe, it would take a long and dreary to restore everything ...
In this case, we have an internal table, where many wasp The new data is duplicated manually and which is updated by us, which eliminates the software failure and the rewriting of incorrect data. Despite the availability of backups - we still use this method. After all, no one cancels the possibility of a global zvizdets.
Fortunately, everything was not so bad, and even those. a specialist who had to solve a problem and who at the beginning announced:
Yet the evening was a success. Since the solution initially involved the use of lvm and the new virtual container had not yet been created, it turned out to restore the actual data, albeit with a tambourine dance:
What conclusions are made? Redundancy and redundancy should include vulnerability accounting and the most stupid development scenario, when everything, even backups, can be destroyed. We did not suffer and did not suffer large losses only due to the fact that the data were not completely deleted. If it is necessary to restore from backup copies, there would be a loss of transactions over a period of an hour and a significant loss of working time. It seemed to us that the probability that when backups might be useful to us when using a geocluster is minimal - we were wrong. We did not take into account that it is possible to remove both servers at once and that we will not remove the servers, but someone.
You must always have an external storage independent of your system, with access, preferably only by some code that is also backed up, so that you can guarantee that the data will not be lost. At the moment, despite the availability of backups in our infrastructure in two regions, I seriously consider using something like Amazon Glacier, although the latter is very expensive. According to the administrators, everything is good there only in the marketing plan, but when you start using it, you come across the fact that the solution is quite expensive, because you have to pay for each request and each file that is very interesting to be considered by their aws-cli application, especially if data needs to be restored. Recently, a client from Britain asked to set up a reservation there, after a few months, he refused to use it - it turned out to be very expensive. But still, we need to determine what is more expensive. And if the budget for reservation there does not exceed the amount of possible damage as a result of the loss of part of the data - we will definitely use it. If not, we will begin to look for another, better price, but still a solution independent of us. To provide additional reliability and confidence that the data will not be lost.
Well, and as for uptime - it is not so important, any losses from downtime are recoverable, especially if you offer a unique product. Therefore, you should not concentrate on excessive fault tolerance, it is better to add redundancy, in particular redundancy, in storing backup copies, because in case of loss of data, no downtime will not seem very scary to you.
PS Events occurred today, on Friday (published on Friday, EST time). Sorry for the many letters, I decided to unsubscribe while it is fresh in the memories. I hope my experience will be useful to someone and will save from such a misfortune. And on Friday you will enjoy the evening before the weekend, and not write an article about errors, as I did. Although that is not - for the better, it could be much worse. Feel free to share your factories in the comments. Have a nice coming and already come weekend!
As advertising.
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps in the Netherlands until December for free if you pay for half a year, you can order here , 30% discount on the first VPS payment in the Netherlands, USA, England here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
But damn ... Today I have surpassed myself. We ourselves completely demolished the site and the billing, with all the transactions, customer data on services, and others, and I was to blame for this, I myself said “delete”. Some of you have already noticed this. It happened today, Friday at 11:20 Eastern North American Time (EST). Moreover, our site and billing were placed not on the same server, and not even in the cloud, we left the data center cloud 2 months ago in favor of our own solution. All this was placed on a fault-tolerant geo-cluster of two virtual servers - our new product, VPS (KVM) with dedicated drives , INDEPENDENTVPS, which were located on two continents - in Europe and in the USA. One in Amsterdam, and the other in Manassas, near Washington, by the fact that DC In two of the most reliable data centers. The content on which was constantly and in real time was duplicated, and the fault tolerance is based on the usual DNS cluster, requests could come to any of the servers, anyone would play the role of MASTER, and in the event of unavailability took on the tasks of the second.
I thought that this could kill only a meteorite, or something else similar global, which can disable two data centers simultaneously. But everything turned out to be easier.
It can be ourselves, we, if we are idiots. There are only two limitless things in the world - the Universe and human stupidity, and if the first is debatable, then the second has become obvious.
I have always adhered to the principle of sound redundancy, I am not one of those people who will shout “I lose $ 1000 per hour of inactivity”, but at the same time I pay $ 15 for my entire infrastructure. No, I certainly do not lose so much. Although, perhaps, sometimes I lose. Most of the idiots who shout it out don't even think that sometimes idle times per second can cost $ 1,000, $ 10,000, or even a million dollars in profit in the long run. How? Very simply, at this moment a client can come in, who will make his first order, and in the future will bring you these millions of dollars, because you always have the opportunity to prove your uniqueness to him and earn his recommendations. And if he sees an error 504 or “sorry, but the server is currently unavailable,” the transaction may not take place. It happened to us, no, not 504 error during an important visitor’s visit, but the first one. Purely by chance, I found myself in the right place at the right time, when major customers came to our site, such as Dmitry Sukhanov, the creator of Film Search, although this is not a very good example, because he worked with us only for 2 years. Yandex did not buy it for $ 60 million or how much is there. So millions here were received by Dmitry rather than us, but we were glad to cooperate with such an interesting and useful project and this, in turn, made us advertisements and provided many new and satisfied customers.
In general, what I am all about. Losses and necessary redundancy need to be assessed healthy. Although there is a risk of losing a million + dollars, you need to look at the likelihood of such an event. Most likely, if Dmitriy saw the error 504 once, nothing critical would have happened, and he came back to us again. Why? At that time, we were probably one of the few who could offer the connectivity of 1+ Gbit / s across Ukraine with high quality and minimal latency for inexpensive, which was extremely important for their resource at that time to provide high-quality access for the Ukrainian audience to the portal, as foreign traffic was of poor quality and still expensive. So it is important to ensure that the solution is also unique, then uptime will not be very critical for you. And since we are unique - we can easily allow for ourselves (even now), having thousands of server clients, simple in a few hours or even more. We do not need mega-fault-tolerant clouds that provide 99.9999% uptime for a lot of money, because even they fall, and if they fall, then, as practice has shown, it takes a very long time, because the problem that caused the inaccessibility is probably uncommon. And they will not help in case of vulnerabilities. No help.
So we built our solution for ourselves very simply. We took two VPS (KVM) on the Dell R730xd nodes, the same VPS (KVM) as we offer our customers, because this is our initial principle - to give people what we use ourselves:
VPS (KVM) - 2 x Intel Dodeca-Core Xeon E5- 2650 v4 (24 Cores) / 40GB / 4x240GB SSD RAID10 / Datatraffic - 40TB - from $ 99 / month, and you can get a 30% discount on the first payment if you find the promotional code in our advertising article .
One in the Netherlands and the other in the USA. Yes, on these nodes, in addition to our site and billing, there are still 2 real clients each that can influence the work of our site in theory and cannot do this in practice. Why - it is written in the advertising article, I will not go into details here the second time. Now it's not about that. In general, the solution is not worse than dedicated entry-level servers and can handle a very large load.
Among other things, it is fault tolerant, data is constantly replicated in real time. And if one server is unavailable, the MASTER role will take the second. Ideally, you can also do so that traffic from the American continent will be processed by the American server, and from Europe, Russia and Asia - the server in the Netherlands.
We tied up the servers to our account in our WHMCS billing, a public licensed product, but adapted for us, which is used by many hosting providers around the world, including us, since writing our own accounting system is a frank debilism (in our case) . Especially in cases when the required function is implemented by writing your own module to the existing billing, which increases your fault tolerance, as it reduces the risk of critical vulnerabilities. After all, alone or even a small team you can not write a more reliable system than the existing one, which was written over the years by a bunch of developers, where thousands of bugs have already been cut out and for which developers are now asking for only $ 30 / month for a license and get millions of dollars a year ,
Speaking of critical vulnerabilities, our programmer recently made a mistake when writing one of the service modules, which had read-only access to the billing database, which was discovered by an independent pentester and asked us to pay $ 550 for the found bug, because it was a SQL vulnerability -injection:
SQL-injection is in the top 10 OWASP, I wrote to you about the amount of $ 550, this is the minimum amount, because the database suffers, thus it is possible to compromise these users.
But some amounts go up to $ 10,000 as a reward, as an example in the case of vk.com.
Of course, we supported such a start and paid a reward without question. As our programmer studied the data provided and confirmed the existence of the problem, the justification of the pentester. After all, we do not yet keep our own Pentester on staff, and this work requires considerable knowledge and time, as it includes a whole series of studies:
The security audit of the entire resource, and this is the test of the following parameters, and our report on the end of the audit, includes:
• A1 Code injection
• A2 Incorrect authentication and session management
• A3 Cross-site scripting
• A4 Access control violation
• A5 Unsecure configuration
• A6 Sensitive data leak
• A7 Insufficient protection against attacks
• A8 Cross-site request forgery
• A9 Use of components with known vulnerabilities
• A10 Insufficient logging and monitoring
Therefore, yes, the decision was made unequivocally and quickly. Moreover, as noted by Pentester, such research increases the security of the web as a whole:
This is my hobby, if every developer, like you, would engage in dialogue with bug-hunters, the Internet would be 80% secure.
Therefore, in general, we paid quite a bit, especially if we divide the amount by the number of months that the employee responsible for penetration testing was not contained in the state. Thank you very much to the pentester for the bug found and the fact that he gave us time, we really are very grateful to him. If anyone needs his services - contact us, we will provide contacts with his permission.
But this time we were killed not by vulnerability. It was us and the peculiarity of the WHMCS product. Each node has a convenient virtual container management product — VM Manager, which WHMCS has access to create, suspend, and delete, as well as clients — to manage the created virtual container.
Every day in WHMCS we receive dozens and even hundreds of orders that need to be accepted (accepted), deleted, or marked as Fraud if the customer tries to pay the order with a stolen credit card. Sometimes there is a boom of such orders and we cannot immediately determine what status to assign to it, since we conduct our internal checks or require the user to identify himself properly if his order seemed suspicious to us, and such users, of course, do not always respond or go identification is successful. Therefore, from time to time a thousand or other non-activated orders or orders with an unknown status accumulate that are easier to remove than to process. Who really needs - will re-order.
Two months ago, we decided to completely abandon the cloud product of the data center, as we began to provide our own solution with VM Manager, which allows you to install the system in one click or even from your image:
And even offered it on NVMe PCIe SSD drives, which are faster than ordinary SSDs for reading and up to 3 times for writing, the solution, like a cloud one, is upgradeable, servers cost from $ 15 and include a convenient VM Manager control panel and ISP Manager 5 upon request free of charge, support an upgrade with a minimum step of 5GB DDR4 RAM , 60GB NVMe PCIe SSD and core 3 E5-2650 v4 to pain his tariff plan in Amsterdam, Manassas and London:
the VPS (the KVM) - E5-2650 v4 (3 Cores) / 5GB DDR4 / 60GB NVMe SSD / 1Gbps 5TB - $ 15 / month
VPS (KVM) - E5-2650 v4 (6 Cores) / 10GB DDR4 / 120GB NVMe SSD / 1Gbps 10TB - $ 30 / month
VPS (KVM) - E5-2650 v4 (9 Cores) / 15GB DDR4 / 180GB NVMe SSD / 1Gbps 15TB - $ 45 / month
...
VPS (KVM) - E5-2650 v4 (24 Cores) / 40GB DDR4 / 480GB NVMe SSD / 1Gbps 40TB - $ 120 / month
...
VPS (KVM) - E5-2650 v4 (24 Cores) / 65GB DDR4 / 780GB NVMe SSD / 1Gbps 65TB - $ 195 / month
VPS (KVM) - E5-2650 v4 (24 Cores) / 70GB DDR4 / 840GB NVMe SSD / 1Gbps 70TB - $ 210 / month
VPS (KVM) - E5-2650 v4 (24 Cores) / 75GB DDR4 / 900GB NVMe SSD / 1Gbps 75TB - $ 225 / month
Therefore, it makes no sense to rent a huge part of the data center cloud and offer customers old E3-1230 processors, albeit from $ 3.99 a month has dried up for us. We believe that customers should receive maximum quality and maximum performance, for a minimal price, yes, we cannot offer a product for $ 3.99 and perhaps do not cover the needs of some developers who have enough minimal resources and any performance, but the node costs more than 7000 euros and we can not afford, at least for now, to place on it more than 15 clients, because we are ready to guarantee quality. And quality means not only stability, but also the maximum ratio of performance / price, then cost-efficiency.
To celebrate, we canceled the entire cloud infrastructure (and these are thousands of VPS), ordered 2 independent virtual servers from ourselves (yes, we pay ourselves for our servers), launched a site and billing on a new solution 2 months ago, as described everything above, brought into the Protect group, so that the system does not stop itself, if you suddenly forgot to pay on time ... It seems that they did everything.
And today, after 2 months, we decided to “Cancel” (do not delete, there is also such a button, but we never try to delete anything so that there is always a story) 1000+ waiting orders, which still have not been assigned a status in the WHMCS billing . Guess? Yes that's it. I was asked - can I cancel? I confirmed "delete."
Sometimes, despite the large amount of resources, since the data selection is large and some process does not fit into the allotted time limit, WHMCS gives 504 error, while everything is done and the billing continues to work, but then we got unavailable. Billing and site ceased to be available. We did not immediately understand the reason. But then realized. The order for our 2 VPSs was not accepted (yes, we did not accept our own order!) And, as a result, was “Canceled” by the system, which led to the launch of the module and the removal of two containers at once, allegedly not created, but still created virtual machines, using our favorite VM Manager. Going to one of the nodes, as expected, our administrators saw the picture "Goodbye":
What is it - a flaw in the WHMCS developers, which leads to the removal of unaccepted orders, and really created with their VPS ID, if they are canceled, or our stupidity (sales department) - is no longer important. The result was the same - "Goodbye site with billing." The panel simply wiped them. And administrators to us (sales), had only one question:
Nachera create a service with its main site and billing.
And then another, and kill her to hell.
And although we had backups, also in two geographically distributed regions, I felt uneasy. Since I was not sure about the freshness of backups, I was not sure that our administrators did everything correctly, as it was written initially in those. specifying that the database was actually reserved every hour or even more often, and the data was updated and several previous versions of the files were stored. That backups for some program error did not cease to be made at all (after all, I personally did not control this, why should I be sure that our administrators will be worried about our data if I scored on this control?). A bunch of negative thoughts ... Do not let the universe you survive this!
I already thought that at least 1 hour, or even worse, there will be no transactions, and I’ll have to recover customer payments manually, compare data on previous transactions and write to account holders that we have re-created the account and paid it , show yourself from the wrong side, send out a notification that we are fools and made such a software failure ... And if there is no fresh backup, then this is a pipe, it would take a long and dreary to restore everything ...
In this case, we have an internal table, where many wasp The new data is duplicated manually and which is updated by us, which eliminates the software failure and the rewriting of incorrect data. Despite the availability of backups - we still use this method. After all, no one cancels the possibility of a global zvizdets.
Fortunately, everything was not so bad, and even those. a specialist who had to solve a problem and who at the beginning announced:
The evening was a success, thank you all.
I went to pick up.
Yet the evening was a success. Since the solution initially involved the use of lvm and the new virtual container had not yet been created, it turned out to restore the actual data, albeit with a tambourine dance:
Everything through the lvm utility, with the help of its commands, we restored the virtual volume group, then the virtual one, then we activated the partition, put it on the left folder, created the server, and dropped the data there. It could have been in other ways, but in our case this option was the fastest + specificity of virtual server settings, that each has his own raid.
What conclusions are made? Redundancy and redundancy should include vulnerability accounting and the most stupid development scenario, when everything, even backups, can be destroyed. We did not suffer and did not suffer large losses only due to the fact that the data were not completely deleted. If it is necessary to restore from backup copies, there would be a loss of transactions over a period of an hour and a significant loss of working time. It seemed to us that the probability that when backups might be useful to us when using a geocluster is minimal - we were wrong. We did not take into account that it is possible to remove both servers at once and that we will not remove the servers, but someone.
You must always have an external storage independent of your system, with access, preferably only by some code that is also backed up, so that you can guarantee that the data will not be lost. At the moment, despite the availability of backups in our infrastructure in two regions, I seriously consider using something like Amazon Glacier, although the latter is very expensive. According to the administrators, everything is good there only in the marketing plan, but when you start using it, you come across the fact that the solution is quite expensive, because you have to pay for each request and each file that is very interesting to be considered by their aws-cli application, especially if data needs to be restored. Recently, a client from Britain asked to set up a reservation there, after a few months, he refused to use it - it turned out to be very expensive. But still, we need to determine what is more expensive. And if the budget for reservation there does not exceed the amount of possible damage as a result of the loss of part of the data - we will definitely use it. If not, we will begin to look for another, better price, but still a solution independent of us. To provide additional reliability and confidence that the data will not be lost.
Well, and as for uptime - it is not so important, any losses from downtime are recoverable, especially if you offer a unique product. Therefore, you should not concentrate on excessive fault tolerance, it is better to add redundancy, in particular redundancy, in storing backup copies, because in case of loss of data, no downtime will not seem very scary to you.
PS Events occurred today, on Friday (published on Friday, EST time). Sorry for the many letters, I decided to unsubscribe while it is fresh in the memories. I hope my experience will be useful to someone and will save from such a misfortune. And on Friday you will enjoy the evening before the weekend, and not write an article about errors, as I did. Although that is not - for the better, it could be much worse. Feel free to share your factories in the comments. Have a nice coming and already come weekend!
As advertising.
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps in the Netherlands until December for free if you pay for half a year, you can order here , 30% discount on the first VPS payment in the Netherlands, USA, England here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?