Skipped Lists: A Probabilistic Alternative to Balanced Trees
- Transfer

Skipped lists are a data structure that can be used instead of balanced trees. Due to the fact that the balancing algorithm is probabilistic rather than strict, inserting and deleting an element in skipped lists is much easier and much faster than in balanced trees.
Skipped lists are a probabilistic alternative to balanced trees. They are balanced using a random number generator. Despite the fact that lists with gaps have poor performance in the worst case, there is no such sequence of operations that would happen all the time (approximately as in the quick sort algorithm with a random selection of a support element). It is very unlikely that this data structure will be significantly unbalanced (for example, for a dictionary larger than 250 elements, the probability that the search will take three times the expected time, less than one millionth).
Balancing the data structure is probably easier than explicitly balancing. For many tasks, skip lists are a more natural representation of data than trees. The algorithms are simpler to implement and, in practice, faster than balanced trees. In addition, skipped lists use memory very efficiently. They can be implemented in such a way that on average one 1.33 pointer (or even less) falls on one element and does not require storing additional information about the balance or priority for each element.
To search for an item in a linked list, we must look at each of its nodes:

If the list is stored sorted and every second node additionally contains a pointer to two nodes in advance, we need to look at no more than ⌈n / 2⌉ + 1 units (where n - length of the list):

Similarly, if now every fourth node includes a pointer to the four nodes forward view will be required not more than ⌈ n / 2 + 4⌉ node:

If every 2 i -th a node contains a pointer to 2 i nodes forward, then the number of nodes to be viewed will be reduced to ⌈log 2 n ⌉, and the total number of pointers in the structure will only double:

Such a data structure can be used for quick searches, but inserting and deleting nodes will be slow .
We call a node containing k pointers to upstream elements a node of level k . If every 2 i-th node contains a pointer to 2 i nodes forward, then the levels are distributed as follows: 50% of nodes - level 1, 25% - level 2, 12.5% - level 3, etc. But what happens if the levels of the nodes are randomly selected in the same proportions? For example, like this:

Pointer number i of each node will refer to the next node of level i or more, and not exactly 2 i -1knots forward, as it was before. Insertions and deletions will require only local changes; the node level, randomly selected when you insert it, will never change. If the level assignment is unsuccessful, performance may turn out to be poor, but we will show that such situations are rare. Due to the fact that these data structures are linked lists with additional pointers for skipping intermediate nodes, I call them skipped lists .
Operations
We describe the algorithms for searching, inserting, and deleting elements in a dictionary implemented on skipped lists. The search operation returns a value for the specified key or signals that the key was not found. The insert operation associates a key with a new value (and creates a key if it was not there before). The delete operation deletes the key. You can also easily add additional operations to this data structure, such as “finding the minimum key” or “finding the next key”.
Each element of the list is a node whose level was randomly selected when it was created, and regardless of the number of elements that were already there. Level i node contains ipointers to various elements in front, indexed from 1 to i . We may not store the node level in the node itself. The number of levels is limited by the pre-selected MaxLevel constant . We call the list level the maximum node level in this list (if the list is empty, then the level is 1). The heading of the list (in the pictures to the left) contains pointers to levels 1 through MaxLevel . If there are no elements of this level yet, then the pointer value is a special NIL element.
Initialization
Create a NIL element whose key is larger than any key that may ever appear in the list. The NIL element will complete all skipped lists. The list level is 1, and all the pointers in the header refer to NIL.
Element search
Starting with the pointer of the highest level, we move forward along the pointers until they refer to an element that does not exceed the desired one. Then we go down one level below and again move according to the same rule. If we have reached level 1 and cannot go further, then we are just in front of the element we are looking for (if it is there).
Search (list, searchKey)
x: = list → header
# loop invariant: x → key <searchKey
for i: = list → level downto 1 do
while x → forward [i] → key <searchKey do
x: = x → forward [ i]
# x → key <searchKey ≤ x → forward [1] → key
x: = x → forward [1]
if x → key = searchKey thenreturn x -> value
else return failure
Insert and delete item
To insert or delete a node, we use a search algorithm to find all the elements before being inserted (or deleted), then update the corresponding pointers:
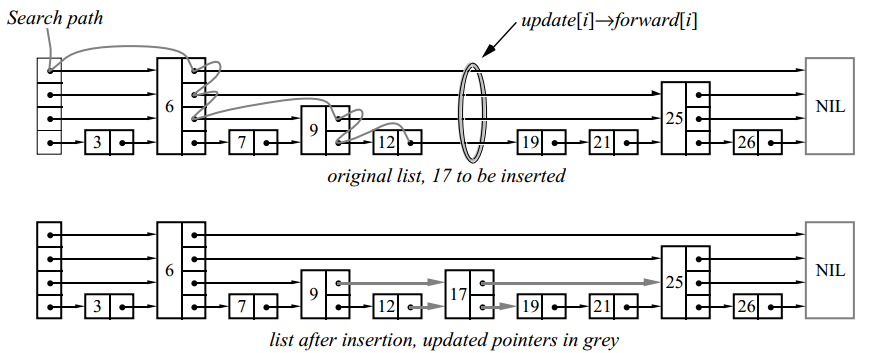
In this example, we inserted a level 2 element.
Insert (list, searchKey, newValue)
local update [1..MaxLevel]
x : = list → header
for i: = list → level downto 1 do
while x → forward [i] → key <searchKey do
x: = x → forward [i]
# x → key <searchKey ≤ x → forward [i] → key
update [i]: = x
x: = x → forward [1]
if x → key = searchKey then x → value: = newValue
else
lvl: = randomLevel ()
if lvl> list → level then
for i: = list → level + 1 to lvl do
update [i]: = list → header
list → level: = lvl
x: = makeNode (lvl, searchKey, value )
for i: = 1 to level do
x → forward [i]: = update [i] → forward [i]
update [i] → forward [i]: = x
Delete (list, searchKey)
local update [1 .. MaxLevel]
x: = list → header
for i: = list → level downto 1 do
while x → forward [i] → key <searchKeydo
x: = x → forward [i]
update [i]: = x
x: = x → forward [1]
if x → key = searchKey then
for i: = 1 to list → level do
if update [i] → forward [i] ≠ x then break
update [i] → forward [i]: = x → forward [i]
free (x)
while list → level> 1 and list → header → forward [list → level] = NIL do
list → level: = list → level - 1
To memorize the elements before the inserted (or deleted) array, the update array is used . Element update [i]- This is a pointer to the rightmost node, level i or higher, from the number to the left of the update location.
If the randomly selected level of the inserted node turned out to be greater than the level of the entire list (i.e., if there were no nodes with such a level yet), increase the list level and initialize the corresponding elements of the update array with pointers to the header. After each deletion, we check whether we deleted the node with the maximum level and, if so, reduce the level of the list.
Level Number Generation
Earlier, we presented the distribution of node levels in the case when half of the nodes containing the level i pointer also contained a pointer to the level i +1 node . To get rid of the magic constant 1/2, we denote by p the fraction of nodes of level i containing a pointer to nodes of level i + i. The level number for a new vertex is randomly generated by the following algorithm:
randomLevel ()
lvl: = 1
# random () returns a random number in the half-interval [0 ... 1)
while random () <p and lvl <MaxLevel do
lvl: = lvl + 1
return lvl
As you can see, the number of elements in the list is not involved in the generation.
What level to start looking for? Definition of L (n)
In the list with gaps of 16 elements generated at p = 1/2, it can happen that it contains 9 elements of level 1, 3 elements of level 2, 3 elements of level 3 and 1 element of level 14 (this is unlikely, but possible) . How to deal with this? If we use the standard algorithm and search starting from level 14, we will do a lot of useless work.
Where is better to start the search? Our research has shown that it is best to start the search at level L , at which we expect 1 / p nodes. This happens when L = log 1 / p n . For the convenience of further discussion, we denote the function log 1 / p n as L (n ).
There are several ways to solve the problem with unexpectedly large nodes:
- Do not steam (orig. Don't worry, be happy). Just start the search from the highest level that is on the list. As we will see later, the probability that the level of a list of n items will be significantly higher than L (n) is very small. Such a solution adds only a small constant at the expected search time. This approach is used in the algorithms given above.
- Use less space than necessary. Although an element can contain 14 pointers, we do not have to use all 14. We can only use L (n) of them. There are several ways to implement this, but all of them complicate the algorithm and do not lead to a noticeable increase in performance. This method is not recommended for use.
- Fix the cube. If a level is generated greater than the maximum level of the node in the list, then we simply assume that it is more than exactly 1. In theory and, it seems, in practice, this works well. But with this approach, we completely lose the ability to analyze the complexity of the algorithms, because the node level is no longer completely random. Programmers are free to use this method, but theorists are better off avoiding it.
Choosing MaxLevel
Since the expected number of levels is L (n), it is best to choose MaxLevel = L ( N ), where N is the maximum number of elements in the skipped list. For example, if p = 1/2, then MaxLevel = 16 is suitable for lists containing less than 2 16 elements.
Algorithm Analysis
In search, insert, and delete operations, it takes the most time to find the right item. To insert and delete, an additional time is required proportional to the level of the inserted or deleted node. The element search time is proportional to the number of nodes passed in the search process, which, in turn, depends on the distribution of their levels.
Probabilistic Philosophy
The structure of the list with gaps is determined only by the number of elements in this list and the values of the random number generator. The sequence of operations by which the list is obtained is not important. We assume that the user does not have access to the node levels, otherwise, he can make the algorithm work in the worst time by deleting all nodes whose level is different from 1.
For sequential operations on the same data structure, their execution times are not independent random quantities; two consecutive operations of searching for the same element will take exactly the same time.
Analysis of Expected Search Time
Consider the path traversed during the search from the end, i.e. we will move up and to the left. Although the levels of the nodes in the list are known and fixed at the time of the search, we assume that the level of the node is determined only when we met it when moving from the end.
At any given point on the path, we are in the following situation:

We look at the ith pointer of the node x and do not know about the levels of the nodes to the left of x . Also, we do not know the exact level of x , but it must be at least i . Suppose x is not the heading of the list (this is equivalent to assuming the list is expanding left infinitely). If level x is i, then we are in situation b . If level x is greater than i , then we are in situation c . The probability that we are in situation c is p . Every time this happens, we go up one level. Let C ( k ) be the expected length of the return search path at which we moved up k times:
C (0) = 0
C ( k ) = (1- p ) ( the path length in situation b ) + p ( the path length in situations c )
Simplify:
C (k ) = (1- p ) (1 + C ( k )) + p ⋅ (1 + C ( k -1))
C ( k ) = 1 + C ( k ) - p ⋅ C ( k ) + p ⋅ C ( k -1)
C ( k ) = 1 / p + C ( k - 1)
C ( k ) = k / p
Наше предположение о том, что список бесконечный — пессимистично. Когда мы доходим до самого левого элемента, мы просто двигаемся все время вверх, не двигаясь влево. Это даёт нам верхнюю границу (L(n) — 1) /p ожидаемой длины пути от узла с уровнем 1 до узла с уровнем L(n) в списке из n элементов.
Мы используем эти рассуждения, чтобы добраться до узла уровня L(n), но для остальной части пути используются другие рассуждения. Количество оставшихся ходов влево ограничено числом узлов, имеющих уровень L(n), или выше во всем списке. Наиболее вероятное число таких узлов 1/p.
Мы также двигаемся вверх от уровня L(n) до максимального уровня в списке. Вероятность того, что максимальный уровень списка больше k, равна 1-(1-pk)n, что не больше, чем npk. Мы можем вычислить, что ожидаемый максимальный уровень не более L(n) + 1/(1-p). Собирая всё вместе, получим, что ожидаемая длина пути поиска для списка из n элементов
<=L(n)/p + 1/(1-p),
или O(log n).
Количество сравнений
We just calculated the length of the path that we searched. The required number of comparisons per unit is greater than the path length (the comparison occurs at each step of the path).
Probabilistic analysis
We can consider the probability distribution of various search path lengths. Probabilistic analysis is somewhat more complex (it is at the very end of the original article). With it, we can estimate from above the probability that the length of the search path will exceed the expected more than a specified number of times. Analysis results:
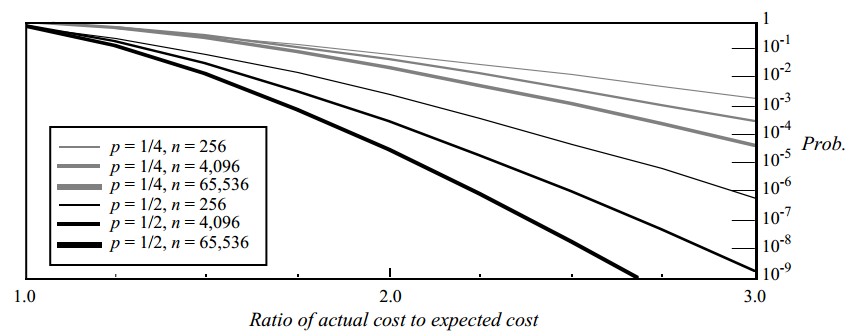
Here is a graph of the upper bound on the probability that the operation will take significantly longer than expected. The vertical axis shows the probability that the length of the search path will be greater than the expected path length by the number of times delayed on the horizontal axis. For example, with p = 1/2 and n = 4096, the probability that the resulting path will be three times longer than expected is less than 1 / 200,000,000.
P choice
The table shows the normalized search times and the amount of required memory for various p values :
| p | Normalized search time (i.e. normalized L ( n ) / p ) | Average number of pointers per node (i.e. 1 / (1 - p )) |
|---|---|---|
| 1/2 | 1 | 2 |
| 1 / e | 0.94 ... | 1.58 ... |
| 1/4 | 1 | 1.33 ... |
| 1/8 | 1.33 ... | 1.14 ... |
| 1/16 | 2 | 1.07 ... |
Decrease p increases time scatter operations. If 1 / p is a power of two, it is convenient to generate a level number from a stream of random bits (on average, (log 2 1 / p ) / (1- p ) random bits are required to generate ). Since there is an overhead related to L ( n ) (but not to L ( n ) / p ), choosing p = 1/4 (instead of 1/2) slightly reduces the constant in the complexity of the algorithm. We recommend choosing p = 1/4, but if the spread in the time of operations is more important for you than speed, then choose 1/2.
Multiple operations
The expected total time of the sequence of operations is equal to the sum of the expected times for each operation in the sequence. Thus, the expected time for any sequence of m search operations in a data structure of n elements is O ( m * log n ). However, the pattern of search operations affects the distribution of the actual time of the entire sequence of operations.
If we look for the same element in the same data structure, then both operations will take exactly the same time. Thus, the variance (scatter) of the total time will be four times greater than the variance of one search operation. If the search times of two elements are independent random variables, then the variance of the total time is equal to the sum of the variances of the times of the execution of individual operations. Searching for the same element again and again maximizes variance.
Performance tests
Compare the performance of skipped lists with other data structures. All implementations have been optimized for maximum performance:
| Data structure | Search | Insert | Delete |
|---|---|---|---|
| skip lists | 0.051 ms (1.0) | 0.065 ms (1.0) | 0.059 ms (1.0) |
| non-recursive AVL trees | 0.046 ms (0.91) | 0.10 ms (1.55) | 0.085 ms (1.46) |
| recursive 2-3 trees | 0.054 ms (1.05) | 0.21 ms (3.2) | 0.21 ms (3.65) |
| Self-regulating trees: | |||
| expanding from top to bottom (top-down splaying) | 0.15 ms (3.0) | 0.16 ms (2.5) | 0.18 ms (3.1) |
| expanding from bottom to top (bottom-up splaying) | 0.49 ms (9.6) | 0.51 ms (7.8) | 0.53 ms (9.0) |
Tests were performed on a Sun-3/60 machine and performed on data structures containing 2 16 elements. The values in parentheses are the time, relative to lists with omissions (in times). For the insertion and deletion tests of elements, the time spent on memory management (for example, on C-th calls of malloc and free) was not taken into account.
Note that skipped lists require more comparison operations than other data structures (the algorithms above require an average of L ( n ) / p + 1 / (1 + p) operations). When using real numbers as keys, operations in skipped lists turned out to be slightly slower than in the non-recursive implementation of the AVL tree, and searches in skipped lists turned out to be slightly slower than searches in the 2-3 tree (however, insertion and deletion in the lists with passes were faster than in the recursive implementation of 2-3 trees). If the comparison operations are very expensive, you can modify the algorithm so that the desired key will not be compared with the key of other nodes more than once per node. For p = 1/2, the upper bound on the number of comparisons is 7/2 + 3/2 * log 2 n .
Unequal distribution of requests
Self-regulating trees can adapt to uneven distribution of requests. Since lists with passes are faster than self-regulating trees by a large number of times, self-regulating trees are faster only with some very uneven distribution of queries. We could try to develop self-regulating lists with omissions, however, we did not see any practical sense in this and did not want to spoil the simplicity and performance of the original implementation. If the application expects uneven requests, then using self-regulating trees or adding caching will be preferable.
Conclusion
From a theoretical point of view, skip lists are not needed. Balanced trees can do the same operations and have good complexity in the worst case (as opposed to skipped lists). However, the implementation of balanced trees is a difficult task and, as a result, they are rarely implemented in practice, except as laboratory work at universities.
Skipped lists are a simple data structure that can be used instead of balanced trees in most cases. Algorithms are very easy to implement, extend and modify. The usual implementation of operations on skipped lists is about as fast as the highly optimized implementations on balanced trees and is significantly faster than the usual, not highly optimized implementations.