Synthesis of an optimal facial recognition algorithm
Content:
1. Search and analysis of the color space optimal for constructing prominent objects on a given class of images
2. Determination of the dominant signs of classification and the development of a mathematical model of facial expressions "
3. Synthesis of an optimal recognition algorithm for facial expressions
4. Implementation and testing of the facial recognition algorithm
5. Creation of a test database lip images of users in various states to increase the accuracy of the system
6. Search for the optimal audio speech recognition system based on open source passcode
7.Search for an optimal audio recognition system for speech recognition with closed source code, but with open APIs, for integration
8. Experiment of integrating a video extension into an audio recognition system with speech test protocol
Goals
Determine the most optimal algorithm for its subsequent implementation and testing in the recognition of facial expressions.
Tasks
To analyze the existing video recognition algorithms of the human face and its characteristics, taking into account the dominant features of classification and the mathematical model defined by us. Based on the data obtained, choose the optimal version of the visual recognition algorithm for its subsequent implementation for our tasks of implementing facial recognition technology for mobile devices or computers.
Topic
Since we are faced with the task of implementing a productive facial recognition system for mobile devices, when choosing the optimal algorithm for solving this problem, we should proceed from the following:
• Low resolution and high noise level (typical for most front-facing VGA cameras of smartphones and PCs);
• Low production requirements of mobile devices and computers for computing data at a frequency of 25 frames per second;
• High speed (for online video processing).
Based on the above conditions, when choosing the optimal algorithm for facial recognition tasks, we need to focus on a reliable algorithm that has minimal system requirements and is highly efficient. Also, when synthesizing the optimal facial recognition algorithm to solve the problem, we must take into account our experience that we gained in the previous stages of the study.
Let us present the scheme of the processing and subsequent analysis of the image in the form of a table (Fig. 1). At the same time, at this stage of the study, we should determine the column that we repainted blue for simplicity — that is, choose the optimal matrix recognition algorithm:
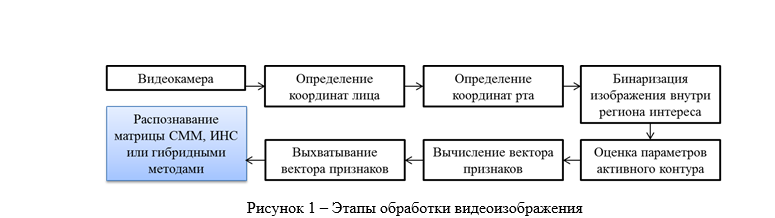
But before proceeding with the selection of the optimal algorithm for our facial recognition tasks, we should explain the mechanism of snatching the feature vector.
Snatching feature vector
After the image was binarized at the previous stages and the lip contour was selected, the so-called n-point overlap procedure is performed, numbered p1 to pn clockwise. The used coordinates of the points are normalized: the middle point of the ellipse is considered the origin, the x axis is directed towards the larger radius of the ellipse, the large radius of the ellipse is considered to be one. In addition to the coordinates of the points, in the process of isolating the contours of the lips are the parameters of the ellipse that describes the region of the lips in the original image. The parameters of the ellipse allow us to draw conclusions about such general parameters of the mouth area as open mouth or closed. The numbering of the contour begins at the intersection of the lip contour with the left large radius of the ellipse.
Then we search for angles (Fig. 2). Among the points obtained, it is necessary to determine the right and left angle. Despite the numbering of points, these are not always points p1 and pn / 2. The right angle is the point located in the right half of the contour (between pn / 4 and p3n / 4), at which the angle α is the smallest. Angle α is the angle between the mean qnext and qprev. Here qnext = (pi + 1 + ... + pi + k) / k, qprev = (pi-1 + ... + pi-k) / k, k = n / 5. A similar rule is used for the left corner [1].
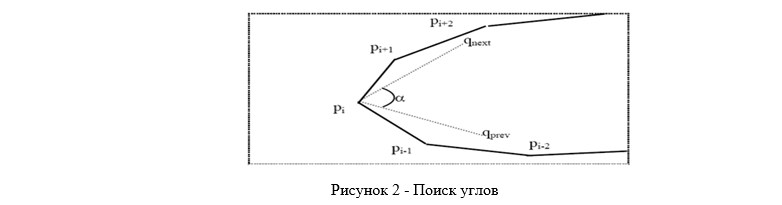
The next step after finding the angles is to convert the set of source data into a set of feature vectors. As the first few elements in the feature vector, features are used that are obtained separately from the coordinates — the ratio of the height of the ellipse of the lip area to its width. Further elements of the feature vector are the coordinates of the left and right angles of the contour, the coordinates of the upper and lower points of the contour, and the coordinates of the remaining points of the contour. Consider the analysis of the data obtained by the method of principal components. The selection of the basis by the method of principal components allows one to find the main directions along which the feature vectors change. This makes it possible to significantly reduce the dimension of feature vectors. The principal component method is applied to a set of feature vectors obtained from a data set that reflects most of the possible lip conditions.
Now consider the most common algorithms for recognizing a human face and its characteristics:
Algorithms based on the method of hidden Markov models (Hidden Markov Models)
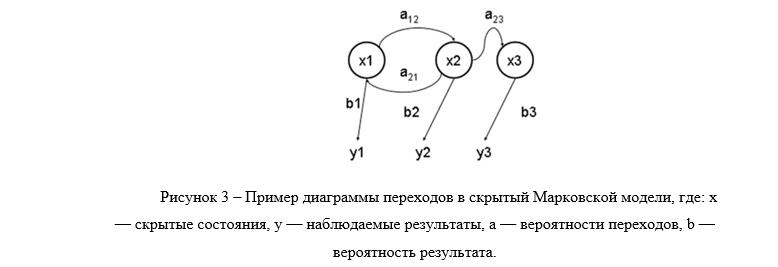
The Hidden Markov Model (SMM) is a statistical model that simulates the operation of a process similar to the Markov process with unknown parameters, and the task is to solve unknown parameters based on observables.
Each feature vector must be associated with a symbol of the hidden Markov model (Fig. 3). To do this, we use the vector quantization method. Using this method, the space of feature vectors is divided into clusters, by the principle of proximity to the centers of clusters - by code words. A set of codewords is called a codebook. The main difficulty of the method is to build a codebook of vectors. The size of the codebook is determined by the number of lip states in the source data. A codebook of known size k is constructed by the K average algorithm [2].
At the first step of the algorithm, k vectors are randomly selected, which are considered code words (cluster centers). In the next step, each input vector is assigned to the cluster whose codeword is at the smallest distance from it. In the third step, the code words of each cluster are recounted. Each codeword is made equal to the arithmetic mean among all vectors of the cluster. The second and third steps are repeated until the codeword changes are sufficiently small.
This algorithm is slow, but the application of the analysis of the main components before quantization allows one to reduce the dimension and, thereby, significantly accelerate the process of building the codebook [3]. The new initial data are quantized before being used in the recognition process: each vector is associated with the nearest vector from the codebook, and then instead of the vector, its index in the codebook is used as a symbol of the hidden Markov model.
Image recognition cannot work at the viseme level, as visemes for different phonemes are fairly close. Moreover, recognition based on sequences of visemes — diphons, trifons — is much more reliable [4]. For recognition, a system of ergodic hidden Markov models is used [5]. Each diphon has its own SMM. SMMs are initialized with equal probabilities for symbols and state transitions. However, such a model, due to the high degree of freedom, is poorly tuned to the training data, which negatively affects the quality of recognition [6].
The SMM system is trained using a sequence of quantized feature vectors. The initial data is manually divided into trained diphons, after which the corresponding SMM is updated using the Baum – Welsh algorithm [7]. The resulting SMM gives the maximum probability values on sequences close to the set for training your diphon.
As a result of the work, an effective algorithm is constructed for constructing lip feature vectors for the speech recognition problem. The algorithm allows you to convert the lip contour data into sets of features suitable for recognition. The algorithm has the properties of reliability and stability and is easily integrated with a speech recognition system based on hidden Markov models. However, it should be noted the weaknesses of this algorithm, in particular, it is characterized by a weak discriminating ability and poorly trained.
Algorithms based on the method of Neural networks (Artificial neural networks)
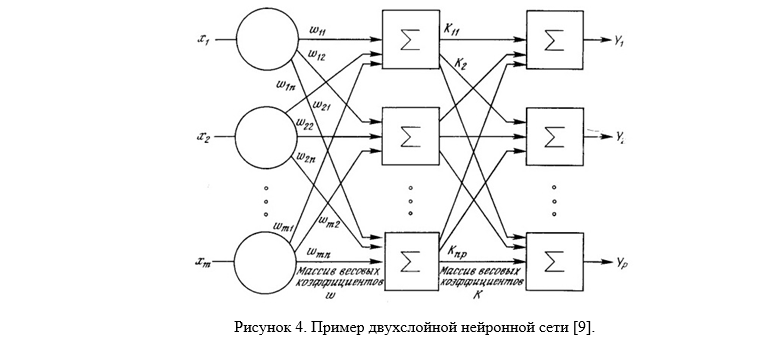
Neural network methods are methods based on the use of various types of neural networks (NS). NS consists of elements called formal neurons, which themselves are very simple and connected with other neurons. Each neuron converts a set of signals arriving at it at the entrance to the output signal. It is the connections between the neurons encoded by the weights that play a key role. One of the advantages of NS (as well as the disadvantage of implementing them on a sequential architecture) is that all elements can function in parallel (Fig. M.4), thereby significantly increasing the efficiency of solving the problem, especially in image processing. In addition to the fact that NSs can effectively solve many problems, they provide powerful flexible and universal learning mechanisms, which is their main advantage over other methods. Also, among other advantages of the neural network, it is necessary to recognize the possibility of obtaining a classifier that well models the complex distribution function of facial images. The disadvantage is the need for careful and painstaking tuning of the neural network to obtain a satisfactory classification result [8].
Combined Method Algorithms
Given the advantages and disadvantages of algorithms based on hidden Markov models and neural networks, recently in the scientific world of recognition on a given class of images, hybrid algorithms have gained popularity. According to research data, hybrid ANNs / SMM recognizers increase the accuracy of traditional SMMs by modeling correlations between simultaneous signal parameters and between current and next parameters [10]. That is, the SMM provides the ability to model long-term dependencies, and the ANN provides a nonparametric universal approximation, probability estimation, discriminant learning algorithms, and a decrease in the number of parameters for evaluation that are usually required for standard SMMs [11]. However, when choosing a combined algorithm, you must keep in mind
Conclusion
To determine the optimal algorithm for the facial recognition problem, we first examined in detail the simplest and most reliable mechanism for grabbing the feature vector for subsequent analysis by matrix algorithms. At the next stage, we examined and analyzed the advantages and disadvantages of the most famous models for constructing the algorithm: hidden Markov models, artificial neural networks, hybrid algorithms. Having studied the existing approaches and solutions in the field of processing feature vectors, we settled on combined data processing methods, which in our opinion are the most effective for our solution: implementing a reliable and fast facial recognition system for mobile devices and computers.
List of sources used
1. Soldatov S. Lip reading: preparing feature vectors. Graphics & Media Laboratory MSU, 2003
2. A. Linde, R. Gray. An algorithm for vector quantization design.// IEEE Transactions on Communicatinos COM-28, 1980
3. Soldatov S. Lip reading: preparing feature vectors. Graphics & Media Laboratory MSU, 2003
4. Ibid.
5. Gultyaeva T.A., Popov A.A. Modifications of one-dimensional hidden Markov models for face recognition // 16th International Conference on Computer Graphics and Computer Vision - GRAPHICON, 2006
6. K. Sobottka and I. Pitas, A novel method for automatic face segmentation, facial feature extraction and tracking, Signal processing: Image communication, Vol. 12, No. 3, pp. 263-281, June, 1998
7. Gultyaeva T.A., Popov A.A. Modifications of one-dimensional hidden Markov models for face recognition // 16th International Conference on Computer Graphics and Computer Vision - GRAPHICON, 2006
8. Makarenko A.A. Classification of images by a highly accurate neural network. Scientific Session - TUSUR-2006. Mater. Vseros. scientific and technical conf. students, graduate students and young specialty. Part 1. Tomsk, 2005.
9. F. Wassermen. Neurocomputer technology: theory and practice (Translated into Russian by Zuyev Yu.A., Tochenov V.A.), 1992.
10. Osetrov V.P. Audiovisual speech recognizer.// Human resources for the development of innovative activity in Russia. Ershovo, M., 2010.
11. Makovkin K.A. Hybrid models: hidden Markov models and neural networks, their application in speech recognition systems.// Models, methods, algorithms and architectures of speech recognition systems. Will calculate. center them. A.A. Dorodnitsyna, M., 2006.
To be continued.