Modern back office of IT company
In one of the discussions recently, I listed the main systems that make the work of an IT company civilized. The list was very extensive, and I decided to design it as an independent article.
A similar design can be seen in many companies, moreover, I observed companies in which a part of these systems was absent for a long time, and because of unsolvable constant problems, these systems began to appear spontaneously.
All of the following applies to companies / departments in which qualified personnel work, that is, they do not need “office for beginners” courses. Just as you do not need group policies on workstations and a special admin for shifting shortcuts on the desktop and installing your favorite program. In other words, this is the back office of IT specialists, significantly different from the back office of other departments.
Short content spoiler: VCS, source code repository, code-review, build server, CI, task tracker, wiki, corporate blog, functional testing, package repository, configuration management system, backups, mail / jabber.
Picture with a fragment of the infrastructure under discussion:
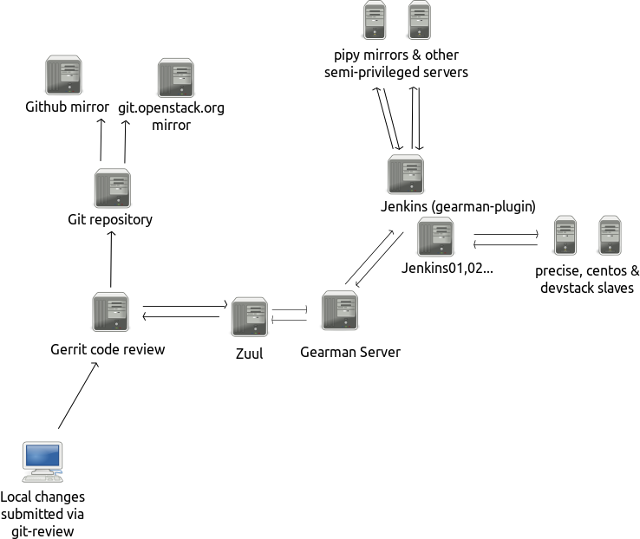
So, let's start with a simple one.
Workplaces: a computer with buttons (about 90-100 pcs) for each workplace. An external / second / third monitor is also desirable. Usually used laptops, very widely - MacBooks. Users have an admin or sudo on their machines, they decide for themselves a set of convenient software, including an editor, a debugger, an email client, a browser, a terminal, etc.
The Internet. Usually in the office there is WiFi and BYOD (in other words, freely brought their own laptops, tablets and phones that abuse office WiFi). Often there may not be a wired network at all. Security in such a network is conditional, because all communications go encrypted. Internet needs a lot. And not only for seals on YouTube during working hours, but also for a suddenly urgent "right now download a DVD with raw materials to compare the version of the package." From real life, by the way. Given all sorts of stackoverflow and other IT resources, the Internet should be unlimited, uncontrolled, and the faster the better.
We drove the simple. Further serious.
Version control system (VCS) should be general, "to each his own" will not work here. The de facto standard - git, conditionally popular mercurial (hg), exotic bazar (bzr), from the last century svn / cvs / vcs. Plus, the winery has its own world, there is something else.
The version control system works locally, so there should be a central source code repository that everyone is pushing into (who should push). Very and very popular is gitlab. There are proprietary solutions, there is github for those who are lazy to raise themselves. She decides the second important thing: pull requests. So that one person can see what another has done before it gets to the main branch (shared repository). I note that pull requests make sense even if a code review is not carried out as such. The principle is simple - one wrote, the other smerdzhil (merge).
If the code is complex, then you need a system for code review. Code review implies that programmers (or sysadmins - devops, all that) look at each other's code, and there is some formal procedure for accepting the code - for example, “at least two people should look and approve, one of them must be a senior / lead”. Examples: gerrit, Crucible. If complexity is balancing on the edge, then you can try to comply with the agreement voluntarily, discussing in the comments in gitlab. But like everything is voluntary, for which robots do not follow, it will sometimes misfire.
Managing a team of people in a minimal form is carried out through the task scheduler (task-tracker) - redmine, jira, mantis. Most often it also performs the role of a bug trackera. The main goal is to formalize the statement of the problem, remove ambiguities and find the perpetrators when someone did something wrong (did you say that? No, I didn’t understand it! - after that the task text looks and it becomes clear who missed). In the case of a task tracker, verbal law should be carefully eliminated, especially from the head / team lead. Need to change something? Set a task. The volume of bureaucracy is minimal, the amount of chaos decreases by multiple.
You can almost consider having your own wiki- mediawiki, moin-moin, confluence, dokuwiki - anything where you can write articles that are visible to other team members, and where you can edit after others. An ideal place for folding the texts “how to do this”, regulations, discussion results, planned architectural solutions, explaining why this will be done in this way and not otherwise. A well-structured wiki is good, but even a messy pile of texts is several times more useful than an oral tradition, which fades away with a retired employee who “knew all this.”
If the wiki supports blogging, well, if not, you should either agree on a blogging formaton the wiki, or raise something for its internal management. What to write in such a blog? Spent 4 hours catching a strange bug in the config? Describe in a blog - the next time you yourself will search, because you will read quickly, but do it yourself slowly. Have you started to deal with a long, long problem that cannot be completely kept in your head? Instead of a text editor on a computer as a notebook, write on a wiki. Sometimes it may turn out that one of the colleagues will read what has already been written and say a shorter solution right in the process of debugging. And at some point, the company's blog will become perhaps the most valuable resource in difficult situations (No. 2 after the Internet).
Writing code that works on the workstation on which it was written is a rare luxury. Most often (and the farther, the more) the code is a middleware - a layer between other large pieces of server code, and requires an extensive environment for productive work. "This debugging application needs mysql with a copy of the working base, memcached, redis and snmp to the switch." Raising such an environment at a workstation is still a pleasure. And it happens that there are several projects, and each has its own environment.
Thus, we get the first difficult thing: stands for programmers. In real life, it can be a usb-connected microcontroller or a hadoop server farm. It is important that the programmer has his stand, which is at least somewhat similar to the working configuration, where the programmer can check the results of his work immediately, as he wrote. It’s not worth saving, and each programmer should have his own stand. If it’s too expensive - you need to raise mocapas, if mocapas cannot be raised, then the company has problems - programmers write "on production", and if there are several programmers, then at the same time. If programmers are not allowed into production, then they write blindly - goodbye to productivity.
Next, there is the question of how the code appears on production. Most often these are packages (deb / rpm), executable files (exe), or just boring layout (html). Note that it makes sense even to “wrap the static stuff” into a package. There are teams that spread directly from the git (a specific brunch, tag, or even a master, with the assumption that development takes place in other brunches).
Building packages can be very confusing and complicated, especially if the code is not written from scratch, but depends on existing configurations and a bunch of other packages. It makes sense to set up a package build system. To do this, use CI (continuous integration) in a minimal configuration, often with manual control (go to the interface and click on "run task" of package assembly). The standard for opensource is jenkins. Of the most famous proprietary ones - team city. The minimal configuration just takes the specified brunch / tag / repository and collects the package. Which can then be downloaded from the CI’s interface.
But everyone is used to aptitude install - and for this you need to raise your mirror , or package repository. The same CI can upload packages to the repository. Click with the mouse - and the source code can be put on all servers where the repository is connected. Note that the presence of repositories allows you to quickly "roll out" the application on a large number of servers in automatic or semi-automatic mode, and even have a separation into experimental / testing / production / oldstable. It also makes it possible to repair damage very quickly, since the package managers have all the necessary tools to validate the integrity of the installed files and can download the package again and restore the modified files (note to webmasters who have all kinds of evil backdoors in WordPress spoil their favorite php files ) If during assembly you need packages that are not in the distribution, then they should also be packaged. Production, the rise of which depends on the pypi uptime, is a sad sight. Note
CI, at the same time, can run tests. Unit tests are most often run at the stage of package assembly (after compilation). But for functional (acceptance) tests, you need to raise (one more, or even many different) test environment . After successful compilation, the installation of the package on the stand and a test for operability are started. If the company has resources, then for every strange bug a test is done that will catch it. In a minimal form, you need to check the basic happy paths, that is, "the customer can come, see the goods, put in the basket, pay and buy." Any sad path (the client has no money / the kernel version does not correspond to the module) can also be checked, but it is much more resources. But even happy path tests greatly improve stability.
If there are many configurations and tests, then it makes sense to raise the integration of the code-review system with tests . The most famous is zuul, which binds gerrit to jenkins. In this case, a proposal for a code review is sent only after the programmer’s (system administrator's) commit has passed the tests - people’s time is saved, not to mention that the lion's number of simple bugs are caught at the “fight with gerrit” stage. An ideal example of how this works for hundreds of independent developers is the openstack project infrastructure .
If the tests are configured, the code review is worked out, there is always a previous version, then it makes sense to think about continuous integration, in its original sense, that is, automatically rolling out changes to production immediately after the tests and code review passed.
This usually requires mail, jabber (with which it would be nice to link the task tracker and CI), possibly mailings. It often makes sense to raise your vpn server so that people can work from anywhere without difficulty with closed ports, etc.
Why "your" when there is Google Mail? Well, because when they start mysteriously not receiving letters from nagios, because Google does not like bulk messages for group address, then the fight against Google may take longer than your mail server.
And, of course, all this comes with its own meta-infrastructure:
Here is a modest economy with a good IT company. Note that these are only working tools, there are no “user directories” (and, in general, the issue of authorization was not dealt with), access control systems, time tracking, salaries, business planning and other things that are not needed by developers / system administrators, but to stakeholders.
I think in man-hours, multiply by s / n. The numbers are extremely approximate (that is, taken from the ceiling):
Note that this is pure refined time (which is not so much). In addition, many things require the involvement of all employees, that is, they cannot be allocated to a separate special person, that is, the implementation time will be smeared on top of the usual work.
Provided that approximately 30% of the working time will be allocated to its own infrastructure (this is a lot), the implementation from scratch will take from three months to a year. This is with constant enthusiasm, if there are pauses, the time increases (disproportionately to the downtime, because everything around changes and after a pause you will have to redo a lot). Once again taking a salary from the same ceiling, taking into account vacations / sick leave / emergency, we get about 1-2 million rubles, without the cost of iron, electricity and licenses, only for work (the figure takes into account the costs of “white” taxes and fees).
About the price of escort. Very much depends on investments in a configuration management system, backups and thorough implementation. In a good system, it should be no more than a few hours per month, plus the separate costs of adding new projects, configurations, changing existing ones, etc.
How many servers do you need? The answer depends heavily on test configurations, if we assume that the test configuration is a small LAMP server (1 GB of memory for everything), then with a tight packing of virtual machines you can get by with 2-5 servers (~ 200-300 tr. each) for everything, plus a separate backup server. Oh, yes, add to the list of configuration works, still maintaining this stack of virtual machines and virtualizers.
All this, of course, pales in comparison with the cost of one job for a tower crane operator (6 million rubles) or a high-precision robotic milling and drilling machine (I did not even find prices in the public domain for example).
Can I save and not do it?
Can.
Moreover, nothing fatal will happen. However, some work processes will be longer, some will be tedious (sending zip changes to each other by mail), a number of employees will be forced to be present in the office in order to do something (for example, to coordinate changes in the code), one illness of employees can greatly complicate the lives of others (and who was here, who knew how to roll out the changes correctly?). The quality of the code will partially suffer or the speed of the programmers will decrease. Some very cool things will simply not be available, but without them it will be fine. Some of the employees will be busy with low-productive work, and because of this, not only not to do what they are paid for, but also to demotivate, because it is monotonous, boring, fraught with mistakes, the process at work, repeated from time to time, is simply an excellent occasion for the implementation of the above. Or resume updates, yes.
Like all capital investments in labor efficiency, all of these systems are optional. In the end, rockets into space successfully launched with some kind of attempt there and without git with code review and tests.
Companies often follow the path of introducing such systems gradually, and it would be a big mistake to start a startup with a three-month lift of the entire infrastructure without writing a single useful line of code.
Often stop at some stage. They are usually caused by staff reluctance, because they (the staff) do not have the pain that the system should eliminate. If there really is no pain - excellent, you can save on particularly advanced complex things. If there is “no pain” because a person has never tried “differently”, then it may be that the stoppage was caused only by a lack of qualifications.
Note that if ignorance of the git can be considered an analogue of illiteracy or slurred speech, that is, a programmer who does not know how to use git, is either very “special” (1C, SAP), or not very programmer, then the “ignorance” of gerrit is quite understandable and will require training. The higher the level of process integration, the greater the chance that a critical mass of employees will simply not want to learn so much. Unlike bookkeepers, system administrators and programmers are trained quite quickly, but if “fast” does not work, then the resistance can be much greater than the indignant groans from changing the 1C version. There is nothing worse than key technical personnel who are indignant at the mandatory implementation of an unsuccessful technical solution.
Most often, new implementations occur in the presence of enthusiasm from one of the employees, or completely unbearable pain, which is not masked in sabotage, but expressed explicitly to colleagues / superiors.
Note that the text above describes the back office, because issues of monitoring production, building logs from there, download metrics and other smart things are not considered at all in this article.
PS Oh yes, I almost forgot - in the list of equipment - I still need a printer in the office to print vacation applications.
A similar design can be seen in many companies, moreover, I observed companies in which a part of these systems was absent for a long time, and because of unsolvable constant problems, these systems began to appear spontaneously.
All of the following applies to companies / departments in which qualified personnel work, that is, they do not need “office for beginners” courses. Just as you do not need group policies on workstations and a special admin for shifting shortcuts on the desktop and installing your favorite program. In other words, this is the back office of IT specialists, significantly different from the back office of other departments.
Short content spoiler: VCS, source code repository, code-review, build server, CI, task tracker, wiki, corporate blog, functional testing, package repository, configuration management system, backups, mail / jabber.
Picture with a fragment of the infrastructure under discussion:
So, let's start with a simple one.
Workplaces: a computer with buttons (about 90-100 pcs) for each workplace. An external / second / third monitor is also desirable. Usually used laptops, very widely - MacBooks. Users have an admin or sudo on their machines, they decide for themselves a set of convenient software, including an editor, a debugger, an email client, a browser, a terminal, etc.
The Internet. Usually in the office there is WiFi and BYOD (in other words, freely brought their own laptops, tablets and phones that abuse office WiFi). Often there may not be a wired network at all. Security in such a network is conditional, because all communications go encrypted. Internet needs a lot. And not only for seals on YouTube during working hours, but also for a suddenly urgent "right now download a DVD with raw materials to compare the version of the package." From real life, by the way. Given all sorts of stackoverflow and other IT resources, the Internet should be unlimited, uncontrolled, and the faster the better.
We drove the simple. Further serious.
Version control system (VCS) should be general, "to each his own" will not work here. The de facto standard - git, conditionally popular mercurial (hg), exotic bazar (bzr), from the last century svn / cvs / vcs. Plus, the winery has its own world, there is something else.
The version control system works locally, so there should be a central source code repository that everyone is pushing into (who should push). Very and very popular is gitlab. There are proprietary solutions, there is github for those who are lazy to raise themselves. She decides the second important thing: pull requests. So that one person can see what another has done before it gets to the main branch (shared repository). I note that pull requests make sense even if a code review is not carried out as such. The principle is simple - one wrote, the other smerdzhil (merge).
If the code is complex, then you need a system for code review. Code review implies that programmers (or sysadmins - devops, all that) look at each other's code, and there is some formal procedure for accepting the code - for example, “at least two people should look and approve, one of them must be a senior / lead”. Examples: gerrit, Crucible. If complexity is balancing on the edge, then you can try to comply with the agreement voluntarily, discussing in the comments in gitlab. But like everything is voluntary, for which robots do not follow, it will sometimes misfire.
Managing a team of people in a minimal form is carried out through the task scheduler (task-tracker) - redmine, jira, mantis. Most often it also performs the role of a bug trackera. The main goal is to formalize the statement of the problem, remove ambiguities and find the perpetrators when someone did something wrong (did you say that? No, I didn’t understand it! - after that the task text looks and it becomes clear who missed). In the case of a task tracker, verbal law should be carefully eliminated, especially from the head / team lead. Need to change something? Set a task. The volume of bureaucracy is minimal, the amount of chaos decreases by multiple.
You can almost consider having your own wiki- mediawiki, moin-moin, confluence, dokuwiki - anything where you can write articles that are visible to other team members, and where you can edit after others. An ideal place for folding the texts “how to do this”, regulations, discussion results, planned architectural solutions, explaining why this will be done in this way and not otherwise. A well-structured wiki is good, but even a messy pile of texts is several times more useful than an oral tradition, which fades away with a retired employee who “knew all this.”
If the wiki supports blogging, well, if not, you should either agree on a blogging formaton the wiki, or raise something for its internal management. What to write in such a blog? Spent 4 hours catching a strange bug in the config? Describe in a blog - the next time you yourself will search, because you will read quickly, but do it yourself slowly. Have you started to deal with a long, long problem that cannot be completely kept in your head? Instead of a text editor on a computer as a notebook, write on a wiki. Sometimes it may turn out that one of the colleagues will read what has already been written and say a shorter solution right in the process of debugging. And at some point, the company's blog will become perhaps the most valuable resource in difficult situations (No. 2 after the Internet).
Writing code that works on the workstation on which it was written is a rare luxury. Most often (and the farther, the more) the code is a middleware - a layer between other large pieces of server code, and requires an extensive environment for productive work. "This debugging application needs mysql with a copy of the working base, memcached, redis and snmp to the switch." Raising such an environment at a workstation is still a pleasure. And it happens that there are several projects, and each has its own environment.
Thus, we get the first difficult thing: stands for programmers. In real life, it can be a usb-connected microcontroller or a hadoop server farm. It is important that the programmer has his stand, which is at least somewhat similar to the working configuration, where the programmer can check the results of his work immediately, as he wrote. It’s not worth saving, and each programmer should have his own stand. If it’s too expensive - you need to raise mocapas, if mocapas cannot be raised, then the company has problems - programmers write "on production", and if there are several programmers, then at the same time. If programmers are not allowed into production, then they write blindly - goodbye to productivity.
Next, there is the question of how the code appears on production. Most often these are packages (deb / rpm), executable files (exe), or just boring layout (html). Note that it makes sense even to “wrap the static stuff” into a package. There are teams that spread directly from the git (a specific brunch, tag, or even a master, with the assumption that development takes place in other brunches).
Building packages can be very confusing and complicated, especially if the code is not written from scratch, but depends on existing configurations and a bunch of other packages. It makes sense to set up a package build system. To do this, use CI (continuous integration) in a minimal configuration, often with manual control (go to the interface and click on "run task" of package assembly). The standard for opensource is jenkins. Of the most famous proprietary ones - team city. The minimal configuration just takes the specified brunch / tag / repository and collects the package. Which can then be downloaded from the CI’s interface.
But everyone is used to aptitude install - and for this you need to raise your mirror , or package repository. The same CI can upload packages to the repository. Click with the mouse - and the source code can be put on all servers where the repository is connected. Note that the presence of repositories allows you to quickly "roll out" the application on a large number of servers in automatic or semi-automatic mode, and even have a separation into experimental / testing / production / oldstable. It also makes it possible to repair damage very quickly, since the package managers have all the necessary tools to validate the integrity of the installed files and can download the package again and restore the modified files (note to webmasters who have all kinds of evil backdoors in WordPress spoil their favorite php files ) If during assembly you need packages that are not in the distribution, then they should also be packaged. Production, the rise of which depends on the pypi uptime, is a sad sight. Note
CI, at the same time, can run tests. Unit tests are most often run at the stage of package assembly (after compilation). But for functional (acceptance) tests, you need to raise (one more, or even many different) test environment . After successful compilation, the installation of the package on the stand and a test for operability are started. If the company has resources, then for every strange bug a test is done that will catch it. In a minimal form, you need to check the basic happy paths, that is, "the customer can come, see the goods, put in the basket, pay and buy." Any sad path (the client has no money / the kernel version does not correspond to the module) can also be checked, but it is much more resources. But even happy path tests greatly improve stability.
If there are many configurations and tests, then it makes sense to raise the integration of the code-review system with tests . The most famous is zuul, which binds gerrit to jenkins. In this case, a proposal for a code review is sent only after the programmer’s (system administrator's) commit has passed the tests - people’s time is saved, not to mention that the lion's number of simple bugs are caught at the “fight with gerrit” stage. An ideal example of how this works for hundreds of independent developers is the openstack project infrastructure .
If the tests are configured, the code review is worked out, there is always a previous version, then it makes sense to think about continuous integration, in its original sense, that is, automatically rolling out changes to production immediately after the tests and code review passed.
Final chords
This usually requires mail, jabber (with which it would be nice to link the task tracker and CI), possibly mailings. It often makes sense to raise your vpn server so that people can work from anywhere without difficulty with closed ports, etc.
Why "your" when there is Google Mail? Well, because when they start mysteriously not receiving letters from nagios, because Google does not like bulk messages for group address, then the fight against Google may take longer than your mail server.
And, of course, all this comes with its own meta-infrastructure:
- All this needs to be configured. In the mind - a configuration management system . chef, puppet, ansible, saltstack.
- All this needs to be monitored. Monitoring - nagios, shinken, zabbix, icinga
- This all needs to be backed up. Yes, the repositories also need to be backed up, because it’s a pleasure to collect 20-30 repositories from developers with “who has the latest version”. And comments in merge requests are generally unrecoverable.
- All this requires domain names, and it’s better that the domain or subdomain is in full control of the department, so that with each new A-record you don’t have to go and munch “Well, add me another stand in the DNS”. Own DNS opens up another important opportunity to generate records automatically (for example, for addresses of ipmi-interfaces of servers)
Here is a modest economy with a good IT company. Note that these are only working tools, there are no “user directories” (and, in general, the issue of authorization was not dealt with), access control systems, time tracking, salaries, business planning and other things that are not needed by developers / system administrators, but to stakeholders.
And how much does it cost?
I think in man-hours, multiply by s / n. The numbers are extremely approximate (that is, taken from the ceiling):
- Employee’s workplace - 8 hours per person (usually counted on the “first working day”)
- gitlab - 4-8 hours
- gerrit - 16-24 hours
- jenkins (base) - 2-4 hours
- jenkins (building packages) - 1-32 hours per repository (depends on the repository and the number of ones already raised - the first ones are difficult to lift, the further it is easier)
- own repository - 2-4 hours
- wiki - 1-16 hours
- blog system - 2-4 hours
- task tracker - 1-8 hours
- stands for programmers - ???
- test stands - ???
- test run setup (subject to availability) - 1-2 hours
- zuul - 2-16 hours
- jabber server - 1-4 hours
- mail server - 0.5-12 hours (depending on size and role)
- Newsletters - 1-3 hours
- configuration management system - x2 from each point (except for package assembly)
- backup - ~ 1 hour for each service
- dns to it all +1 hour
Note that this is pure refined time (which is not so much). In addition, many things require the involvement of all employees, that is, they cannot be allocated to a separate special person, that is, the implementation time will be smeared on top of the usual work.
Provided that approximately 30% of the working time will be allocated to its own infrastructure (this is a lot), the implementation from scratch will take from three months to a year. This is with constant enthusiasm, if there are pauses, the time increases (disproportionately to the downtime, because everything around changes and after a pause you will have to redo a lot). Once again taking a salary from the same ceiling, taking into account vacations / sick leave / emergency, we get about 1-2 million rubles, without the cost of iron, electricity and licenses, only for work (the figure takes into account the costs of “white” taxes and fees).
About the price of escort. Very much depends on investments in a configuration management system, backups and thorough implementation. In a good system, it should be no more than a few hours per month, plus the separate costs of adding new projects, configurations, changing existing ones, etc.
How many servers do you need? The answer depends heavily on test configurations, if we assume that the test configuration is a small LAMP server (1 GB of memory for everything), then with a tight packing of virtual machines you can get by with 2-5 servers (~ 200-300 tr. each) for everything, plus a separate backup server. Oh, yes, add to the list of configuration works, still maintaining this stack of virtual machines and virtualizers.
All this, of course, pales in comparison with the cost of one job for a tower crane operator (6 million rubles) or a high-precision robotic milling and drilling machine (I did not even find prices in the public domain for example).
Does it really need it?
Can I save and not do it?
Can.
Moreover, nothing fatal will happen. However, some work processes will be longer, some will be tedious (sending zip changes to each other by mail), a number of employees will be forced to be present in the office in order to do something (for example, to coordinate changes in the code), one illness of employees can greatly complicate the lives of others (and who was here, who knew how to roll out the changes correctly?). The quality of the code will partially suffer or the speed of the programmers will decrease. Some very cool things will simply not be available, but without them it will be fine. Some of the employees will be busy with low-productive work, and because of this, not only not to do what they are paid for, but also to demotivate, because it is monotonous, boring, fraught with mistakes, the process at work, repeated from time to time, is simply an excellent occasion for the implementation of the above. Or resume updates, yes.
Like all capital investments in labor efficiency, all of these systems are optional. In the end, rockets into space successfully launched with some kind of attempt there and without git with code review and tests.
Conclusion
Companies often follow the path of introducing such systems gradually, and it would be a big mistake to start a startup with a three-month lift of the entire infrastructure without writing a single useful line of code.
Often stop at some stage. They are usually caused by staff reluctance, because they (the staff) do not have the pain that the system should eliminate. If there really is no pain - excellent, you can save on particularly advanced complex things. If there is “no pain” because a person has never tried “differently”, then it may be that the stoppage was caused only by a lack of qualifications.
Note that if ignorance of the git can be considered an analogue of illiteracy or slurred speech, that is, a programmer who does not know how to use git, is either very “special” (1C, SAP), or not very programmer, then the “ignorance” of gerrit is quite understandable and will require training. The higher the level of process integration, the greater the chance that a critical mass of employees will simply not want to learn so much. Unlike bookkeepers, system administrators and programmers are trained quite quickly, but if “fast” does not work, then the resistance can be much greater than the indignant groans from changing the 1C version. There is nothing worse than key technical personnel who are indignant at the mandatory implementation of an unsuccessful technical solution.
Most often, new implementations occur in the presence of enthusiasm from one of the employees, or completely unbearable pain, which is not masked in sabotage, but expressed explicitly to colleagues / superiors.
Note that the text above describes the back office, because issues of monitoring production, building logs from there, download metrics and other smart things are not considered at all in this article.
PS Oh yes, I almost forgot - in the list of equipment - I still need a printer in the office to print vacation applications.