System.IO.Pipelines: High Performance IO in .NET
- Transfer
System.IO.Pipelines is a new library that simplifies code organization in .NET. It is difficult to ensure high performance and accuracy if you have to deal with complex code. The task of System.IO.Pipelines is to simplify the code. More under the cut!

The library came as a result of the efforts of the .NET Core development team, which sought to make Kestrel one of the fastest web servers in the industry . It was originally conceived as part of the Kestrel implementation, but evolved into a reusable API, available in version 2.1 as the first class BCL API (System.IO.Pipelines).
To properly analyze data from a stream or socket, you need to write a large amount of standard code. At the same time, there are many pitfalls that complicate both the code itself and its support.
Let's start with a simple task. We need to write a TCP server that receives line-delimited messages (\ n) from the client.
REMOVAL: As in any task that requires high performance, each case should be considered based on the characteristics of your application. It is possible that spending resources on the use of various approaches, which will be discussed further, does not make sense if the scale of the network application is not very large.
Normal .NET code before using pipelines looks like this:
see sample1.cs on GitHub
This code will probably work with local testing, but it has some errors:
These are the most common errors in reading streaming data. To avoid them, you need to make a number of changes:
see sample2.cs on GitHub
I repeat: this could work with local testing, but sometimes there are lines longer than 1 KB (1024 bytes). It is necessary to increase the size of the input buffer until a new line is found.
In addition, we collect buffers into an array when processing long strings. We can improve this process using ArrayPool, which will avoid re-allocation of buffers during the analysis of long rows coming from the client.
see sample3.cs on GitHub.
The code works, but now the buffer size has changed, resulting in a lot of copies. More memory is also used, since the logic does not reduce the buffer after processing strings. To avoid this, you can save a list of buffers, and not to change the buffer size each time when lines arrive longer than 1 KB.
In addition, we do not increase the buffer size of 1 KB, until it is completely empty. This means that we will send smaller and smaller buffers to ReadAsync, resulting in an increase in the number of calls to the operating system.
We will try to eliminate this and allocate a new buffer as soon as the size of the existing one is less than 512 bytes:
see sample4.cs on GitHub
As a result, the code becomes much more complicated. During the search for a separator, we monitor the filled buffers. To do this, use the List, which displays the buffered data when searching for a new row delimiter. As a result, ProcessLine and IndexOf will take a List instead of byte [], offset and count. The parsing logic will start processing one or more segments of the buffer.
And now the server will process partial messages and use the combined memory to reduce the total memory consumption. However, a number of changes need to be made:
The difficulty begins to roll off (and this is not all cases!). To create a high-performance network, you need to write very complex code.
The goal of System.IO.Pipelines is to simplify this procedure.
Let's see how System.IO.Pipelines works:
see sample5.cs on GitHub
In the pipeline version of our row reader there are two cycles:
Unlike the first examples, there are no specially assigned buffers. This is one of the main features of System.IO.Pipelines. All buffer management tasks are passed to PipeReader / PipeWriter implementations.
The procedure is simplified: we use code only for business logic, instead of implementing complex buffer management.
The first loop first calls PipeWriter.GetMemory (int) to get a certain amount of memory from the main recorder. Then PipeWriter.Advance (int) is called, which tells PipeWriter how much data is actually written to the buffer. This is followed by a call to PipeWriter.FlushAsync () so that PipeReader can access the data.
The second loop consumes buffers that were recorded by PipeWriter, but initially came from a socket. When a request is returned to PipeReader.ReadAsync (), we get a ReadResult containing two important messages: data read in the form ReadOnlySequence, as well as the logical data type IsCompleted, which tells the reader whether the recorder has finished the job (EOF). When the end-of-line (EOL) separator is found and the string is analyzed, we divide the buffer into parts to skip the already processed fragment. After that, PipeReader.AdvanceTo is called, and it tells PipeReader how much data has been consumed.
At the end of each cycle, the work of both the reader and the recorder is completed. As a result, the main channel frees all allocated memory.
In addition to memory management, System.IO.Pipelines performs another important function: it looks at the data in the channel, but does not consume it.
PipeReader has two main APIs: ReadAsync and AdvanceTo. ReadAsync receives data from the channel, AdvanceTo informs PipeReader that these buffers are no longer required by the reader, so you can get rid of them (for example, return to the main buffer pool).
Below is an example HTTP analyzer that reads data from the channel partial data buffers until it gets a suitable starting line.

The channel implementation stores a list of associated buffers that are transferred between PipeWriter and PipeReader. PipeReader.ReadAsync reveals ReadOnlySequence, which is a new BCL type and consists of one or more ReadOnlyMemory <T> segments. It is similar to Span or Memory, which gives us the opportunity to look at arrays and strings.
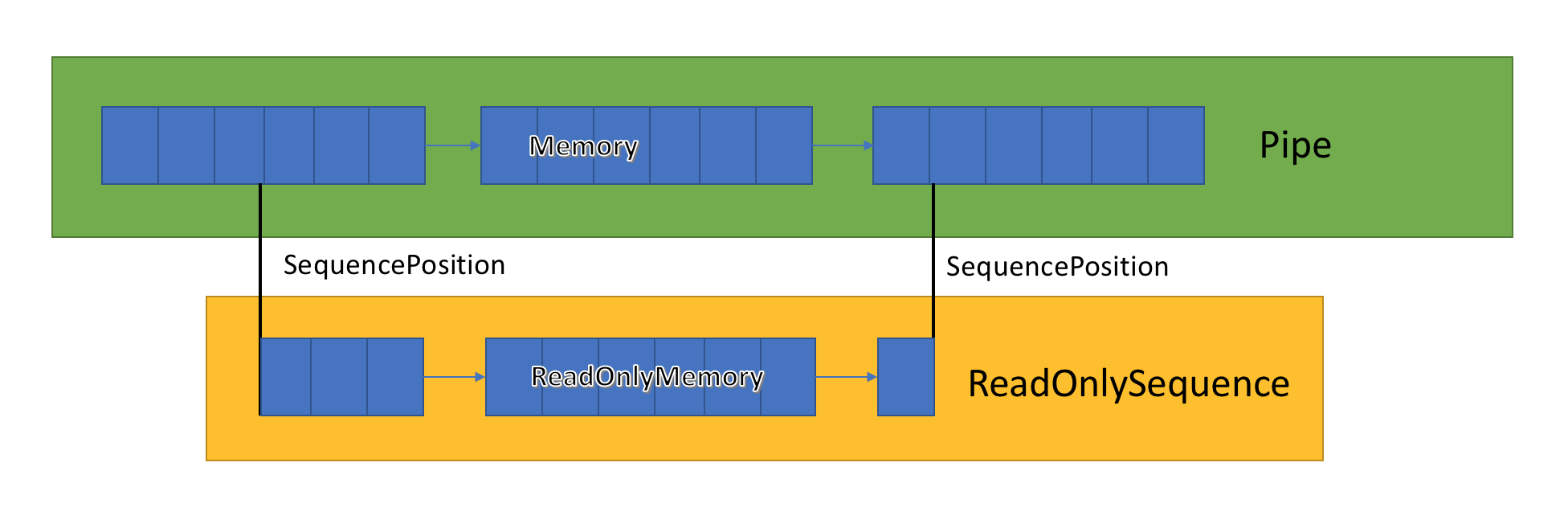
Inside the channel there are pointers that show where the reader and the recorder are located in the general set of selected data, and also update them as they are written and read the data. SequencePosition is a single point in the linked list of buffers and is used to efficiently separate ReadOnlySequence <T>.
Since ReadOnlySequence <T> supports one segment and more, the standard operation of high-performance logic is the separation of fast and slow paths based on the number of segments.
As an example, we present a function that converts an ASCII ReadOnlySequence to a string:
see sample6.cs on github
Ideally, reading and analysis work together: the reading stream consumes data from the network and puts it into buffers, while the analysis stream creates the appropriate data structures. Analysis usually takes longer than just copying data blocks from a network. As a result, the read stream can easily overload the analysis stream. Therefore, the reading stream will have to either slow down or consume more memory in order to save data for the analysis stream. To ensure optimal performance, a balance is needed between the pause frequency and the allocation of large amounts of memory.
To solve this problem, the pipeline has two flow control functions: PauseWriterThreshold and ResumeWriterThreshold. PauseWriterThreshold determines how much data needs to be buffered before pausing PipeWriter.FlushAsync. ResumeWriterThreshold determines how much memory the reader can consume before resuming the operation of the recorder.
PipeWriter.FlushAsync is “blocked” when the amount of data in the pipeline stream exceeds the limit set in PauseWriterThreshold and is “unlocked” when it falls below the limit set in ResumeWriterThreshold. To prevent the consumption limit being exceeded, only two values are used.
When using async / await, subsequent operations are usually called either in pool threads or in the current SynchronizationContext.
When implementing I / O, it is very important to carefully control where it is executed in order to use the processor cache more efficiently. This is critical for high performance applications such as web servers. System.IO.Pipelines uses PipeScheduler to determine where to place asynchronous callbacks. This allows you to very precisely control which threads to use for I / O.
A practical example is the Kestrel Libuv transport, in which I / O callbacks are executed through dedicated channels of the event loop.
We also added a number of new simple BCL types to System.IO.Pipelines:
The APIs are in the System.IO.Pipelines nuget package .
An example of a .NET Server 2.1 server application that uses pipelines to handle inline messages (from the example above) see here . It can be run using the dotnet run (or Visual Studio). In the example, data transfer from the socket on port 8087 is expected, then the received messages are written to the console. To connect to port 8087, you can use a client, such as netcat or putty. Send a text message and see how it works.
At the moment, the pipeline is working in Kestrel and SignalR, and we hope that it will find more widespread use in many network libraries and components of the .NET community in the future.
The library came as a result of the efforts of the .NET Core development team, which sought to make Kestrel one of the fastest web servers in the industry . It was originally conceived as part of the Kestrel implementation, but evolved into a reusable API, available in version 2.1 as the first class BCL API (System.IO.Pipelines).
What problems does she solve?
To properly analyze data from a stream or socket, you need to write a large amount of standard code. At the same time, there are many pitfalls that complicate both the code itself and its support.
What difficulties arise today?
Let's start with a simple task. We need to write a TCP server that receives line-delimited messages (\ n) from the client.
TCP Server with NetworkStream
REMOVAL: As in any task that requires high performance, each case should be considered based on the characteristics of your application. It is possible that spending resources on the use of various approaches, which will be discussed further, does not make sense if the scale of the network application is not very large.
Normal .NET code before using pipelines looks like this:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = newbyte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}see sample1.cs on GitHub
This code will probably work with local testing, but it has some errors:
- Perhaps after a single call to ReadAsync, the entire message will not be received (until the end of the line).
- It ignores the output of the stream.ReadAsync () method — the amount of data actually transferred to the buffer.
- The code does not handle receiving multiple lines in a single ReadAsync call.
These are the most common errors in reading streaming data. To avoid them, you need to make a number of changes:
- You need to buffer incoming data until a new string is found.
- It is necessary to analyze all the rows returned to the buffer.
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = newbyte[1024];
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered);
if (bytesRead == 0)
{
// EOFbreak;
}
// Keep track of the amount of buffered bytes
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed, bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offsetvar lineLength = linePosition - bytesConsumed;
// Process the line
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line we consumed (including \n)
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}see sample2.cs on GitHub
I repeat: this could work with local testing, but sometimes there are lines longer than 1 KB (1024 bytes). It is necessary to increase the size of the input buffer until a new line is found.
In addition, we collect buffers into an array when processing long strings. We can improve this process using ArrayPool, which will avoid re-allocation of buffers during the analysis of long rows coming from the client.
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffervar bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffervar newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOFbreak;
}
// Keep track of the amount of buffered bytes
bytesBuffered += bytesRead;
do
{
// Look for a EOL in the buffered data
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed, bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offsetvar lineLength = linePosition - bytesConsumed;
// Process the line
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line we consumed (including \n)
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}see sample3.cs on GitHub.
The code works, but now the buffer size has changed, resulting in a lot of copies. More memory is also used, since the logic does not reduce the buffer after processing strings. To avoid this, you can save a list of buffers, and not to change the buffer size each time when lines arrive longer than 1 KB.
In addition, we do not increase the buffer size of 1 KB, until it is completely empty. This means that we will send smaller and smaller buffers to ReadAsync, resulting in an increase in the number of calls to the operating system.
We will try to eliminate this and allocate a new buffer as soon as the size of the existing one is less than 512 bytes:
publicclassBufferSegment
{
publicbyte[] Buffer { get; set; }
publicint Count { get; set; }
publicint Remaining => Buffer.Length - Count;
}
async Task ProcessLinesAsync(NetworkStream stream)
{
constint minimumBufferSize = 512;
var segments = new List<BufferSegment>();
var bytesConsumed = 0;
var bytesConsumedBufferIndex = 0;
var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) };
segments.Add(segment);
while (true)
{
// Calculate the amount of bytes remaining in the bufferif (segment.Remaining < minimumBufferSize)
{
// Allocate a new segment
segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) };
segments.Add(segment);
}
var bytesRead = await stream.ReadAsync(segment.Buffer, segment.Count, segment.Remaining);
if (bytesRead == 0)
{
break;
}
// Keep track of the amount of buffered bytes
segment.Count += bytesRead;
while (true)
{
// Look for a EOL in the list of segmentsvar (segmentIndex, segmentOffset) = IndexOf(segments, (byte)'\n', bytesConsumedBufferIndex, bytesConsumed);
if (segmentIndex >= 0)
{
// Process the line
ProcessLine(segments, segmentIndex, segmentOffset);
bytesConsumedBufferIndex = segmentOffset;
bytesConsumed = segmentOffset + 1;
}
else
{
break;
}
}
// Drop fully consumed segments from the list so we don't look at them againfor (var i = bytesConsumedBufferIndex; i >= 0; --i)
{
var consumedSegment = segments[i];
// Return all segments unless this is the current segmentif (consumedSegment != segment)
{
ArrayPool<byte>.Shared.Return(consumedSegment.Buffer);
segments.RemoveAt(i);
}
}
}
}
(int segmentIndex, int segmentOffest) IndexOf(List<BufferSegment> segments, bytevalue, int startBufferIndex, int startSegmentOffset)
{
var first = true;
for (var i = startBufferIndex; i < segments.Count; ++i)
{
var segment = segments[i];
// Start from the correct offsetvar offset = first ? startSegmentOffset : 0;
var index = Array.IndexOf(segment.Buffer, value, offset, segment.Count - offset);
if (index >= 0)
{
// Return the buffer index and the index within that segment where EOL was foundreturn (i, index);
}
first = false;
}
return (-1, -1);
}see sample4.cs on GitHub
As a result, the code becomes much more complicated. During the search for a separator, we monitor the filled buffers. To do this, use the List, which displays the buffered data when searching for a new row delimiter. As a result, ProcessLine and IndexOf will take a List instead of byte [], offset and count. The parsing logic will start processing one or more segments of the buffer.
And now the server will process partial messages and use the combined memory to reduce the total memory consumption. However, a number of changes need to be made:
- From ArrayPoolbyte, we use only Byte [] - the standardly managed arrays. In other words, when executing the ReadAsync or WriteAsync function, the lifetime of the buffers is tied to the time when an asynchronous operation is performed (to interact with the operating system's own I / O API). Since pinned memory cannot move, this affects the performance of the garbage collector and can cause array fragmentation. You may need to change the pool implementation, depending on how long the asynchronous operation waits for execution.
- Throughput can be improved by breaking the link between the logic of reading and processing. We get the effect of batch processing, and now the parsing logic will be able to read large amounts of data, processing large blocks of buffers, rather than analyzing individual lines. As a result, the code becomes even more complicated:
- It is necessary to create two cycles, working independently of each other. The first will read data from the socket, and the second will analyze the buffers.
- We need a way to tell the parsing logic that the data is available.
- You also need to determine what happens if the loop reads data from the socket too quickly. We need a way to regulate the read cycle if the syntax analysis logic does not keep up with it. This is commonly referred to as "flow control" or "flow resistance."
- We need to make sure that the data is transferred safely. Now the set of buffers is used both by the read cycle and the syntax analysis cycle, they work independently of each other on different threads.
- The memory management logic is also involved in two different code fragments: borrowing data from the buffer pool, which reads data from the socket, and returning from the buffer pool, which is the logic of parsing.
- You need to be extremely careful with returning buffers after executing the parsing logic. Otherwise, there is a possibility that we will return the buffer to which the socket read logic is still being written.
The difficulty begins to roll off (and this is not all cases!). To create a high-performance network, you need to write very complex code.
The goal of System.IO.Pipelines is to simplify this procedure.
TCP Server and System.IO.Pipelines
Let's see how System.IO.Pipelines works:
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
return Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
constint minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// Tell the PipeReader that there's no more data coming
writer.Complete();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
SequencePosition? position = null;
do
{
// Look for a EOL in the buffer
position = buffer.PositionOf((byte)'\n');
if (position != null)
{
// Process the line
ProcessLine(buffer.Slice(0, position.Value));
// Skip the line + the \n character (basically position)
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
}
}
while (position != null);
// Tell the PipeReader how much of the buffer we have consumed
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data comingif (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete
reader.Complete();
}see sample5.cs on GitHub
In the pipeline version of our row reader there are two cycles:
- FillPipeAsync reads from the socket and writes to PipeWriter.
- ReadPipeAsync reads from PipeReader and analyzes incoming lines.
Unlike the first examples, there are no specially assigned buffers. This is one of the main features of System.IO.Pipelines. All buffer management tasks are passed to PipeReader / PipeWriter implementations.
The procedure is simplified: we use code only for business logic, instead of implementing complex buffer management.
The first loop first calls PipeWriter.GetMemory (int) to get a certain amount of memory from the main recorder. Then PipeWriter.Advance (int) is called, which tells PipeWriter how much data is actually written to the buffer. This is followed by a call to PipeWriter.FlushAsync () so that PipeReader can access the data.
The second loop consumes buffers that were recorded by PipeWriter, but initially came from a socket. When a request is returned to PipeReader.ReadAsync (), we get a ReadResult containing two important messages: data read in the form ReadOnlySequence, as well as the logical data type IsCompleted, which tells the reader whether the recorder has finished the job (EOF). When the end-of-line (EOL) separator is found and the string is analyzed, we divide the buffer into parts to skip the already processed fragment. After that, PipeReader.AdvanceTo is called, and it tells PipeReader how much data has been consumed.
At the end of each cycle, the work of both the reader and the recorder is completed. As a result, the main channel frees all allocated memory.
System.IO.Pipelines
Partial reading
In addition to memory management, System.IO.Pipelines performs another important function: it looks at the data in the channel, but does not consume it.
PipeReader has two main APIs: ReadAsync and AdvanceTo. ReadAsync receives data from the channel, AdvanceTo informs PipeReader that these buffers are no longer required by the reader, so you can get rid of them (for example, return to the main buffer pool).
Below is an example HTTP analyzer that reads data from the channel partial data buffers until it gets a suitable starting line.
ReadOnlySequenceT
The channel implementation stores a list of associated buffers that are transferred between PipeWriter and PipeReader. PipeReader.ReadAsync reveals ReadOnlySequence, which is a new BCL type and consists of one or more ReadOnlyMemory <T> segments. It is similar to Span or Memory, which gives us the opportunity to look at arrays and strings.
Inside the channel there are pointers that show where the reader and the recorder are located in the general set of selected data, and also update them as they are written and read the data. SequencePosition is a single point in the linked list of buffers and is used to efficiently separate ReadOnlySequence <T>.
Since ReadOnlySequence <T> supports one segment and more, the standard operation of high-performance logic is the separation of fast and slow paths based on the number of segments.
As an example, we present a function that converts an ASCII ReadOnlySequence to a string:
stringGetAsciiString(ReadOnlySequence<byte> buffer)
{
if (buffer.IsSingleSegment)
{
return Encoding.ASCII.GetString(buffer.First.Span);
}
returnstring.Create((int)buffer.Length, buffer, (span, sequence) =>
{
foreach (var segment in sequence)
{
Encoding.ASCII.GetChars(segment.Span, span);
span = span.Slice(segment.Length);
}
});
}see sample6.cs on github
Flow Resistance and Flow Control
Ideally, reading and analysis work together: the reading stream consumes data from the network and puts it into buffers, while the analysis stream creates the appropriate data structures. Analysis usually takes longer than just copying data blocks from a network. As a result, the read stream can easily overload the analysis stream. Therefore, the reading stream will have to either slow down or consume more memory in order to save data for the analysis stream. To ensure optimal performance, a balance is needed between the pause frequency and the allocation of large amounts of memory.
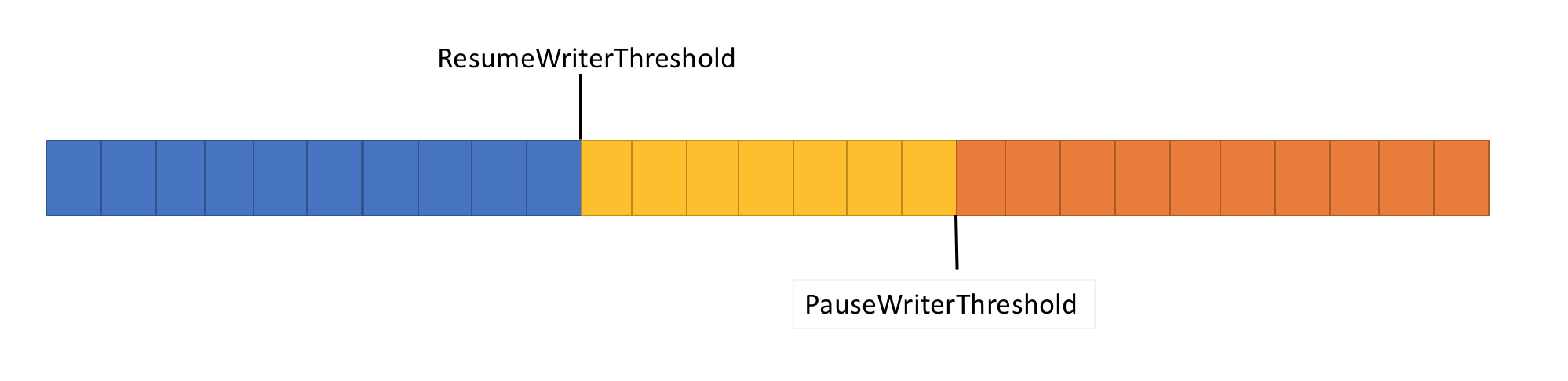
To solve this problem, the pipeline has two flow control functions: PauseWriterThreshold and ResumeWriterThreshold. PauseWriterThreshold determines how much data needs to be buffered before pausing PipeWriter.FlushAsync. ResumeWriterThreshold determines how much memory the reader can consume before resuming the operation of the recorder.
PipeWriter.FlushAsync is “blocked” when the amount of data in the pipeline stream exceeds the limit set in PauseWriterThreshold and is “unlocked” when it falls below the limit set in ResumeWriterThreshold. To prevent the consumption limit being exceeded, only two values are used.
I / O scheduling
When using async / await, subsequent operations are usually called either in pool threads or in the current SynchronizationContext.
When implementing I / O, it is very important to carefully control where it is executed in order to use the processor cache more efficiently. This is critical for high performance applications such as web servers. System.IO.Pipelines uses PipeScheduler to determine where to place asynchronous callbacks. This allows you to very precisely control which threads to use for I / O.
A practical example is the Kestrel Libuv transport, in which I / O callbacks are executed through dedicated channels of the event loop.
There are other benefits of the PipeReader pattern.
- Some basic systems support “wait without buffering”: the buffer does not need to be allocated until available data appears in the base system. So, in Linux with epoll, you can not provide a buffer for reading until the data is prepared. This avoids a situation where there are many threads waiting for data, and you need to immediately reserve a huge amount of memory.
- The default pipeline simplifies the recording of network code unit tests: the parsing logic is separate from the network code, and the unit tests run this logic only in buffers in memory, and do not consume it directly from the network. It also makes it easy to test complex patterns with partial data sent. ASP.NET Core uses it to test various aspects of the Kestrel http parser.
- Systems that allow custom code to use the main OS buffers (for example, the registered Windows I / O API) are initially suitable for using pipelines, since the PipeReader implementation always provides buffers.
Other related types
We also added a number of new simple BCL types to System.IO.Pipelines:
- MemoryPoolT , IMemoryOwnerT , MemoryManagerT . ArrayPoolT has been added to .NET Core 1.0 , and .NET Core 2.1 now has a more general abstract representation for the pool that works with any MemoryTs. We get an extensibility point that allows for more advanced distribution strategies, as well as control buffer management (for example, using predefined buffers instead of exclusively managed arrays).
- The IBufferWriterT is a receiver for recording synchronous buffered data (implemented by PipeWriter).
- IValueTaskSource - ValueTaskT has existed since the release of .NET Core 1.1, but in .NET Core 2.1 it has acquired extremely efficient tools that provide uninterrupted asynchronous operations without distribution. For more information, see here .
How to use conveyors?
The APIs are in the System.IO.Pipelines nuget package .
An example of a .NET Server 2.1 server application that uses pipelines to handle inline messages (from the example above) see here . It can be run using the dotnet run (or Visual Studio). In the example, data transfer from the socket on port 8087 is expected, then the received messages are written to the console. To connect to port 8087, you can use a client, such as netcat or putty. Send a text message and see how it works.
At the moment, the pipeline is working in Kestrel and SignalR, and we hope that it will find more widespread use in many network libraries and components of the .NET community in the future.