Organization of multitasking in the OS kernel
 By the will of fate, I happened to deal with the organization of multitasking, more precisely pseudo-multitasking, since tasks share time on one processor core. I’ve already seen articles on this topic on the Habré, and it seemed to me that the community was interested in this topic, so I will allow myself to make my modest contribution to the coverage of this issue.
By the will of fate, I happened to deal with the organization of multitasking, more precisely pseudo-multitasking, since tasks share time on one processor core. I’ve already seen articles on this topic on the Habré, and it seemed to me that the community was interested in this topic, so I will allow myself to make my modest contribution to the coverage of this issue.First, I will try to talk about the types of multitasking (cooperative and preemptive). Then I'll move on to planning principles for preemptive multitasking. The story is designed more for a novice reader who wants to understand how multitasking works at the kernel level of the OS. But since everything will be accompanied by examples that can be compiled, run, and which you can play with if you wish, then perhaps the article will be of interest to those who are already familiar with the theory, but who have never tried the planner “to taste”. Too lazy to read, you can immediately proceed to study the code, because the code of examples will be taken from our project .
Well, multi-threaded seals to attract attention.
Introduction
First we’ll define what the term “multitasking” means. Here is the definition from Russian Wikipedia:
Multitasking (English multitasking) - the property of the operating system or programming environment to provide the ability to parallel (or pseudo-parallel) processing of several processes.
English gives, in my opinion, a less clear, but more detailed definition:
In computing, multitasking is a method where multiple tasks, also known as processes, are performed during the same period of time. The tasks share common processing resources, such as a CPU and main memory. In the case of a computer with a single CPU, only one task is said to be running at any point in time, meaning that the CPU is actively executing instructions for that task. Multitasking solves the problem by scheduling which task may be the one running at any given time, and when another waiting task gets a turn. The act of reassigning a CPU from one task to another one is called a context switch.
It introduces the concept of resource sharing (resources sharing) and, in fact, planning (scheduling). It is about planning (primarily processor time) that will be discussed in this article. Both definitions are about process planning, but I will talk about thread-based planning.
 Thus, we need to introduce another concept, let's call it the flow of execution - this is a set of instructions with a certain sequence that the processor executes while the program is running.
Thus, we need to introduce another concept, let's call it the flow of execution - this is a set of instructions with a certain sequence that the processor executes while the program is running.Since we are talking about multitasking, then naturally there may be several of these very computational threads in the system. A thread whose instructions the processor is currently executing is called active. Since only one instruction can be executed on one processor core at a time, only one computational thread can be active. The process of selecting an active computing thread is called scheduling. In turn, the module that is responsible for this choice is usually called a scheduler.
There are many different planning methods. Most of them can be attributed to two main types:
- non-preemptive (cooperative) - the scheduler cannot take the time from the computing thread until he himself gives it away
- preemptive - the scheduler after the time slice selects the next active computing thread, the computing thread itself can also give the remainder of the time quantum intended for it
Let's start with a non-preemptive planning method, as it can be implemented very simply.
Non-preemptive planner
The non-preemptive scheduler under consideration is very simple, this material is given for beginners to make it easier to understand multitasking. Anyone who has an idea, even a theoretical one, can immediately go to the “Extrusion Scheduler” section.
The simplest non-crowding scheduler
Imagine that we have several tasks that are short enough in time, and we can call them one at a time. Let us formalize the task as an ordinary function with some set of parameters. The scheduler will operate with an array of structures for these functions. It will go through this array and call task functions with the given parameters. The function, having performed the necessary actions for the task, will return control to the main scheduler cycle.
#include<stdio.h>#define TASK_COUNT 2structtask {void (*func)(void *);
void *data;
};
staticstructtasktasks[TASK_COUNT];staticvoidscheduler(void){
int i;
for (i = 0; i < TASK_COUNT; i++) {
tasks[i].func(tasks[i].data);
}
}
staticvoidworker(void *data){
printf("%s\n", (char *) data);
}
static struct task *task_create(void (*func)(void *), void *data){
staticint i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
intmain(void){
task_create(&worker, "First");
task_create(&worker, "Second");
scheduler();
return0;
}
Output Results:
First
second
CPU busy graph:

Event-Based Non-Preemptive Scheduler
It is clear that the example described above is too primitive. Let's introduce another opportunity to activate a specific task. To do this, add a flag to the task description structure indicating whether the task is active or not. Of course, you still need a small API to control the activation.
#include<stdio.h>#define TASK_COUNT 2structtask {void (*func)(void *);
void *data;
int activated;
};
staticstructtasktasks[TASK_COUNT];structtask_data {char *str;
structtask *next_task;
};
static struct task *task_create(void (*func)(void *), void *data){
staticint i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
staticinttask_activate(struct task *task, void *data){
task->data = data;
task->activated = 1;
return0;
}
staticinttask_run(struct task *task, void *data){
task->activated = 0;
task->func(data);
return0;
}
staticvoidscheduler(void){
int i;
int fl = 1;
while (fl) {
fl = 0;
for (i = 0; i < TASK_COUNT; i++) {
if (tasks[i].activated) {
fl = 1;
task_run(&tasks[i], tasks[i].data);
}
}
}
}
staticvoidworker1(void *data){
printf("%s\n", (char *) data);
}
staticvoidworker2(void *data){
structtask_data *task_data;
task_data = data;
printf("%s\n", task_data->str);
task_activate(task_data->next_task, "First activated");
}
intmain(void){
structtask *t1, *t2;structtask_datatask_data;
t1 = task_create(&worker1, "First create");
t2 = task_create(&worker2, "Second create");
task_data.next_task = t1;
task_data.str = "Second activated";
task_activate(t2, &task_data);
scheduler();
return0;
}
Output Results:
Second activated
first activated
CPU busy graph

Message Queuing Non-Preemptive Scheduler
The problems of the previous method are obvious: if someone wants to activate a certain task twice, until the task is processed, then he will not succeed. Information about the second activation is simply lost. This problem can be partially solved by using Message Queuing. Instead of flags, add an array in which message queues for each thread are stored.
#include<stdio.h>#include<stdlib.h>#define TASK_COUNT 2structmessage {void *data;
structmessage *next;
};
structtask {void (*func)(void *);
structmessage *first;
};
structtask_data {char *str;
structtask *next_task;
};
staticstructtasktasks[TASK_COUNT];static struct task *task_create(void (*func)(void *), void *data){
staticint i = 0;
tasks[i].func = func;
tasks[i].first = NULL;
return &tasks[i++];
}
staticinttask_activate(struct task *task, void *data){
structmessage *msg;
msg = malloc(sizeof(struct message));
msg->data = data;
msg->next = task->first;
task->first = msg;
return0;
}
staticinttask_run(struct task *task, void *data){
structmessage *msg = data;
task->first = msg->next;
task->func(msg->data);
free(data);
return0;
}
staticvoidscheduler(void){
int i;
int fl = 1;
structmessage *msg;while (fl) {
fl = 0;
for (i = 0; i < TASK_COUNT; i++) {
while (tasks[i].first) {
fl = 1;
msg = tasks[i].first;
task_run(&tasks[i], msg);
}
}
}
}
staticvoidworker1(void *data){
printf("%s\n", (char *) data);
}
staticvoidworker2(void *data){
structtask_data *task_data;
task_data = data;
printf("%s\n", task_data->str);
task_activate(task_data->next_task, "Message 1 to first");
task_activate(task_data->next_task, "Message 2 to first");
}
intmain(void){
structtask *t1, *t2;structtask_datatask_data;
t1 = task_create(&worker1, "First create");
t2 = task_create(&worker2, "Second create");
task_data.next_task = t1;
task_data.str = "Second activated";
task_activate(t2, &task_data);
scheduler();
return0;
}
Results of work:
Second activated
Message 2 to first
Message 1 to first
CPU busy graph

Non-preemptive scheduler with call order preservation
Another problem with the previous examples is that the order of activating tasks is not preserved. In fact, each task has its own priority, which is not always good. To solve this problem, you can create one message queue and a dispatcher who will parse it.
#include<stdio.h>#include<stdlib.h>#define TASK_COUNT 2structtask {void (*func)(void *);
void *data;
structtask *next;
};
staticstructtask *first = NULL, *last = NULL;static struct task *task_create(void (*func)(void *), void *data){
structtask *task;
task = malloc(sizeof(struct task));
task->func = func;
task->data = data;
task->next = NULL;
if (last) {
last->next = task;
} else {
first = task;
}
last = task;
return task;
}
staticinttask_run(struct task *task, void *data){
task->func(data);
free(task);
return0;
}
static struct task *task_get_next(void){
structtask *task = first;if (!first) {
return task;
}
first = first->next;
if (first == NULL) {
last = NULL;
}
return task;
}
staticvoidscheduler(void){
structtask *task;while ((task = task_get_next())) {
task_run(task, task->data);
}
}
staticvoidworker2(void *data){
printf("%s\n", (char *) data);
}
staticvoidworker1(void *data){
printf("%s\n", (char *) data);
task_create(worker2, "Second create");
task_create(worker2, "Second create again");
}
intmain(void){
structtask *t1;
t1 = task_create(&worker1, "First create");
scheduler();
return0;
}
Results of work:
First create
Second create
Second create again
CPU busy graph

Before moving on to the preemptive scheduler, I want to add that the non-preemptive scheduler is used in real systems, since the costs of switching tasks are minimal. True, this approach requires a lot of attention on the part of the programmer; he must independently ensure that tasks do not go in cycles during execution.
Extrusion Planner
 Now let's imagine the following picture. We have two computational threads executing the same program, and there is a scheduler, which at any time before executing any instruction can interrupt the active thread and activate the other. To manage such tasks, there is no longer enough information only about the call function of the stream and its parameters, as is the case with non-preemptive schedulers. At a minimum, you still need to know the address of the current instruction being executed and the set of local variables for each task. That is, for each task, you need to store copies of the corresponding variables, and since local variables for the threads are located on its stack, space should be allocated for the stack of each thread, and somewhere a pointer to the current position of the stack should be stored.
Now let's imagine the following picture. We have two computational threads executing the same program, and there is a scheduler, which at any time before executing any instruction can interrupt the active thread and activate the other. To manage such tasks, there is no longer enough information only about the call function of the stream and its parameters, as is the case with non-preemptive schedulers. At a minimum, you still need to know the address of the current instruction being executed and the set of local variables for each task. That is, for each task, you need to store copies of the corresponding variables, and since local variables for the threads are located on its stack, space should be allocated for the stack of each thread, and somewhere a pointer to the current position of the stack should be stored.This data - instruction pointer and stack pointer - is stored in processor registers. In addition to them, other information contained in the registers is necessary for the correct operation: status flags, various general-purpose registers that contain temporary variables, and so on. All this is called the processor context.
Processor context
 A processor context is a data structure that stores the internal state of processor registers. The context should allow to bring the processor to the correct state to execute the computational stream. The process of replacing one computing thread with another is commonly called a context switch.
A processor context is a data structure that stores the internal state of processor registers. The context should allow to bring the processor to the correct state to execute the computational stream. The process of replacing one computing thread with another is commonly called a context switch. Description of the context structure for x86 architecture from our project:
structcontext {/* 0x00 */uint32_t eip; /**< instruction pointer *//* 0x04 */uint32_t ebx; /**< base register *//* 0x08 */uint32_t edi; /**< Destination index register *//* 0x0c */uint32_t esi; /**< Source index register *//* 0x10 */uint32_t ebp; /**< Stack pointer register *//* 0x14 */uint32_t esp; /**< Stack Base pointer register *//* 0x18 */uint32_t eflags; /**< EFLAGS register hold the state of the processor */
};
The concepts of processor context and context switching are fundamental in understanding the principle of preemptive planning.
Context switch
Context Switching - replacing the context of one thread with another. The scheduler saves the current context and loads another into the processor registers.
I said above that the scheduler can interrupt the active thread at any time, which simplifies the model somewhat. In fact, it is not the scheduler that interrupts the flow, but the current program is interrupted by the processor as a result of a reaction to an external event - a hardware interrupt - and transfers control to the scheduler. For example, an external event is a system timer, which counts the quantum of time allocated for the active thread. If we assume that there is exactly one interrupt source in the system, the system timer, then the processor time map will look like this:

Context switching procedure for x86 architecture:
.global context_switch
context_switch:
movl 0x04(%esp), %ecx /* Point ecx to previous registers */
movl (%esp), %eax /* Get return address */
movl %eax, CTX_X86_EIP(%ecx) /* Save it as eip */
movl %ebx, CTX_X86_EBX(%ecx) /* Save ebx */
movl %edi, CTX_X86_EDI(%ecx) /* Save edi */
movl %esi, CTX_X86_ESI(%ecx) /* Save esi */
movl %ebp, CTX_X86_EBP(%ecx) /* Save ebp */
add $4, %esp /* Move esp in state corresponding to eip */
movl %esp, CTX_X86_ESP(%ecx) /* Save esp */
pushf /* Push flags */pop CTX_X86_EFLAGS(%ecx)/* ...and save them */
movl 0x04(%esp), %ecx /* Point ecx to next registers */
movl CTX_X86_EBX(%ecx), %ebx /* Restore ebx */
movl CTX_X86_EDI(%ecx), %edi /* Restore edi */
movl CTX_X86_ESP(%ecx), %esi /* Restore esp */
movl CTX_X86_EBP(%ecx), %ebp /* Restore ebp */
movl CTX_X86_ESP(%ecx), %esp /* Restore esp */
push CTX_X86_EFLAGS(%ecx)/* Push saved flags */
popf /* Restore flags */
movl CTX_X86_EIP(%ecx), %eax /* Get eip */
push %eax /* Restore it as return address */
ret
Stream state machine
We discussed the important difference between the flow structure in the case of the preemptive scheduler and the case of the non-preemptive scheduler - the presence of context. Let's see what happens to a stream from its creation to completion:

- States init is responsible for the fact that the thread has been created, but has not yet been added to the queue to the scheduler, and exit indicates that the thread has completed its execution, but has not yet freed the memory allocated to it.
- The run state should also be obvious - a thread in this state is executed on the processor.
- The ready state means that the thread is not running, but waits for the scheduler to give it time, that is, it is in the scheduler's queue.
But this does not exhaust the possible states of the flow. A thread can give a quantum of time in anticipation of an event, for example, just fall asleep for a while and after this time continue execution from the place where it fell asleep (for example, a normal call to sleep).
Thus, the thread can be in different states (ready for execution, terminating, in standby mode, and so on), while in the case of a non-crowding scheduler it was enough to have a flag on the activity of a particular task.
This is how a generalized state machine can be imagined:
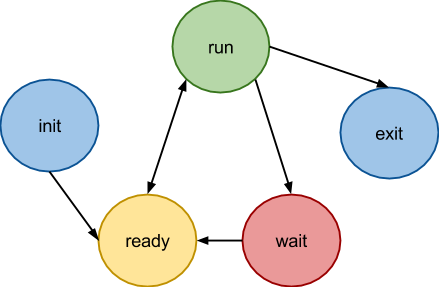
In this scheme, a new wait state has appeared, which tells the scheduler that the thread has fallen asleep, and until it wakes up, it does not need to allocate processor time.
Now let’s take a closer look at the flow control API and deepen our knowledge of flow conditions.
State implementation
If you look at the state diagram more closely, you can see that the init and wait states are almost the same: both can only go into the ready state, that is, tell the scheduler that they are ready to get their time slice. Thus, the init state is redundant.
Now let's look at the exit state. This state has its own subtleties. It is set to the scheduler in the final function, which will be discussed below. The completion of the flow can take place in two scenarios: the first - the thread completes its main function and frees the resources occupied by it, the second - the other thread takes responsibility for freeing resources. In the second case, the thread sees that another thread will free its resources, informs it that it has completed, and transfers control to the scheduler. In the first case, the thread frees up resources and also transfers control to the scheduler. After the scheduler has gained control, the thread should never resume work. That is, in both cases, the exit state has the same value - the stream in this state does not want to receive a new time quantum, it does not need to be placed in the scheduler queue.
Thus, we have three states. We will store these states in three separate fields. It would be possible to store everything in one integer field, but to simplify the checks and due to the peculiarity of the multiprocessor case, which we will not discuss here, such a decision was made. So, the state of the stream:
- active - launched and executed on the processor
- waiting - expects some kind of event. In addition, it replaces the states of init and exit
- ready - is under the control of the scheduler, i.e. lies in the queue of ready-made threads in the scheduler or running on the processor. This state is somewhat wider than the ready that we see in the picture. In most cases, active and ready, while ready and waiting are theoretically orthogonal, but there are specific transition states where these rules are violated. I will talk about these cases below.
Creature
Creating a thread includes the necessary initialization (thread_init function) and the possible start of the thread. During initialization, memory is allocated for the stack, the processor context is set, the necessary flags and other initial values are set. Since when creating, we work with the queue of ready-made flows, which the scheduler uses at any time, we must block the scheduler from working with the flow structure until the entire structure is fully initialized. After initialization, the thread is in the waiting state, which, as we recall, is also responsible for the initial state. After that, depending on the parameters passed, we either start the stream or not. The thread start function is a run / wake function in the scheduler, it is described in detail below. Now let's just say
So, the thread_create and thread_init function code:
struct thread *thread_create(unsignedint flags, void *(*run)(void *), void *arg){
int ret;
structthread *t;//…/* below we are going work with thread instances and therefore we need to
* lock the scheduler (disable scheduling) to prevent the structure being
* corrupted
*/
sched_lock();
{
/* allocate memory */if (!(t = thread_alloc())) {
t = err_ptr(ENOMEM);
goto out;
}
/* initialize internal thread structure */
thread_init(t, flags, run, arg);
//…
}
out:
sched_unlock();
return t;
}
voidthread_init(struct thread *t, unsignedint flags,
void *(*run)(void *), void *arg){
sched_priority_t priority;
assert(t);
assert(run);
assert(thread_stack_get(t));
assert(thread_stack_get_size(t));
t->id = id_counter++; /* setup thread ID */
dlist_init(&t->thread_link); /* default unlink value */
t->critical_count = __CRITICAL_COUNT(CRITICAL_SCHED_LOCK);
t->siglock = 0;
t->lock = SPIN_UNLOCKED;
t->ready = false;
t->active = false;
t->waiting = true;
t->state = TS_INIT;
/* set executive function and arguments pointer */
t->run = run;
t->run_arg = arg;
t->joining = NULL;
//.../* cpu context init */
context_init(&t->context, true); /* setup default value of CPU registers */
context_set_entry(&t->context, thread_trampoline);/*set entry (IP register*//* setup stack pointer to the top of allocated memory
* The structure of kernel thread stack follow:
* +++++++++++++++ top
* |
* v
* the thread structure
* xxxxxxx
* the end
* +++++++++++++++ bottom (t->stack - allocated memory for the stack)
*/
context_set_stack(&t->context,
thread_stack_get(t) + thread_stack_get_size(t));
sigstate_init(&t->sigstate);
/* Initializes scheduler strategy data of the thread */
runq_item_init(&t->sched_attr.runq_link);
sched_affinity_init(t);
sched_timing_init(t);
}
Standby mode
A thread can give its time to another thread for some reason, for example, by calling the sleep function. That is, the current thread goes from standby to standby. If in the case of the non-preemptive scheduler we just set the activity flag, then here we will save our stream in another queue. The waiting thread is not queued by the scheduler. In order not to lose the stream, it is usually stored in a special queue. For example, when trying to capture a busy mutex stream, before falling asleep, it places itself in a queue of waiting mutex threads. And when an event occurs that expects a thread, for example, the release of a mutex, it wakes him up and we can return the thread back to the ready queue. We will tell you more about waiting and pitfalls below, after we deal with the code of the scheduler itself.
Stream completion
Here the thread ends up in a wait state. If the thread has performed the processing function and terminated naturally, resources must be freed. I already described this process in detail when I talked about the redundancy of the exit state. Now let's look at the implementation of this function.
void __attribute__((noreturn)) thread_exit(void *ret) {
structthread *current = thread_self();structtask *task = task_self();structthread *joining;/* We can not free the main thread */if (task->main_thread == current) {
/* We are last thread. */
task_exit(ret);
/* NOTREACHED */
}
sched_lock();
current->waiting = true;
current->state |= TS_EXITED;
/* Wake up a joining thread (if any).
* Note that joining and run_ret are both in a union. */
joining = current->joining;
if (joining) {
current->run_ret = ret;
sched_wakeup(joining);
}
if (current->state & TS_DETACHED)
/* No one references this thread anymore. Time to delete it. */
thread_delete(current);
schedule();
/* NOTREACHED */
sched_unlock(); /* just to be honest */
panic("Returning from thread_exit()");
}
Springboard for calling a processing function
We have said more than once that when a thread completes execution, it must free resources. I don’t feel like calling the thread_exit function on my own - very rarely you need to terminate the thread in an exceptional order, and not naturally, after executing your function. In addition, we need to prepare the initial context, which is also to be done every time - unnecessarily. Therefore, the thread starts not with the function that we specified at creation, but with the thread_trampoline wrapper function. It serves to prepare the initial context and terminate the flow correctly.
staticvoid __attribute__((noreturn)) thread_trampoline(void) {
structthread *current = thread_self();void *res;
assert(!critical_allows(CRITICAL_SCHED_LOCK), "0x%x", (uint32_t)__critical_count);
sched_ack_switched();
assert(!critical_inside(CRITICAL_SCHED_LOCK));
/* execute user function handler */
res = current->run(current->run_arg);
thread_exit(res);
/* NOTREACHED */
}
Summary: stream structure description
 So, to describe the task in the case of the crowding-out scheduler, we need a rather complicated structure. It contains:
So, to describe the task in the case of the crowding-out scheduler, we need a rather complicated structure. It contains:- processor register information (context).
- information about the status of the task, whether it is ready for execution or, for example, is waiting for the release of any resource.
- identifier. In the case of an array, this is an index in the array, but if threads can be added and deleted, it is better to use a queue, where identifiers are useful.
- the start function and its arguments, perhaps even the return result.
- the address of the piece of memory that is allocated for the stack, because when you exit the stream, you need to free it.
Accordingly, the description of the structure in our project is as follows:
structthread {unsignedint critical_count;
unsignedint siglock;
spinlock_t lock; /**< Protects wait state and others. */unsignedint active; /**< Running on a CPU. TODO SMP-only. */unsignedint ready; /**< Managed by the scheduler. */unsignedint waiting; /**< Waiting for an event. */unsignedint state; /**< Thread-specific state. */structcontextcontext;/**< Architecture-dependent CPU state. */void *(*run)(void *); /**< Start routine. */void *run_arg; /**< Argument to pass to start routine. */union {
void *run_ret; /**< Return value of the routine. */void *joining; /**< A joining thread (if any). */
} /* unnamed */;
thread_stack_tstack; /**< Handler for work with thread stack */__thread_id_t id; /**< Unique identifier. */structtask *task;/**< Task belong to. */structdlist_headthread_link;/**< list's link holding task threads. */structsigstatesigstate;/**< Pending signal(s). */structsched_attrsched_attr;/**< Scheduler-private data. */thread_local_t local;
thread_cancel_t cleanups;
};
There are fields in the structure that are not described in the article (sigstate, local, cleanups) they are needed to support full POSIX threads (pthread) and are not important in the framework of this article.
Planner and planning strategy
Recall that now we have a stream structure, including context, we can switch this context. In addition, we have a system timer that measures time slices. In other words, we have an environment ready for the planner.
The task of the scheduler is to distribute processor time between threads. The scheduler has a queue of ready-made threads, which it operates to determine the next active thread. The rules by which the scheduler chooses the next thread for execution will be called the planning strategy. The main function of the planning strategy is to work with the queue of ready-made flows: add, delete, and retrieve the next ready-made flow. The behavior of the scheduler will depend on how these functions are implemented. Since we were able to define a separate concept - a planning strategy, we take it out into a separate entity. We described the interface as follows:
externvoidrunq_init(runq_t *queue);
externvoidrunq_insert(runq_t *queue, struct thread *thread);
externvoidrunq_remove(runq_t *queue, struct thread *thread);
extern struct thread *runq_extract(runq_t *queue);
externvoidrunq_item_init(runq_item_t *runq_link);
Consider the implementation of the planning strategy in more detail.
Planning Strategy Example
As an example, I will analyze the most primitive planning strategy in order to focus not on the intricacies of the strategy, but on the features of the crowding-out scheduler. Streams in this strategy will be processed in order of priority, without regard to priority: a new stream and its just spent quantum are placed at the end; the thread that receives the processor resources will come from the beginning.
The queue will be a regular doubly linked list. When we add an element, we insert it at the end, and when we get it out, we take it and remove it from the beginning.
voidrunq_item_init(runq_item_t *runq_link){
dlist_head_init(runq_link);
}
voidrunq_init(runq_t *queue){
dlist_init(queue);
}
voidrunq_insert(runq_t *queue, struct thread *thread){
dlist_add_prev(&thread->sched_attr.runq_link, queue);
}
voidrunq_remove(runq_t *queue, struct thread *thread){
dlist_del(&thread->sched_attr.runq_link);
}
struct thread *runq_extract(runq_t *queue){
structthread *thread;
thread = dlist_entry(queue->next, struct thread, sched_attr.runq_link);
runq_remove(queue, thread);
return thread;
}
Scheduler
Now we will pass to the most interesting - the description of the scheduler.
Launch scheduler
The first stage of the scheduler's work is its initialization. Here we need to ensure the correct environment for the scheduler. You need to prepare a queue of ready-made threads, add an idle thread to this queue, and start a timer, which will be used to count time slices for thread execution.
Scheduler Launch Code:
intsched_init(struct thread *idle, struct thread *current){
runq_init(&rq.queue);
rq.lock = SPIN_UNLOCKED;
sched_wakeup(idle);
sched_ticker_init();
return0;
}
Awakening and starting a thread
As we remember from the description of the state machine, waking up and starting a thread for the scheduler is one and the same process. The call to this function is at the start of the scheduler, there we start the idle thread. What essentially happens on waking? Firstly, the mark that we are waiting is removed, that is, the thread is no longer in the waiting state. Then two options are possible: we have already fallen asleep or not yet. Why this happens, I will describe in the next section, “Waiting”. If you do not have time, then the stream is still in the ready state, and in this case the awakening is completed. Otherwise, we put the thread in the scheduler queue, uncheck the waiting state, set ready. In addition, rescheduling is called if the priority of the awakened stream is greater than the current one. Pay attention to various locks: the whole action occurs when interrupts are disabled.
/** Locks: IPL, thread. */staticint __sched_wakeup_ready(struct thread *t) {
int ready;
spin_protected_if (&rq.lock, (ready = t->ready))
t->waiting = false;
return ready;
}
/** Locks: IPL, thread. */staticvoid __sched_wakeup_waiting(struct thread *t) {
assert(t && t->waiting);
spin_lock(&rq.lock);
__sched_enqueue_set_ready(t);
__sched_wokenup_clear_waiting(t);
spin_unlock(&rq.lock);
}
staticinlinevoid __sched_wakeup_smp_inactive(struct thread *t) {
__sched_wakeup_waiting(t);
}
/** Called with IRQs off and thread lock held. */int __sched_wakeup(struct thread *t) {
int was_waiting = (t->waiting && t->waiting != TW_SMP_WAKING);
if (was_waiting)
if (!__sched_wakeup_ready(t))
__sched_wakeup_smp_inactive(t);
return was_waiting;
}
intsched_wakeup(struct thread *t){
assert(t);
return SPIN_IPL_PROTECTED_DO(&t->lock, __sched_wakeup(t));
}
Expectation
Going into standby mode and correctly exiting it (when the expected event finally happens) is probably the most difficult and subtle thing in preemptive planning. Let's look at the situation in more detail.
First of all, we must explain to the scheduler that we want to wait for any event, and the event occurs naturally asynchronous, and we need to receive it synchronously. Therefore, we must indicate how the planner determines that the event has occurred. Moreover, we do not know when it can happen, for example, we managed to tell the planner that we are waiting for an event, checked that the conditions for its occurrence have not yet been fulfilled, and at this moment a hardware interrupt occurs, which generates our event. But since we have already completed the verification, this information will be lost. In our project, we solved this problem as follows.
Wait macro code
#define SCHED_WAIT_TIMEOUT(cond_expr, timeout) \
((cond_expr) ? 0 : ({ \
int __wait_ret = 0; \
clock_t __wait_timeout = timeout == SCHED_TIMEOUT_INFINITE ? \
SCHED_TIMEOUT_INFINITE : ms2jiffies(timeout); \
\
threadsig_lock(); \
do { \
sched_wait_prepare(); \
\
if (cond_expr) \
break; \
\
__wait_ret = sched_wait_timeout(__wait_timeout, \
&__wait_timeout); \
} while (!__wait_ret); \
\
sched_wait_cleanup(); \
\
threadsig_unlock(); \
__wait_ret; \
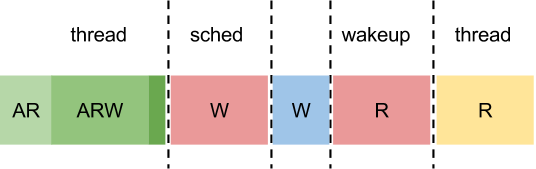
}))The flow with us can be immediately in a superposition of states. That is, when the stream falls asleep, it is still active and just sets the additional waiting flag. During waking up, this flag is again simply removed, and only if the thread has already reached the scheduler and leaves the queue of ready-made threads, it is added there again. If we consider the situation described earlier in the picture, we get the following picture.

A - active
R - ready
W - wait
In the picture, the letters indicate the presence of states. Light green is the state of the stream before wait_prepare, green is after wait_prepare, and dark green is the call to the rescheduling stream.
If the event does not have time to happen before rescheduling, then everything is simple - the thread will fall asleep and will wait for awakening:
Replanning
The main task of the planner is planning, I apologize for the tautology. And we finally came to the point where you can make out how this process is implemented in our project.
Firstly, rescheduling should be performed with the scheduler locked. Secondly, we want to give the opportunity to allow the displacement of the flow or not. Therefore, we took the logic of work into a separate function, surrounded its call with locks and called it indicating that in this place we do not allow crowding out.
Next are the actions with the queue of ready-made threads. If the thread that is active at the time of rescheduling is not going to fall asleep, that is, if it does not have a waiting state, we simply add it to the scheduler's thread queue. Then we get the highest priority thread from the queue. The rules for finding this stream are implemented using a planning strategy.
Then, if the current active thread matches the one we got from the queue, we do not need to reschedule and we can just exit and continue the thread. If rescheduling is required, the sched_switch function is called, in which the actions necessary for the scheduler are performed and the main thing is called context_switch, which we examined above.
If the thread is about to fall asleep, it is in the waiting state, then it does not fall into the scheduler queue, and the ready label is removed from it.
At the end, signal processing occurs, but as I noted above, this is beyond the scope of this article.
staticvoidsched_switch(struct thread *prev, struct thread *next){
sched_prepare_switch(prev, next);
trace_point(__func__);
/* Preserve initial semantics of prev/next. */
cpudata_var(saved_prev) = prev;
thread_set_current(next);
context_switch(&prev->context, &next->context); /* implies cc barrier */
prev = cpudata_var(saved_prev);
sched_finish_switch(prev);
}
staticvoid __schedule(int preempt) {
structthread *prev, *next;ipl_t ipl;
prev = thread_self();
assert(!sched_in_interrupt());
ipl = spin_lock_ipl(&rq.lock);
if (!preempt && prev->waiting)
prev->ready = false;
else
__sched_enqueue(prev);
next = runq_extract(&rq.queue);
spin_unlock(&rq.lock);
if (prev != next)
sched_switch(prev, next);
ipl_restore(ipl);
assert(thread_self() == prev);
if (!prev->siglock) {
thread_signal_handle();
}
}
voidschedule(void){
sched_lock();
__schedule(0);
sched_unlock();
}
Testing multithreading
As an example, I used the following code:
#include<stdint.h>#include<errno.h>#include<stdio.h>#include<util/array.h>#include<kernel/thread.h>#include<framework/example/self.h>/**
* This macro is used to register this example at the system.
*/
EMBOX_EXAMPLE(run);
/* configs */#define CONF_THREADS_QUANTITY 0x8 /* number of executing threads */#define CONF_HANDLER_REPEAT_NUMBER 300 /* number of circle loop repeats*//** The thread handler function. It's used for each started thread */staticvoid *thread_handler(void *args){
int i;
/* print a thread structure address and a thread's ID */for(i = 0; i < CONF_HANDLER_REPEAT_NUMBER; i ++) {
printf("%d", *(int *)args);
}
return thread_self();
}
/**
* Example's executing routine
* It has been declared by the macro EMBOX_EXAMPLE
*/staticintrun(int argc, char **argv){
structthread *thr[CONF_THREADS_QUANTITY];int data[CONF_THREADS_QUANTITY];
void *ret;
int i;
/* starting all threads */for(i = 0; i < ARRAY_SIZE(thr); i ++) {
data[i] = i;
thr[i] = thread_create(0, thread_handler, &data[i]);
}
/* waiting until all threads finish and print return value*/for(i = 0; i < ARRAY_SIZE(thr); i ++) {
thread_join(thr[i], &ret);
}
printf("\n");
return ENOERR;
}
Actually, this is almost a normal application. The EMBOX_EXAMPLE (run) macro sets the entry point to the specific type of our modules. The thread_join function waits for the thread to finish before I examine it too. And so much has already happened for one article.
The result of running this example on qemu as part of our project is as follows.

As you can see from the results, the first created threads are executed one after another, the scheduler gives them time in turn. At the end of a discrepancy. I think this is a consequence of the fact that the scheduler has rather rough accuracy (not comparable to displaying one character on the screen). Therefore, in the first passes, the threads manage to perform a different number of cycles.
In general, who wants to play, you can download the project and try all of the above in practice.
If the topic is interesting, I will try to continue the story about planning, there are still quite a lot of topics left open.