Why are TPUs so well suited for depth learning?
- Transfer

Third Generation
Tensor Processor Google Tensor Processor is a special-purpose integrated circuit ( ASIC ) developed by Google from scratch to perform machine learning tasks. It works in several major Google products, including Translate, Photos, Search Assistant and Gmail. Cloud TPU provides the benefits of scalability and ease of use for all developers and data scientists to launch advanced Google cloud machine learning models. At the Google Next '18 conference, we announced that Cloud TPU v2 is now available to all users, including free trial accounts , and Cloud TPU v3 is available for alpha testing.

But many people ask - what is the difference between CPU, GPU and TPU? We made a demo site , where the presentation and animation, which answers this question. In this post I would like to dwell in more detail on certain features of the content of this site.
How neural networks work
Before we start comparing CPU, GPU and TPU, let's see what kind of computation is required for machine learning — specifically, for neural networks.
Imagine, for example, that we use a single-layer neural network to recognize handwritten numbers, as shown in the following diagram:
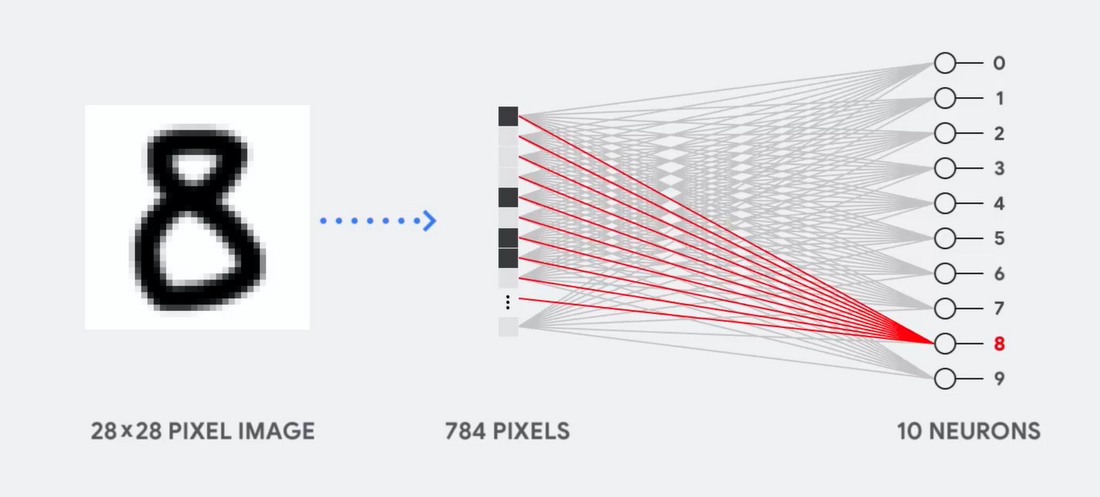
If the picture is a grid of 28x28 pixels in the gray scale, it can be converted to a vector of 784 values (dimensions). The neuron recognizing the digit 8 takes these values and multiplies them with the parameter values (red lines in the diagram).
The parameter works as a filter, extracting the features of the data, talking about the similarity of the image and form 8:

This is the simplest explanation for data classification by neural networks. Multiplication of data with the corresponding parameters (coloring of points) and their addition (sum of points on the right). The highest result indicates the best match between the entered data and the corresponding parameter, which is likely to be the correct answer.
Simply put, neural networks are required to make a huge number of multiplications and additions of data and parameters. Often we organize them in the form of matrix multiplication , which you might encounter at school on algebra. Therefore, the problem is to perform a large number of matrix multiplications as quickly as possible, spending as little energy as possible.
How does the CPU work
How does the CPU approach this task? CPU is a general-purpose processor based on von Neumann architecture . This means that the CPU works with software and memory something like this:
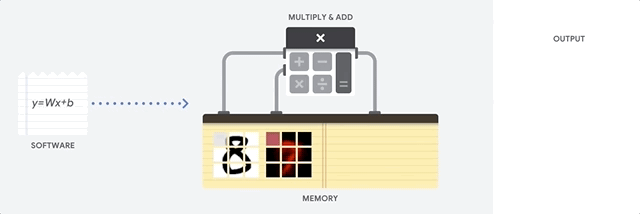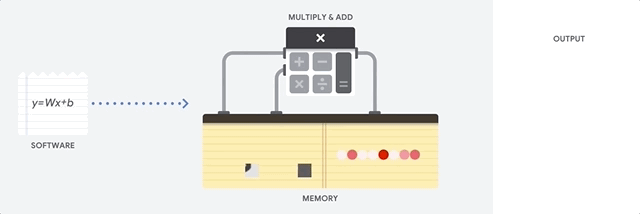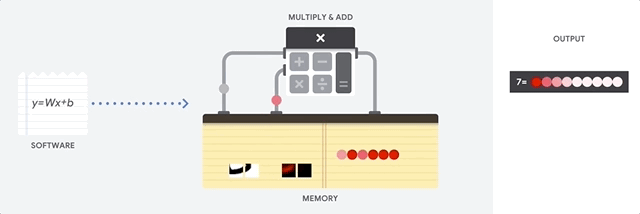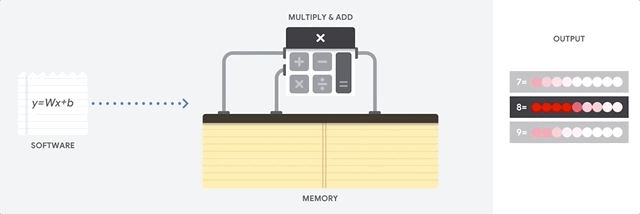
The main advantage of the CPU is flexibility. Thanks to the von Neumann architecture, you can download completely different software for millions of different purposes. The CPU can be used for word processing, rocket engine management, banking transactions, image classification using a neural network.
But since the CPU is so flexible, the hardware does not always know in advance what the next operation will be until it reads the next instruction from the software. The CPU needs to store the results of each calculation in a memory located inside the CPU (the so-called registers, or L1 cache). Access to this memory becomes a minus of the CPU architecture, known as the bottleneck of the von Neumann architecture. And although a huge amount of computation for neural networks makes predictable future steps, each CPU arithmetic logic unit (ALU, a component that stores and manages multipliers and adders) performs operations sequentially, each time accessing memory, which limits the overall throughput and consumes a significant amount of energy. .
How does the GPU
To increase throughput compared to the CPU, the GPU uses a simple strategy: why not embed thousands of ALUs in the processor? A modern GPU contains about 2500-5000 ALUs on a processor, which makes it possible to perform thousands of multiplications and additions simultaneously.

Such architecture works well with applications requiring massive parallelization, such as, for example, multiplication of matrices in a neural network. With a typical deep-field training (GO) training load, the throughput in this case is increased by an order of magnitude compared to the CPU. Therefore, today the GPU is the most popular processor architecture for GO.
But the GPU still remains a general-purpose processor that must support a million different applications and software. And this brings us back to the fundamental problem of the bottleneck of von Neumann architecture. For each calculation in thousands of ALUs, GPUs, you need to refer to registers or shared memory to read and store intermediate results of calculations. Since the GPU performs more parallel computing on thousands of its ALUs, it also spends proportionately more energy on memory access and occupies a larger area.
How does TPU work
When we developed TPU at Google, we built an architecture designed for a specific task. Instead of developing a general-purpose processor, we developed a matrix processor specialized for working with neural networks. TPU will not be able to work with a word processor, control rocket engines or perform banking transactions, but it can process a huge number of multiplications and additions for neural networks at an incredible speed, while consuming much less energy and accommodating in a smaller physical volume.
The main thing that allows him to do this is a radical elimination of the bottleneck of von Neumann architecture. Since the main task of TPU is the processing of matrices, the developers of the scheme were familiar with all the necessary computation steps. Therefore, they were able to place thousands of multipliers and adders, and physically combine them, forming a large physical matrix. This is called a pipeline array architecture . In the case of Cloud TPU v2, two pipeline arrays of 128 x 128 are used, which in total gives 32,768 ALU for 16-bit floating point values on a single processor.
Let's see how a pipeline array performs calculations for a neural network. First, the TPU loads the parameters from the memory into the matrix of multipliers and adders.

The TPU then loads the data from the memory. By performing each multiplication, the result is transmitted to the following multipliers, while simultaneously performing additions. Therefore, the output will be the sum of all multiplications of data and parameters. During the entire process of volume calculations and data transfer, memory access is completely unnecessary.
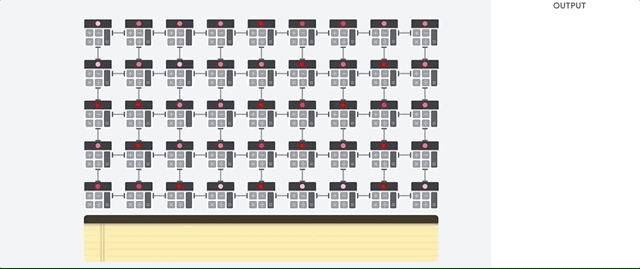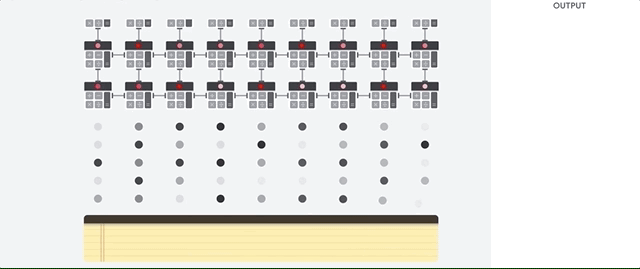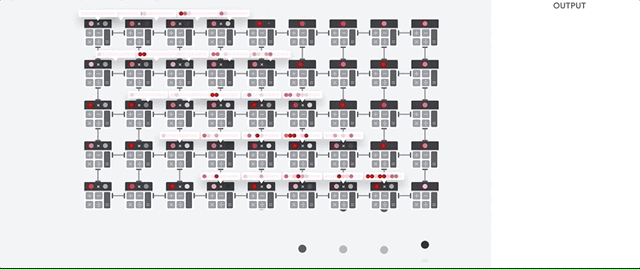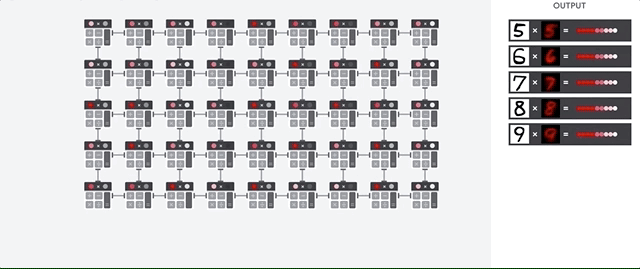
Therefore, TPU shows a large bandwidth when calculating for neural networks, consuming much less energy and taking up less space.
Advantage: 5 times reduced cost
What are the benefits of TPU architecture? Cost Here is the cost of Cloud TPU v2 work for August 2018, at the time of writing the article:
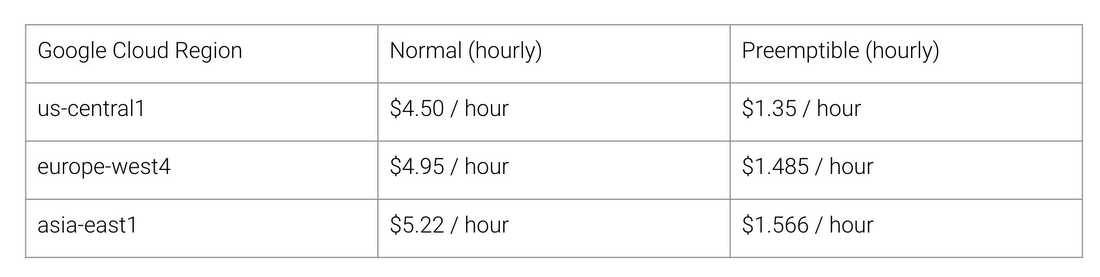
Regular and TPU cost of work for different regions of Google Cloud
Stanford University is distributing a set of DAWNBench tests that measure the speed of deep learning systems. There you can look at various combinations of tasks, models and computing platforms, as well as the corresponding test results.
At the time of the end of the competition in April 2018, the minimum cost of training on processors with non-TPU architecture was $ 72.40 (for ResNet-50 training with 93% accuracy on ImageNet on spot instances). With the help of Cloud TPU v2, such training can be held for $ 12.87. This is less than 1/5 of the cost. Such is the power of architecture designed specifically for neural networks.