Physical design of storage structures in Teradata DBMS
- Tutorial
What is the physical design of storage structures
 The main goal pursued during the development of the physical data model is the creation of such objects for a specific platform / DBMS that will allow to achieve maximum performance of queries / applications that create the main load, while reducing additional costs, such as the need to maintain additional indexes, and materialize derivatives data, etc., to a minimum.
The main goal pursued during the development of the physical data model is the creation of such objects for a specific platform / DBMS that will allow to achieve maximum performance of queries / applications that create the main load, while reducing additional costs, such as the need to maintain additional indexes, and materialize derivatives data, etc., to a minimum. All relational DBMSs are built on the same principles, but each platform has unique features in the form of various types of objects and features of their implementation. For this reason, the process of physical modeling is platform-dependent, in contrast to logical modeling, the main purpose of which is to reliably describe data and business processes.
Data storage in Teradata DBMS
Speaking about the physical design of databases on the Teradata platform, among other things, it is necessary to mention that this is an MPP (Massive Parallel Processing) platform in which all data is distributed among the system components (AMPs) and processed by them when performing user queries in parallel (see our first article ). Such an architecture, as well as uniform distribution of data, make their processing effective even in the absence of additional elements for ensuring productivity. This feature allows Teradata to perfectly handle Ad-Hoc requests not provided by the developers of the physical model.
But for a mixed load, when both tactical (OLTP-like) and strategic (OLAP, DSS, Data Mining) requests are simultaneously executed in the system, this is clearly not enough. This is especially true for tactical requests, which have rather high requirements for response time and bandwidth. The main physical design technique for improving the performance of tactical queries is the creation of indexes - data access paths that can be used by queries to quickly find the desired rows of a table without having to fully view it. Using indexes can drastically reduce the number of I / O operations when executing a query, which reduces response time and, as a result, increases system throughput. Let's see how indexes are arranged in Teradata, taking into account the parallel architecture.
Data Access Methods
Teradata DBMS supports various ways of accessing table rows:
Access by the primary index (what was the primary index discussed in our first article )
This is the fastest and least expensive way to access data in Teradata.
Recall that the data in the Teradata DBMS is distributed using the result of hashing the value of the primary index column. Rows with the same primary index column values ALWAYS fall on the same AMP.
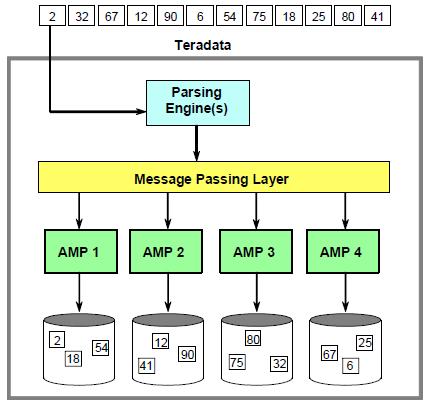
The algorithm used to determine the AMP on which the row should be placed when it is inserted into the table is used with the same success to find the row with the known value of the primary index column.
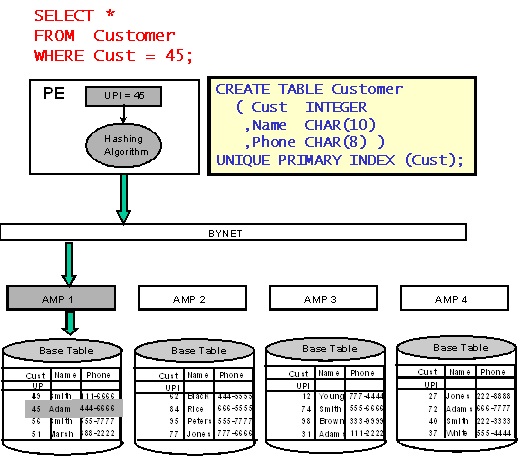
When the AMP on which the search string is located is determined, Teradata uses index structures to find the required data block. Sequentially viewed:
- Master Index (always loaded into AMP's memory) to search for a cylinder containing the desired data block;
- Cylinder Index (almost always loaded into AMP's memory) to search for the desired data block.
After the required data block is found, it is read and then the line is searched using an array of row pointers (Row Reference Array).
This algorithm works the same for both unique (Unique Primary Index - UPI) and non-unique (Non-unique Primary Index - NUPI) primary indices - the only difference is that when accessing via UPI, only one data block is always read and no more one row, while when accessing via NUPI, these values depend on the degree of nonuniqueness of the index.
Base Table Row Format
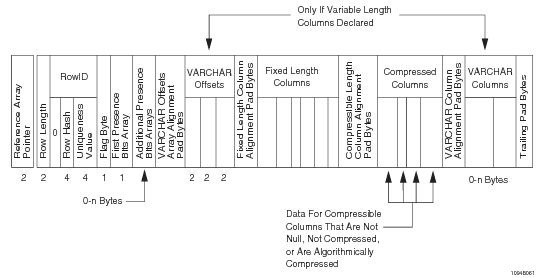
The peculiarity of data storage in Teradata is that on each AMP, table rows are not stored in random order, but sorted by hash values of the primary index. This approach requires additional efforts when inserting data, since new rows need to be inserted not at the “end of the table”, but in order to keep the hash sorting. In doing so, we get two advantages:
- When joining on a primary index column, the ability to immediately apply an effective MERGE JOIN join, since the rows are already ordered.
- Automatic indexing of the primary index column. The internal indexes of the file system (master index and cylinder index) indicated above contain within themselves ranges of hash values for the data stored in data blocks. Due to the fact that the lines are ordered, these ranges do not intersect. As a result, when creating the layout of disk space for data blocks, we actually get not only this layout, but also the indexing of the primary index column - a classic B-tree index based on hash values of the primary index. We even sometimes say that the primary index does not take up disk space and does not require maintenance, bearing in mind that it is part of the "master index" and "cylinder-index" structures for storing data on the AMP disk system.
The features of this algorithm also determine its inherent limitations, namely access by the primary index is possible only under the following conditions:
- using the condition "equal" in the query for filtering by the primary index column;
- inclusion in the search conditions ALL columns that make up the primary index.
Secondary Index Access
Secondary indexes are alternative ways to access data. Implemented in the form of index sub-tables, which allow identifying the corresponding row identifiers of the base table by the value of the indexing column.
The implementation of index sub-tables of unique (Unique Secondary Index - USI) and non-unique (Non-unique Secondary Index - NUSI) secondary indices are different.
USI Index Subtable Row Format

The rows of the USI index subtable are distributed among AMPs using the hash of the index column. With a high probability, the row of the index table will be on another in relation to the corresponding row of the base table AMP'e. Each row of the base table corresponds to a row of the index subtable. Accessing data using the USI requires the involvement of two AMPs (the first to search for a row in the index, the second to read the row of the base table by its identifier). Access to data using the USI can be considered as effective as using the primary index. The main purpose of USI is to access data by the value of the index column. In the same way as for the primary index, the expression “WHERE” must indicate ALL columns that make up the index with the condition “EQUAL”.

NUSI Index Subtable Row Format

The rows of the NUSI index subtable are located locally (on the same AMPs) relative to the rows of the base table and are logically sorted by default by the hash value of the secondary index column. Such storage means that rows with the same index column value can be found on any of the AMPs in the system, and therefore, all AMPs will be involved in the search for the required rows in the index subtable. Further, only those AMPs on which rows of the index subtable are selected will be used to select rows from the base table. Whether the optimizer will use NUSI to access data depends on the selectivity of the index. As a value, above which the optimizer selects a full table scan, you can focus on 1% (if less than 1% of the table rows are selected during the query, the index will be used).
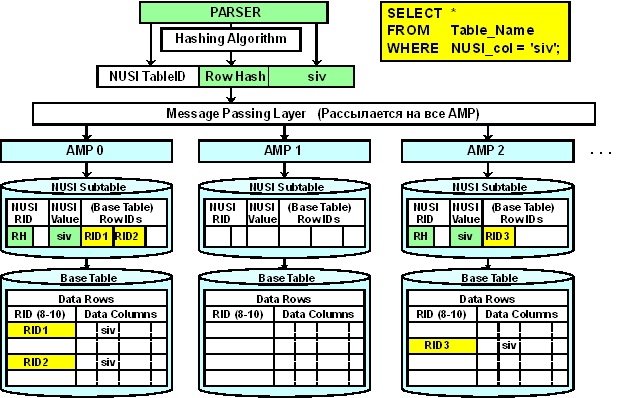
As with PI and USI, by default, NUSI is used to access rows by value (the condition is “EQUAL” on all NUSI columns in the WHERE clause). But besides this, NUSI can also be used for queries with range access to table rows, for which there is an option “ORDER BY VALUES”, which logically sorts the rows of the index subtable by the value of the index column. An index created in this way allows you to improve performance with conditions on the index column other than "EQUAL": <,>,> =, <=, BETWEEN.
Also, as you can see from the row format of the index subtable, more than one RowID of the base table can fall on one value of the index column. This makes the NUSI index subtable automatically compressed, which minimizes disk space usage.
Full table scan (Full Table Scan, or FTS)
There is especially nothing to say about this access method. Teradata uses it when other ways of accessing data, from the point of view of the optimizer, are ineffective. I just want to note that searching for rows by full viewing in Teradata is very effective due to the MPP architecture, since many AMPs simultaneously scan the fragments of the table distributed over them. Often, the complete reading of tables containing millions of rows requires each AMP to complete just a few I / O operations.
At the end of this review of access to the data of the primary / secondary index tables, I would like to note that Teradata will always prefer the primary index to the secondary and unique to non-unique when there are alternatives.
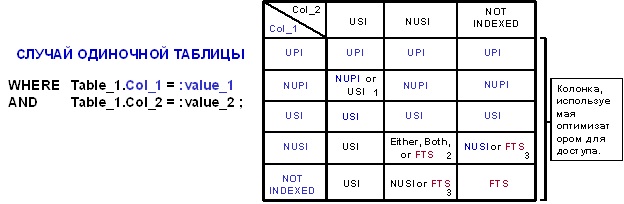
1. The optimizer prefers the primary index over the secondary, and unique indexes over the nonunique. Preference will be given to NUPI only if one block of data is requested (1 I / O).
2. Depending on the selectivity, the optimizer may use NUSI, NUSI Bit Mapping, or FTS.
3. It all depends on the selectivity of the index.
Table Join Access
Another way to access data is to join two or more tables. This process has one very important feature specific to MPP platforms. It consists in the fact that the join of the tables is performed by AMPs, and the data participating in the join should be on the corresponding AMPs.
As you remember, the distribution of table rows by AMPs depends on the primary index, and rows of joined tables with the same values of the join column are not always located on the same AMPs. Therefore, not always, but often the join of the tables is preceded by a preparatory operation. An exception is the combination of two tables on a primary index column, since in this case, rows with the same primary index column values are already on the same AMP. Joining tables by PI columns is the fastest.
To perform table joining in all other cases, Teradata can ensure that there are rows on the same AMP with the same join column value in the following ways (important: all derived data sets are materialized in SPOOL - the temporary storage area for intermediate query results):
- Duplication of rows of a small table for all AMPs;
- redistribution of the rows of one / both tables of the join step along the join column (PI change). In this case, the table itself remains in place, and a temporary copy of those rows that participate in the query (not necessarily the entire table) is created with a different primary index.
Which of the above methods will be chosen by the optimizer depends on the demographics of the data, the availability of collected statistics and indexes (Teradata can use some types of indexes, for example, NUSI, to improve connection performance).
When the availability of the necessary data on AMPs is ensured, Teradata can use traditional table join strategies, such as:
- MERGE JOIN:
- Row Hash;
- Inclusion
- Exclusion
- PRODUCT JOIN;
- NESTED JOIN;
- HASH JOIN.
What you need to have to carry out a high-quality physical design
Logical model
Directly to physical modeling is traditionally preceded by the creation of a logical model, which later serves as a template for creating database objects. The structure of a good logical model can be implemented in a one-to-one database.
In relation to corporate data warehouses, the logical model is a description of all the organization's business processes. It should be implemented in such a way as not only to solve existing business problems, but also to support its further development. Creating such a model from scratch is a very non-trivial and time-consuming task requiring excellent knowledge of the subject area and modeling techniques. In this article we will not discuss the issues of logical modeling, we only note that in our projects we try to use the industry-specific logical Teradata logic models that have been tested by time and numerous implementations. To those who consider Western models unsuitable for use on the Russian market, we object that in practice the amount of work on localization (or rather, adapting the model to the customer’s processes,
Data
No, you can, of course, simulate “in a vacuum”, but for a physical model it is extremely important to have before your eyes data that will later be loaded into the model. This allows you to make decisions about how to transition from a logical model to a physical one. Some believe that a one-to-one physical model corresponds to a logical one, but this is far from always the case. For example, as a result of data analysis, a decision may be made to implement several entities of a logical data model in the form of a single table in a physical table. And this is just one example.
Demographics
No matter how good the logical model is, just a set of entities and relationships is not enough to carry out high-quality physical design - an understanding of the specifics of the data and the nature of their use is necessary. Usually we analyze several demographics:
- data demography - data volumes, frequency diagrams, etc.
- demography of variability - how often data in a particular column of the table changes;
- usage demography - whether columns are used to access data by value (single or by range of values) or by connection.
Knowing the demographics listed above allows the creator of a physical model to make a conscious choice.
Obviously, not all of these demographics are known before using the model. In particular, the methods of accessing data and the frequency of accessing one or another model column to 100% 99% can be found out only after a long period of operation of the storage. But a fairly large number of access methods can be thought out in advance, based on the logic of the implementation of the model itself.
Patience and mindfulness
Physical modeling is a fascinating process, but not always clearly algorithmized. To paraphrase the character of the famous Soviet cartoon: "Physical modeling is not an exact science." On the one hand, this provides opportunities for creativity, on the other hand, it takes time, attention, and often an iterative approach, so attention to detail and patience when working with large data models play a key role in physical modeling.
Index Selection
Indexes are often used as one of the main ways to optimize a physical model for specific usage patterns. Sometimes the choice of indexes may seem obvious. Let's look at an example where the obvious is not always true.
Imagine the following table: ACCOUNT (1,000,000 rows)
| Acct_id | Acct_num | Acct_open_dt | Acct_close_dt | Acct_pty_id |
| PK | NOT NULL, UNIQUE | NOT NULL | NOT NULL, FK | |
| UPI | USI | NUSI | NUSI? | NUSI |
The third line contains the proposed selection of indexes.
Legend:
- UPI (Unique Primary Index)
- NUPI (Non-Unique Primary Index)
- USI (Unique Secondary Index)
- NUSI (Non-Unique Secondary Index)
Can you say with confidence that this choice is the right one? I think that the experience of creating physical models for a particular DBMS can suggest the right choice, but in the general case, it is impossible to say that the choice made is correct. Speaking about the example presented above, one can, for example, ask a question: is a search in this table carried out by account identifier? If the answer is no, you can exclude the Acct_id column from the candidates for the primary index.
A simple example shows that even the best logical model is not enough to create a physical model. An understanding of data demographics is required (see above). We complement the above example with demographics and see if this makes the task easier.
Same ACCOUNT table (1,000,000 rows)
| Acct_id | Acct_num | Acct_open_dt | Acct_close_dt | Acct_pty_id | |
| PK | NOT NULL, UNIQUE | NOT NULL | NOT NULL, FK | ||
| Access frequency by value | 800 | 10K | 1K | 500 | 1K |
| Connection Access Frequency | 3K | 0 | 0 | 0 | 5K |
| Unique lines | 1000K | 1000K | 731 | 256 | 400K |
| Max. number of rows per value (not NULL) | 1 | 1 | 2056 | 1K | 7 |
| Typical number of rows per value | 1 | 1 | 1235 | 400 | 2 |
| Number of NULL Rows | 0 | 0 | 0 | 900K | 0 |
| Estimated Choice | USI | NUSI | NUSI | ||
| Demographic Based Choice | NUSI | USI | NUSI | NUSI? | Nupi |
As you can see, the initial selection of indexes has been changed. There are quite objective reasons for this:
- For the Acct_pty_id column
, Primary Index Access is the most efficient data access method in Teradata. As we see from the example, access by the value of this column occurs frequently. In addition, the same column is most often used to connect to another table. Joining the two tables along the primary index columns is also most preferred for Teradata. - For column Acct_id
This column is also used for access quite often. Since the choice of the primary index has already been made, we can create a non-unique secondary index for the most efficient reading of table rows by value and increase the performance of the connections. - For the column Acct_close_dt, the
choice of the index is called into question due to the fact that for certain values (NULL) Teradata will not use it due to insufficient selectivity.
Partitioning tables in Teradata
If the table is large in volume, then the natural desire is to break it into parts (partitions) and scan only these partitions instead of fully viewing the table.
In Teradata, the following two mechanisms — AMP distribution and partitioning — complement each other effectively. Partitioned tables are distributed among AMPs in the same way as nonpartitioned tables. Further, on each AMP, the lines are sorted first by partition, and the partition numbers are recorded in the master index and index cylinder for addressing the data blocks. And then, inside partitions, rows are already sorted by hash values of the primary index, as well as for non-partitioned tables.
Thus, if we run a query like “partition_better column BETWEEN value1 AND value2”, then all AMPs work in parallel and scan each fragment of the table, but not completely, but only the necessary partitions.
There is also a multilevel partitioning, when there are several columns - at the same time subpartitions are created inside the partitions.
All large tables are usually partitioned. This physical design technique can improve the performance of certain queries that are filtered by partition fields.
Conclusion
In this article, we decided to confine ourselves to a description of the basic principles and elements used in performing the physical design of the databases for the Teradata DBMS. Using only these practices in your work will allow you not to step on the "rake" at the very beginning of the path for those who are just starting to work with massive-parallel DBMSs.
In the next article, “Advanced Physical Modeling Techniques in Teradata,” we plan to tell you about additional features for indexing and compressing data in Teradata.
Waiting for your questions.