ShareJS or how to make your Google Wave with OT and NodeJS
- Tutorial

After two years of work on OT (a technique for resolving conflicts with data sharing) for Google Wave, Joseph (Joseph Gentle) came up with the idea that for those who want to make a similar product, it will take almost a little less time. To somehow help these people and share knowledge, the ShareJS library was written , which is an implementation of OT based on NodeJS. There is also a C implementation .
What is OT?
OT is Operational Transformation or Operational Transformation.
We have data and there are operations on this data. Operations come to us in turn. The whole point is that before you perform yourself on the data, the operation itself changes according to all previous operations on the current data.
A good example from Wikipedia:
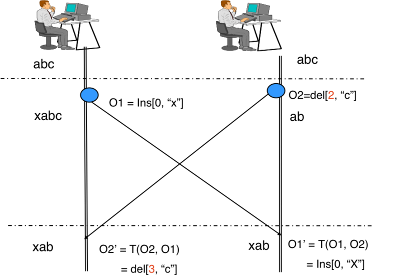
At the initial time, both users have the string 'abc', for which they simultaneously create two operations:
O1 = Insert [0, “x”] (insert the character “x” at position “0”)
O2 = Delete [2, “c” ] (delete the character “c” at position “2”)
Depending on the order of execution of these operations, the result will be different.
If O2, O1, then 'abc' -> 'ab' -> 'xab'
If O1, O2, then 'abc' -> 'xabc' -> 'xac'
How would we get the same result 'xab' in both cases ? Convert operations, taking into account previous changes? What would it look like with OT?
O2: 'abc' -> 'ab'
OT: O1 Insert [0, "x"] -> O1` Insert [0, "x"]
O1`: 'ab' -> 'xab'
In this case, the operations O1 and O1` are identical (Insert [0, “x”]) because the previous operation O2 was above the characters in the position more than the position for O1. Thus, O2 does not affect O1 and does not change it.
O1: 'abc' -> 'xabc'
OT: O2 Delete [2, “c”] -> O2` Delete [3, “c”]
O2`: 'xabc' -> 'xab'
In this case, OT takes into account that before O2 there was already an operation O1, which inserted one character in front of the position for O2 and therefore O2 should remove the character not from position 2, but from position 3. That's all magic.
Read more about OT: wiki , FAQ
Data types
In OT, a lot depends on the type of data. After all, operations (as well as operations on o_O operations) are different for different data types. For example, all operations with a string can ultimately be reduced to just 3:
- Move the carriage to position n
- Insert a string n at the current position
- Delete n characters starting at the current position
Or even two:
- Insert a string at a position n
- Delete m characters starting at position n
First of all, we are interested in the json data type and there everything is somewhat more complicated, since json can consist of objects, arrays, strings, numbers. These are all different data types. We have already seen how this works for strings. For arrays, a similar situation. Also, OT can deal with the increment of a number. More complicated with objects: if two users simultaneously overwrite the json object field, then it is impossible to take into account changes from both users for the common json data type. One of two operations will be lost. If this is critical, you can create your own data types specific to your application.
The data types for ShareJS are a separate OTTypes project . There are currently several implementations for string and json. The plans are for a rich-text data type.
Arichtecture
ShareJS consists of server and client parts. Part of the code (for example, the transformation of operations) is isomorphic, that is, it is performed both on the server and on the client. The operation store uses LiveDB , which consists of Mongo (data) and Redis (operation cache). Data Model - Document Oriented - Collections and Documents. Each document has a data type and version, which is incremented with every change to the document. Operations are atomic at the document level.
The client performs several synchronous operations. They are grouped (setTimeout (sendToServer, 0);), compressed (successive identical ones are combined, those that neutralize the action of each other are deleted) and sent to the server all in bulk.
If the version of the operation data corresponds to the current version of the data in the database, then the operation is applied, if not, then the server tries to find the history of intermediate operations first in Redis, then in Mongo (by default also the repository of all operations). The operation is transformed according to the intermediate operations and applied to the data. The execution of operations itself occurs sequentially (transaction) in Redis (Lua script), where once again the relevance of the data version is checked, if the version is no longer relevant, then the circle is repeated again.
With the help of Redis PubSub, data change events are caught and intermediate operations are sent to all subscribed clients, where they are applied accordingly.
This model allows you to have consistent data on the one hand, and high speed and scalability on the other.
LiveDB can be implemented in another form. The main thing is that the store supports transactions and events (PubSub). For example, Foundation DB is perfect for this.
In the current implementation, communication with Mongo is provided by the adapter , which can be rewritten for any other database.
By default, the entire history of operations is stored in the same Mongo database as the data. You can not store it at all or store it in another database.
Application
ShareJS is great for creating real-time data sharing applications like Google Wave, Google Docs, etc.
There is a wrapper over ShareJS - RacerJS . This is essentially a beautiful interface for working with data. It is possible to use RacerJS with client frameworks (AngularJS, Backbone, etc.).
For those who want everything and immediately there is DerbyJS . This is a full-stack isomorphic framework using RacerJS as a model for working with data.
Questions about ShareJS, RacerJS, DerbyJS can be asked in Stackoverflow Chat (Need a reputation on Stackoverflow> 20)
DerbyJS content