How to migrate ONTAP and not go crazy

Migration of IT systems is not an easy task. But the particular difficulty is the situation when you need not just to switch from the old hardware to the new one, but to move to the new operating system on the existing hardware, and without migration of productive data. One such move lasted about a year, and preparation took most of the time.
The client has two sites in different cities, and each has two interconnected data storage systems. Information from one storage system using built-in replication is sent to the second. Management is performed using an external backup system. Two NetApp 3250 systems are installed in one city, the other is the main NetApp 6220 and the backup NetApp 3250. The client plans to expand this complex in the future, add disks, and upgrade controllers.
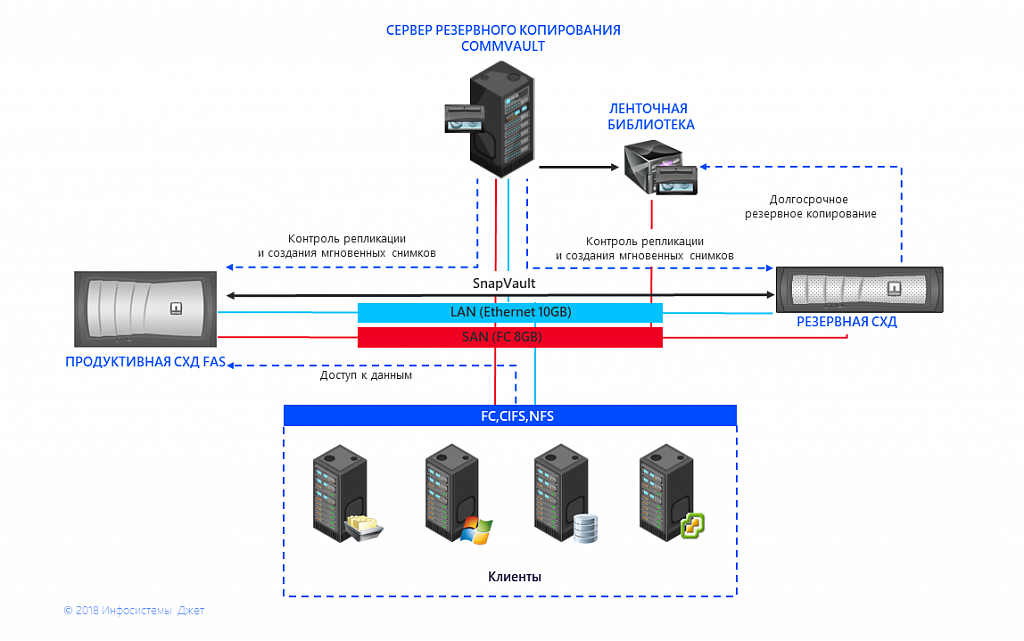
Fig. 1 Scheme of interaction between storage systems and RMS.
And this is the main problem - the end of support. For the Data ONTAP 8.2 operating system installed on the storage system, 7-Mode major updates have not been for a couple of years, and the release of critical bug fixes will cease in 2021. New drives and controllers are not compatible with an outdated operating system.
The solution is to switch to the ONTAP 9.1 cluster system as the last supported for these storage controllers. Its main advantages are:
- Horizontal scaling by combining into a single fault-tolerant cluster, which will allow creating a unified system based on productive storage and RMS.
- Load sharing between controllers, disks, as well as data movement within the storage system without interrupting the service and stopping access to applications.
- Maintenance of hardware and software data storage systems without stopping their work and interrupt service.
- The ability to create heterogeneous cluster configurations, including controllers and disks of various types, including third-party storage systems, subject to the use of licenses to virtualize their disk capacity.
- The ability to use SSD as a caching layer for aggregates.
- Optimized work of Data Compaction mechanisms (compression and deduplication).
There are 3 options for migrating from 7 mode to Cluster Mode:
- Migrate with data replication using the Netapp 7-Mode Transition Tool (7MTT) utility and copy-based transition (CBT) mode. This requires a second storage system with disk space of a smaller volume and phased replication based on SnapMirror. For each service, the switches are negotiated and executed at the specified time.
At one of our customers, we have already done this procedure on the metro cluster. Due to the large number of volumes, LUNs (> 400) and long coordination of parts, downtime, etc. migration took about 3 months without preparation. - Migrate without moving data using the Netapp 7-Mode Transition Tool (7MTT) utility and copy-free transition (CFT) mode. This requires a second storage system with a minimum number of disks, to which, after preliminary preparation, the productive disk subsystem will be switched. For all services one big downtime is negotiated.
- Migration with data copying by means of a host. This is a traditional migration path between storage systems of any manufacturers.
Since the existing storage systems were still on vendor support, and there was a shortage of controller performance in the short term, the budget for the purchase of new controllers was not allocated. In this regard, it was decided to migrate the controllers to Cluster Mode using 7MTT CFT. One of the key requirements was the absence of noticeable interruptions in the work of the data storage system: most systems must operate smoothly on weekdays. Therefore, the main work on migration to a productive storage system was assigned for the weekend.
The preparation phase began with the collection of information from the storage system and preliminary checks. Specialized software NetApp 7MTT generates a list of warnings that can interfere with the migration or complete it with errors. For example, for one of the systems, this list consisted of more than 200 items. It was necessary to upgrade all systems to the latest supported OS versions, to update the firmware of the controllers, disk shelves and the disks themselves. Also, the new operating system has a different operation logic, requiring additional IP addresses and connections between the storage systems.
The stop factor was quickly discovered: the client used a technology that was not based on replicating volumes entirely, but on qtree replication (a subsection to which restrictions on access, volume, etc.) apply. And it is impossible to migrate such SnapVault relations to the new OS . As a result, before starting work it would be necessary to completely remove all replication copies. So that the client after the move does not remain without backups, a backup based on the entire replication of the volumes was launched before the migration. With SnapMirror, new backups were created next to the old ones, and in the course of four weeks a log of changes was accumulated. And if at one of the sites there was enough space for this, then the second space was limited, it was necessary to gradually make copies of one of the volumes. After four weeks, old relationships were removed and new ones were created. Sufficiently long, phased process, which in the case of one site took about 1.5 months, and in the second more than 3. Additionally, I want to note that the procedure for stopping the Snapvault relationship is accompanied by the removal of the target qtree and its speed depends strongly on the number of files and, to a lesser extent, on its size. For example, a qtree with 4 million files and 500GB in size was deleted within 24 hours.
In the process there were various difficulties. The bureaucratization of the processes of making changes on the client’s systems increased the time needed to coordinate the work. Fortunately, we managed to agree on solving technical issues directly, discussing at a higher level only important, “ideological” issues, such as agreeing on a work plan and choosing specific dates for migration.
Difficulties delivered using temporary storage. Under the guidance of 7MTT, both storage systems were configured according to the requirements and pre-checks. Then they turned off the old storage system and connected the disk shelves to the new one. They checked everything again. From the point of view of the NetApp software, the migration process is complete and everyone is leaving
Additional time was laid for work on the second site, hoping to avoid at least some of the problems, but this did not help - the operating system behaved unpredictably. The schedule moved twice. In the first case, when we were working with FAS3250, it was impossible to migrate the combat systems operating 24/7, due to an error in the recently changed settings of the customer's network infrastructure (although when testing migration a week before the start of work, everything flew). vMotion to a remote storage system was copied by virtuals with a speed of less than 1 Mb / s.
During the migration process, the client partially changed the architecture. Volumes that were delivered to their VMware vSphere infrastructure were previously issued over NFS Ethernet. The client redid them, and they moved to the Fiber Channel. During the migration process, it turned out that the LUN completely changed the ID and, accordingly, VMware saw new LUNs that were addressed to it with old data, and refused to connect them permanently. As a result, thanks to the help of VMware specialists, it was possible to connect these LUNs through the console on an ongoing basis, indicating that this is a snapshot of old datastores. Then I had to restart VMware-hosts. As a result, they were able to see the virtual machines and raise the virtual infrastructure. And if the client continued to use NFS, then such a problem would not have occurred - the IP address and DNS name would remain the same as before.
Work plan directly on migration days:
Friday: work with storage systems and RMS
- SnapVault and SnapMirror ceased all relationships, switched the temporary storage system and checked the readiness of the systems for migration. We launched migration procedures for storage at 7MTT using the Copy Free Transition method. Reconnect the combat disk shelves to the temporary controller.
- Migrated to 7MTT, migrated root vol swap controllers on the disk shelves of the storage system. We installed new Ethernet adapters, launched the storage system for SRK, erased the configuration and downloaded the OS image over the network from the HTTP server. Installed new versions of the firmware and OS (at this stage there were unexplained problems with downloading the image over the network. In the end, they downloaded directly from the laptop).
- We replaced the controllers in the cluster with the old ones and connected the combat disk shelves to the storage system according to the upgrading by moving storage procedure. We restored the work of the cluster, reconfigured network interfaces (we had to solve problems related to incorrect cluster operation) and installed license keys.
Saturday: work with the main storage system
- We connected the temporary disk shelves to a temporary storage system and set it up again.
- Migrated important virtual machines on the storage to a remote data center using VMware vMotion.
- Migrated basic storage in 7MTT using the CFT method. We turned off the main combat storage, connected its disk shelves to the controller and converted the OS metadata to 7MTT. Migrated root vol swap controllers on disk shelves SHD SRK.
- We installed new Ethernet adapters and launched the combat storage in diskless configuration, erased the settings, and then downloaded over the network from the HTTP server. Install new firmware and OS versions. We replaced the controllers in the cluster, connected the combat disk shelves to the storage system according to the upgrading by moving storage procedure.
- Restored the work of the cluster, reconfigured network interfaces (fiddling with the incorrect work of the cluster due to the connected combat network interfaces). Installed license keys.
- We restored the storage connections to the VMware servers, changed the zoning in the SAN network, configured the LUN mapping, and moved the volumes to a separate SVM to work with FC access. LUN connected to ESXi. Due to the fact that the LUN ID has changed, the datastores did not appear in automatic mode, I had to sequentially restart the ESXi servers and connect the LUN commands via esxcli.
- Reconfigured combat interfaces, renamed CIFS servers, and restored access to CIFS balls and NFS exports.
Sunday: problem solving and software configuration
- Virtual machines migrated back from the storage system to the combat storage system.
- Solved the problem with access to the folder in the recording mode from a Linux host. We deployed the latest version of the monitoring software Netapp onCommand Unified Manager 7.3 and connected both storage systems to it.
- Analyzed the data on the current load on the units using the Unified Manager software, using the SSD connected the caching layer to the existing disk units (Flash / Storage Pool).
- Turned off the substitution storage system, created connections between clusters (Cluster peering, SVM peering) so that replication could be used. We created a new SnapMirror relationship between the main storage system and the storage system of the CPM based on the existing volumes (used in the SnapMirror 7 mode relationship) with resynchronization of the changed data, and then converted the SnapMirror relationship into the SnapVault relationship (SnapMirror XDP).
- Both storage systems were connected to the Commvault software in the NetApp Open Replication mode using Commvault technical support, but it did not work out differently, although everything was done according to the instructions. Configured sending Autosupport logs from combat storage and storage system.
Monday: grinding
- Verification of the work of the main productive storage system and storage system. Solving possible problems and problems.
- Disconnection and dismantling of temporary equipment.
The migration itself took only two days. The move was successful, all customer data is safe and sound. Also, the backup management system and integration with the existing software of IBS was preserved. If the Commvault with OnCommand Unified Manager was previously used, then after switching to Cluster Mode, it was decided to abandon it in favor of Netapp Open Replication to connect Commvault directly to the storage controllers.
The main recommendations that I can give on the results of this migration are to switch from 7 mode to Cluster Mode along with the replacement of controllers. If you still plan to move to the second controllers, as in the case described above, then you need to plan for enough time to solve various problems that will arise when you move back to the old controllers. Using migration without moving data using 7MTT CFT is quite a safe procedure, if you entrust it to professionals.
Useful guides that were used during this migration:
- Netapp portal with ONTAP 9 OS documentation and 7MTT software
- Netapp portal with FAS and AFF storage documentation, section on controller upgrades
- Hardware Universe portal to determine hardware compatibility for Netapp
- Netapp Open Replication Tutorial for Commvault
Dmitry Kostryukov, Lead Design Engineer of Data Storage Systems of the
Jet Infosystems Computing Systems Design Center