How we created a recommendation service for the selection of clothes on neural networks
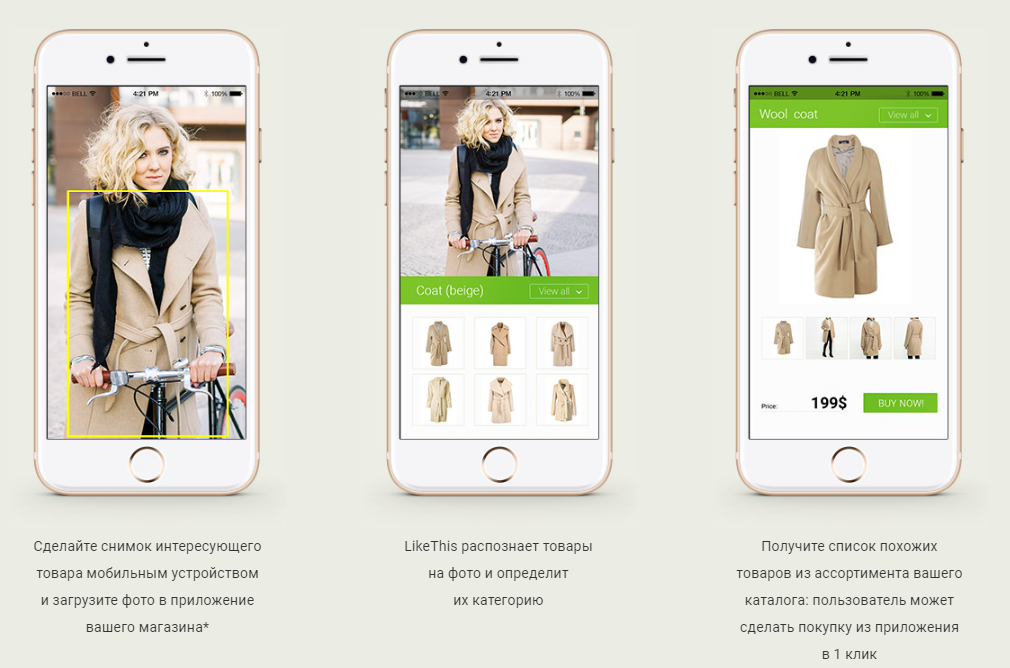
In this article I want to talk about how we created a search system for similar clothes (or rather clothes, shoes and bags) from a photograph. That is, to put it in business terms, is a recommendation service based on neural networks.
Like most modern IT solutions, you can compare the development of our system with the assembly of the Lego designer, when we take a lot of small parts, instructions, and create a ready-made model from this. Here's the instruction: what parts to take and how to apply them so that your GPU can select similar products from a photo - you will find in this article.
What parts our system is built from:
- detector and classifier of clothes, shoes and bags on images;
- crawler, indexer or module of work with electronic catalogs of stores;
- similar image search module;
- JSON-API for convenient interaction with any device and service;
- web interface or mobile application for viewing results.
At the end of the article, all the “rakes” that we attacked during the development and recommendations on how to neutralize them will be described.
Task setting and rubricator creation
The task and the main use-case of the system sounds quite simple and clear:
- the user submits to the entrance (for example, through a mobile application) a photograph on which there are garments and / or bags and / or shoes;
- the system detects (detects) all these items;
- finds for each of them the most similar (relevant) products in real online stores;
- gives the user goods with the ability to go to a specific page of the goods for purchase.
Simply put, the goal of our system is to answer the famous question: “Do you have the same, only with pearl buttons?”
Before you rush into the pool of coding, marking and learning of neural networks, you need to quite clearly define the categories that will be inside your system, that is, the categories that will be detected by the neural network. It is important to understand that the wider and more detailed the list of categories is, the more universal it is, since a large number of narrow small categories such as mini-dress, midi-dress, maxi-dress can always be combined into one category of type of type with one touch. BUT NOT vice versa. In other words, the rubricator needs to be well thought out and compiled at the very beginning of the project, so that later not to redo the same work 3 times. We made a rubricator, taking as a basis several large stores, such as Lamoda.ru, Amazon.com, and tried to make it as wide as possible on the one hand, on the other hand, it is as versatile as possible in order to make it easier to connect the categories of the detector with the categories of various online stores in the future (I will talk more about how to make this link in the crawler and indexer section). Here is an example of what happened.

Example of categories of rubricator
In our catalog at the moment there are only 205 categories: women's clothing, men's clothing, women's shoes, men's shoes, bags, clothes for newborns. The full version of our classifier is available here .
Indexer or module of work with electronic catalogs of stores
In order to look for similar products in the future, we need to create an extensive database of what we are looking for. In our experience, the quality of searching for similar images directly depends on the size of the search base, which should exceed at least 100K images, and preferably 1M images. If you add 1-2 small online stores to your database, you most likely will not get impressive results simply because in 80% of cases there is nothing really like the desired item in your catalog.
So, to create a large database of images you need to process catalogs of various online stores, this is what this process includes:
- first you need to find XML feeds of online stores, you can usually find them either freely available on the Internet, or by asking from the store itself, or in various aggregators like Admitad;
- The feed is processed (parsed) by a special program - a crawler that downloads all the images from the feed, adds them to the hard disk (more precisely, to the network storage to which your server is connected), writes all the meta information about the goods in the database;
- then another process starts - an indexer that calculates binary 128-dimensional feature vectors for each image. It is possible to combine the crawler and indexer into one module or program, but historically, we had different processes. This was mainly due to the fact that initially we calculated descriptors (hashes) for each image distributed on a large fleet of machines, since it was a very resource-intensive process. If you work only with neural networks, then the 1st machine with the GPU is enough for you;
- binary vectors are written to the database, all processes are completed and voila - your product database is ready for further search;
- but one little trick remains: since all the stores have different catalogs with different categories inside, you need to compare the categories of all feeds contained in your database with the categories of the detector (more precisely, the classifier) of goods, we call this the process of creating mapping. This is a manual routine, but very useful work, during which the operator, manually editing a regular XML file, compares the categories of feeds in the database with the categories of detector. Here is what comes out:
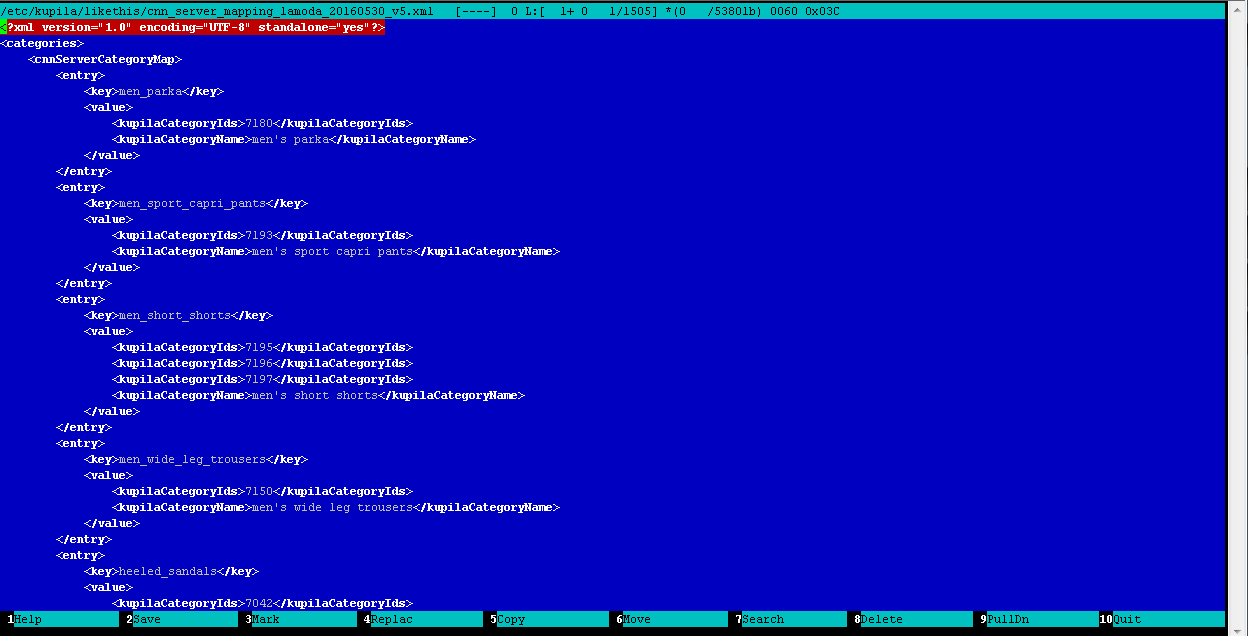
Example category mapping file: catalog categories categorizer
Detection and classification
In order to find something similar to what our eye found in the photo, we need to detect this “something” (i.e., localize and select the object). We have come a long way in creating the detector, starting with the training of OpenCV cascades, which did not work at all on this task, and ending with the modern R-FCN detection and classification technology and classifier based on the ResNet neural network .
We took all sorts of images from the Internet as data used for training and testing (the so-called training and test samples):
- Google search / Yandex images;
- third-party tagged data sets;
- social networks;
- fashion magazine sites;
- Internet shops of clothes, shoes, bags.
The markup was carried out using a samopisny tool, the result of the markup were sets of images and * .seg-files to them, which store the coordinates of the objects and class labels for them. On average, from 100 to 200 images were marked out for each category; the total number of images in 205 classes was 65,000.
After the training and test samples are ready, we did a double-check markup, giving all the images to another operator. This made it possible to filter out a large number of errors that greatly affect the quality of training of the neural network, that is, the detector and classifier. Then we start training the neural network with standard means and “remove” the next snepshot of the neural network “with the heat of the heat” after a few days. On average, the training time of the detector and classifier on the data volume of 65,000 images per GPU of the order Titan X is approximately 3 days.
The finished neural network must somehow be checked for quality, that is, to assess whether the current version of the network has become better than the previous one and how much. How we did it:
- the test sample consisted of 12,000 images and was labeled in exactly the same way as the training sample;
- we wrote a small tool that ran the entire test sample through the detector and compiled a table of this type (the full version of the table is available by reference );
- This table is added to Excel on a new tab and compared with the previous one manually or using the built-in Excel formulas;
- at the output, we get the overall TPR / FPR indicators of the detector and classifier for the entire system in and for each category separately.

An example of a table-report on the quality of the detector and classifier
Similar Image Search Module
After we have detected the wardrobe items in the photo, we launch a mechanism for searching for similar images, this is how it functions:
- for all cut-off image fragments (detected goods), neural network 128-bit binary feature vectors are calculated in shape and color (where they come from the vectors below);
- the same vectors, previously calculated at the indexing stage, for all images of goods stored in the database are already loaded into the computer’s RAM (since to search for similar ones, we will need to perform a large number of searches and pairwise comparisons, we loaded the entire database into memory at once, which allowed us to increase search speed is dozens of times, while the base of about 100 thousand products breaks no more than 2-3 GB of RAM);
- from the interface or from hard-coded properties, search coefficients for this category come, for example, in the “dress” category we are looking for more in color than in form (for example, 8-to-2 search for color-form), and in the “heel shoes” category we are looking for 1-to-1 form-color as the shape and color are equally important here;
- then the vectors for the crocks (fragments) from the input image are compared in pairs with the image from the base, taking into account the coefficients (the Hamming distance between the vectors is compared);
- as a result, an array of similar products from the database is formed for each cut-out item, and a weight is also assigned to each item (using a simple formula, taking into account the normalization, so that all weights are in the range from 0 to 1) for output to the interface, as well as for further sorting;
- An array of similar products is displayed in the interface via the web-JSON-API.
Neural networks for the formation of neural network vectors in shape and color are taught as follows.
- To train a neural network in form, we take all the marked images, cut out the fragments by markup and distribute them into folders according to the class: that is, all the sweaters in one folder, all the T-shirts in the other, and all high-heeled shoes in the third one and so on. d. Next, we train an ordinary classifier based on this sample. Thus, we kind of “explain” the neural network its understanding of the shape of the object.
- In order to train a neural network in color, we take all the marked images, cut out the fragments by markup and distribute them into folders according to color: that is, put all T-shirts, shoes, bags, etc. in the “green” folder green color (in general, any objects of green color accumulate in the end), in the “stripped” folder we put all the things in a strip, and in the “red-white” folder all the red and white things. Next, we train a separate classifier for these classes, as if “explaining” the neural network its understanding of the color of a thing.
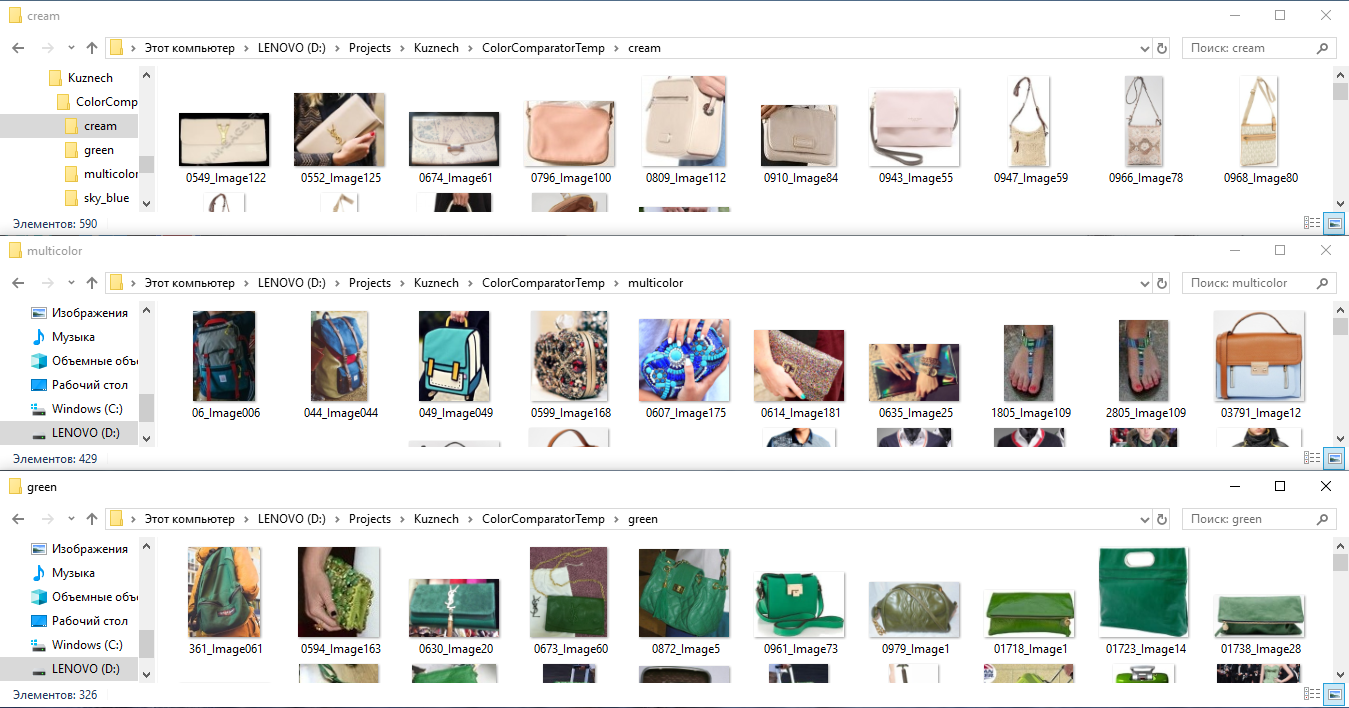
An example of marking images by color for obtaining neural network feature vectors by color.
Interestingly, this technology works fine even on difficult backgrounds, that is, when fragments of things are not cut out clearly along the contour (mask), but along a rectangular frame, which was determined by the stripper.
The search for similar ones is made on the basis of extracting binary feature vectors from the neural network in the following way: the output of the penultimate layer is taken, compressed, normalized and binarized. In our work, we compressed up to a 128-bit vector. You can do it a little differently, for example, as described in the Yahoo article " Deep Learning Retrieval of the Binary Coverage ", but the essence of all algorithms is about the same — you look for similar images by comparing the properties that the neural network operates within the layers.
Initially, as a technology to search for similar images, we used hashes or image descriptors based on (more precisely calculated) using certain mathematical algorithms, such as the Sobel operator (or contour hash), the SIFT algorithm (or singular points), the construction of the histogram or the comparison of the number of angles in the image . This technology worked and gave some more or less sane result, but nothing compared with the technology of searching for similar images based on the properties selected by the neural network hashes do not go. If you try to explain the difference in 2 words, then the hash-based image comparison algorithm is a “calculator” that was configured to compare pictures using some formula and it works continuously. And the comparison with the help of signs from the neural network is “artificial intelligence”, trained by a person to solve a specific task in a certain way. We can give such a rough example: if you search for hashes with a black-and-white striped sweater, then you are more likely to find all black-and-white things as similar. And if you search using a neural network, then:
- in the first places you will find all the sweaters with black and white stripes,
- then all black and white sweaters
- and then all the striped sweaters.
JSON-API for easy interaction with any device and service
We created a simple and convenient WEB-JSON-API for communicating our system with any devices and systems, which, of course, is not an innovation, but rather a good strong standard for development.
Web interface or mobile application for viewing results
To visually check the results, as well as to demonstrate the system to customers, we have developed simple interfaces:
- web interface, http://demo.likethis.me/
- mobile application is available by reference
Mistakes that were made in the project
- Initially, it is necessary to define the task more clearly and, based on the task, select photos for marking. If you need to search for UGC (User Generated Content) photos, this is one case and markup examples. If you need to search for photos from glossy magazines, this is a different case, and if you need to search by photos, where one large object is located on a white background, this is a separate story and a completely different sample. We mixed all this in one pile, which affected the quality of the detector and classifier.
- In photographs you always need to mark ALL objects, at least from the fact that at least somehow fit your task, for example, when selecting a similar selection of wardrobe, you had to immediately mark all accessories (beads, glasses, bracelets, etc.), head headwear, etc. Because now, when we have a huge training set, in order to add another category we need to re-allocate ALL photos, and this is a very voluminous work.
- Detection is probably best done by the mask network, the transition to Mask-CNN and a modern solution based on Detectron is one of the directions of the system development.
- It would be nice to immediately decide how you are going to determine the quality of selection of similar images - there are 2 methods: “by eye” and this is the easiest and cheapest method and 2nd - “scientific” method when you collect data from “experts” (people which test your search algorithm similar) and on the basis of this data you form a test sample and a catalog for searching similar images. This method is good in theory and looks pretty convincing (for yourself and for customers), but in practice its implementation is difficult and quite expensive.
Conclusion and future development plans
This technology is quite ready and suitable for use, now it functions at one of our customers in the online store as a recommendation service. Also recently, we set about developing a similar system in another industry (that is, we are now working with other types of goods).
From the nearest plans: transfer of the network to Mask-CNN, as well as re-marking and additional image markup to improve the quality of the detector and classifier.
In conclusion, I would like to say that, according to our feelings, such technology and neural networks in general are capable of solving up to 80% of the complex and highly intelligent tasks with which our brain meets daily. The only question is who first implements this technology and relieves a person from routine work, freeing him the space for creativity and development, which is, in our opinion, the highest purpose of man!