Активность мозга человека впервые транслировали в чёткую речь
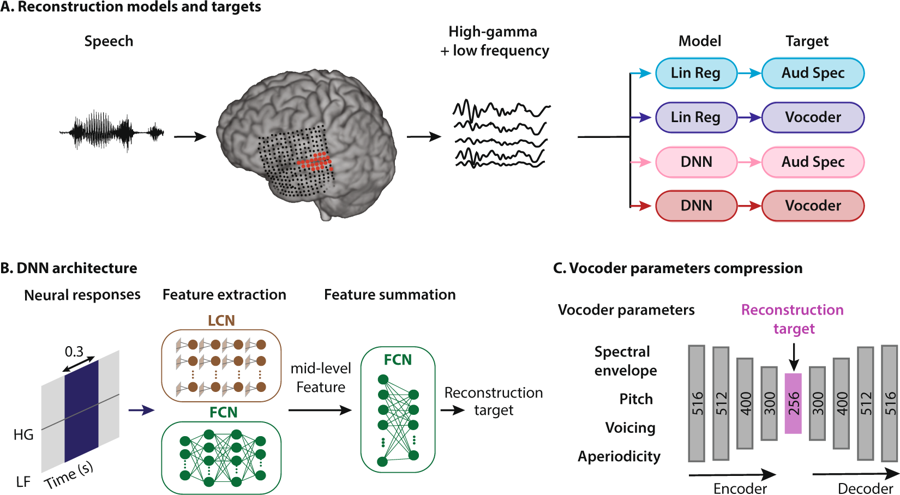
Diagram of speech reconstruction method. A person listens to words, as a result, neurons of his auditory cortex are activated. The data is interpreted in four ways: a combination of two types of regression models and two types of speech representations, then transferred to the neural network system to extract features, which are subsequently used to adjust vocoder parameters
Neuro engineers of Columbia University (USA) were the first in the world to create a system that translates human thoughts into understandable , distinguishable speech, here is the sound recording of words (mp3), synthesized by brain activity.
Watching the activity in the auditory cortex, the system recovers, with unprecedented clarity, the words a person hears. Of course, this is not the articulation of thoughts in the literal sense of the word, but an important step has been taken in this direction. After all, similar patterns of brain activity occur in the cerebral cortex when a person imagines that he is listening to a speech, or when he mentally speaks words.
This scientific breakthrough using artificial intelligence technologies brings us closer to creating effective neural interfaces that connect computers directly to the brain. It will also help to communicate to people who can not speak, as well as those who recover from a stroke or for some other reason temporarily or permanently unable to pronounce words.
Decades of research have shown that in the process of speech or even mental speaking of words, control models of activity appear in the brain. In addition, a distinct (and recognizable) pattern of signals occurs when we listen to someone or imagine that we are listening. Experts have long been trying to record and decipher these patterns in order to “free” the thoughts of a person from the skull - and automatically translate them into oral form.
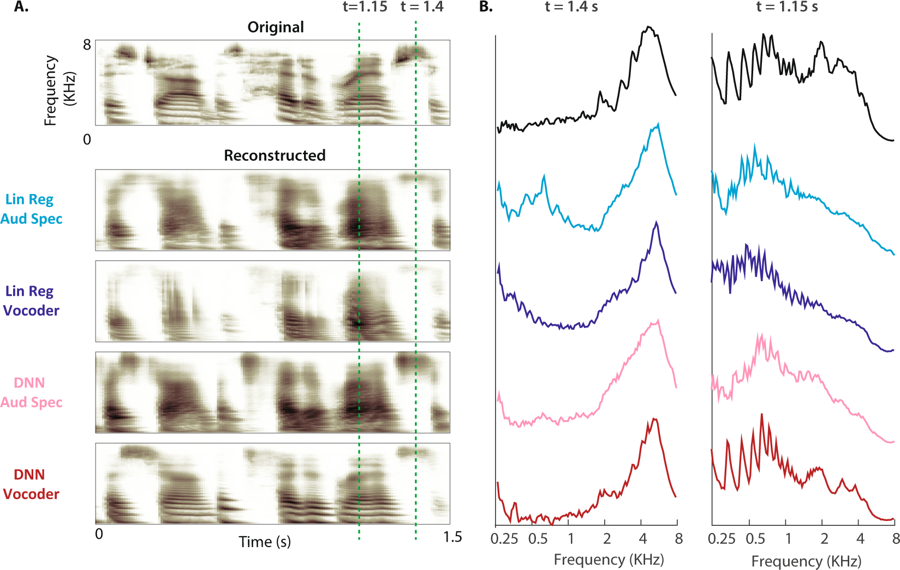
(A) The top shows the original spectrogram of the speech pattern. Below are the reconstructed auditory spectrograms of four models. (B) Magnetic power of frequency bands during unvoiced (t = 1.4 s) and voiced speech (t = 1.15 s: the gap is shown by dashed lines for the original spectrogram and four reconstructions)
"This is the same technology used by Amazon Echo and Apple Siri for oral answers to our questions, ” explainsDr. Nima Mesgarani, lead author of scientific work. To teach the vocoder to interpret brain activity, specialists found five patients with epilepsy who had already undergone brain surgery. They were asked to listen to suggestions made by different people, while electrodes measured brain activity, which was processed by four models. These neural patterns taught vocoder. Then the researchers asked the same patients to listen to the dynamics of the numbers from 0 to 9, recording brain signals that could be passed through the vocoder. The sound produced by the vocoder in response to these signals is analyzed and cleaned by several neural networks.
As a result of processing at the output of the neural network, a robot voice was received, pronouncing a sequence of numbers. To test the accuracy of recognition, people were given to listen to sounds synthesized from their own brain activity: “We found that people can understand and repeat sounds in 75% of cases, which is much higher than any previous attempt,” said Dr. Mesgarani.
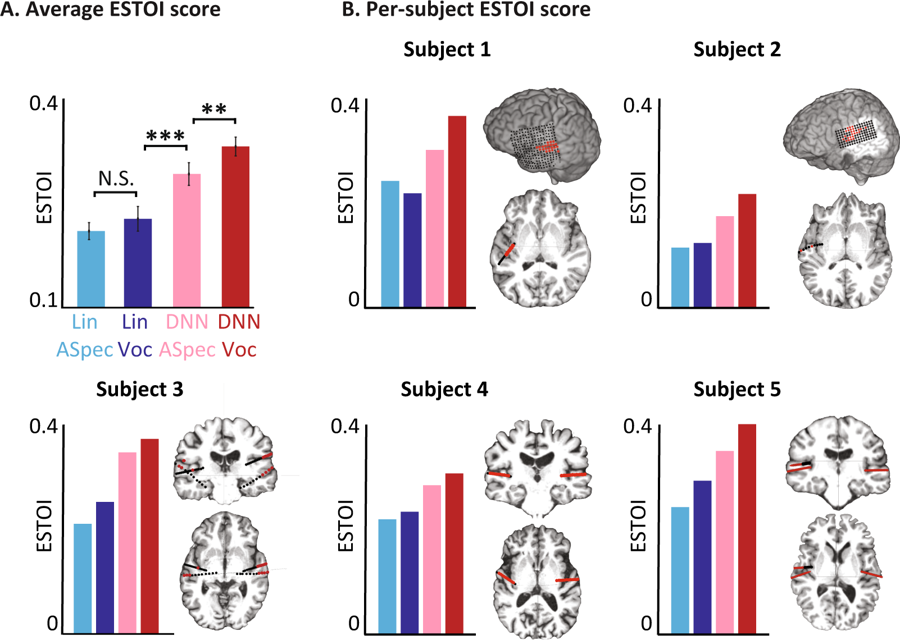
Objective evaluations for different models. (A) The average score for the standard ESTOI score for all subjects for four models. B) The coverage and location of the electrodes and the ESTOI score for each of the five people. Everyone has an ESTOI vocoder rating of DNN higher than other models.
Now scientists are planning to repeat the experiment with more complex words and sentences. In addition, the same tests will run for brain signals when a person imagines what he is saying. Ultimately, they hope the system will become part of an implant that translates the wearer's thoughts directly into words.
The scientific article was published on January 29, 2019 in open access in the journal Scientific Reports (doi: 10.1038 / s41598-018-37359-z).
The code for conducting phoneme analysis, calculating high-frequency amplitudes and restoring the auditory spectrogram is made publicly available .