Creating an application on .NET Core and Kubernetes: our experience
Hello!
Today we will tell about the experience of one of our DevOps projects. We decided to implement a new Linux application using .Net Core on the microservice architecture.
We expect that the project will be actively developed, and there will be more and more users. Therefore, it should be easily scaled both in functionality and in performance.
We need a fault-tolerant system - if one of the blocks of functionality does not work, then the rest should work. We also want to ensure continuous integration, including the deployment of the solution on the customer’s servers.
Therefore, we used the following technologies:
In this article we will share the details of our decision.

This is a transcript of our performance on .NET-mitap, here is a link to the video of the speech.
Our customer is a federal company, where there are merchandisers - these are people who are responsible for the way goods are presented in stores. And then there are supervisors - these are the heads of merchandisers.
The company has a process of learning and evaluating the work of merchandisers by supervisors, which needed to be automated.
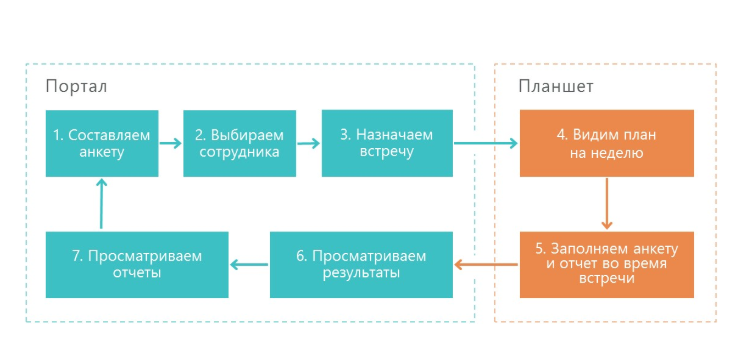
Here is how our solution works:
1. The supervisor prepares the questionnaire - this is the checklist of what needs to be checked in the work of the merchandiser.
2. Next, the supervisor selects the employee whose work will be checked. The date of the survey is assigned.
3. Next, the activity is sent to the mobile device of the supervisor.
4. Then the questionnaire is filled out and sent to the portal.
5. The portal generates results and various reports.
1. In the future, we want to easily extend the functionality, since there are many similar business processes in the company.
2. We want the solution to be fault tolerant. If some part ceases to function, the decision will be able to restore its work independently, and the failure of one part will not greatly affect the work of the decision as a whole.
3. The company for which we are implementing a solution has many branches. Accordingly, the number of users of the solution is constantly growing. Therefore, I wanted this to not affect performance.
As a result, we decided to use microservices on this project, which required taking a number of non-trivial decisions.
• Docker makes it easy to distribute solution distribution. In our case, the distribution kit is a set of microservice images
• Since there are a lot of microservices in our solution, we need to manage them. For this we use Kubernetes.
• We implement microservices ourselves using .Net Core.
• To quickly update a solution with a customer, we must implement convenient continuous integration and delivery.
Here is our set of technologies in general:
• .Net Core we use to create microservices,
• Microservice is packaged in a Docker image,
• Continuous integration and continuous delivery is implemented using TFS,
• Front end part is implemented on Angular,
• For monitoring and logging we use Elasticsearch and Kibana,
• RabbitMQ and MassTransit are used as an integration bus.
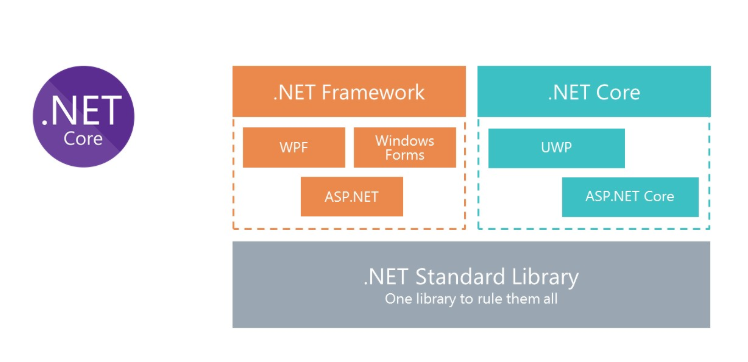
We all know what the classic .Net Framework is. The main disadvantage of the platform is that it is not cross-platform. Accordingly, we cannot launch solutions on the .Net Framework platform under Linux in Docker.
To allow Docker to use C #, Microsoft rethought the .Net Framework and created .Net Core. And in order to use the same libraries, Microsoft created the .Net Standard Library specification. .Net Standart Library assemblies can be used in the .Net Framework and .Net Core.
Kubernetes is used to manage and cluster Docker containers. Here are the main advantages of Kubernetes that we used:
- provides the ability to easily configure the microservice environment,
- simplifies the environment management (Dev, QA, Stage),
- out of the box provides the ability to replicate microservices and load-balance replicas.
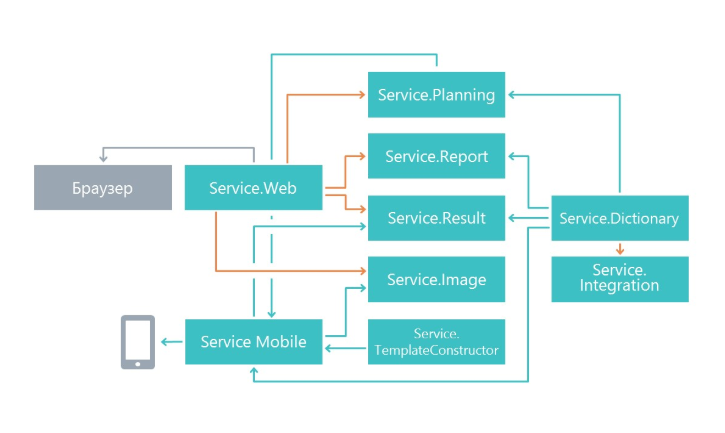
At the beginning of the work, we wondered how to divide the functionality into microservices. The split was done on the principle of common responsibility, only at the level of more. Its main task is to make changes in one service as little as possible affect other microservices. As a result, in our case, microservices began to perform a separate functional area.
As a result, we have services that are engaged in planning questionnaires, microservice displaying the results, microservice working with a mobile application and other microservices.
Microsoft in his book about microservices “ .NET Microservices. The architecture of .NET container applications offers three possible implementations of interaction with microservices. We reviewed all three and selected the most appropriate.
• API Gateway service The
API Gateway service is an implementation of a facade for user requests to other services. The problem of the solution is that if the facade does not work, then the whole solution will cease to function. We decided to abandon this approach for the sake of resiliency.
• API Gateway with Azure API Management
Microsoft provides the ability to use the cloud facade in Azure. But this solution did not come up, since we were going to deploy the solution not in the cloud, but on the customer’s servers.
• Direct Client-To-Microservice communication
As a result, we still have the last option - direct user interaction with microservices. We chose it.
Its plus in fault tolerance. The downsides are that some of the functionality will have to be reproduced on each service separately. For example, it was necessary to configure authorization separately on each microservice to which users have access.
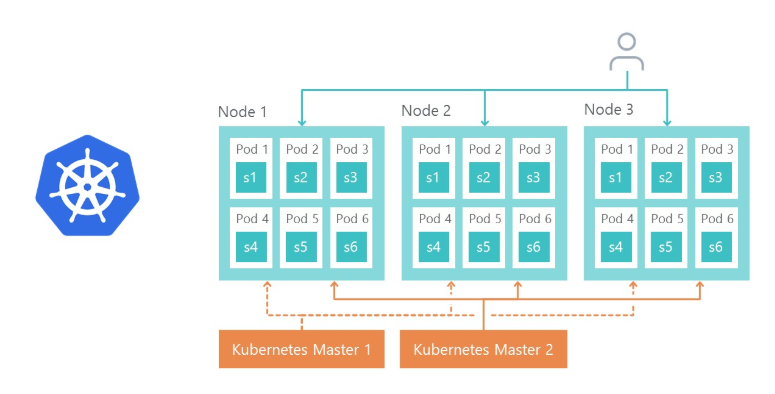
Of course, the question arises how we will balance the load and how fault tolerance is implemented. Everything is simple - this is what the Ingress Controller Kubernetes does.

Node 1, node 2 and node 3 are replicas of one microservice. If one of the replicas fails, then the load balancer will automatically redirect the load to the other microservices.
Here's how we organized the infrastructure of our solution:
• Each microservice has its own database (if it is, of course, needed), other services do not apply to the database of another microservice.
• Microservices communicate with each other only via RabbitMQ + Mass Transit bus, as well as using HTTP requests.
• Each service has its own clearly defined responsibility.
• For logging we use Elasticsearch and Kibana and library to work with him Serilog .
The database service was deployed on a separate virtual machine, and not in Kubernetes, because Microsoft DBMS does not recommend using Docker on product environments.
The logging service was also deployed on a separate virtual machine for reasons of fault tolerance - if we have problems with Kubernetes, then we can figure out what the problem is.
Our infrastructure has created 3 Neimespeys in Kubernetes. All three environments refer to one database service and one logging service. And, of course, each environment looks at its database.
On the infrastructure of the customer, we also have two environments - this is pre-production and production. In production, we have separate database servers for pre-production and product environments. For logging, we have allocated one ELK server on our infrastructure and on the customer's infrastructure.
On average, we have 10 services per project and three environments: QA, DEV, Stage, on which about 30 microservices are deployed. And it is only on the development infrastructure! Let's add 2 more environments on the customer's infrastructure, and we get 50 microservices.
It is clear that such a number of services must somehow be managed. Kubernetes helps us in this.
In order to deploy a microservice, you need to
• Expand the secret,
• Expand the deployement,
• Expand the service.
We'll write about secret below.
Deployment is the instruction for Kubernetes, on the basis of which it will launch the Docker container of our microservice. Here is the deployment deployment team:
This file describes what is called deployment (imtob-etr-it-dictionary-api), which image it needs to use for execution, plus other settings. In the secret section we will customize our environment.
After deployment, we need to deploy a service, if necessary.
Services are needed when access to microservice is required from outside. For example, when it is necessary for a user or another microservice to be able to make a Get request to another microservice.
Usually the description of the service is small. In it we see the name of the service, how it can be accessed and the port number.
As a result, for the deployment of the environment, we need
• a set of files with secret for all microservices,
• a set of files with deployment of all microservices,
• a set of files with service all of microservices.
All these scripts are stored in the git repository.
To deploy the solution, we have a set of three types of scripts:
• folder with secrets - these are the configurations for each environment,
• folder with deployment s for all microservices,
• folder with service s for some microservices,
in each - about ten teams, one for each microservice. For convenience, we brought a page with scripts in Confluence, which helps us quickly deploy a new environment.
Here is the deployment deployment script (there are similar sets for the secret and for service):
Each service is in its own folder, plus we have one folder with shared components.
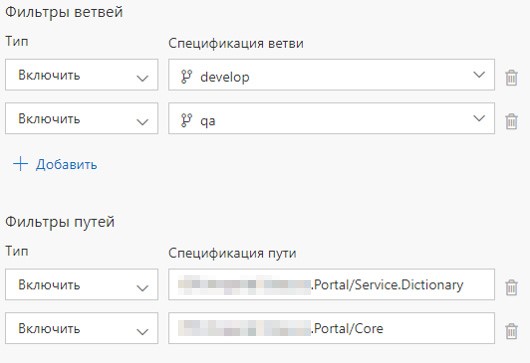
Also for each microservice there is Build Definition and Release Definition. We set up the launch of Build Definion when committing to the appropriate service or commiting to the appropriate folder. If the contents of the folder with shared components are updated, then all microservices are deployed.
What advantages from such an organization Build-we see:
1. The solution is in one git-repository,
2. If you change in several microservices, the assembly runs in parallel if there are free assembly agents,
3. Each Build Definition represents a simple script from the image assembly and its push in the Nexus Registry.
How to deploy a VSTS agent, we previously described in this article .
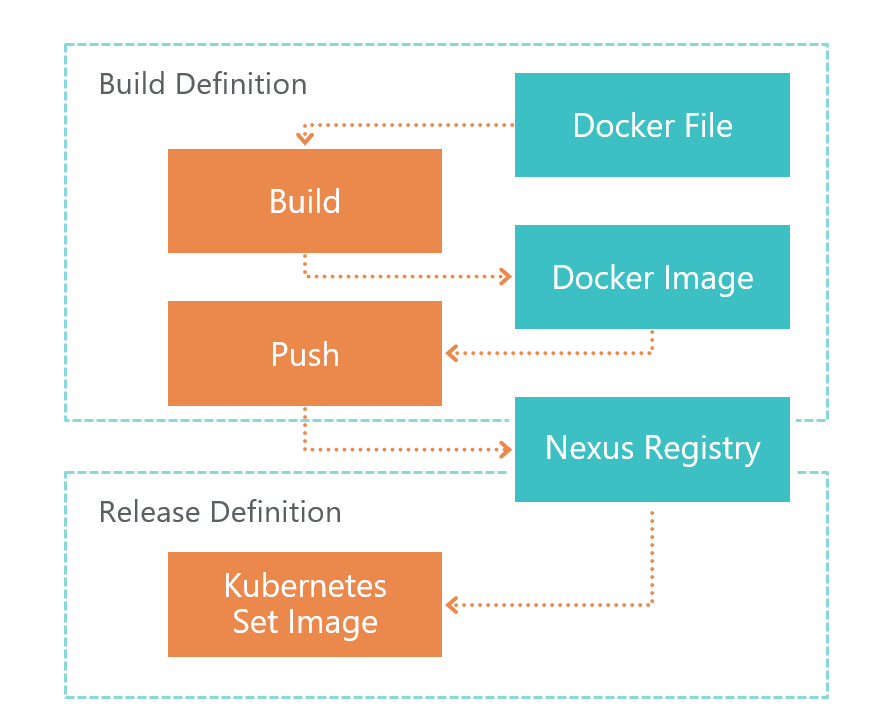
First comes Build Definition. At the command of TFS, the VSTS agent launches the Dockerfile build. As a result, we get the image of microservice. This image is saved locally on the environment where the VSTS agent is running.
After the build, Push is launched, which sends the image we received in the previous step to the Nexus Registry. Now it can be used from the outside. Nexus Registry is a kind of Nuget, not only for libraries, but for Docker images and not only.
After the image is ready and accessible from the outside, it needs to be deployed. For this we have Release Definition. Everything is simple here - we execute the set image command:
After that, it will update the image for the desired microservice and launch a new container. As a result, our service has been updated.
Let's now compare the build with and without Dockerfile.
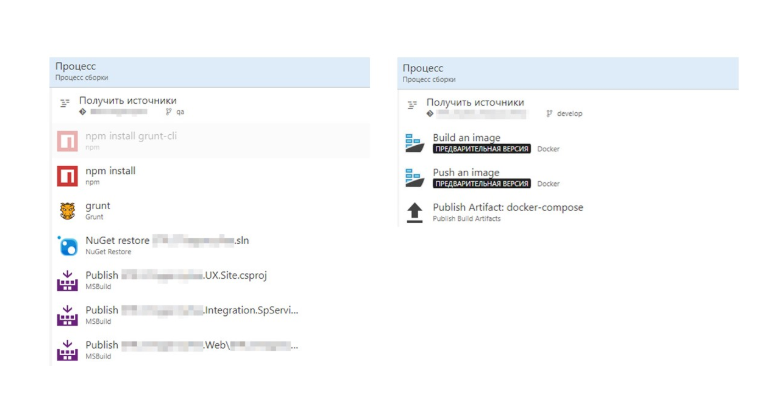
Without Dockerfile, we have many steps, in which there is a lot of specificity of .Net. On the right, we see a Docker image build. Everything has become much easier.
The entire image building process is described in the Dockerfile. This assembly can be debugged locally.

1. Separation of development and deployment. The assembly is described in the Dockerfile and lies on the shoulders of the developer.
2. When configuring CI / CD, you do not need to know about the details and features of the assembly - work is carried out only with Dockerfile.
3. We update only changed microservices.
Further it is required to nastrit RabbitMQ in K8S: about it we wrote separate article .
Anyway, we need to configure microservices. The main part of the environment is configured in the root configuration file Appsettings.json. This file stores settings that are independent of the environment.
Those settings that depend on the environment, we store in the secrets folder in the appsettings.secret.json file. We took the approach described in the article Managing ASP.NET Core App Settings on Kubernetes .
The appsettings.secrets.json file stores settings for Elastic Search indexes and a database connection string.
In order to add this file, you need to deploy it in the Docker-container. This is done in the deployment file of a cubnet. In deployment, it describes in which folder you need to create a file with secret and with which secret you need to associate the file.
Create a secret in Kubernetes using the utility kubectl. We see here the name of the secret and the path to the file. We also indicate the name of the environment for which we are creating a secret.
1. High entry threshold. If you are doing a similar project for the first time, there will be a lot of new information.
2. Microservices → more complex design. It is necessary to apply a lot of non-obvious solutions due to the fact that we have not a monolithic solution, but a microservice one.
3. Not everything is implemented for Docker. Not everything can be run in microservice architecture. For example, while SSRS is not in docker.
1. Infrastructure as a code
Description of the infrastructure is stored in the source control. At the time of deployment does not need to adapt the environment.
2. Scaling both at the functional level and at the level of performance out of the box.
3. Microservices are well isolated.
Virtually no critical parts, the failure of which leads to the inoperability of the system as a whole.
4. Fast delivery of changes.
Only microservices in which there were changes are updated. If we do not take into account the time for coordination and other things related to the human factor, then we update one microservice in 2 minutes or less.
1. On .NET Core it is possible and necessary to implement industrial solutions.
2. K8S really made life easier, simplified updating of environments, and facilitated the configuration of services.
3. TFS can be used to implement CI / CD for Linux.
Today we will tell about the experience of one of our DevOps projects. We decided to implement a new Linux application using .Net Core on the microservice architecture.
We expect that the project will be actively developed, and there will be more and more users. Therefore, it should be easily scaled both in functionality and in performance.
We need a fault-tolerant system - if one of the blocks of functionality does not work, then the rest should work. We also want to ensure continuous integration, including the deployment of the solution on the customer’s servers.
Therefore, we used the following technologies:
- .Net Core for the implementation of microservices. In our project version 2.0 was used,
- Kubernetes for microservice orchestration,
- Docker for creating microservice images,
- Rabbit MQ and Mass Transit integration bus,
- Elasticsearch and Kibana for logging,
- TFS to implement the CI / CD pipeline.
In this article we will share the details of our decision.
This is a transcript of our performance on .NET-mitap, here is a link to the video of the speech.
Our business challenge
Our customer is a federal company, where there are merchandisers - these are people who are responsible for the way goods are presented in stores. And then there are supervisors - these are the heads of merchandisers.
The company has a process of learning and evaluating the work of merchandisers by supervisors, which needed to be automated.
Here is how our solution works:
1. The supervisor prepares the questionnaire - this is the checklist of what needs to be checked in the work of the merchandiser.
2. Next, the supervisor selects the employee whose work will be checked. The date of the survey is assigned.
3. Next, the activity is sent to the mobile device of the supervisor.
4. Then the questionnaire is filled out and sent to the portal.
5. The portal generates results and various reports.
Microservices will help us solve three problems:
1. In the future, we want to easily extend the functionality, since there are many similar business processes in the company.
2. We want the solution to be fault tolerant. If some part ceases to function, the decision will be able to restore its work independently, and the failure of one part will not greatly affect the work of the decision as a whole.
3. The company for which we are implementing a solution has many branches. Accordingly, the number of users of the solution is constantly growing. Therefore, I wanted this to not affect performance.
As a result, we decided to use microservices on this project, which required taking a number of non-trivial decisions.
What technologies helped to implement this solution:
• Docker makes it easy to distribute solution distribution. In our case, the distribution kit is a set of microservice images
• Since there are a lot of microservices in our solution, we need to manage them. For this we use Kubernetes.
• We implement microservices ourselves using .Net Core.
• To quickly update a solution with a customer, we must implement convenient continuous integration and delivery.
Here is our set of technologies in general:
• .Net Core we use to create microservices,
• Microservice is packaged in a Docker image,
• Continuous integration and continuous delivery is implemented using TFS,
• Front end part is implemented on Angular,
• For monitoring and logging we use Elasticsearch and Kibana,
• RabbitMQ and MassTransit are used as an integration bus.
.NET Core for Linux solutions
We all know what the classic .Net Framework is. The main disadvantage of the platform is that it is not cross-platform. Accordingly, we cannot launch solutions on the .Net Framework platform under Linux in Docker.
To allow Docker to use C #, Microsoft rethought the .Net Framework and created .Net Core. And in order to use the same libraries, Microsoft created the .Net Standard Library specification. .Net Standart Library assemblies can be used in the .Net Framework and .Net Core.
Kubernetes - for microservice orchestration
Kubernetes is used to manage and cluster Docker containers. Here are the main advantages of Kubernetes that we used:
- provides the ability to easily configure the microservice environment,
- simplifies the environment management (Dev, QA, Stage),
- out of the box provides the ability to replicate microservices and load-balance replicas.
Solution Architecture
At the beginning of the work, we wondered how to divide the functionality into microservices. The split was done on the principle of common responsibility, only at the level of more. Its main task is to make changes in one service as little as possible affect other microservices. As a result, in our case, microservices began to perform a separate functional area.
As a result, we have services that are engaged in planning questionnaires, microservice displaying the results, microservice working with a mobile application and other microservices.
Options for interaction with external consumers
Microsoft in his book about microservices “ .NET Microservices. The architecture of .NET container applications offers three possible implementations of interaction with microservices. We reviewed all three and selected the most appropriate.
• API Gateway service The
API Gateway service is an implementation of a facade for user requests to other services. The problem of the solution is that if the facade does not work, then the whole solution will cease to function. We decided to abandon this approach for the sake of resiliency.
• API Gateway with Azure API Management
Microsoft provides the ability to use the cloud facade in Azure. But this solution did not come up, since we were going to deploy the solution not in the cloud, but on the customer’s servers.
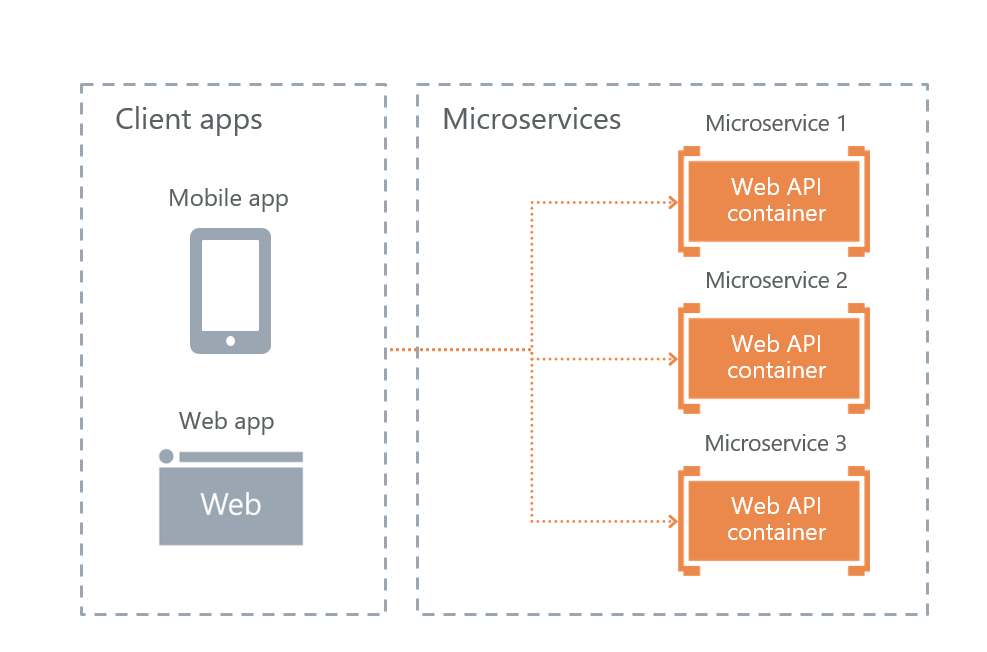
• Direct Client-To-Microservice communication
As a result, we still have the last option - direct user interaction with microservices. We chose it.
Its plus in fault tolerance. The downsides are that some of the functionality will have to be reproduced on each service separately. For example, it was necessary to configure authorization separately on each microservice to which users have access.
Of course, the question arises how we will balance the load and how fault tolerance is implemented. Everything is simple - this is what the Ingress Controller Kubernetes does.
Node 1, node 2 and node 3 are replicas of one microservice. If one of the replicas fails, then the load balancer will automatically redirect the load to the other microservices.
Physical architecture
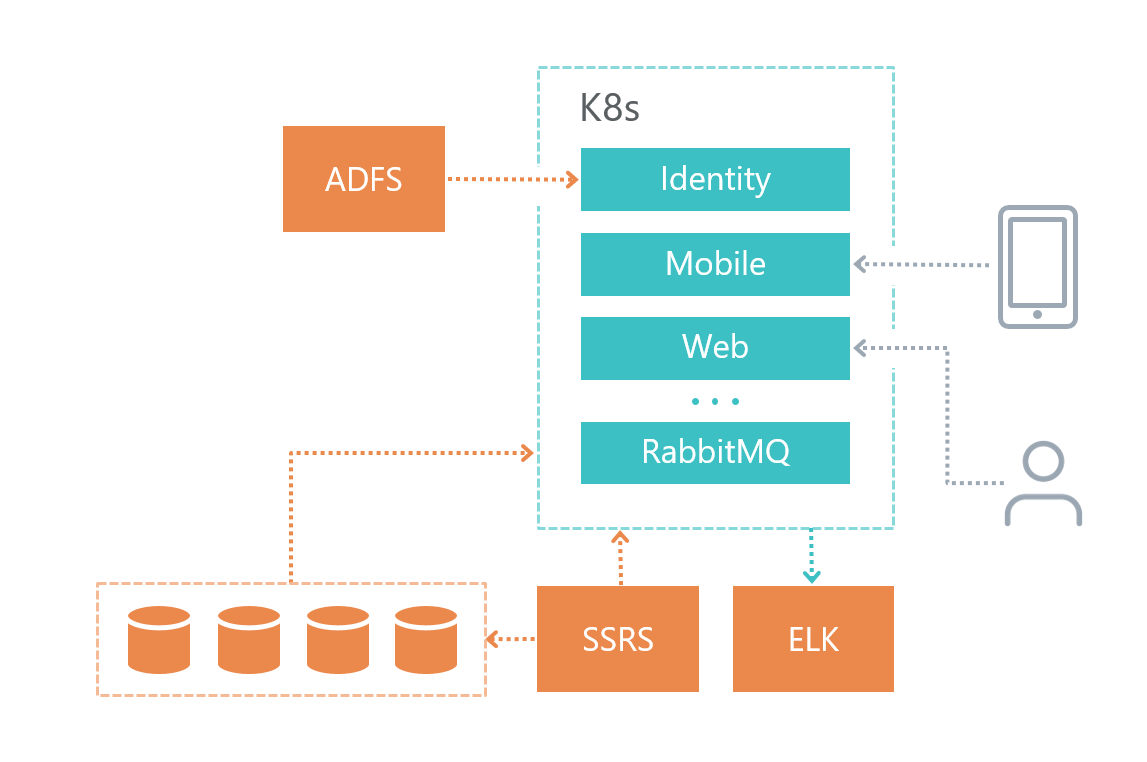
Here's how we organized the infrastructure of our solution:
• Each microservice has its own database (if it is, of course, needed), other services do not apply to the database of another microservice.
• Microservices communicate with each other only via RabbitMQ + Mass Transit bus, as well as using HTTP requests.
• Each service has its own clearly defined responsibility.
• For logging we use Elasticsearch and Kibana and library to work with him Serilog .
The database service was deployed on a separate virtual machine, and not in Kubernetes, because Microsoft DBMS does not recommend using Docker on product environments.
The logging service was also deployed on a separate virtual machine for reasons of fault tolerance - if we have problems with Kubernetes, then we can figure out what the problem is.
Deployment: how we organized the development and product environments
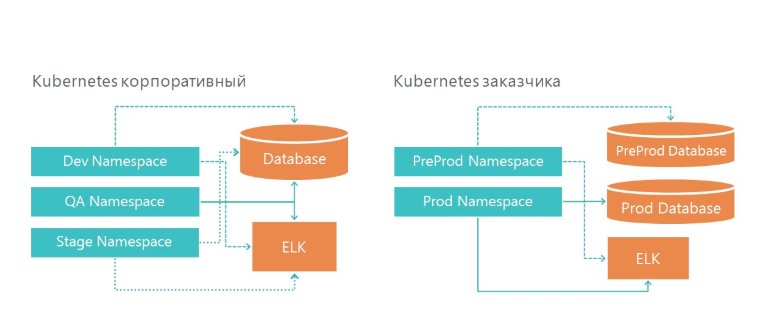
Our infrastructure has created 3 Neimespeys in Kubernetes. All three environments refer to one database service and one logging service. And, of course, each environment looks at its database.
On the infrastructure of the customer, we also have two environments - this is pre-production and production. In production, we have separate database servers for pre-production and product environments. For logging, we have allocated one ELK server on our infrastructure and on the customer's infrastructure.
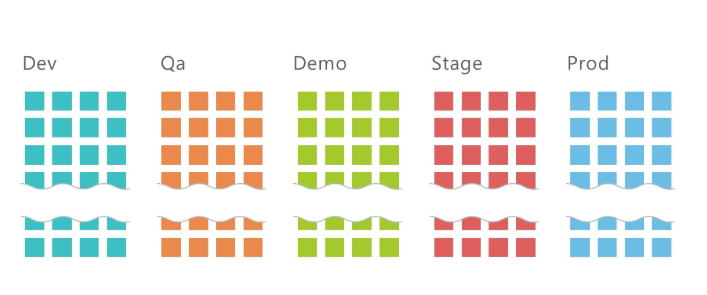
How to deploy 5 environments with 10 microservices in each?
On average, we have 10 services per project and three environments: QA, DEV, Stage, on which about 30 microservices are deployed. And it is only on the development infrastructure! Let's add 2 more environments on the customer's infrastructure, and we get 50 microservices.
It is clear that such a number of services must somehow be managed. Kubernetes helps us in this.
In order to deploy a microservice, you need to
• Expand the secret,
• Expand the deployement,
• Expand the service.
We'll write about secret below.
Deployment is the instruction for Kubernetes, on the basis of which it will launch the Docker container of our microservice. Here is the deployment deployment team:
kubectl apply -f .\(yaml конфигурация deployment-а) --namespace=DEVapiVersion: apps/v1beta1
kind: Deployment
metadata:
name: imtob-etr-it-dictionary-api
spec:
replicas: 1
template:
metadata:
labels:
name: imtob-etr-it-dictionary-api
spec:
containers:
- name: imtob-etr-it-dictionary-api
image: nexus3.company.ru:18085/etr-it-dictionary-api:18289
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
volumeMounts:
- name: secrets
mountPath: /app/secrets
readOnly: true
volumes:
- name: secrets
secret:
secretName: secret-appsettings-dictionary
This file describes what is called deployment (imtob-etr-it-dictionary-api), which image it needs to use for execution, plus other settings. In the secret section we will customize our environment.
After deployment, we need to deploy a service, if necessary.
Services are needed when access to microservice is required from outside. For example, when it is necessary for a user or another microservice to be able to make a Get request to another microservice.
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEVapiVersion: v1
kind: Service
metadata:
name: imtob-etr-it-dictionary-api-services
spec:
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
selector:
name: imtob-etr-it-dictionary-apiUsually the description of the service is small. In it we see the name of the service, how it can be accessed and the port number.
As a result, for the deployment of the environment, we need
• a set of files with secret for all microservices,
• a set of files with deployment of all microservices,
• a set of files with service all of microservices.
All these scripts are stored in the git repository.
To deploy the solution, we have a set of three types of scripts:
• folder with secrets - these are the configurations for each environment,
• folder with deployment s for all microservices,
• folder with service s for some microservices,
in each - about ten teams, one for each microservice. For convenience, we brought a page with scripts in Confluence, which helps us quickly deploy a new environment.
Here is the deployment deployment script (there are similar sets for the secret and for service):
Deployment script deployment
kubectl apply -f .\imtob-etr-it-image-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-mobile-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-planning-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-result-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-web.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-report-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-template-constructor-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-integration-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-identity-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-mobile-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-planning-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-result-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-web.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-report-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-template-constructor-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-integration-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-identity-api.yml --namespace=DEV
CI / CD implementation
Each service is in its own folder, plus we have one folder with shared components.
Also for each microservice there is Build Definition and Release Definition. We set up the launch of Build Definion when committing to the appropriate service or commiting to the appropriate folder. If the contents of the folder with shared components are updated, then all microservices are deployed.
What advantages from such an organization Build-we see:
1. The solution is in one git-repository,
2. If you change in several microservices, the assembly runs in parallel if there are free assembly agents,
3. Each Build Definition represents a simple script from the image assembly and its push in the Nexus Registry.
Build definition and Release Definition
How to deploy a VSTS agent, we previously described in this article .
First comes Build Definition. At the command of TFS, the VSTS agent launches the Dockerfile build. As a result, we get the image of microservice. This image is saved locally on the environment where the VSTS agent is running.
After the build, Push is launched, which sends the image we received in the previous step to the Nexus Registry. Now it can be used from the outside. Nexus Registry is a kind of Nuget, not only for libraries, but for Docker images and not only.
After the image is ready and accessible from the outside, it needs to be deployed. For this we have Release Definition. Everything is simple here - we execute the set image command:
kubectl set image deployment/imtob-etr-it-dictionary-api imtob-etr-it-dictionary-api=nexus3.company.ru:18085/etr-it-dictionary-api:$(Build.BuildId)After that, it will update the image for the desired microservice and launch a new container. As a result, our service has been updated.
Let's now compare the build with and without Dockerfile.
Without Dockerfile, we have many steps, in which there is a lot of specificity of .Net. On the right, we see a Docker image build. Everything has become much easier.
The entire image building process is described in the Dockerfile. This assembly can be debugged locally.
Total: we got a simple and transparent CI / CD
1. Separation of development and deployment. The assembly is described in the Dockerfile and lies on the shoulders of the developer.
2. When configuring CI / CD, you do not need to know about the details and features of the assembly - work is carried out only with Dockerfile.
3. We update only changed microservices.
Further it is required to nastrit RabbitMQ in K8S: about it we wrote separate article .
Setting up the environment
Anyway, we need to configure microservices. The main part of the environment is configured in the root configuration file Appsettings.json. This file stores settings that are independent of the environment.
Those settings that depend on the environment, we store in the secrets folder in the appsettings.secret.json file. We took the approach described in the article Managing ASP.NET Core App Settings on Kubernetes .
var configuration = new ConfigurationBuilder()
.AddJsonFile($"appsettings.json", true)
.AddJsonFile("secrets/appsettings.secrets.json", optional: true)
.Build();The appsettings.secrets.json file stores settings for Elastic Search indexes and a database connection string.
{
"Serilog": {
"WriteTo": [
{
"Name": "Elasticsearch",
"Args": {
"nodeUris": "http://192.168.150.114:9200",
"indexFormat": "dev.etr.it.ifield.api.dictionary-{0:yyyy.MM.dd}",
"templateName": "dev.etr.it.ifield.api.dictionary",
"typeName": "dev.etr.it.ifield.api.dictionary.event"
}
}
]
},
"ConnectionStrings": {
"DictionaryDbContext": "Server=192.168.154.162;Database=DEV.ETR.IT.iField.Dictionary;User Id=it_user;Password=PASSWORD;"
}
}
Add a configuration file to Kubernetes
In order to add this file, you need to deploy it in the Docker-container. This is done in the deployment file of a cubnet. In deployment, it describes in which folder you need to create a file with secret and with which secret you need to associate the file.
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: imtob-etr-it-dictionary-api
spec:
replicas: 1
template:
metadata:
labels:
name: imtob-etr-it-dictionary-api
spec:
containers:
- name: imtob-etr-it-dictionary-api
image: nexus3.company.ru:18085/etr-it-dictionary-api:18289
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
volumeMounts:
- name: secrets
mountPath: /app/secrets
readOnly: true
volumes:
- name: secrets
secret:
secretName: secret-appsettings-dictionary
Create a secret in Kubernetes using the utility kubectl. We see here the name of the secret and the path to the file. We also indicate the name of the environment for which we are creating a secret.
kubectl create secret generic secret-appsettings-dictionary
--from-file=./Dictionary/appsettings.secrets.json --namespace=DEMOfindings
Cons of the chosen approach
1. High entry threshold. If you are doing a similar project for the first time, there will be a lot of new information.
2. Microservices → more complex design. It is necessary to apply a lot of non-obvious solutions due to the fact that we have not a monolithic solution, but a microservice one.
3. Not everything is implemented for Docker. Not everything can be run in microservice architecture. For example, while SSRS is not in docker.
Pros of the approach, proven on yourself
1. Infrastructure as a code
Description of the infrastructure is stored in the source control. At the time of deployment does not need to adapt the environment.
2. Scaling both at the functional level and at the level of performance out of the box.
3. Microservices are well isolated.
Virtually no critical parts, the failure of which leads to the inoperability of the system as a whole.
4. Fast delivery of changes.
Only microservices in which there were changes are updated. If we do not take into account the time for coordination and other things related to the human factor, then we update one microservice in 2 minutes or less.
Conclusions for us
1. On .NET Core it is possible and necessary to implement industrial solutions.
2. K8S really made life easier, simplified updating of environments, and facilitated the configuration of services.
3. TFS can be used to implement CI / CD for Linux.