Why stop counting neural networks as a black box?
If you have been fond of neural network technologies for quite a long time, then you probably met with an opinion briefly concluded in the rhetorical question: “How can you explain to a person when the neural network thinks that it has cancer?”. And if, at best, such thoughts make you doubt the use of neural networks in sufficiently responsible spheres, at worst, you can lose all your interest.
I got the best option - I calmly accepted such limitations and, without thinking twice, I continued to use neural network technologies in the field of computer vision.
Task
Recently, I had the task to create an efficient detector of emotions as quickly as possible. The conditions were set quite clearly - front facing face with a resolution of 100x100. In search of a ready dataset, I spent a couple of hours and realized that practically nothing suits me. Or even for “research purposes” it was too difficult to access the dataset. The solution was found quickly - take a dozen feature films and simply unload all faces by simply running a Haar cascade through them. Overnight more (!) 30k images were received. Next, the resulting images were sorted into 5 main emotions (happy, sad, neutral, angry, surprised). Of course, not all the images came up and as a result, 400-500 face images fell on each category.
This is where everything is tied up with the topic of explaining the results of the work of neural networks. Even with a sufficiently high-quality custom data augmentation, such a data set seemed to be clearly insufficient. When learning the network based on Resnet blocks, the following numbers for metrics were obtained:
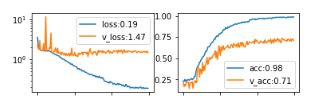
Retraining on the background against an insufficient number of examples, but due to lack of time, it was necessary to make sure that the network works at least somewhat satisfactorily and does not rely on determining emotions, for example on the background.
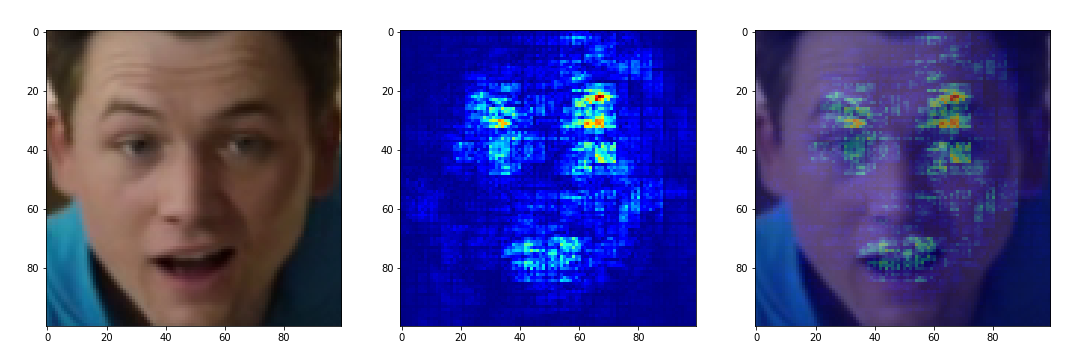
Previously, I had to work with tools such as Lime and Keras-Vis, but it was here that they could become a philosophical stone, turning the black box into something more transparent. The essence of both tools is about the same - to identify the areas of the original image that carry the greatest contribution to the final network solution. For the test, I shot a video that imitated various emotions. Having unloaded facial expressions corresponding to different emotions, I drove the above described tools through them. The
following results from Lime were obtained:

Unfortunately, even changing various parameters of functions, it was not possible to obtain a sufficiently comprehensible display from Lime. For some reason, the right half of the face affects the belonging to the “angry” class. The only thing for “happy” is the logical area of the mouth and the dimples typical for a smile.
Further, all the same images were driven through Keras-Vis and bingo:
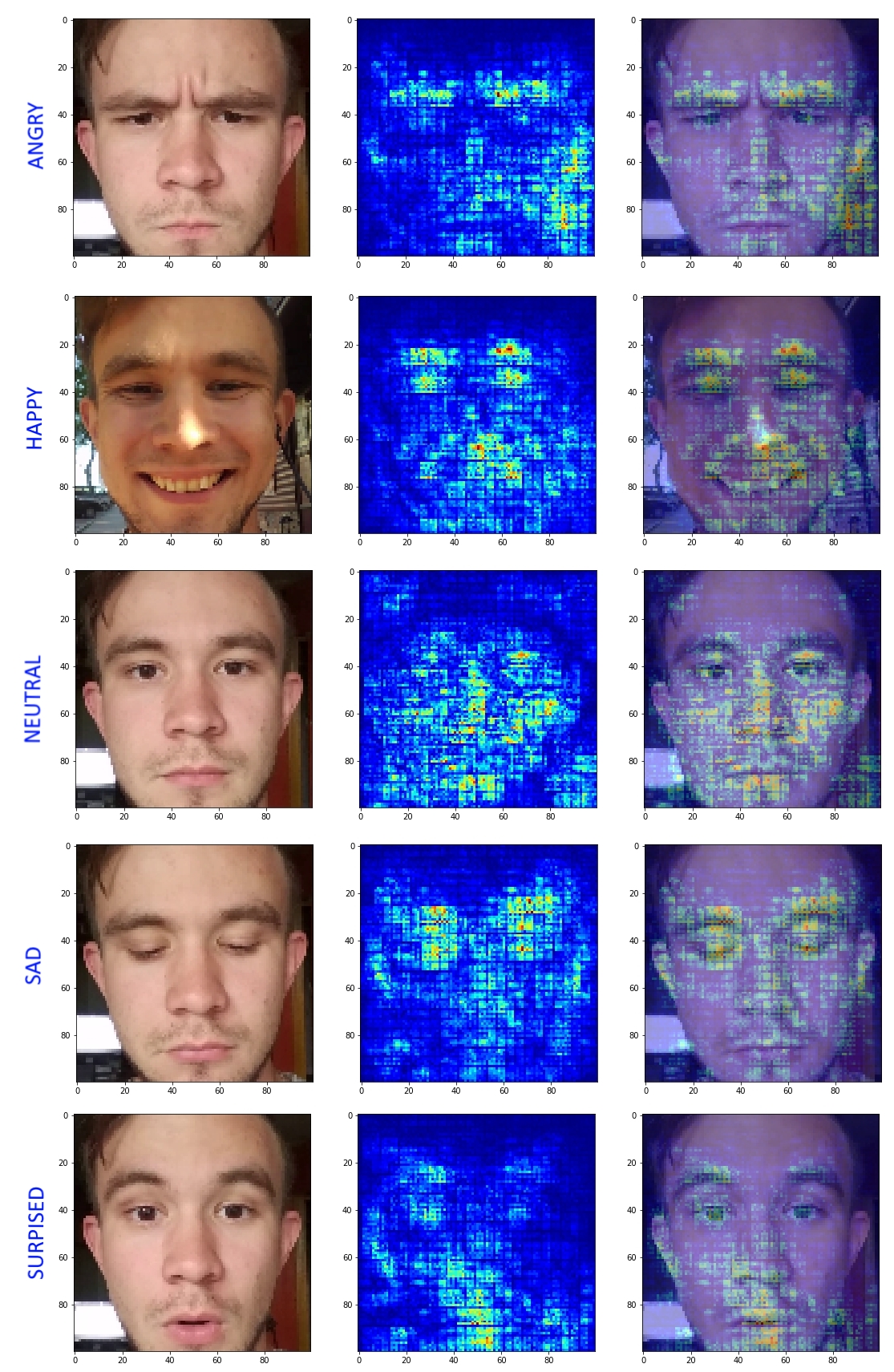
“Happy” is looking for the location of the eyes and the shape of the mouth. Sad focuses on lowered eyebrows and eyelids. Neutral tries to look at the entire face as a whole and the innocent lower corners of the image. “Angry” logically focuses on shifted eyebrows, but forgets about the shape of the mouth and for some reason is looking for features in the lower right corner. And “Surprised” looks at the shape of the mouth and the left (!) Raised eyelid - it’s time to start recognizing the right one.
The results pleased and made it possible to see the strengths and weaknesses of the resulting network. Feeling weak in the classification of the classes “Surprised” and “Angry”, I found the strength to slightly increase the sample and added a drop more dropout. At the next iteration, the following results were obtained:

It is seen that the areas of activations are more localized. Disappeared network attention to the background in the case of "Angry". Of course, the network still has its drawbacks, forgetting about the eyebrow on the one hand and so on. But this approach allowed us to understand more deeply what the obtained model does and why. This approach is ideal in cases where we have doubts about the correct convergence of the network.
findings
Neural networks remain just a solution to a complex optimization problem. But even the simplest attention cards of the network bring a share of transparency to these wilds. This approach can be used along with the usual orientation on the loss function, which will make it possible to obtain even more conscious networks.
If we recall the rhetorical question from the beginning of the article, then we can say that the use of attention cards, together with the final response of the network, already carries with it a certain intelligible explanation, which was so lacking.
Visualize, visualize and visualize again!