Failover for Hyper-V VM and MSSQL
Instead of a foreword
Fault tolerance is understood - within the framework of one data center - that is, protection from failure of 1-2 physical servers.
Our implementation will be inexpensive in terms of hardware, namely what one famous German hoster rents out.
In terms of software cost, it is either free or already available. Microsoft affiliate program, so to speak, in action.
With the advent of the Windows Server 2012 market, there was a lot of advertising “From the server to the cloud,” “Your applications always work.” That is what we will try to implement.
Of course, there is a topic for holivars: what is better than VMWare or Hyper-V - but this is not the topic of this post. I will not argue. On taste and color - all felt-tip pens are different.
Probably, some will say that this business can be sent to Azure - it may turn out that it is even cheaper, but we are paranoid and we want
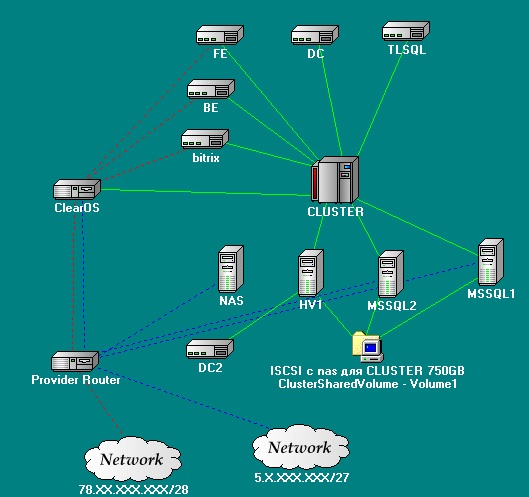
Solution Requirements
There is a certain project that uses:
- Database - MSSQL
- backend - IIS
- frontend - some kind of application in PHP
It is necessary to implement:
- This bunch worked "always."
- The failure of the "iron" server did not cause downtime.
- No data was lost.
- There was some kind of load balancing.
- Scalability.
- To implement the above, it was not necessary to fence the garden with software (for example, Identity for MSSQL).
All this economy will be hosted on one well-known German hosting.
Implementation
Divide the implementation into logical parts:
- Hardware Requirements.
- Preparatory Activities
- Fault tolerance MSSQL (with balancing elements).
- Fault tolerance backend and frontend
- Network configuration
- Fault tolerance: another milestone.
Hardware requirements
For this, we need at least 4 servers. It is highly desirable that they are in the same data center, and preferably in one switch. In our case, we will have a separate rack. And since there is only one rack, as they explained to us, her switch is also dedicated.
Server
2 servers - a processor with virtualization support, 32GB of RAM, 2HDD X 3TB (RAID 1) the
remaining 2 will go under SQL, so we will use a small change in them (in the configuration we replace one hard drive with a RAID controller and 3 SAS drives of 300 GB each (they will go to RAID 5 - fast storage for MSSQL)).
In principle, this is not necessary. Fault tolerance, of course, decreases, but speed is more important.
You will also need a flash drive (but more on that below.)
Optional: a separate switch for organizing a local network, but this can be done later as the project grows.
Preparatory Activities
Since we are raising the Failover Cluster, we will need an Active Directory domain.
He will then simplify the task of authorizing our backend on the SQL server.
Raise the domain controller in the virtual machine.
It is also necessary to determine the addressing of the local network.
Our DC (Domain Controller), of course, will not have a white ip address and will go "out" through NAT.
In the settings of all virtual machines and not so Primary DNS: our domain controller.
Second ip addresses, in addition to the white ones issued, it is necessary to register the addresses of our local network.
The ideal option is described in terms of scalability below.
Fault tolerance MSSQL.
We will use MSSQL clustering, but not in the classical sense, that is, we will not cluster the entire service, but only the Listener. Clustering all MSSQL requires a common repository, which will be the point of failure. We are following the path of minimizing points of failure. To do this, we will take advantage of the new feature of MSSQL Server 2012 - Always On.
Ode to this feature is well described by SQL Server 2012 - Always On by Andrew Fryer . It also describes in detail how to configure.
In short, the combination of the two technologies of replication and Mirroring. Both database instances contain identical information, but each uses its own repository.
It is also possible to use load balancing using read-only replicas. Having preconfigured reading routes, read more - Read-Only Routing with SQL Server 2012 Always On Database Availability Groups
Generally Best Practice on this issue is covered in detail in the Microsoft SQL Server AlwaysOn Solutions Guide for High Availability and Disaster Recovery by LeRoy Tuttle
I will focus only on that that the path configuration in the MSSQL settings must be identical.
Fault tolerance backend and frontend.
We will implement this functionality by clustering virtual machines.
To cluster virtual machines, we need Cluster Shared Volume (CSV).
And in order to create a CSV, we need a SAN, and it must be validated by a cluster and be free. It turns out that this is not an easy task. A dozen solutions were tried (Open Source and not). As a result, the desired product was discovered. It is called NexentaStor
18 TB raw space for free, a bunch of protocols and chips.
The only thing that, when deploying, it is necessary to take into account the experience and recommendations of ULP. The operating experience of Nexenta, or 2 months later.
We, unfortunately, went through this rake on our own.
Nexenta also periodically has a “disease” - the Web interface stops responding, while all other services function normally. The solution is available at http://www.nexentastor.org/boards/2/topics/2598#message-2979
So. More about installation.
We are trying to install Nexenta, the installation is successful. We go into the system and are surprised - all the free space was spent under the system pool and we have nowhere to place the data. It would seem that the solution is obvious - we re-order the hard drives to the server and create a pool for storing data, but there is another solution. To do this, we will use a flash drive.
We put the system on a flash drive (this process takes about 3 hours).
After installation, we create a system pool and a pool for data. We attach a flash drive to the system pool and synchronize it. After that, the flash drive from the pool can be removed. Described in detail at http://www.nexentastor.org/boards/1/topics/356#message-391 .
And we get such a picture.
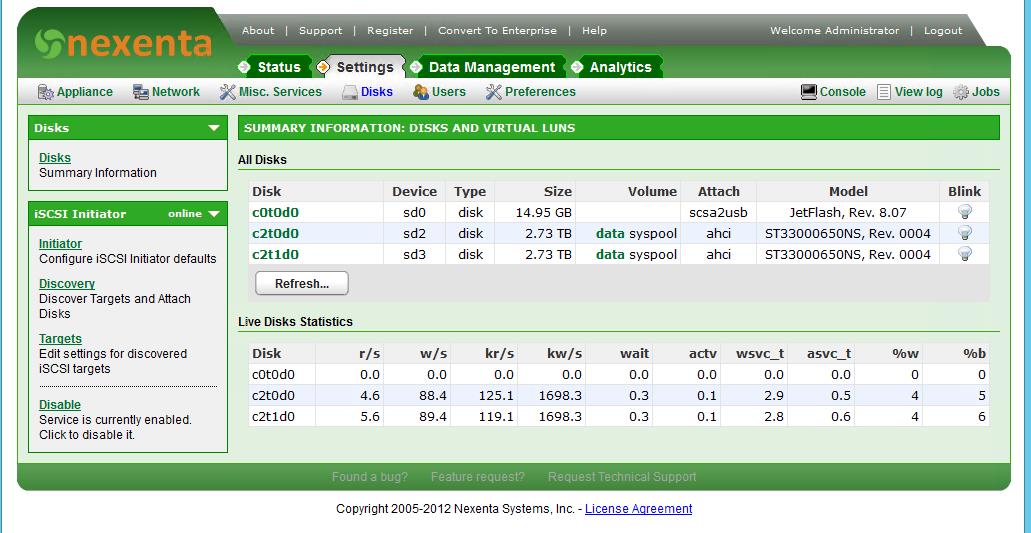
Create zvol. After creating it, bind it to target and publish via ISCSI.
We connect it to each node of our cluster. And add it to the Cluster Shared Volume.
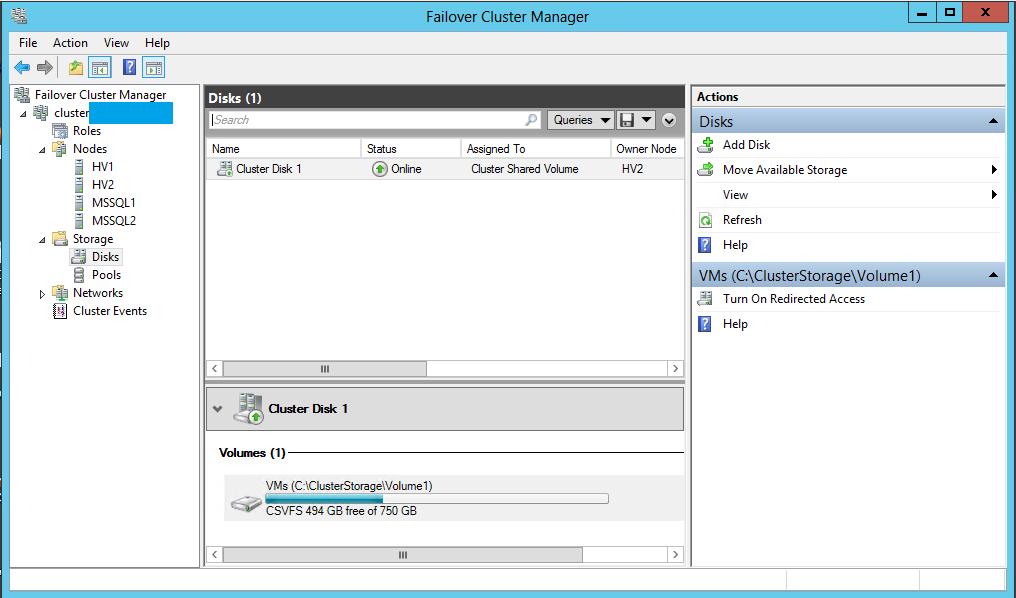
Accordingly, in the Hyper-V settings on each node of the cluster, we indicate the location of the virtual machine configurations and hard disk files on it.
It is also not unimportant - the names of virtual switches on each node must also be the same.
After that, you can create virtual machines and configure a faylover for them.
The choice of OS, of course, is limited to MS Windows and Linux, for which there are integration services , but it so happened that we use them.
Also, do not forget to add our domain controller to the Hyper-V cluster.
Network configuration
We already have fault tolerant SQL, we have fault tolerant frontend and backend.
It remains to be made so that they are accessible from the outside world.
Our hosting provider has 2 services for implementing this functionality:
- It is possible to request an additional IP address for our server and bind it to the MAC address.
- It is also possible to request a whole subnet / 29 or / 28 and ask to route it to an address of 1 point.
We create one more virtual machine in our Hyper-v cluster. For this purpose we will use ClearOS . The choice fell on her, right away, because it is built on the basis of CentOS and therefore integration services can be installed on it.
Do not forget to install them after installation, otherwise there may be problems with the disappearance of network interfaces.
She will have 3 interfaces:
- The local network
- Dmz
- External network
The external network is that additional address that we asked the
DMZ provider - the subnet that the provider gave us.
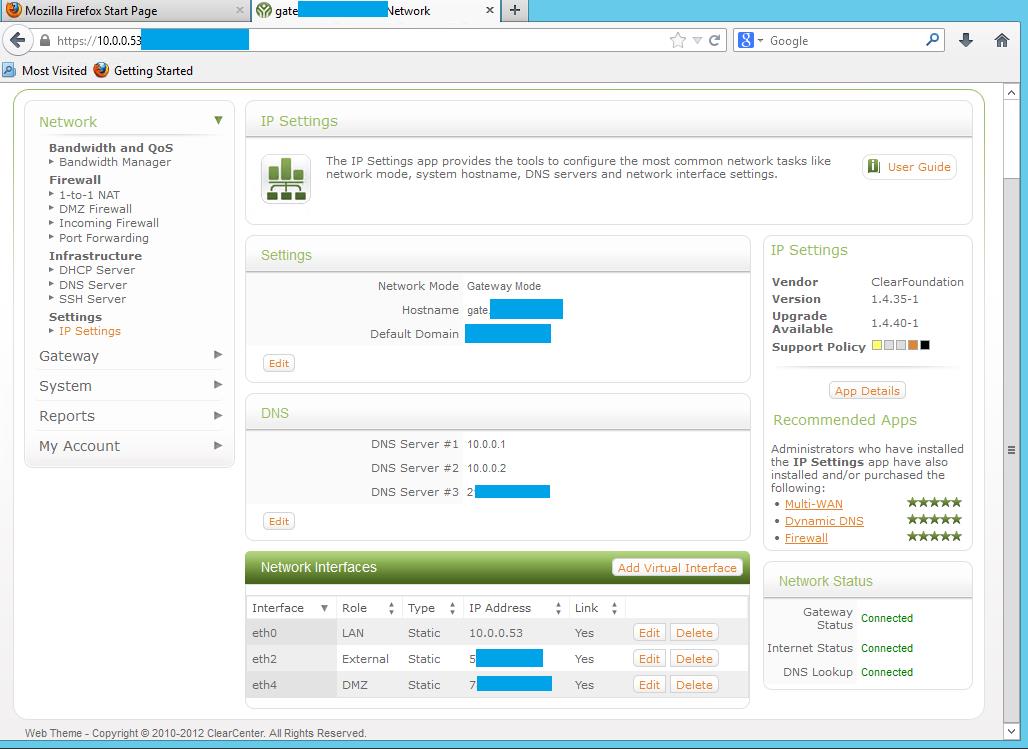
Also, this machine will release our virtual machines (not having a white ip address) out through NAT.
Thus, we made our routing failover as well. The router is clustered and can also move from node to node.
On the nodes themselves, we don’t forget to configure the firewall (we block access from all ip except for trusted and local ones on dangerous ports). Better to turn off white ip addresses.
Of course, if there is no need for more than one white address, then it makes no sense to highlight the whole subnet, and access from the outside can be realized through Port Forwarding and Reverse Proxy.
Fault tolerance: another milestone
As mentioned earlier, we are on the path to reducing points of failure. But we still have one point of failure - this is our SAN. Since all clustered virtual machines are on it, including our domain controller, the disappearance of this resource will not only lead to the disappearance of the backend and frontend, but also lead to the collapse of the cluster.
We have one more server left. We will use it as the last frontier.
We will create a virtual machine on our backup server with a second domain controller and configure AD replication on it.
Do not forget the secondary DNS server on all our machines to register it. In this case, when CSV disappears, those services that are not dependent on CSV, namely our clustered SQL-listener, will continue to function.
In order that the backend and frontend, after the fall of CSV, could return to operation, we will use the new Windows Server 2012 feature - Hyper-V replication. We will replicate critical machines for the project to our 4 server. The minimum replication period is 5 minutes, but this is not so important, because frontend and backend contain static data that is rarely updated.
In order to accomplish this, it is necessary to add the Hyper-V Replica Broker cluster role. And in its properties to configure replication properties. Replication Details:
Hyper-V
Windows Server 2012 Hyper-V Replica Overview . Hyper-V Replica
And, of course, do not forget about backup.
A bit about scalability
This solution can be scaled up in the future by adding node servers.
The MSSQL server is scaled by adding read-only nodes and balancing read routes.
Virtual machines can be "inflated" to the size of the resource node, without being tied to the hardware.
In order to optimize traffic, you can add additional interfaces to the node servers and connect Hyper-V virtual switches to these interfaces. This will allow you to separate external traffic from internal.
You can replicate virtual machines in Azure.
You can add SCVMM and Orchestrator and get a “private cloud."
Something like this you can build your own cluster that will be fault tolerant, to a certain extent. As in principle, all fault tolerance.
PSThree months - the flight is normal. The number of cluster nodes and virtual machines is growing. The screenshot shows that the system is already somewhat larger than described.
The post, probably, does not reveal all the details of the setting, and there was no such task. I think all the details will be tedious to read. If suddenly, who will be interested in the details - you are welcome. Criticism is welcome.