Porting JS to Elbrus
This is a story about porting JavaScript to the domestic platform Elbrus, made by guys from the UniPro company. The article provides a brief comparative analysis of platforms, process details and pitfalls.

The article is based on a report by Dmitry ( dbezheckov ) Bezhetskova and Vladimir ( volodyabo ) Anufrienko with HolyJS 2018 Piter. Under the cut you will find the video and text transcript of the report.
First, let's deal with the fact that Elbrus. Here are a few key features of this platform compared to x86.
A completely different architectural solution than superscalar architecture, which is more common in the market now. VLIW allows you to more subtly express intentions in the code due to the explicit control of all independent arithmetic logic units (ALU), which Elbrus has, by the way, 4. This does not exclude the possibility of some ALU being idle, but still increases the theoretical performance by one clock cycle processor.
Ready processor teams are combined in bundles (Bundles). One bundle is one big instruction that runs in a conditional cycle. There are many atomic instructions in it that are executed independently and immediately in the architecture of Elbrus.

In the image on the right, gray rectangles indicate bundles that were obtained by processing the JS code on the left. If everything is approximately clear with the instructions ldd, fmuld, faddd, fsqrts, then the return instruction at the very beginning of the first bundle is surprising to people who are not familiar with the Elbrus assembler. This instruction loads the return address from the current floatMath function into the ctpr3 register in advance so that the processor can manage to load the necessary instructions. Then in the last bundle we are already making the transition to the pre-loaded address in ctpr3.
It is also worth noting that Elbrus has much more registers 192 + 32 + 32 against 16 + 16 +8 for x86.
Elbrus maintains clear speculation at the command level. Therefore, we can call and load a.bar from memory even before checking that it is not null, as can be seen in the code on the right. If the reading logically at the end proves invalid, then the value in b will simply be marked with hardware as incorrect and will not be accessed.

Elbrus also supports conditional execution. Consider this in the following example.

As we can see, the code from the previous example about speculativeness is also reduced by using the convolution of the conditional expression into dependence not by control, but by data. Elbrus hardware supports predicate registers in which only two values of true or false can be stored. Their main feature is that you can label instructions with such a predicate and depending on its value at the time of execution, the instruction will be executed or not. In this example, the cmpeq instruction performs a comparison and places its logical result in predicate P1, which is then used as a marker to load the value from b into the result. Accordingly, if the predicate was true, then the result is left with the value 0.
This approach allows you to transform a rather complex graph of program management into a predicate execution and, accordingly, increases the fullness of the bundle. Now we can generate more independent commands under different predicates and fill them with bundles. Elbrus supports 32 predicate registers, which allows coding 65 control flows (plus one for the absence of a predicate on a command).
Two of them are protected from modification by the programmer. One — the chain stack — is responsible for storing addresses for returns from functions, the other — the stack of registers — contains the parameters through which they are passed. The third, the user stack, stores variables and user data. In intel, everything is stored in one stack, which causes vulnerabilities, since all the addresses of transitions, parameters are in one place that is not protected from modifications by the user.
Instead, an if-conversion scheme and transition preparations are used to prevent the execution pipeline from stopping.
It was based on the previous implementation of v8 from Google. It works like this: an abstract syntax tree is created from the source code, then, depending on whether the code was executed or not, an optimized or non-optimized binary code is created using one of two compilers (Crankshaft or FullCodegen). There is no interpreter.

The nodes of the syntactic tree are translated into binary code, after which everything is “glued together”. One node represents about 300 lines of code on a macro assembler. This, firstly, gives a wide horizon of optimizations, and, secondly, there are no bytecode transitions, as in the interpreter. This is simple, but at the same time there is a problem - during porting you will have to rewrite a lot of code on a macro assembler.
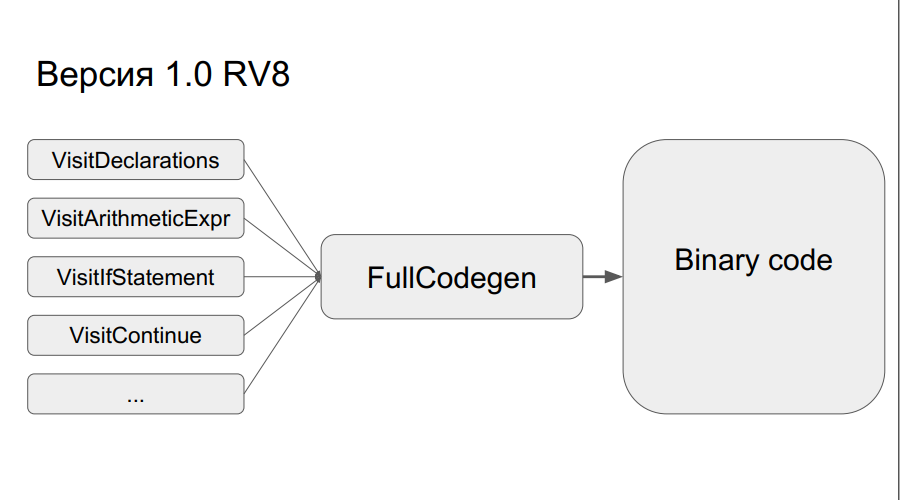
Nevertheless, all this was done, and the compiler version was FullCodegen 1.0 for Elbrus. Everything was done through C ++ runtime v8, nothing was optimized, the assembly code was simply rewritten from x86 to the Elbrus architecture.
As a result, the result was not exactly as expected, and it was decided to release version FullCodegen 1.1:

Note that checking for NaN, undefined, null is done at a time, without using if, which would be required in the Intel architecture.
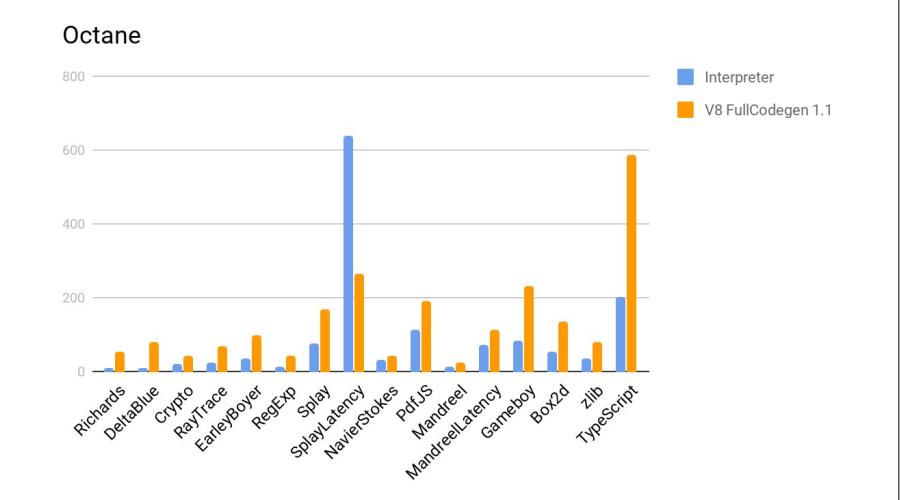
Tests were conducted in Google Octane. Test machines:
Next results:

On the histogram - the ratio of results, i.e. how many times Elbrus is worse than Intel. In the two tests of Crypto and zlib, the results are noticeably worse due to the fact that Elbrus does not yet have hardware instructions for working with encryption. In general, given the difference in frequencies, it turned out well.
Further, the test is compared to the js interpreter from firefox, included in the standard delivery of Elbrus. More is better.
Verdict - the compiler coped well again.
Everything would be fine, but then Google announced that it no longer supports FullCodegen and Crankshaft and they will be deleted. After that, the team received an order for development for the Firefox browser, and more on that later.

It's about the browser engine Firefox - SpiderMonkey. The figure shows the differences between this engine and the newer V8.
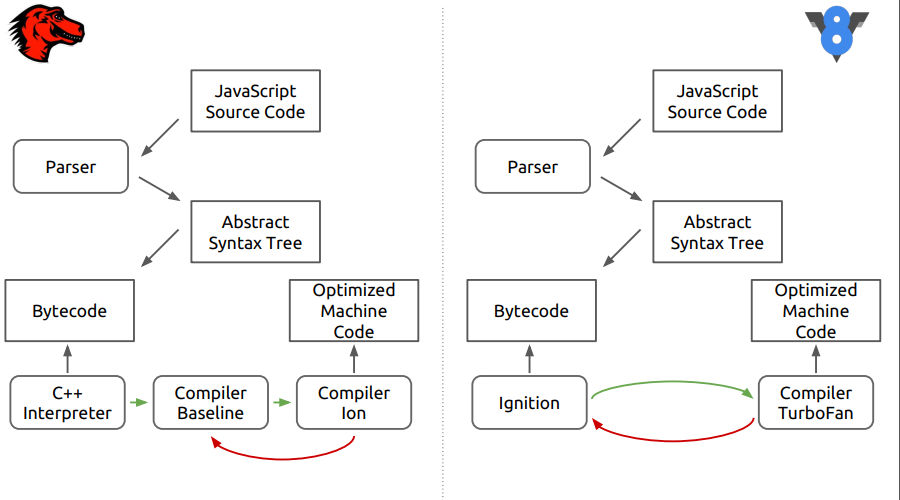
It can be seen that at the first stage everything looks like, the source code is parsed into an abstract syntax tree, then into a byte code, and then the differences begin.
In SpiderMonkey, the bytecode is interpreted by the C ++ interpreter, which essentially resembles a large switch, inside which bytecode jumps are performed. Further, the interpreted code falls into the Baseline non-optimizing compiler. Then, at the final stage, the optimizing compiler Ion is included. In the V8 engine, the bytecode is processed by the Ingnition interpreter, and then by the TurboFan compiler.
Porting started with the Baseline compiler. It is essentially a stack machine. That is, there is a certain stack from which cells it takes variables, remembers them, performs some actions with them, and then returns both variables and the results of actions back to the stack cells. Below in several pictures this mechanism is shown step by step with respect to the simple function foo:
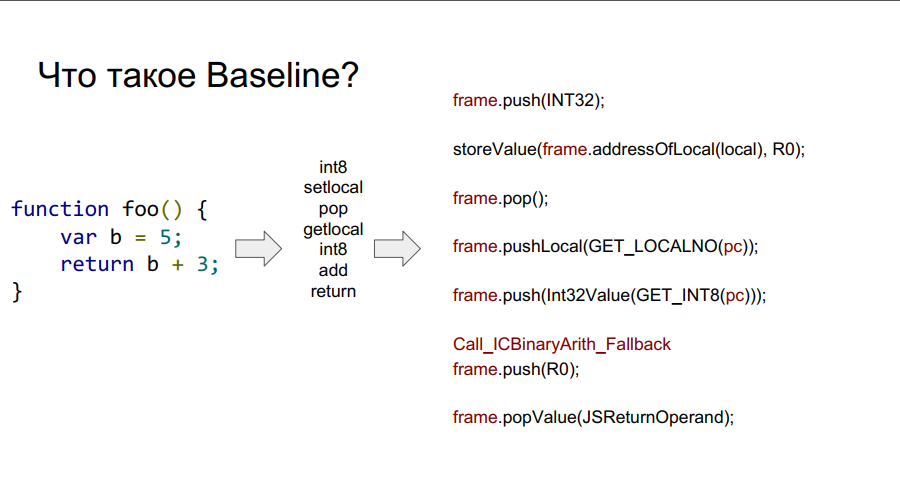


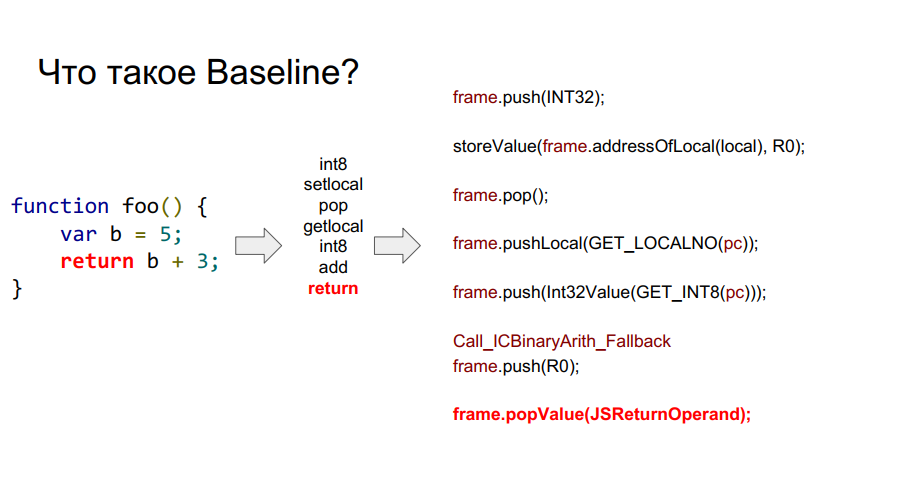
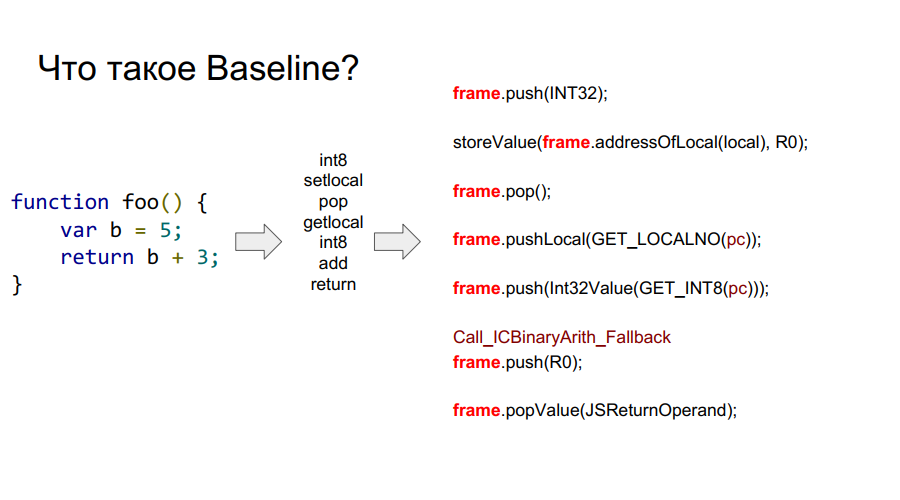
In the images above, you can see the word frame. Roughly speaking, this is a Javascript context on the hardware, that is, a dataset on the stack that describes any of your functions. The image below shows the foo function, and to the right of it is what it looks like on the stack: arguments, function description, return address, indication of the previous frame, because the function was called from somewhere and in order to return to the call point correctly, this information should be stored in the stack, and then the local variables themselves and the operands for the calculations.

Thus, the advantages of Baseline :
But there are also disadvantages :
It only remained to implement a macro assembler and get a ready-made compiler. Debugging also did not foretell any particular problems, it was enough to look at the stack on the x86 architecture, and then on the one that was obtained when porting to find the problem.
As a result, according to tests with a new compiler, performance has increased threefold:

However, Octane does not support work with exceptions. And their implementation is very important.
First, let's look at how x86 exceptions work. While the program is running, return addresses from functions are written to the stack. At some point an exception occurs. Go to the runtime exception handler, which uses the frames we talked about above. We find where exactly the exception occurred, after which we need to unwind the stack to the desired state, and then the return address changes to where the exception will be processed.
The problem is that due to a different stack device on the Elbrus architecture, this will not work. It will be necessary to calculate the system calls, how much you need to rewind back in the chain stack. Next, do a system call to get a call stack. Next in the address in the chain stack we make a replacement with the address that makes a return.
Below is an illustration about the order of these steps.

Not the fastest way, however, the exception is handled. Still, on Intel it looks somehow simpler:

With Elbrus, there will be more jumps up to the handler:

This is why you should not base the program logic on exceptions, especially on Elbrus.
So, exception handling is implemented. Now let's tell how we made it all a bit faster:
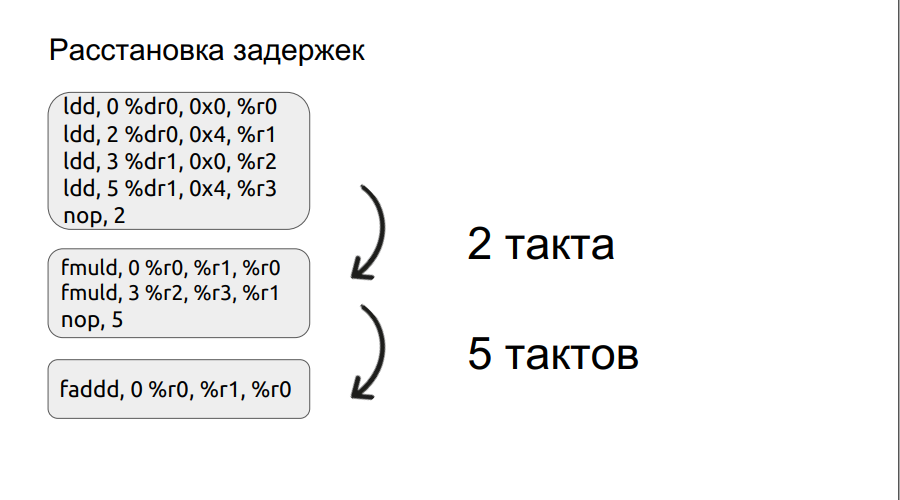
On the second paragraph, we’ll dwell a little more detail. We have already considered a small example of working with bundles, and we’ll go to it.

Any operation, for example, loading is not done in one cycle, in this case it is done in three cycles. Thus, if we want to multiply two numbers, we have come to the multiplication operation, but the operands themselves have not yet been loaded, the processor needs only to wait for them to load. And he will wait a certain number of bars, a multiple of four. But if you manually set the delay, the waiting time can be reduced, thereby increasing the speed. Further, the process of delay placement was automated.
Results optimization BaseLine v1.0 vs Baseline v1.1. Undoubtedly, the engine has become faster.

In the wake of the success of the implementation of Baseline v1.1, it was decided to port and optimizing the Ion compiler.

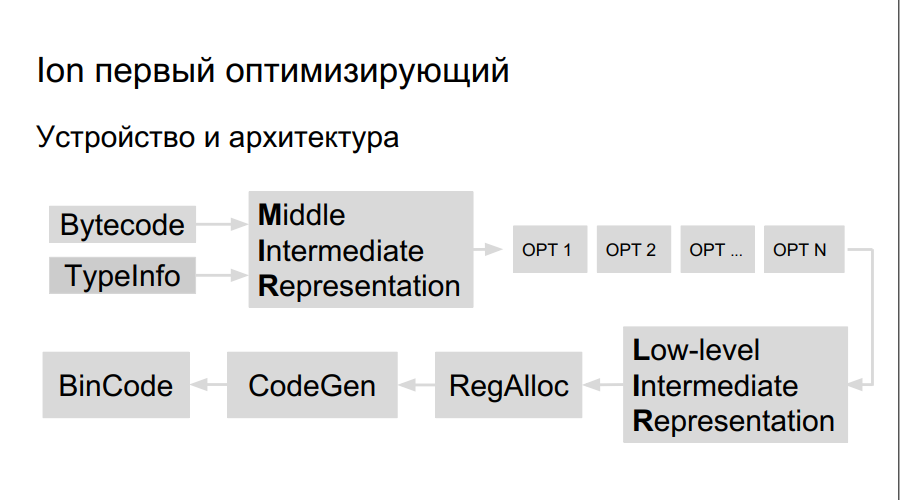
How does an optimizing compiler work? The source code is interpreted, compilation is started. In the process of executing bytecode, Ion collects data about the types used in the program, the analysis of "hot functions" - those that are performed more often than others. After that, the decision is made to compile them better, optimize. Next, a high-level compiler representation, an operation graph, is built. An optimization occurs on the graph (opt 1, opt 2, opt ...), a low-level representation is created consisting of machine commands, registers are reserved, a directly optimized binary code is generated.
There are more registers on Elbrus and the teams themselves are big, so we need:
The team already had experience in porting Java to Elbrus, they decided to use the same library for code generation for porting Ion. It is called TANGO. It has:
It remains to introduce a high-level view in TANGO, to make a selector. The problem is that the low-level representation in TANGO is similar to an assembler that is difficult to maintain and debug. What should the compiler look like inside? In Mozilla, for greater clarity, they made their own compiler, HolyJit, there is also another option to write your own mini-language for translation between high-level and low-level representation.
Development is still underway. Well, then how not to overdo it with optimization.
The process of optimization in Ion, when the code is heated, and then compiled and optimized - greedy, it can be seen in the following example.
When running in JS Shell with disconnected multithreading (for the purity of the experiment) that comes with Mozilla, we see the following situation:

The function is executed. We see that the counter of the number of performances is large, but at some point a message appears about bailout (bailout). This means that de-optimization has occurred. In this case, objects of type object are first passed to the foo function, but after the function is run in a loop with strings as arguments, the compiler decides to optimize the code as if this function works only with strings. If you decompile the optimized code, you get the following:
As soon as the first argument is not passed to the function, the optimized code will be thrown away and we will again switch to the non-optimized version of the code.
In the image we see an example of a low-level compiler operation. Commands that he optimized when creating a new version of the code, for example with DCE, are marked in gray.
During the ejection, we move to a less optimized code that expects all the objects it needs to be on the stack, as if the non-optimized version of the code had been running all this time.
To ensure that the data required for execution is not lost, there is a Resume Point in SpiderMonkey. Something like savepoints to which you can always return. They contain all the operands that are currently needed to restore the baseline frames. But they are not enough, so in runtime you need to get information where these operands are located. The lowering, regAlloc phase takes place, after which a snapshot is obtained, in which it is known where the desired operands are located. Based on this information, the baseline frame is restored.
The procedure is shown in the picture:

At x86 runtime, it looks like this: let's say, the test in the optimized code worked and you were ejected. The dump of registers and the necessary information from them is collected. It is called C, information about received frames is placed on the heap, another stub is called that copies the operands to the stack, and then a transition to bytecode, which corresponds to the save point, is made. Or, if you were in the middle of an inline cache, switch to a Type monitor. The scheme is shown below:
On Elbrus, this will not work, because one function corresponds to several frames, and the frames in Elbrus are controlled by iron and are stored in a protected chain stack. Therefore, you need to recreate not one frame, but several.
The scheme for Elbrus is more complicated: there is an intermediate deoptimization stub that recreates all this information on the chain stack, recursively calling itself N times, then a system call occurs that replaces return addresses with the corresponding baseline frame addresses, and then goes to the save point and resumes performance.
This is worth considering when developing, if you often see deoptimization in your code.
Revised scheme for the Elbrus architecture:

The result of the entire work of porting Ion was a 4-fold performance boost on some benchmarks compared to the previous baseline implementation. You can see the histogram below:
So, now you know that there is SpiderMonkey, V8 and Node on Elbrus. In general, porting is an easy process. It can be done by a small team.
But it is always important to remember the pitfalls. In the case of Elbrus, they were deoptimization, slow stubs, work with pipeline delays and a chain stack.
The article is based on a report by Dmitry ( dbezheckov ) Bezhetskova and Vladimir ( volodyabo ) Anufrienko with HolyJS 2018 Piter. Under the cut you will find the video and text transcript of the report.
Part 1. Elbrus, originally from Russia
First, let's deal with the fact that Elbrus. Here are a few key features of this platform compared to x86.
VLIW architecture
A completely different architectural solution than superscalar architecture, which is more common in the market now. VLIW allows you to more subtly express intentions in the code due to the explicit control of all independent arithmetic logic units (ALU), which Elbrus has, by the way, 4. This does not exclude the possibility of some ALU being idle, but still increases the theoretical performance by one clock cycle processor.
Team Bundling
Ready processor teams are combined in bundles (Bundles). One bundle is one big instruction that runs in a conditional cycle. There are many atomic instructions in it that are executed independently and immediately in the architecture of Elbrus.
In the image on the right, gray rectangles indicate bundles that were obtained by processing the JS code on the left. If everything is approximately clear with the instructions ldd, fmuld, faddd, fsqrts, then the return instruction at the very beginning of the first bundle is surprising to people who are not familiar with the Elbrus assembler. This instruction loads the return address from the current floatMath function into the ctpr3 register in advance so that the processor can manage to load the necessary instructions. Then in the last bundle we are already making the transition to the pre-loaded address in ctpr3.
It is also worth noting that Elbrus has much more registers 192 + 32 + 32 against 16 + 16 +8 for x86.
Explicit speculative versus implicit
Elbrus maintains clear speculation at the command level. Therefore, we can call and load a.bar from memory even before checking that it is not null, as can be seen in the code on the right. If the reading logically at the end proves invalid, then the value in b will simply be marked with hardware as incorrect and will not be accessed.
Conditional support
Elbrus also supports conditional execution. Consider this in the following example.
As we can see, the code from the previous example about speculativeness is also reduced by using the convolution of the conditional expression into dependence not by control, but by data. Elbrus hardware supports predicate registers in which only two values of true or false can be stored. Their main feature is that you can label instructions with such a predicate and depending on its value at the time of execution, the instruction will be executed or not. In this example, the cmpeq instruction performs a comparison and places its logical result in predicate P1, which is then used as a marker to load the value from b into the result. Accordingly, if the predicate was true, then the result is left with the value 0.
This approach allows you to transform a rather complex graph of program management into a predicate execution and, accordingly, increases the fullness of the bundle. Now we can generate more independent commands under different predicates and fill them with bundles. Elbrus supports 32 predicate registers, which allows coding 65 control flows (plus one for the absence of a predicate on a command).
Three hardware stacks compared with one at Intel
Two of them are protected from modification by the programmer. One — the chain stack — is responsible for storing addresses for returns from functions, the other — the stack of registers — contains the parameters through which they are passed. The third, the user stack, stores variables and user data. In intel, everything is stored in one stack, which causes vulnerabilities, since all the addresses of transitions, parameters are in one place that is not protected from modifications by the user.
No dynamic conversion predictor
Instead, an if-conversion scheme and transition preparations are used to prevent the execution pipeline from stopping.
So why do we need JS on Elbrus?
- Import Substitution
- Elbrus is brought to the home computer market, where Javascript is already required for the same browser.
- In the industry, Elbrus is already needed, for example, with Node.js. Therefore, you need to port Node under this architecture.
- The development of architecture Elbrus, as well as specialists in this field.
If there is no interpreter, two compilers come
It was based on the previous implementation of v8 from Google. It works like this: an abstract syntax tree is created from the source code, then, depending on whether the code was executed or not, an optimized or non-optimized binary code is created using one of two compilers (Crankshaft or FullCodegen). There is no interpreter.
How does FullCodegen work?
The nodes of the syntactic tree are translated into binary code, after which everything is “glued together”. One node represents about 300 lines of code on a macro assembler. This, firstly, gives a wide horizon of optimizations, and, secondly, there are no bytecode transitions, as in the interpreter. This is simple, but at the same time there is a problem - during porting you will have to rewrite a lot of code on a macro assembler.
Nevertheless, all this was done, and the compiler version was FullCodegen 1.0 for Elbrus. Everything was done through C ++ runtime v8, nothing was optimized, the assembly code was simply rewritten from x86 to the Elbrus architecture.
Codegen 1.1
As a result, the result was not exactly as expected, and it was decided to release version FullCodegen 1.1:
- They made a less runtime, wrote on a macro assembler;
- Added manual if-conversions (in the figure, as an example, the js variable is checked for true or false);
Note that checking for NaN, undefined, null is done at a time, without using if, which would be required in the Intel architecture.
- The code was not just rewritten from Intel, but implemented speculative stubs and implemented fast-path through MAsm (macro assembler) too.
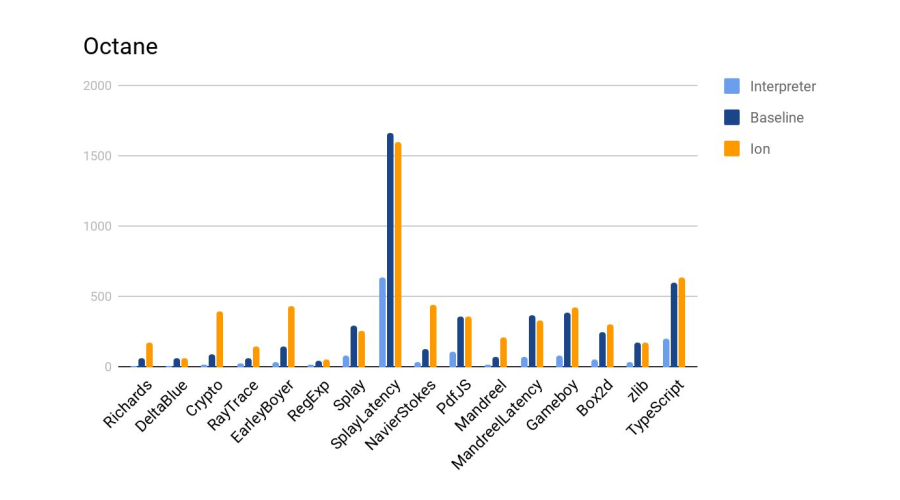
Tests were conducted in Google Octane. Test machines:
- Elbrus: E2S 750 MHz, 24 GB
- Intel: core i7 3.4 GHz, 16 GB
Next results:
On the histogram - the ratio of results, i.e. how many times Elbrus is worse than Intel. In the two tests of Crypto and zlib, the results are noticeably worse due to the fact that Elbrus does not yet have hardware instructions for working with encryption. In general, given the difference in frequencies, it turned out well.
Further, the test is compared to the js interpreter from firefox, included in the standard delivery of Elbrus. More is better.
Verdict - the compiler coped well again.
Development results
- New JS-engine passed test262 tests. This gives him the right to be called a full-fledged execution environment ECMAScript 262.
- Productivity has increased on average five times in comparison with the previous engine - an interpreter.
- Node.js 6.10 was also ported as an example of using V8, since it was not difficult.
- However, it is still worse than Core i7 on FullCodegen, seven times.
It seemed nothing foreshadowed
Everything would be fine, but then Google announced that it no longer supports FullCodegen and Crankshaft and they will be deleted. After that, the team received an order for development for the Firefox browser, and more on that later.
Part 2. Firefox and its spider monkey
It's about the browser engine Firefox - SpiderMonkey. The figure shows the differences between this engine and the newer V8.
It can be seen that at the first stage everything looks like, the source code is parsed into an abstract syntax tree, then into a byte code, and then the differences begin.
In SpiderMonkey, the bytecode is interpreted by the C ++ interpreter, which essentially resembles a large switch, inside which bytecode jumps are performed. Further, the interpreted code falls into the Baseline non-optimizing compiler. Then, at the final stage, the optimizing compiler Ion is included. In the V8 engine, the bytecode is processed by the Ingnition interpreter, and then by the TurboFan compiler.
Baseline, choose you!
Porting started with the Baseline compiler. It is essentially a stack machine. That is, there is a certain stack from which cells it takes variables, remembers them, performs some actions with them, and then returns both variables and the results of actions back to the stack cells. Below in several pictures this mechanism is shown step by step with respect to the simple function foo:
What is a frame?
In the images above, you can see the word frame. Roughly speaking, this is a Javascript context on the hardware, that is, a dataset on the stack that describes any of your functions. The image below shows the foo function, and to the right of it is what it looks like on the stack: arguments, function description, return address, indication of the previous frame, because the function was called from somewhere and in order to return to the call point correctly, this information should be stored in the stack, and then the local variables themselves and the operands for the calculations.
Thus, the advantages of Baseline :
- Similar to FullCodegen, therefore, his porting experience came in handy;
- Porting an assembler, we get a working compiler;
- Convenient to debug;
- Any stub can be rewritten.
But there are also disadvantages :
- Linear code, until you execute one byte code, you will not be able to execute the next one, which is not very good for a parallel computing architecture;
- Since it works with bytecode, you are not particularly optimizing.
It only remained to implement a macro assembler and get a ready-made compiler. Debugging also did not foretell any particular problems, it was enough to look at the stack on the x86 architecture, and then on the one that was obtained when porting to find the problem.
As a result, according to tests with a new compiler, performance has increased threefold:
However, Octane does not support work with exceptions. And their implementation is very important.
Exceptional work
First, let's look at how x86 exceptions work. While the program is running, return addresses from functions are written to the stack. At some point an exception occurs. Go to the runtime exception handler, which uses the frames we talked about above. We find where exactly the exception occurred, after which we need to unwind the stack to the desired state, and then the return address changes to where the exception will be processed.
The problem is that due to a different stack device on the Elbrus architecture, this will not work. It will be necessary to calculate the system calls, how much you need to rewind back in the chain stack. Next, do a system call to get a call stack. Next in the address in the chain stack we make a replacement with the address that makes a return.
Below is an illustration about the order of these steps.
Not the fastest way, however, the exception is handled. Still, on Intel it looks somehow simpler:
With Elbrus, there will be more jumps up to the handler:
This is why you should not base the program logic on exceptions, especially on Elbrus.
Optimize it!
So, exception handling is implemented. Now let's tell how we made it all a bit faster:
- Rewrote inline caches;
- Made a manual (and then automatic) alignment of delays;
- They made preparations for transitions (higher in code): the earlier the transition is prepared the better;
- Supported incremental garbage collector
On the second paragraph, we’ll dwell a little more detail. We have already considered a small example of working with bundles, and we’ll go to it.
Any operation, for example, loading is not done in one cycle, in this case it is done in three cycles. Thus, if we want to multiply two numbers, we have come to the multiplication operation, but the operands themselves have not yet been loaded, the processor needs only to wait for them to load. And he will wait a certain number of bars, a multiple of four. But if you manually set the delay, the waiting time can be reduced, thereby increasing the speed. Further, the process of delay placement was automated.
Results optimization BaseLine v1.0 vs Baseline v1.1. Undoubtedly, the engine has become faster.
How is it for programmers and not to make Ion's gun?
In the wake of the success of the implementation of Baseline v1.1, it was decided to port and optimizing the Ion compiler.
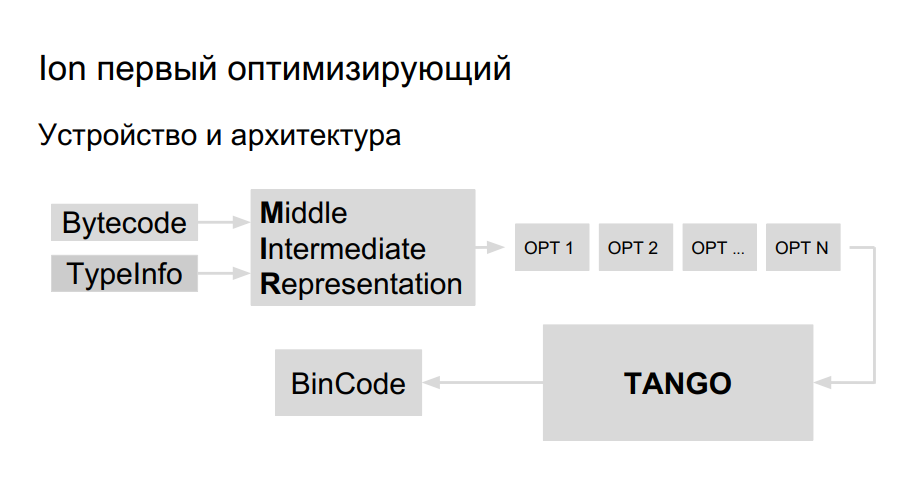
How does an optimizing compiler work? The source code is interpreted, compilation is started. In the process of executing bytecode, Ion collects data about the types used in the program, the analysis of "hot functions" - those that are performed more often than others. After that, the decision is made to compile them better, optimize. Next, a high-level compiler representation, an operation graph, is built. An optimization occurs on the graph (opt 1, opt 2, opt ...), a low-level representation is created consisting of machine commands, registers are reserved, a directly optimized binary code is generated.
There are more registers on Elbrus and the teams themselves are big, so we need:
- Team planner;
- Own register allocator;
- Own LIR (Low-level Intermediate Representation);
- Own Code-generator.
The team already had experience in porting Java to Elbrus, they decided to use the same library for code generation for porting Ion. It is called TANGO. It has:
- Team planner;
- Own register allocator;
- Low-level optimizations.
It remains to introduce a high-level view in TANGO, to make a selector. The problem is that the low-level representation in TANGO is similar to an assembler that is difficult to maintain and debug. What should the compiler look like inside? In Mozilla, for greater clarity, they made their own compiler, HolyJit, there is also another option to write your own mini-language for translation between high-level and low-level representation.
Development is still underway. Well, then how not to overdo it with optimization.
Part 3. The best is the enemy of the good.
Compilation as it is
The process of optimization in Ion, when the code is heated, and then compiled and optimized - greedy, it can be seen in the following example.
functionfoo(a, b) {
return a + b;
}
functiondoSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
When running in JS Shell with disconnected multithreading (for the purity of the experiment) that comes with Mozilla, we see the following situation:
The function is executed. We see that the counter of the number of performances is large, but at some point a message appears about bailout (bailout). This means that de-optimization has occurred. In this case, objects of type object are first passed to the foo function, but after the function is run in a loop with strings as arguments, the compiler decides to optimize the code as if this function works only with strings. If you decompile the optimized code, you get the following:
functiondoSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceofString))
// bailout
print(foo_only_str(obj, obj));
}
}
As soon as the first argument is not passed to the function, the optimized code will be thrown away and we will again switch to the non-optimized version of the code.
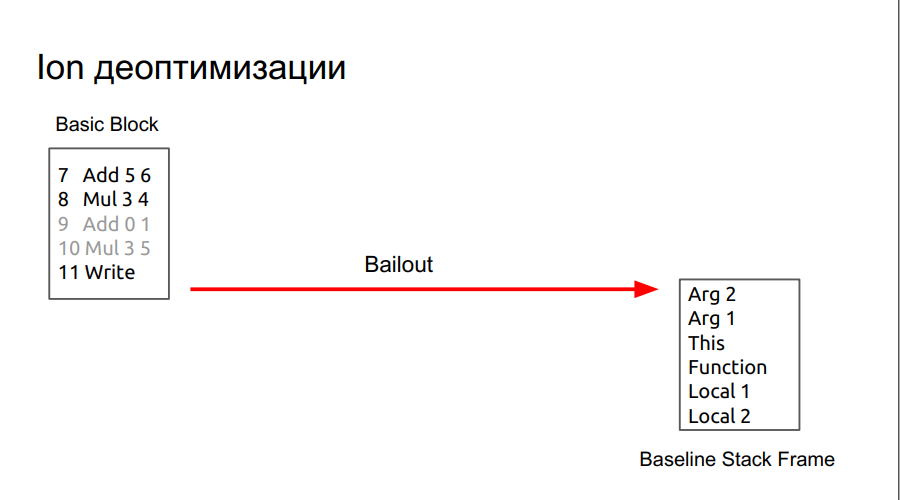
In the image we see an example of a low-level compiler operation. Commands that he optimized when creating a new version of the code, for example with DCE, are marked in gray.
Reduced gear
During the ejection, we move to a less optimized code that expects all the objects it needs to be on the stack, as if the non-optimized version of the code had been running all this time.
To ensure that the data required for execution is not lost, there is a Resume Point in SpiderMonkey. Something like savepoints to which you can always return. They contain all the operands that are currently needed to restore the baseline frames. But they are not enough, so in runtime you need to get information where these operands are located. The lowering, regAlloc phase takes place, after which a snapshot is obtained, in which it is known where the desired operands are located. Based on this information, the baseline frame is restored.
The procedure is shown in the picture:
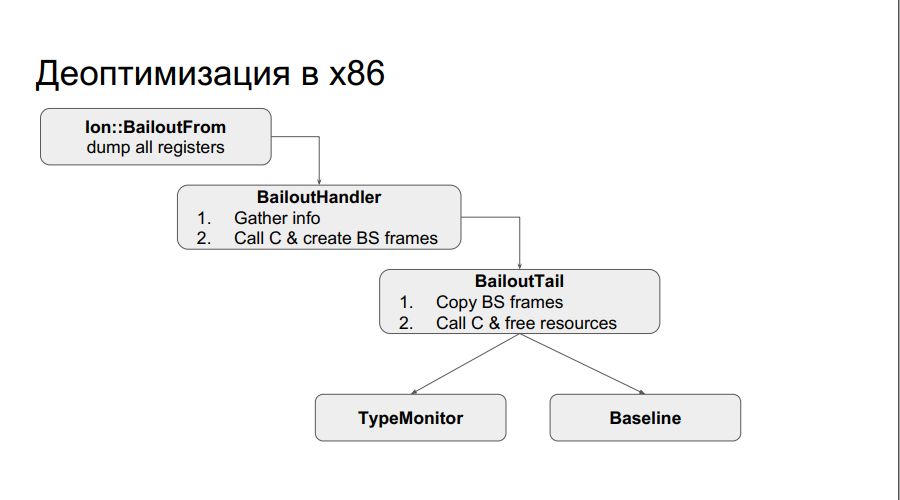
At x86 runtime, it looks like this: let's say, the test in the optimized code worked and you were ejected. The dump of registers and the necessary information from them is collected. It is called C, information about received frames is placed on the heap, another stub is called that copies the operands to the stack, and then a transition to bytecode, which corresponds to the save point, is made. Or, if you were in the middle of an inline cache, switch to a Type monitor. The scheme is shown below:
On Elbrus, this will not work, because one function corresponds to several frames, and the frames in Elbrus are controlled by iron and are stored in a protected chain stack. Therefore, you need to recreate not one frame, but several.
The scheme for Elbrus is more complicated: there is an intermediate deoptimization stub that recreates all this information on the chain stack, recursively calling itself N times, then a system call occurs that replaces return addresses with the corresponding baseline frame addresses, and then goes to the save point and resumes performance.
This is worth considering when developing, if you often see deoptimization in your code.
Revised scheme for the Elbrus architecture:
The result of the entire work of porting Ion was a 4-fold performance boost on some benchmarks compared to the previous baseline implementation. You can see the histogram below:
Results
So, now you know that there is SpiderMonkey, V8 and Node on Elbrus. In general, porting is an easy process. It can be done by a small team.
But it is always important to remember the pitfalls. In the case of Elbrus, they were deoptimization, slow stubs, work with pipeline delays and a chain stack.
If you like the report, pay attention: a new HolyJS will take place on November 24-25 in Moscow , and there will also be many interesting things there. Already known information about the program - on the website, and tickets can be purchased there.