ZFS Filer for Cloud Infrastructure - NexentaStor
In connection with the change of Hostkey of the main data center from Stordata to Megafon and the transfer of the main platform for virtualization and the transition to Server 2012 for Windows, we had to create a new high-performance filer for issuing iSCSI / NFS / SMB targets to clusters and to our clients for organizing private clouds / clusters. We selected and implemented the NexentaStor and this is what came of it and how we did it.
Last Friday we talked about the experience with deploying 180 IPSs using SolusVM , which we all liked except for the lack of subtle allocation of resources. That is what was important to us to ensure uninterrupted service of a cluster based on KVM with Linux, as well as on Hyper-V Windows Server 2012.
For the past 2 years, we have worked with varying success at Starvind. Variable success was that a highly accessible cluster of two equivalent filers for Hyper-V (as planned) had to be forgotten - once a week it fell apart. As a result, it became more or less reliable to work only with the primary and backup, where asynchronous replication was carried out. Using the MPIO settings, we discouraged the Hyper-V cluster from using the backup filer in all cases except crashes, but sometimes the targets themselves crawled to the archive filer.
Another minus is that you cannot do ANYTHING with the already created volume: neither migrate, expand, change the settings, etc. If the volume has a size of about 8TB and under a constant load of 1000 to 2000 IOPS, this is a problem, and each migration is an admin nightmare with monthly preparation and replacement servers. All sorts of little things like resynchronization which takes about 3 days, blue screens of death, unstable deduplication, etc. leave it out of brackets. Attempts to get to the bottom of the problem through support - a dead number, send logs and silence or a slurred answer that does not reflect the essence of the phenomenon. Any upgrade version == reload target == re-synchronization for 2-3 days == nightmare.
The system runs on Windows Server 2008 Standard edition. 2 cars with 2 processors, ~ 2000 rubles per month for each SPLA. 48,000 rubles a year. Support for our 8TB HA license is still around 60,000 rubles. Total, the most basic TCO about 100000r per year.
We searched for an alternative for a long time and began to look closely at the NexentaStor system based on ZFS / Open Solaris (yes, I know that Solaris is not quite open there, it's not about that). Nexenta found a competent small local partner who helped us configure everything, suggested the necessary configuration and set everything up as it should. It took about a month to complete everything from the start of the tests to the launch.
I will not touch on the theory of ZFS, a lot of posts have been written about it.
I want to say right away - HCL (Hardware compatibility list) is our everything. Do not even try to put there something not described in it, there will be no happiness. As a hoster with a fleet of 1000 of his machines, it was relatively simple for us - he climbed into a cabinet with spare parts or a free server and got an alternative part. It will not be easy for a corporate client in case of an error. Solaris does not have as many drivers as other popular OSs.
The license for 8TB and support cost us $ 1,700, there is a free version without support for 18TB. All the same, but without useful and necessary plug-ins. TCO - only a support contract, about 30000r per year. We save from scratch 70000r.
The result of our collaboration was the server of the following configuration:

Special Supermicro Filer, SuperChassis 847E16 .
4U, redundant power supply, 36 3.5 ”hot-swap drives on both sides, 2 high-quality backplanes, large fans with the ability to replace and a place for a standard mother with 8 low-profile expansion cards.
Supermicro motherboard, 2x s1366, 6xPCIe 8x, 2xSAS 2.0, 2x Xeon E5520, 192Gb DDR3 LV RAM processors.
3 LSI HBA controllers LSI9211-8i - Nexente needs the drives themselves, without RAID
1 LSI HBA LSI9200-8e controller - for expansion by disk shelves via SAS.
1 Adaptec controller for 4 ports for connecting an SSD
1 Intel 520 10G network adapter for 2 SFP + ports, through copper direct-connected modules we work with the switch through it
Disks - 35x Hitachi Ultrastar SAS 300Gb 15K
One port is occupied by an AgeStar hot swap box with two small 2.5 ”SSD drives for storing ZFS logs (ZIL), consumables need to be easily and simply replaced (and the box is just included in the 3.5” slot corps as a native). The box is connected to Adaptek.
One SSD on 300Gb server class Intel 710, this is the central cache ZFS. Households are not suitable, they burn out at a time. Connected to Adaptek.
Nexenta has a cache in RAM and holds a deduplication table and metadata in memory. The more memory the better. We set to the maximum, 12x16Gb = 192.
Event budget: ~ 350 000 rub.
We have on the motherboard 2 gigabit ports and 2 10G ports on the Intel 520 controller. 10G ports are connected to the Cisco 2960S switch - 24 1G ports and 2 10G ports, SFP + (~ 90000р). They are connected via copper SFP + direct connect, it is inexpensive - about 1000r per meter cord with SFP + connectors.
In the near future, an Extreme Summit 640 switch will come to us with 48 10G SFP + ports (~ 350,000r), then we will transfer the filer there and use Tsiska to reduce it by 1G.

As it turned out, the most reliable way is the analog of RAID50, triples of disks are assembled in RAIDZ1 and all of them are added to the shared disk pool. A number of hot-swap drives are added to them. As you know, in ZFS there is a special scrub read method that checks in real time the real contents of the disk with the checksums of the blocks and if it finds a difference, then it fixes it right away. If there are a lot of errors, the disk goes out of the array and a backup one is put in its place.


Normal operation through an intuitive web interface. There is a console with simple syntax and the usual ZFS management commands. On the web, statistics, iSCSI / NSF / SMB target generation, creating and managing mount points. Here, just the most important thing is why we took the Nexent - thin provisioning & deduplication. For us in the world of virtualization, deduplication is everything - in each of the hundreds of 10GB Windows VPS, the places are almost the same. In nexent, they come together at the block level.
Further, customers order large disks for viralok and do not use them completely. The average use with the OS is about 15G. In Nexent, we can make a virtual iSCSI target (shared mount point on ISCSI) with an arbitrary size, for example, 500T. This does not affect disk usage, as new data appears there - space is wasted.
The pool capacity can be expanded at any time by adding new disks. This is not a dramatic event when expanding RAID6 with a capacity of 10Tb on a traditional controller, you simply add more disks and the system starts using them. Nothing is rebuilt, data is not moved anywhere.
Nexenta gives complete statistics on how it feels and works for itself - here are the data on the processor load, network interfaces, memory, cache, disaggregation by disk, IOPS by disk / target, etc.

Nature ZFS - the simplicity of snapshots. The system can take pictures from mount points at a given interval and store them on an external storage. You can do asynchronous replication to the nexent side by side. Viral machines themselves can be baked using the means of the used system of virilization.
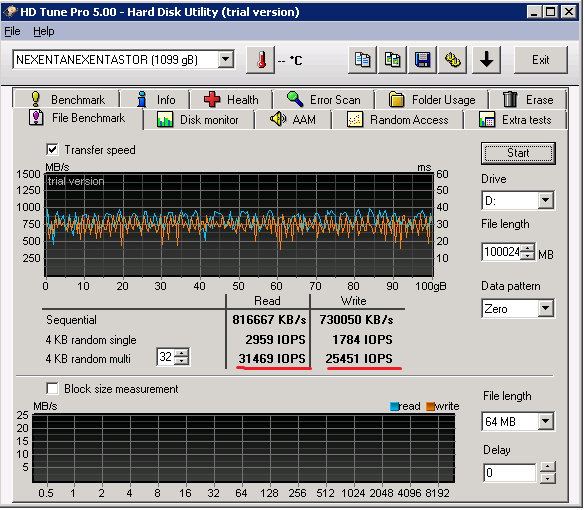
Yes, 10G and multi-tiered storage do almost miracles. On tests from the Windows 2008 Standard edition stand with a regular iSCSI initiator and a Qlogic card, we received a delay of about 2-4 ms, linear transfers of about 700-800 MB per second and more than 31000 IOPS for reading at a queue depth of 16 requests. There were about 25,000 per IOPS record, but in our mass virtualization environment, reading per record is about 1 in 10. We have about 3,000 IOPS per line. The file size for tests does not affect the speed, you can at least 1T.
As the disks fill and load increases, we will add more disks, which will add speed and space.
The main purpose of this solution is to send iSCSI targets to the highly available cluster of Windows Server 2012 for Cluster Shared Volumes to work and to KVM nodes working under SolusVM to organize LVM with which we are working. Deduplication and all the buns described above allow us to keep prices at an excellent level.
The second purpose is to provide customers with the iSCSI target service as a pay-as-you-go service so that our customers no longer need to make their filer if they need a cluster. Since we specialize in large dedicated servers with SLAs for 4 hours, we know why they are taken. It will be possible to seriously save through the use of a centralized infrastructure.
We can now distribute targets at a speed of 1GB, and 10GB. Client targets are automatically snapshot and replicated to archive storage.
I hope this post will be useful and will help to avoid a rake when choosing a solution for multi-level budget vaults. We will work, I will write observations. We look forward to comments and welcome to HOSTKEY .
Last Friday we talked about the experience with deploying 180 IPSs using SolusVM , which we all liked except for the lack of subtle allocation of resources. That is what was important to us to ensure uninterrupted service of a cluster based on KVM with Linux, as well as on Hyper-V Windows Server 2012.
For the past 2 years, we have worked with varying success at Starvind. Variable success was that a highly accessible cluster of two equivalent filers for Hyper-V (as planned) had to be forgotten - once a week it fell apart. As a result, it became more or less reliable to work only with the primary and backup, where asynchronous replication was carried out. Using the MPIO settings, we discouraged the Hyper-V cluster from using the backup filer in all cases except crashes, but sometimes the targets themselves crawled to the archive filer.
Another minus is that you cannot do ANYTHING with the already created volume: neither migrate, expand, change the settings, etc. If the volume has a size of about 8TB and under a constant load of 1000 to 2000 IOPS, this is a problem, and each migration is an admin nightmare with monthly preparation and replacement servers. All sorts of little things like resynchronization which takes about 3 days, blue screens of death, unstable deduplication, etc. leave it out of brackets. Attempts to get to the bottom of the problem through support - a dead number, send logs and silence or a slurred answer that does not reflect the essence of the phenomenon. Any upgrade version == reload target == re-synchronization for 2-3 days == nightmare.
The system runs on Windows Server 2008 Standard edition. 2 cars with 2 processors, ~ 2000 rubles per month for each SPLA. 48,000 rubles a year. Support for our 8TB HA license is still around 60,000 rubles. Total, the most basic TCO about 100000r per year.
Nexenta
We searched for an alternative for a long time and began to look closely at the NexentaStor system based on ZFS / Open Solaris (yes, I know that Solaris is not quite open there, it's not about that). Nexenta found a competent small local partner who helped us configure everything, suggested the necessary configuration and set everything up as it should. It took about a month to complete everything from the start of the tests to the launch.
I will not touch on the theory of ZFS, a lot of posts have been written about it.
I want to say right away - HCL (Hardware compatibility list) is our everything. Do not even try to put there something not described in it, there will be no happiness. As a hoster with a fleet of 1000 of his machines, it was relatively simple for us - he climbed into a cabinet with spare parts or a free server and got an alternative part. It will not be easy for a corporate client in case of an error. Solaris does not have as many drivers as other popular OSs.
The license for 8TB and support cost us $ 1,700, there is a free version without support for 18TB. All the same, but without useful and necessary plug-ins. TCO - only a support contract, about 30000r per year. We save from scratch 70000r.
The result of our collaboration was the server of the following configuration:
Materiel
Special Supermicro Filer, SuperChassis 847E16 .
4U, redundant power supply, 36 3.5 ”hot-swap drives on both sides, 2 high-quality backplanes, large fans with the ability to replace and a place for a standard mother with 8 low-profile expansion cards.
Supermicro motherboard, 2x s1366, 6xPCIe 8x, 2xSAS 2.0, 2x Xeon E5520, 192Gb DDR3 LV RAM processors.
3 LSI HBA controllers LSI9211-8i - Nexente needs the drives themselves, without RAID
1 LSI HBA LSI9200-8e controller - for expansion by disk shelves via SAS.
1 Adaptec controller for 4 ports for connecting an SSD
1 Intel 520 10G network adapter for 2 SFP + ports, through copper direct-connected modules we work with the switch through it
Disks - 35x Hitachi Ultrastar SAS 300Gb 15K
One port is occupied by an AgeStar hot swap box with two small 2.5 ”SSD drives for storing ZFS logs (ZIL), consumables need to be easily and simply replaced (and the box is just included in the 3.5” slot corps as a native). The box is connected to Adaptek.
One SSD on 300Gb server class Intel 710, this is the central cache ZFS. Households are not suitable, they burn out at a time. Connected to Adaptek.
Nexenta has a cache in RAM and holds a deduplication table and metadata in memory. The more memory the better. We set to the maximum, 12x16Gb = 192.
Event budget: ~ 350 000 rub.
network
We have on the motherboard 2 gigabit ports and 2 10G ports on the Intel 520 controller. 10G ports are connected to the Cisco 2960S switch - 24 1G ports and 2 10G ports, SFP + (~ 90000р). They are connected via copper SFP + direct connect, it is inexpensive - about 1000r per meter cord with SFP + connectors.
In the near future, an Extreme Summit 640 switch will come to us with 48 10G SFP + ports (~ 350,000r), then we will transfer the filer there and use Tsiska to reduce it by 1G.
Features of the partitioning disks
As it turned out, the most reliable way is the analog of RAID50, triples of disks are assembled in RAIDZ1 and all of them are added to the shared disk pool. A number of hot-swap drives are added to them. As you know, in ZFS there is a special scrub read method that checks in real time the real contents of the disk with the checksums of the blocks and if it finds a difference, then it fixes it right away. If there are a lot of errors, the disk goes out of the array and a backup one is put in its place.
Control
Normal operation through an intuitive web interface. There is a console with simple syntax and the usual ZFS management commands. On the web, statistics, iSCSI / NSF / SMB target generation, creating and managing mount points. Here, just the most important thing is why we took the Nexent - thin provisioning & deduplication. For us in the world of virtualization, deduplication is everything - in each of the hundreds of 10GB Windows VPS, the places are almost the same. In nexent, they come together at the block level.
Further, customers order large disks for viralok and do not use them completely. The average use with the OS is about 15G. In Nexent, we can make a virtual iSCSI target (shared mount point on ISCSI) with an arbitrary size, for example, 500T. This does not affect disk usage, as new data appears there - space is wasted.
The pool capacity can be expanded at any time by adding new disks. This is not a dramatic event when expanding RAID6 with a capacity of 10Tb on a traditional controller, you simply add more disks and the system starts using them. Nothing is rebuilt, data is not moved anywhere.
Nexenta gives complete statistics on how it feels and works for itself - here are the data on the processor load, network interfaces, memory, cache, disaggregation by disk, IOPS by disk / target, etc.
Backup
Nature ZFS - the simplicity of snapshots. The system can take pictures from mount points at a given interval and store them on an external storage. You can do asynchronous replication to the nexent side by side. Viral machines themselves can be baked using the means of the used system of virilization.
Performance
Yes, 10G and multi-tiered storage do almost miracles. On tests from the Windows 2008 Standard edition stand with a regular iSCSI initiator and a Qlogic card, we received a delay of about 2-4 ms, linear transfers of about 700-800 MB per second and more than 31000 IOPS for reading at a queue depth of 16 requests. There were about 25,000 per IOPS record, but in our mass virtualization environment, reading per record is about 1 in 10. We have about 3,000 IOPS per line. The file size for tests does not affect the speed, you can at least 1T.
As the disks fill and load increases, we will add more disks, which will add speed and space.
Using
The main purpose of this solution is to send iSCSI targets to the highly available cluster of Windows Server 2012 for Cluster Shared Volumes to work and to KVM nodes working under SolusVM to organize LVM with which we are working. Deduplication and all the buns described above allow us to keep prices at an excellent level.
The second purpose is to provide customers with the iSCSI target service as a pay-as-you-go service so that our customers no longer need to make their filer if they need a cluster. Since we specialize in large dedicated servers with SLAs for 4 hours, we know why they are taken. It will be possible to seriously save through the use of a centralized infrastructure.
We can now distribute targets at a speed of 1GB, and 10GB. Client targets are automatically snapshot and replicated to archive storage.
I hope this post will be useful and will help to avoid a rake when choosing a solution for multi-level budget vaults. We will work, I will write observations. We look forward to comments and welcome to HOSTKEY .