MIT course "Security of computer systems". Lecture 7: "Sandbox Native Client", part 2
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems." Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Control of hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: “Privilege Separation” Part 1 / Part 2 / Part 3
Lecture 5: “Where Security System Errors Come From” Part 1 / Part 2
Lecture 6: “Capabilities” Part 1 / Part 2 / Part 3
Lecture 7: "Native Client Sandbox" Part 1 / Part 2 / Part 3
Audience: why should the range of the memory capacity of the address space start from zero?
Professor: because from a performance point of view, it is more efficient to apply a target jump if you know that a valid address is a continuous set of addresses starting from zero. Because then you can do it with a single AND -mask, where all the high bits are one, and only a pair of low bits is zero.
Audience: I thought AND- mask was supposed to provide alignment.
Prof: right, the mask provides alignment, but why does it start from scratch? I think they rely on segmented hardware. Segmentation Hardware. So, in principle, they could use it to move the area upwards in terms of linear space. Or maybe it’s just because the application “sees” this range. In fact, you can place it at different offsets in your virtual address space. This will allow you to perform certain tricks with segmented hardware to run multiple modules in a single address space.

Audience: Is this perhaps because they want to “catch” the point of reception of the null pointer?
Professor:Yes, because they want to catch all points of reception. But you have a way to do it. Because the null pointer refers to the segment that is being accessed. And if you move a segment, you can display an unused zero page at the beginning of each segment. So this will help to make several modules.
I think that one of the reasons for this decision - to start the range from 0 - is related to their desire to port their program to the x64 platform , which has a slightly different design. But in their article this is not mentioned. In 64-bit design, the hardware itself got rid of some of the segmentation hardware that they relied on for efficiency reasons, so they had to consider a software-based approach. However, for x32this is not a sufficiently weighty reason for the space to start from scratch.
So, we continue the main question - what do we want to provide from a security point of view. Let's get to this case a little “naively” and see how we can spoil everything, and then try to fix it.
I believe that a naive plan is to look for prohibited instructions, simply by scanning the executable from the very beginning to the end. So how can you discover these instructions? You can simply take the program code and put it in a giant line that goes from zero to 256 megabytes, depending on how big your code is, and then start the search.

This line can first contain the NOP module , then the ADD instruction module , NOT, JUMP and so on. You are simply looking for, and if you find bad instructions, then say that this is a bad module and discard it. And if you do not see any system call to this instruction, then you can allow the launch of this module and do everything that is within the range of 0-256. Do you think it will work or not? What are they worried about? Why is it so hard?
Audience: Are they concerned about the size of the instructions?
Professor: Yes, the fact is that the x86 platformhas variable length instructions. This means that the specific size of the instruction depends on the first few bytes of this instruction. In fact, you can look at the first byte to say that the instruction will be much larger, and then you may have to look at a couple more bytes, and then decide what kind of size it takes. Some architectures, such as Spark , ARM , MIPS, have more fixed-length instructions. In ARM has two lengths of instructions - either 2 or 4 bytes. But in the x86 platform , the length of instructions can be 1, and 5, and 10 bytes, and if you try, you can even get a rather long instruction of 15 bytes. However, these are complex instructions.
As a result, there may be a problem. If you scan this line of software code linearly, everything will be fine. But maybe at runtime you will go to the middle of some instruction, for example, NOT .

It is possible that this is a multibyte instruction, and if we interpret it, starting from the second byte, then it will look completely different.
Another example in which we will “play” with an assembler. Suppose we have instruction 25 CD 80 00 00 . Looking at the 2nd byte, you will interpret it as a five-byte instruction, that is, you will have to look 5 bytes ahead and see that it is followed by the AND% EAX, 0x00 00 80 CD instruction , starting with the AND operator for the registerEAX with some defined constants, for example, 00 00 80 CD . This is one of the safe instructions that the Native Client should simply allow according to the first rule for checking binary instructions. But if during the execution of the program the CPU decides that it should start executing the code from the CD , I will mark this place of the instruction with an arrow, then the instruction % EAX, 0x00 00 80 CD , which is actually a 4-byte instruction, will mean execution INT $ 0x80 , which is a way to make a system call on Linux .
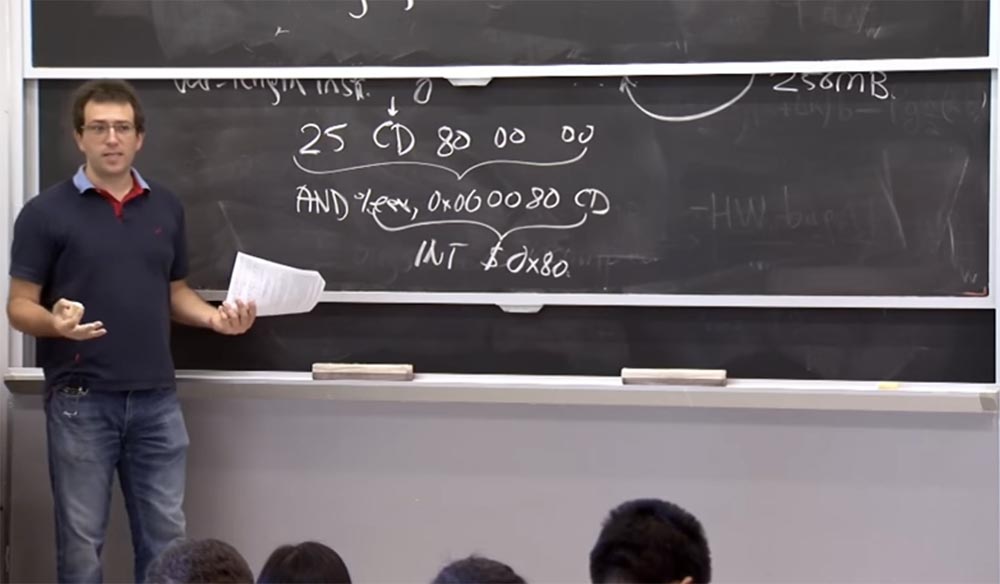
So if you miss this fact, then let the unreliable module "jump" into the kernel and make system calls, that is, do what you wanted to prevent. How can we avoid this?
Perhaps we should try to look at the offset of each byte. Since x86 can only begin to interpret the instruction in byte boundaries, not bit boundaries. Thus, you will have to look at the offset of each byte to see where the instruction starts from. Do you think this is a practical plan?
Audience: I think that if someone actually uses AND , the processor will not jump to this place, but simply allow the program to run.
Professor:Yes, because basically it is not prone to false positives. Now, if you really want it, you can change the code a little to somehow avoid it. If you know exactly what the test device is looking for, you could potentially change these instructions. Maybe by setting AND first for one instruction, and then use the mask on another. But it’s much easier to avoid these suspicious byte locations, although this seems rather inconvenient.
It is possible that the architecture includes a compiler change. In principle, they have some component that actually needs to compile the code correctly. You can’t just take GCC off the shelf and compile code for a Native Client. So basically it is doable. But probably, they just think that it causes too much trouble, will not be a reliable or high-performance solution, and so on. Plus, there are several x86 instructions that are prohibited, or should be recognized as unsafe and therefore should be prohibited. But for the most part, they are one byte in size, so they are quite difficult to search for or filter out.
Therefore, if they cannot simply collect and sort unsafe instructions and hope for the best, they need to use another plan to disassemble it in a reliable way. So what does the Native Client do to make sure that they do not “stumble” about this variable length encoding?
In a sense, if we really scan the executable file forward from left to right and look for all possible incorrect codes, and if that is the way the code is executed, then we are in good shape. Even if there are some strange instructions present and there is some offset, the processor is still not going to “jump” there, it will execute the program in the same order in which the instructions are scanned, that is, from left to right.

Thus, the problem with reliable disassembling arises from the fact that “jumps” can take place somewhere in the application. A processor may crash if it “jumps” to some kind of code instruction that it did not notice when scanning from left to right. So this is a problem of reliable disassembling while it is in development. And the basic plan is to check where all the “jumps” go. In fact, it is quite simple at some level. There are a lot of rules that we will consider in a second, but the approximate plan is that if you see the “jump” of the instructions, then you need to make sure that the goal of the “jump” was seen earlier. To do this, in fact, it suffices to perform a scan from left to right, that is, the procedure that we described in our naive approach to the problem.
In this case, if you see any “jump” instruction and the address that this instruction points to, then you must make sure that this is the same address that you already saw during the disassembly from left to right.
If a jump instruction to this CD byte is found, then we must mark this jump as invalid, because we have never seen the instruction starting at the CD byte, but we have seen another instruction starting with the number 25. But if all the jump instructions order to proceed to the beginning of the instruction, in this case to 25, then everything is fine with us. It's clear?
The only problem is that you cannot check the goals of each jump in the program, because there may be indirect jumps. For example, in x86you may have something like a jump to the value of this register EAX . This is great for implementing function pointers.

That is, the function pointer is somewhere in memory, you hold it in some register, and then go to any address that is in the move register.
So how do these guys deal with indirect jumps? Because, in fact, I have no idea whether this will be a “jump” to the CD byte or to byte 25. What do they do in this case?
Audience: use tools?
Professor:Yes, instrumentation is their main trick. Therefore, whenever they see that the compiler is ready to perform the generation, this is proof that this jump does not cause trouble. To do this, they need to make sure that all jumps are performed with a multiplicity of 32 bytes. How do they do it? They change all the jump instructions for what they called “pseudoinstructions”. These are the same instructions, but prefixed, which clears the 5 low bits in the EAX register . The fact that the instruction clears 5 low bits means that this causes the value to be a multiple of 32, from two to five, and then a “jump” is made to this value.

If you look at it during verification, then make sure that this instructional “pair” will “jump” only with a multiplicity of 32 bytes. And then, in order to make sure that there is no possibility of “jumping” into some strange instructions, you apply an additional rule. It lies in the fact that during disassembling, when you view your instructions from left to right, you ensure that the beginning of each valid instruction will also be a multiple of 32 bytes.
Thus, in addition to this toolkit, you verify that every code that is a multiple of 32 is the correct instruction. By correct, valid instruction, I understand the instruction that is being disassembled from left to right.
Audience: why is the number 32 chosen?
Professor:yes, why did they choose 32, not 1000 or 5? Why is 5 a bad thing?
Audience: because the number must be a degree 2.
Prof: yes, well, that's why. Because otherwise, ensuring the use of something multiple of 5 will require additional instructions leading to overhead. What about eight? Eight - a good enough number?
Audience: You may have instructions longer than eight bits.
Professor:Yes, it can be for the longest instruction allowed on the x86 platform. If we have 10 byte instructions, and everything must be a multiple of 8, then we will not be able to insert it anywhere. So the length should be sufficient for all cases, because the biggest instruction I saw was 15 bytes long. So 32 bytes is quite enough.
If you want to adapt the instruction to enter or exit from the process environment, you may need some nontrivial amount of code in one 32-byte slot. For example, 31 bytes, because 1 byte contains the instruction. Should it be much bigger? Should we make it equal, say, 1024 bytes? If you have a lot of function pointers or a lot of indirect jumps, then every time you want to create some place where you are going to jump, you must continue it to the next border, regardless of its value. So with 32 bits, it's quite a normal size. In the worst case, you will lose only 31 bytes if you need to quickly get to the next border. But if you have a size that is a multiple of 1024 bytes, then it is possible to waste a whole kilobyte of memory for an indirect jump.
I do not think that the number 32 is a stumbling block for the Native Client . Some blocks could work with a multiplicity of 16 bits, some 64 or 128 bits are not important. Just 32 bits seemed to them the most acceptable, optimal value.
So let's make a reliable disassembly plan. As a result, the compiler should be a bit careful when compiling C or C ++ code into a binary Native Client file and follow these rules.

Therefore, whenever he has a jump, as shown in the top line, he should add these additional instructions given in the 2 bottom lines. And regardless of the fact that it creates the function to which it is going to "jump", our instruction will jump as indicated by this addition AND $ 0xffffffe0,% eax . And it cannot simply add zeros to it, because all of this must have the correct codes. Thus, the addition is necessary in order to make sure that every possible instruction is valid. And, fortunately, on the x86 platform , no noop function is described by one byte, or at least there is no noopsize of 1 byte. Thus, you can always add things to the value of a constant.
So what does this guarantee us? Let's make sure that we always see what happens in the terminology of the instructions that will be executed. That's what gives us this rule - the confidence that the system call will not be made by chance. This is about jumping, but what about returns? How do they cope with the return? Can we perform a return to a function in the Native Client ? What happens if you run hot code?
Audience: He can overflow the stack.
Professor: it is true that he quite unexpectedly pops up on the stack. But the fact is that the stack that the Native Client modules useIt actually contains some data inside it. Thus, when contacting the Native Client you should not be worried about stack overflow.
Audience: wait, but you can put anything on the stack. And when you make an indirect jump.
Professor: that's true. A return looks almost like an indirect jump from some place in memory that is at the top of the stack. Therefore, I think that one thing they could do for the return function is to set the prefix in the same way as it was done in the previous test. And this prefix checks for what floats at the top of the stack. You check if it is valid and when you are recording or using the operatorAND , then you check what is at the top of the stack. This seems a bit unreliable due to constant data changes. Because, for example, if you look at the top of the stack and make sure everything is fine, and then write something, the data flow in the same module can modify something at the top of the stack, after which you will refer to the wrong address.
Audience: Doesn’t this also apply to jumps?
Professor: yes, so what happens there with a jump? Can our race conditions somehow invalidate this check?
Audience: but the code is not available for recording?
Professor:Yes, the code can not be written, it's true. Thus, you cannot modify AND. But can not some other stream change the purpose of the jump between these two instructions?
Audience: this is in the register, so ...
Professor: Yes, it's a cool thing. Because if the stream modifies something in memory or in what is loaded from EAX (by itself, you do it before loading), in this case, this EAX will be in a bad state, but then clear the bad bits. Or it may change memory after the pointer is already in EAX , so it does not matter that it changes the location of the memory from which the EAX register was loaded .
In fact, threads do not share sets of registers. Therefore, if another thread changes the EAX register , it will not affect the EAX register of this thread. Thus, other threads cannot invalidate this sequence of instructions.
There is another interesting question. Can we get around this AND ? I can jump wherever I want to anywhere in this address space. And when I disassemble this instruction, it looks like a parallel instruction for AND and jumps.

And the check of static jumps is that they should point to the goal we saw earlier, that is, yes, we have already seen this line of the AND operator. This is one valid instruction. We also saw the jmp jump , and this is another valid instruction.

Therefore, when I see a direct jump here, I jump to a specific address, for example, 1237. In fact, this is normal, although not a multiple of 32. Usually, the Native Client does not allow direct jumping to arbitrary addresses, if this address is the instruction we saw during disassembling, as we just said. Could I put here a proven indirect jump and then, when executing the code, go directly from this address 1237 to the second instruction in our sequence?
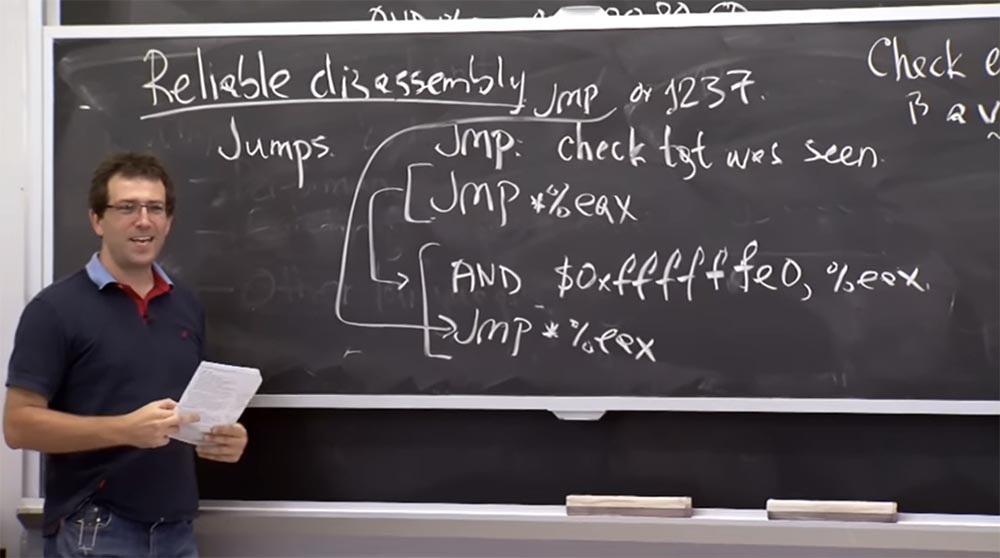
When I upload something to EAX, then I will jump here, upwards, and then I will jump directly to this lower line, to this address, which is not isolated in the sandbox. Everyone understands that this will violate security? So how can you avoid this?
Audience: NaCl must make this leap handled by a separate pseudoinstruction.
Professor: yes, that's why this thing is called the only pseudoinstruction. And even at the level of the x86 platform , this is a completely separate instruction, and as long as the validator is NaClcares about it, these 2 lower lines actually represent the separate atomic block. So, when checking instructions on whether they saw it before, the validator considers: “oh, yes, this is the only instruction I’ve seen before!”, Therefore jumping to the middle of the pseudoinstruction code means jumping to the middle of the address above 25 CD 80 00 00 . It is the same. So they understand the semantics of instructions a bit differently, as understood by the x86 platform .
And this means that in the Native Client you can represent specific sequences of instructions. Therefore, if you really had a legitimate code that looked like this last but one line, then it can be turned into a separate code in NaCl. Hope this is no problem.
Audience: presumably, they can do this in a trusted code base when the next text segment begins. Because this method means that these two lines are always replaced with one. Instead of putting them in a binary file that you still create, you simply jump directly to the jump target, which is in the privileged section.

Professor: yes it is true. This is another smart decision that can be applied. Suppose that you do not want to do this pseudoinstruction, but you just want to have one instruction replacing the EAX jump . You can do this with a library of all possible indirect jumps that may ever take place. In this case, we will have a jumpEAX , EBX jump and so on. You will create a library for these jumps and develop a safe check that they will replace the first line of our pseudoinstructions. To do this, you place the AND operator in front of each of these jumps, EAX and EBX, and so on. And then in a binary file, every time you want to jump to EAX , you will actually jump to a fixed address. And this address will point to the useful part of the code, which is stored somewhere in the low 64k bits of the program. And after that, Jmp *% eax will execute the AND operator and jump again.

The reason they probably do not do this is in performance. Because Intel , one of the most common processors in our time, has to predict where the process forks in order to constantly maintain a full flow of processes. So for him the task of predicting jumps, especially indirect ones, guessing jump addresses and storing them in the linear memory cache will be too confusing. Because if AND jumping occurs in a certain place, then EAX jumps occur from everywhere, which can greatly “confuse” the processor.
So, we have roughly figured out how the process of disassembling instructions proceeds and how to prevent the execution of incorrect instructions. Now let's look at the set of rules that they placed in the first table of the article. It contains various rules that a validator must follow, or binary files that the validator checks. Therefore, I will go through these rules to check that you understand what they are for.
So, we have these rules, from C1 to C7 .
C1basically says that as soon as you load binary memory, the binary file actually becomes unavailable for writing at the page table level. That is, this rule establishes that the allowed bits for “binaries” cannot be used for writing. This is because the overall security plan is based on the fact that your binaries are correct. Therefore, you need to make sure that you have not modified these files so that they can do something forbidden. I think this rule is quite understandable.
C2 means that the parameters start at 0 and end at 64k.. This is not related to security, but is done simply for convenience, because they want to have a standard program layout. In a sense, this contributes to the ease of data transfer, because it limits the number of things that can damage the validator or the loader.
Rule C3 means that indirect, or indirect, jumps use pseudoinstructions. That is, we have a double parallel instruction, described above, which does not allow you to jump into the middle of the wrong instruction.
C4 says that you must fill in the boundary pages with a stop instruction hlt . Why do they want to supplement their binary file with processor suspension using the halt command? I do not have a clear answer why C4 exists. But I think this is because the code naturally stops at some point, that is, there is some end to the operation.
And the question is what happens when you just continue to execute the code and get to the end? Obviously, then the processor may simply continue to perform some additional instructions, or it may turn out in some strange way.
Therefore, they just want to make sure that there is no ambiguity in what happens if you continue to perform and do not jump, but simply follow to the end of the instructions screen. So let's assume that the meaning of this rule is that if you continue execution, you will stop, get trapped during the execution of the process and interrupt the module. So this rule concerns simplicity and safety of work.

55:20 min.
Continued:
Course MIT "Security of computer systems." Lecture 7: "Sandbox Native Client", part 3
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
3 months for free if you pay for new Dell R630 for a period of half a year - 2 x Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 4x1TB HDD or 2x240GB SSD / 1Gbps 10 TB - from $ 99.33 a month , only until the end of August, order can be here.
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?