Optimization of games for iOS platform. Code Vectorization
The desire has long been brewing to write a couple of articles in which I can lay out my experience and knowledge on optimizing games for the ARMv7 CPU architecture and PowerVR SGX 5 GPU series, read the iOS platform. But all, or almost all, tips are equally applicable to other systems with the same hardware, read Androids. This material can be used not only in games but also in most demanding applications - image processing, audio, video, etc. I will start my first article with the most important, IMHO, optimization - vectorization of code for NEON .
This article began as a report to the conference, which will be held on 24.11. A wealth of iPhone optimization tips can be found here . The following articles will expand the breadth and depth of the topic material from this presentation.
What is NEON? NEON is a general-purpose SIMD engine used in ARM processors. On board it has 16 registers of 128 bits each, which can be considered as 32 registers of 64 bits. NEON shares its registers with VFP, although it has its own separate pipeline. As with SSE, data must be aligned by 16 bytes. NEON also knows how to work with unaligned data, but usually it is 2 times slower.
NEON can work with:
It is great for multimedia tasks, including games.
Let's start with the main one - the heart of every modern mobile system, a system on a chip or SoC (System on Chip). It is known that iOS A devices use the Apple A series of systems on a chip - A4, A5, A5x, A6 and A6x. The most important specifications for these chips are listed in the table:
* Note: NEON runs at CPU frequency
It is easy to see that NEON has a 5-fold increase in frequency compared to the GPU! Of course, this does not mean that we will get a 5-fold increase in productivity compared to the GPU - IPC, pipeline, etc. are significant. But NEON has one feature killer - it can simultaneously process 4 32-bit floats, while PowerVR SGX is only one. It seems that PowerVR SGX 5-series SIMD registers have a length of 64 bits, since the GPU can simultaneously process 4 half-precision floats (16 bits). Consider an example:
Now consider another example executed on the GPU vector engine:
You will need a highp specifier for your data, for example, the position of the vertices. The profit from NEON is obvious here.
Now let's move on to another advantage of NEON. PowerVR SGX 5 Series is known to have USSE, a shader processor, which does not matter which type of shader to process - vertex or pixel. This means that the programmer has a certain power budget and it is up to him to decide whether to spend it on vertex or pixel processing. This is where NEON comes to the rescue - this is your new vertex processor. You might think that I forgot to insert a trollface here, but everything is quite serious. The performance of almost every mobile system is limited by fill rate, especially in 2D games, especially nowadays races for screen resolution. Transferring all vertex processing to NEON, you free up resources for pixel processing. In addition to this, NEON will help reduce the number of draw calls - calculate the positions of all the vertices of one batch in world coordinates and draw N objects in one call.
Theory is over! Now let's get to the hardcore! There are several ways to take advantage of NEON:
It's time to discover all the advantages and disadvantages of each method. To do this, I wrote a simple demo - each frame of 10,000 sprites will change their position to a random one within the screen. The goal is to get the fastest code with the minimum CPU load - after all, in games there is a lot to consider, in addition to data for rendering.
All data is stored in one VBO. The Update method multiplies the projection matrix by the ModelView matrix of a random position. Next, each vertex of each sprite will be multiplied by the resulting ModelViewProjection matrix. The final position of each vertex will simply be passed to gl_Position in the vertex shader. All data is aligned to a border of 16 bytes.
Method Update Code:
Well, now we come to the essence of this article - vectorization of code. Next, the code will be presented, used in the three compared approaches for the most frequently used operations in game dev - multiplication of a matrix by a vector and multiplication of a matrix by a matrix.
Copy paste with GLKMath:
Assembler approach:
Intrinsic Method:
I did a test on iPod Touch 4. The table contains the profiling results of the Update function:
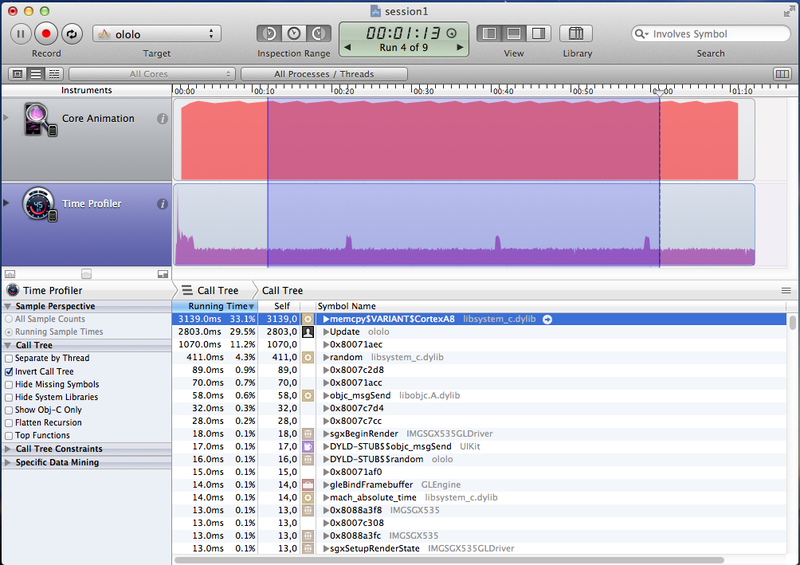
* In the screenshot from Instruments, you can see that the Matrix4ByMatrix4 function is not inlined.
Here's another tip - aggressively inline your performance-critical code. Prefer __attribute __ ((always_inline)) over regular inline in such cases.
Updated Results Table:
Forced inline gave a very good performance boost! Let's see how code auto-vectorization will show itself. All we need to do is add –mllvm –vectorize –mllvm –bb-vectorize-aligned-only to Other C Flags in the project settings.
Final table of results:
Quite strange results can be observed in the case of assembler and intrinsics - in fact the code is the same, but the result differs dramatically - almost 2 times! The answer to this question lies in assembly listing (those who want to take a look themselves). In the case of the assembler, we see exactly what we wrote in the listing. In the case of intrinsics, the compiler optimized the code. Slow, at first glance, the GLKMath code compiler perfectly optimized, which gave the same code execution time as the manually written intrinsics.
It is time to take stock. Several conclusions can be drawn:
blogs.arm.com/software-enablement/161-coding-for-neon-part-1-load-and-stores
code.google.com/p/ math-neon
llvm.org/devmtg/2012-04-12/Slides/Hal_Finkel.pdf
Demo project
This article began as a report to the conference, which will be held on 24.11. A wealth of iPhone optimization tips can be found here . The following articles will expand the breadth and depth of the topic material from this presentation.
What is NEON? NEON is a general-purpose SIMD engine used in ARM processors. On board it has 16 registers of 128 bits each, which can be considered as 32 registers of 64 bits. NEON shares its registers with VFP, although it has its own separate pipeline. As with SSE, data must be aligned by 16 bytes. NEON also knows how to work with unaligned data, but usually it is 2 times slower.
NEON can work with:
- Signed \ unsigned 8 \ 16 \ 32 \ 64-bit integer data types;
- Single precision floating point numbers - 32-bit float.
It is great for multimedia tasks, including games.
Let's start with the main one - the heart of every modern mobile system, a system on a chip or SoC (System on Chip). It is known that iOS A devices use the Apple A series of systems on a chip - A4, A5, A5x, A6 and A6x. The most important specifications for these chips are listed in the table:
| CPU Specifications | A4 | A5 | A5x | A6 |
|---|---|---|---|---|
| Architecture | ARMv7 | ARMv7 | ARMv7 | ARMv7 |
| Core | Cortex a8 | Cortex a9 | Cortex a9 | Own development |
| # cores | 1 | 2 | 2 | 2 |
| Frequency, MHz | 800 | 1000 | 1000 | 1300 |
| Extensions | VFPv3 (VFPLite), NEON | VFPv3, NEON | VFPv3, NEON | VFPv4, NEON |
| GPU Specifications | ||||
| Model | PowerVR SGX 535 | PowerVR SGX 543MP2 | PowerVR SGX 543MP4 | PowerVR SGX 543MP3 |
| Frequency, MHz | 200 | 200 | 200 | 266 |
It is easy to see that NEON has a 5-fold increase in frequency compared to the GPU! Of course, this does not mean that we will get a 5-fold increase in productivity compared to the GPU - IPC, pipeline, etc. are significant. But NEON has one feature killer - it can simultaneously process 4 32-bit floats, while PowerVR SGX is only one. It seems that PowerVR SGX 5-series SIMD registers have a length of 64 bits, since the GPU can simultaneously process 4 half-precision floats (16 bits). Consider an example:
highp vec4 v1, v2;
highp float s1, s2;
// Плохо
v2 = (v1 * s1) * s2; //v1 * s1 будет выполнено на скалярном процессоре – 4 операции, результат этого умножения будет умножен на s2, опять на скалярном процессоре - еще 4 операции.
//8 операций в общем
// Хорошо
v2 = v1 * (s1 * s2); //s1 * s2 – 1 операция на скалярном процессоре; результат * v1 – 4 операции на скалярном.
//5 операций в общем
Now consider another example executed on the GPU vector engine:
mediump vec4 v1, v2, v3;
highp vec4 s1, s2, s3;
v3 = v1 * v2; //исполняется на векторном процессоре – 1 операция
s3 = s1 * s2; //исполняется на скалярном процессоре – 4 операции
You will need a highp specifier for your data, for example, the position of the vertices. The profit from NEON is obvious here.
Now let's move on to another advantage of NEON. PowerVR SGX 5 Series is known to have USSE, a shader processor, which does not matter which type of shader to process - vertex or pixel. This means that the programmer has a certain power budget and it is up to him to decide whether to spend it on vertex or pixel processing. This is where NEON comes to the rescue - this is your new vertex processor. You might think that I forgot to insert a trollface here, but everything is quite serious. The performance of almost every mobile system is limited by fill rate, especially in 2D games, especially nowadays races for screen resolution. Transferring all vertex processing to NEON, you free up resources for pixel processing. In addition to this, NEON will help reduce the number of draw calls - calculate the positions of all the vertices of one batch in world coordinates and draw N objects in one call.
Theory is over! Now let's get to the hardcore! There are several ways to take advantage of NEON:
- Let the compiler vectorize the code for you. Bad way. The compiler may vectorize ... or it may not vectorize. Even if the compiler vectorizes the code, then it’s far from the fact that it will be the best code. But, on the other hand, this method does not require any efforts on your part, and you can get profit. But still, you should not blindly rely on the compiler, but manually vectorize at least the most critical code.
- NEON assembler. And here he is, hardcore. The path of a true Jedi and all that. You have to learn dark magic, spend nights on ARM manuals, etc. It is also worth keeping in mind that NEON code works in both ARM and Thumb-2 modes.
- NEON intrinsics (same as SSE for x86). Unlike assembler, where the compiler stupidly inserts what it was given, intrinsics will be optimized. It is much easier to live with them - there is no need to study the timings of instructions, shuffle them to avoid pipe stagnation, etc.
- Use with already vectorized code - GLKMath, math neon.
It's time to discover all the advantages and disadvantages of each method. To do this, I wrote a simple demo - each frame of 10,000 sprites will change their position to a random one within the screen. The goal is to get the fastest code with the minimum CPU load - after all, in games there is a lot to consider, in addition to data for rendering.
All data is stored in one VBO. The Update method multiplies the projection matrix by the ModelView matrix of a random position. Next, each vertex of each sprite will be multiplied by the resulting ModelViewProjection matrix. The final position of each vertex will simply be passed to gl_Position in the vertex shader. All data is aligned to a border of 16 bytes.
Method Update Code:
void Update()
{
GLKMatrix4 modelviewMat =
{
1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0,
0, 0, 0, 1,
};
const u32 QUADS_COUNT = 10000;
const u32 VERTS_PER_QUAD = 4;
const float Y_DELTA = 420.0f / QUADS_COUNT; //равномерно распределить все спрайты по Y
float vertDelta = Y_DELTA;
for (int i = 0; i < QUADS_COUNT * VERTS_PER_QUAD; i += VERTS_PER_QUAD)
{
float randX = random() % 260; //Матрица смещения на случайное число
modelviewMat.m[12] = randX;
modelviewMat.m[13] = vertDelta;
float32x4x4_t mvp;
Matrix4ByMatrix4((float32x4x4_t*)proj.m, (float32x4x4_t*)modelviewMat.m, &mvp);
for (int j = 0; j < 4; ++j) {
Matrix4ByVec4(&mvp, &squareVertices[j], &data[i + j].pos);
}
vertDelta += Y_DELTA;
}
glBindBuffer(GL_ARRAY_BUFFER, vertexBuffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(data), data, GL_STREAM_DRAW);
}
Well, now we come to the essence of this article - vectorization of code. Next, the code will be presented, used in the three compared approaches for the most frequently used operations in game dev - multiplication of a matrix by a vector and multiplication of a matrix by a matrix.
Copy paste with GLKMath:
static __inline__ GLKVector4 GLKMatrix4MultiplyVector4(GLKMatrix4 matrixLeft, GLKVector4 vectorRight)
{
float32x4x4_t iMatrix = *(float32x4x4_t *)&matrixLeft;
float32x4_t v;
iMatrix.val[0] = vmulq_n_f32(iMatrix.val[0], (float32_t)vectorRight.v[0]);
iMatrix.val[1] = vmulq_n_f32(iMatrix.val[1], (float32_t)vectorRight.v[1]);
iMatrix.val[2] = vmulq_n_f32(iMatrix.val[2], (float32_t)vectorRight.v[2]);
iMatrix.val[3] = vmulq_n_f32(iMatrix.val[3], (float32_t)vectorRight.v[3]);
iMatrix.val[0] = vaddq_f32(iMatrix.val[0], iMatrix.val[1]);
iMatrix.val[2] = vaddq_f32(iMatrix.val[2], iMatrix.val[3]);
v = vaddq_f32(iMatrix.val[0], iMatrix.val[2]);
return *(GLKVector4 *)&v;
}
static __inline__ GLKMatrix4 GLKMatrix4Multiply(GLKMatrix4 matrixLeft, GLKMatrix4 matrixRight)
{
float32x4x4_t iMatrixLeft = *(float32x4x4_t *)&matrixLeft;
float32x4x4_t iMatrixRight = *(float32x4x4_t *)&matrixRight;
float32x4x4_t m;
m.val[0] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[0], 0));
m.val[1] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[1], 0));
m.val[2] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[2], 0));
m.val[3] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[3], 0));
m.val[0] = vmlaq_n_f32(m.val[0], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[0], 1));
m.val[1] = vmlaq_n_f32(m.val[1], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[1], 1));
m.val[2] = vmlaq_n_f32(m.val[2], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[2], 1));
m.val[3] = vmlaq_n_f32(m.val[3], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[3], 1));
m.val[0] = vmlaq_n_f32(m.val[0], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[0], 2));
m.val[1] = vmlaq_n_f32(m.val[1], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[1], 2));
m.val[2] = vmlaq_n_f32(m.val[2], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[2], 2));
m.val[3] = vmlaq_n_f32(m.val[3], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[3], 2));
m.val[0] = vmlaq_n_f32(m.val[0], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[0], 3));
m.val[1] = vmlaq_n_f32(m.val[1], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[1], 3));
m.val[2] = vmlaq_n_f32(m.val[2], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[2], 3));
m.val[3] = vmlaq_n_f32(m.val[3], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[3], 3));
return *(GLKMatrix4 *)&m;
}
Assembler approach:
inline void Matrix4ByVec4(float32x4x4_t* __restrict__ mat, const float32x4_t* __restrict__ vec, float32x4_t* __restrict__ result)
{
asm
(
"vldmia %0, { d24-d31 } \n\t"
"vld1.32 {q1}, [%1]\n\t"
"vmul.f32 q0, q12, d2[0]\n\t"
"vmla.f32 q0, q13, d2[1]\n\t"
"vmla.f32 q0, q14, d3[0]\n\t"
"vmla.f32 q0, q15, d3[1]\n\t"
"vstmia %2, { q0 }"
:
: "r" (mat), "r" (vec), "r" (result)
: "memory", "q0", "q1", "q8", "q9", "q10", "q11"
);
}
inline void Matrix4ByMatrix4(const float32x4x4_t* __restrict__ m1, const float32x4x4_t* __restrict__ m2, float32x4x4_t* __restrict__ r)
{
asm
(
"vldmia %1, { q0-q3 } \n\t"
"vldmia %2, { q8-q11 }\n\t"
"vmul.f32 q12, q8, d0[0]\n\t"
"vmul.f32 q13, q8, d2[0]\n\t"
"vmul.f32 q14, q8, d4[0]\n\t"
"vmul.f32 q15, q8, d6[0]\n\t"
"vmla.f32 q12, q9, d0[1]\n\t"
"vmla.f32 q13, q9, d2[1]\n\t"
"vmla.f32 q14, q9, d4[1]\n\t"
"vmla.f32 q15, q9, d6[1]\n\t"
"vmla.f32 q12, q10, d1[0]\n\t"
"vmla.f32 q13, q10, d3[0]\n\t"
"vmla.f32 q14, q10, d5[0]\n\t"
"vmla.f32 q15, q10, d7[0]\n\t"
"vmla.f32 q12, q11, d1[1]\n\t"
"vmla.f32 q13, q11, d3[1]\n\t"
"vmla.f32 q14, q11, d5[1]\n\t"
"vmla.f32 q15, q11, d7[1]\n\t"
"vstmia %0, { q12-q15 }"
:
: "r" (result), "r" (m2), "r" (m1)
: "memory", "q0", "q1", "q2", "q3", "q8", "q9", "q10", "q11", "q12", "q13", "q14", "q15"
);
}
Intrinsic Method:
inline void Matrix4ByVec4(float32x4x4_t* __restrict__ mat, const float32x4_t* __restrict__ vec, float32x4_t* __restrict__ result)
{
(*result) = vmulq_n_f32((*mat).val[0], (*vec)[0]);
(*result) = vmlaq_n_f32((*result), (*mat).val[1], (*vec)[1]);
(*result) = vmlaq_n_f32((*result), (*mat).val[2], (*vec)[2]);
(*result) = vmlaq_n_f32((*result), (*mat).val[3], (*vec)[3]);
}
inline void Matrix4ByMatrix4(const float32x4x4_t* __restrict__ m1, const float32x4x4_t* __restrict__ m2, float32x4x4_t* __restrict__ r)
{
(*r).val[0] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[0], 0));
(*r).val[1] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[1], 0));
(*r).val[2] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[2], 0));
(*r).val[3] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[3], 0));
(*r).val[0] = vmlaq_n_f32((*r).val[0], (*m1).val[1], vgetq_lane_f32((*m2).val[0], 1));
(*r).val[1] = vmlaq_n_f32((*r).val[1], (*m1).val[1], vgetq_lane_f32((*m2).val[1], 1));
(*r).val[2] = vmlaq_n_f32((*r).val[2], (*m1).val[1], vgetq_lane_f32((*m2).val[2], 1));
(*r).val[3] = vmlaq_n_f32((*r).val[3], (*m1).val[1], vgetq_lane_f32((*m2).val[3], 1));
(*r).val[0] = vmlaq_n_f32((*r).val[0], (*m1).val[2], vgetq_lane_f32((*m2).val[0], 2));
(*r).val[1] = vmlaq_n_f32((*r).val[1], (*m1).val[2], vgetq_lane_f32((*m2).val[1], 2));
(*r).val[2] = vmlaq_n_f32((*r).val[2], (*m1).val[2], vgetq_lane_f32((*m2).val[2], 2));
(*r).val[3] = vmlaq_n_f32((*r).val[3], (*m1).val[2], vgetq_lane_f32((*m2).val[3], 2));
(*r).val[0] = vmlaq_n_f32((*r).val[0], (*m1).val[3], vgetq_lane_f32((*m2).val[0], 3));
(*r).val[1] = vmlaq_n_f32((*r).val[1], (*m1).val[3], vgetq_lane_f32((*m2).val[1], 3));
(*r).val[2] = vmlaq_n_f32((*r).val[2], (*m1).val[3], vgetq_lane_f32((*m2).val[2], 3));
(*r).val[3] = vmlaq_n_f32((*r).val[3], (*m1).val[3], vgetq_lane_f32((*m2).val[3], 3));
}
I did a test on iPod Touch 4. The table contains the profiling results of the Update function:
| An approach | Execution time, ms | CPU load,% |
|---|---|---|
| FPU | 6058 + 5067 * | 35-38 |
| GLKMath | 2789 | 20-23 |
| Assembler | 5304 | 23-25 |
| Intrinsic | 2803 | 18-20 |
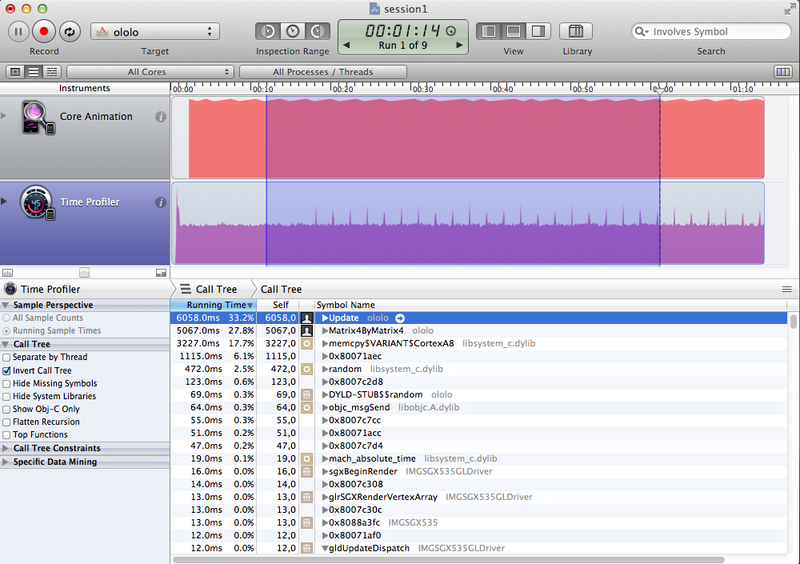{kind=link}
Here's another tip - aggressively inline your performance-critical code. Prefer __attribute __ ((always_inline)) over regular inline in such cases.
Updated Results Table:
| An approach | Execution time, ms | CPU load,% |
|---|---|---|
| FPU forceinlined | 6209 | 25-28 |
| GLKMath | 2789 | 20-23 |
| Assembler | 5304 | 23-25 |
| Intrinsic | 2803 | 18-20 |
Final table of results:
| An approach | Execution time, ms | Execution time (vector), ms | CPU load,% | CPU load (vector),% |
|---|---|---|---|---|
| FPU forceinlined | 6209 | 5028 | 25-28 | 22-24 |
| GLKMath | 2789 | 2776 | 20-23 | 20-23 |
| Assembler | 5304 | 5291 | 23-25 | 22-24 |
| Intrinsic | 2803 | 2789 | 18-20 | 18-20 |
Quite strange results can be observed in the case of assembler and intrinsics - in fact the code is the same, but the result differs dramatically - almost 2 times! The answer to this question lies in assembly listing (those who want to take a look themselves). In the case of the assembler, we see exactly what we wrote in the listing. In the case of intrinsics, the compiler optimized the code. Slow, at first glance, the GLKMath code compiler perfectly optimized, which gave the same code execution time as the manually written intrinsics.
Screenshot Results
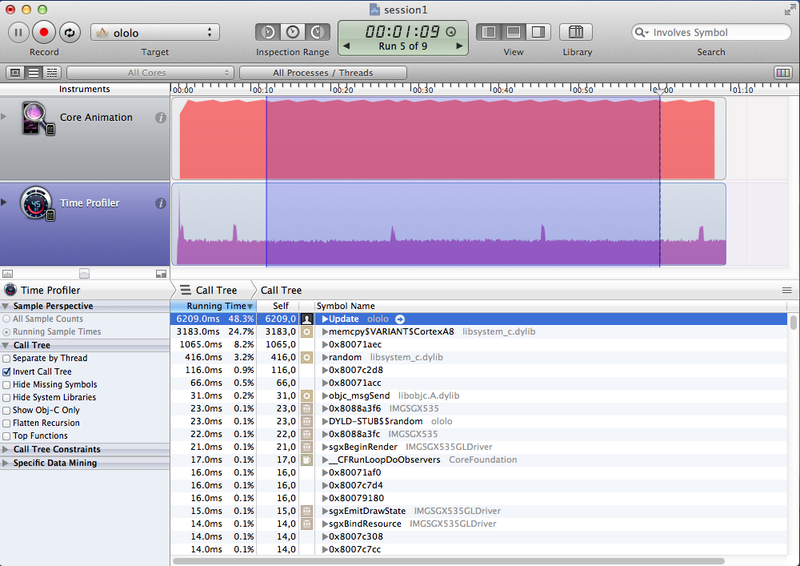{kind=link}
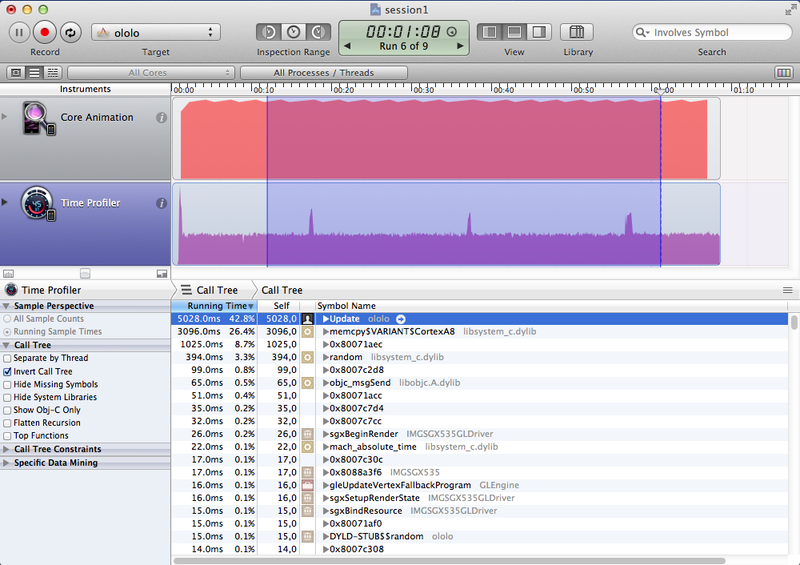{kind=link}
{kind=link}
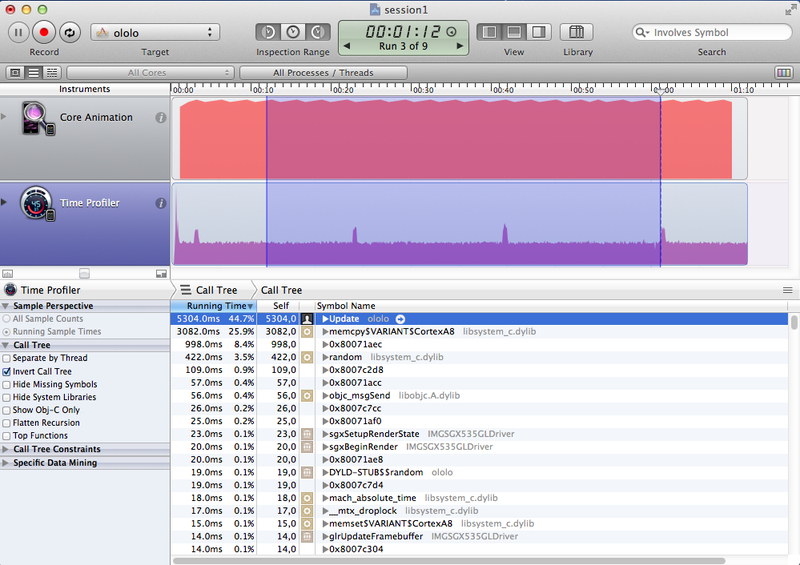{kind=link}
{kind=link}
It is time to take stock. Several conclusions can be drawn:
- The engineers from the LLVM team did an excellent job. As a result, the compiler generates well-optimized intrinsic code. I did a similar test more than a year ago when the only compiler in Xcode was GCC 4.2 and it produced a very bad result - only 10-15% of the performance gain compared to FPU code. This is great news - there is no need to learn assembler and I am incredibly happy about it!
- The clang compiler can auto-vectorize code. For a programmer, this is a performance bonus by writing just 4 words. What else can I say except that this is a cool thing ?!
- NEON code gives a very good boost in performance compared to regular C code - 2.22 times! As a result of the optimization done, vertex processing has become faster than copying these very vertices to the GPU side! If you look at the memcpy assembler, you can see that NEON code is also used there. The lack of hardware mopping in the Cortex A8 seems to be the reason for the slower code.
- Learning all these low level things is worth the time, especially if your goal is to become a professional.
References
www.arm.com/products/processors/technologies/neon.phpblogs.arm.com/software-enablement/161-coding-for-neon-part-1-load-and-stores
code.google.com/p/ math-neon
llvm.org/devmtg/2012-04-12/Slides/Hal_Finkel.pdf
Demo project