Shogi AI (Japanese Chess)
There is one old Japanese shogi game . It is sometimes called Japanese chess. I will not argue that these games have something in common, but shogi is much more complicated. I first learned about this game from a comment on Habré, where it was argued that this is one of the most difficult games, and the best computer programs still cannot defeat the strongest human players. Of course, I became interested and started playing. Over the year, I achieved some success and even took second place among newcomers to the official tournament. Given my love of programming, the next step was obvious - write your own AI. This will be the story below.
I did not dare to immediately write AI for real shogi on the 9 by 9 field and decided to start with a simplified version of the game on the 5 by 5 field (this field is often used by beginners). If you read the full rules of the game on Wikipedia, then the following section will be much easier for you to understand.
Let's agree that from now on I will write "shogi", but imply a simplified version of the game on the 5 by 5 field.
The first thing to understand when learning a new game is the moves. Shogi has 10 different shapes. Designations of figures, their names and possible moves are presented in the table below:
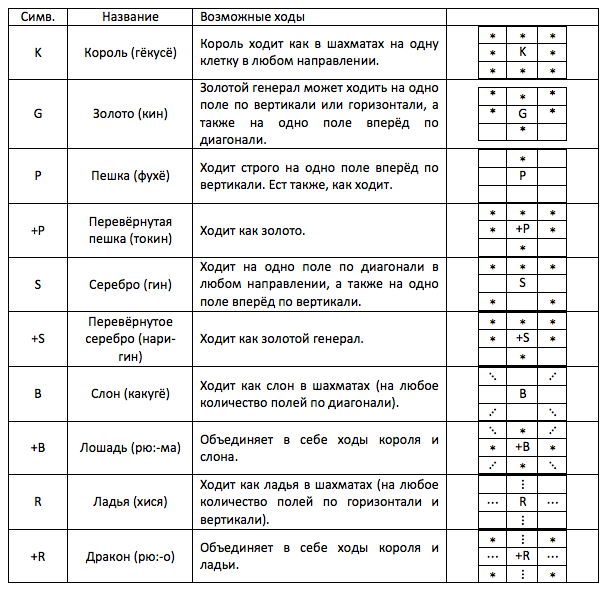
Surely you have noticed that among the figures there are “inverted doubles”, which are most often stronger than the original. The principle of amplification in shogi is similar to chess, but if in chess only a pawn turns and it turns into an arbitrary piece, then all pieces except gold and the king turn into shogi. To achieve a coup, you must start or end the move on the last horizontal of the enemy. In the general case, the coup is arbitrary: i.e. you can reach with the rook to the last horizontal line, but not turn it over, and the next move back to your camp with a coup (since you started the move on the last diagonal). Naturally, a pawn must roll over if it reaches the coup zone.
If you read up to this point, you may think that shogi is some kind of chess or checkers, but I assure you this is not so. Shogi has one nuance that immediately makes this game several orders of magnitude more difficult.
You can put any piece eaten by the opponent on any free field as your own. Such an action is called a discharge (although I personally prefer the word "space landing", which was first used by Andrei Vasnetsov in this context).
True, there are several limitations when resetting, but they are quite simple:
The reset rule may seem insignificant to you, but it radically changes the whole strategy of the game. If in chess or checkers it is enough to get a small material advantage, and then constantly go for exchanges and win the endgame, then in chess the exchanges lead to a more tense position and complicate the miscalculation.
The game takes place on a square field with a side of 5 cells. At the beginning of the game, the field looks like this:

For reasons unknown to me, the blacks are the first to start the shogi, and the white ones defend themselves. In order not to get confused with the terms, let's agree that the party starting the party is called Sente, and the defending party is Gote.
Before moving on to programming itself, one more important thing to note. There is no concept of shah in shogi, i.e. your king is threatened, you do not have to defend yourself or run away. You can very well start your attack. True, the next move is likely to eat your king, and the game will end.
The entry turned out to be quite long, but believe me, you could not do without it. Once upon a time I already wrote a post on the hub about game trees. The main advantage of game trees is that they can be applied to any game: tic-tac-toe, drafts, chess, and even shogi. Let's try to recall the main ideas.
Let us play shogi and at some point on the board an interesting position has arisen in which we need to find the best move for sente. Because the computer is essentially a stupid performer, we can order it to sort through all the possible moves and evaluate them. Then the move with the highest rating will be the best move. But we still don’t know how to evaluate the moves.
Here you can make a small digression and notice that if sente has an advantage in conventional units in a certain position, then Goths in this position lose conventional units. It turns out that the function of evaluating the position both from the side of sente and from the side of the gote will give the same modulo result, and the difference will be only in the sign.
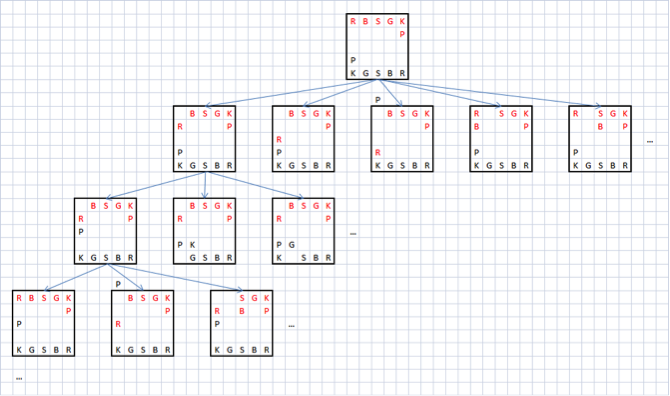
Then, the estimate of each move for sente can be obtained by inverting the estimate of the best response move for the gote. And an estimate of the best move for a goth is obtained by evaluating the best return move for sente, etc. Those. it turns out that the progress evaluation function is essentially recursive. These recursive positional evaluations should ideally continue until the game ends with a mat in each branch of the tree. The figure below shows a small part of the game tree that occurs when playing shogi:
Obviously, this tree grows extremely fast. Even for tic-tac-toe, a complete tree will contain more than a quarter of a million nodes, to say nothing of chess and shogi. In real algorithms, the recursion depth is artificially limited, and if the maximum recursion depth is reached, then the function of static position estimation is called, which, for example, simply calculates the material advantage. Thus, the best move search function can be written as follows:
It is clear that this algorithm does not give a complete position estimate, but only an estimate of the position that will arise through the Depth of moves. Therefore, if it is necessary to strengthen the game of the program, first of all, it is necessary to increase the depth of the recursion, and this in turn leads to an increase in the tree, and therefore to an increase in the counting time.
In fact, there is an algorithm that allows you to sort out not the whole tree, but only a small part of it, and at the same time give estimates of the same accuracy as with full enumeration. This algorithm is called alpha beta clipping.
The basis of the algorithm is the idea that some branches of a tree can be considered inefficient even before they are fully considered. For example, if the evaluating function in some node is guaranteed worse than in the previously considered branches, then consideration of this node can be stopped ahead of schedule.
Such a situation arises in the following cases: let us consider a position behind sente, and, having examined, some branch will receive an assessment of the position. Then, in the depths of the tree, when considering another possible move, we noticed that the score for White became greater than or equal to the previously obtained maximum. Obviously, there is no point in looking further at this node, and all branches emerging from it will not bring any improvement in position.
You may already have noticed that this algorithm allows you to cut branches only if a better move has been considered earlier. If we assume that when viewing all the moves were checked in sequence from worst to best, then the alpha-beta algorithm will not give any gain in comparison with exhaustive search. If at the beginning the best moves were considered, then the alpha-beta algorithm instead of a full tree of N nodes will consider only the root of N nodes, with the same accuracy of the estimate.
The main problem is that it is impossible to determine in advance which moves are actually good and which turn out to be bad. In this case, you have to resort to heuristics. If, when evaluating a position, only material advantage is taken into account, then it makes sense to be the first to consider taking moves. Moreover, it makes sense in the first place to consider those moves where a heavy figure is taken as a light one. In addition, inverted pieces play a huge role in shogi, so for preliminary coup moves, you can also increase the preliminary heuristic score.
Speaking of coups. It is important to understand that if a coup is possible, it does not always have to be done. For example, at the end of the game, silver that can sideways retreat is sometimes more effective than gold, which is much less maneuverable when retreating. But for pawns, rooks and bishops, a coup is always carried out, because a coup leaves all the original moves and adds new ones.
As a result, after all the moves have been generated and their heuristic evaluation has been carried out, it is necessary to sort them by this evaluation, and submit an alpha-beta algorithm that looks something like this:
As a result, I wrote a small program ( download ), which, in my opinion, plays shogi quite well. Of course, it is far from perfect, and there are many things in it that require correction and refinement. It would be nice to add moves - threats to the king in a heuristic assessment, it would be great to finalize the program and teach it how to play full-fledged shogi, but all these are plans for the future, but for now you can try your hand at this interesting game.
I did not dare to immediately write AI for real shogi on the 9 by 9 field and decided to start with a simplified version of the game on the 5 by 5 field (this field is often used by beginners). If you read the full rules of the game on Wikipedia, then the following section will be much easier for you to understand.
Rules of the game
Let's agree that from now on I will write "shogi", but imply a simplified version of the game on the 5 by 5 field.
Figures
The first thing to understand when learning a new game is the moves. Shogi has 10 different shapes. Designations of figures, their names and possible moves are presented in the table below:
Coups
Surely you have noticed that among the figures there are “inverted doubles”, which are most often stronger than the original. The principle of amplification in shogi is similar to chess, but if in chess only a pawn turns and it turns into an arbitrary piece, then all pieces except gold and the king turn into shogi. To achieve a coup, you must start or end the move on the last horizontal of the enemy. In the general case, the coup is arbitrary: i.e. you can reach with the rook to the last horizontal line, but not turn it over, and the next move back to your camp with a coup (since you started the move on the last diagonal). Naturally, a pawn must roll over if it reaches the coup zone.
Discharges
If you read up to this point, you may think that shogi is some kind of chess or checkers, but I assure you this is not so. Shogi has one nuance that immediately makes this game several orders of magnitude more difficult.
You can put any piece eaten by the opponent on any free field as your own. Such an action is called a discharge (although I personally prefer the word "space landing", which was first used by Andrei Vasnetsov in this context).
True, there are several limitations when resetting, but they are quite simple:
- All figures are reset unverted;
- If you drop a piece into the coup zone, then it can roll over only after it makes a move;
- You cannot fold a pawn to a vertical where your pawn already exists (the token is not considered a pawn);
- You cannot drop a pawn to the last horizontal;
- You cannot fold a pawn with a checkmate.
The reset rule may seem insignificant to you, but it radically changes the whole strategy of the game. If in chess or checkers it is enough to get a small material advantage, and then constantly go for exchanges and win the endgame, then in chess the exchanges lead to a more tense position and complicate the miscalculation.
Sequence of moves and initial placement
The game takes place on a square field with a side of 5 cells. At the beginning of the game, the field looks like this:
For reasons unknown to me, the blacks are the first to start the shogi, and the white ones defend themselves. In order not to get confused with the terms, let's agree that the party starting the party is called Sente, and the defending party is Gote.
Before moving on to programming itself, one more important thing to note. There is no concept of shah in shogi, i.e. your king is threatened, you do not have to defend yourself or run away. You can very well start your attack. True, the next move is likely to eat your king, and the game will end.
Game programming
The entry turned out to be quite long, but believe me, you could not do without it. Once upon a time I already wrote a post on the hub about game trees. The main advantage of game trees is that they can be applied to any game: tic-tac-toe, drafts, chess, and even shogi. Let's try to recall the main ideas.
Search Trees
Complete search of game trees
Let us play shogi and at some point on the board an interesting position has arisen in which we need to find the best move for sente. Because the computer is essentially a stupid performer, we can order it to sort through all the possible moves and evaluate them. Then the move with the highest rating will be the best move. But we still don’t know how to evaluate the moves.
Here you can make a small digression and notice that if sente has an advantage in conventional units in a certain position, then Goths in this position lose conventional units. It turns out that the function of evaluating the position both from the side of sente and from the side of the gote will give the same modulo result, and the difference will be only in the sign.
Then, the estimate of each move for sente can be obtained by inverting the estimate of the best response move for the gote. And an estimate of the best move for a goth is obtained by evaluating the best return move for sente, etc. Those. it turns out that the progress evaluation function is essentially recursive. These recursive positional evaluations should ideally continue until the game ends with a mat in each branch of the tree. The figure below shows a small part of the game tree that occurs when playing shogi:
Enumeration of game trees with a limited depth of recursion
Obviously, this tree grows extremely fast. Even for tic-tac-toe, a complete tree will contain more than a quarter of a million nodes, to say nothing of chess and shogi. In real algorithms, the recursion depth is artificially limited, and if the maximum recursion depth is reached, then the function of static position estimation is called, which, for example, simply calculates the material advantage. Thus, the best move search function can be written as follows:
function SearchBestMove (Depth: byte; color: TColor): real;
var
r, tmpr: real;
i, N: word;
Moves: TAMoves;
begin
if Depth = 0 then
r: = EstimatePos
else
begin
real: = - 100000;
N: = GenerateAllMoves (Moves);
for i: = 1 to N do
begin
Make the move Moves [i];
tmpr: = - SearchBestMove (Depth-1, opcolor (color));
Cancel the move Moves [i];
if tmpr> r then
r: = tmpr;
end;
end;
SearchBestMove: = r;
end;
It is clear that this algorithm does not give a complete position estimate, but only an estimate of the position that will arise through the Depth of moves. Therefore, if it is necessary to strengthen the game of the program, first of all, it is necessary to increase the depth of the recursion, and this in turn leads to an increase in the tree, and therefore to an increase in the counting time.
Alpha beta clipping
In fact, there is an algorithm that allows you to sort out not the whole tree, but only a small part of it, and at the same time give estimates of the same accuracy as with full enumeration. This algorithm is called alpha beta clipping.
The basis of the algorithm is the idea that some branches of a tree can be considered inefficient even before they are fully considered. For example, if the evaluating function in some node is guaranteed worse than in the previously considered branches, then consideration of this node can be stopped ahead of schedule.
Such a situation arises in the following cases: let us consider a position behind sente, and, having examined, some branch will receive an assessment of the position. Then, in the depths of the tree, when considering another possible move, we noticed that the score for White became greater than or equal to the previously obtained maximum. Obviously, there is no point in looking further at this node, and all branches emerging from it will not bring any improvement in position.
You may already have noticed that this algorithm allows you to cut branches only if a better move has been considered earlier. If we assume that when viewing all the moves were checked in sequence from worst to best, then the alpha-beta algorithm will not give any gain in comparison with exhaustive search. If at the beginning the best moves were considered, then the alpha-beta algorithm instead of a full tree of N nodes will consider only the root of N nodes, with the same accuracy of the estimate.
Sorting moves
The main problem is that it is impossible to determine in advance which moves are actually good and which turn out to be bad. In this case, you have to resort to heuristics. If, when evaluating a position, only material advantage is taken into account, then it makes sense to be the first to consider taking moves. Moreover, it makes sense in the first place to consider those moves where a heavy figure is taken as a light one. In addition, inverted pieces play a huge role in shogi, so for preliminary coup moves, you can also increase the preliminary heuristic score.
Speaking of coups. It is important to understand that if a coup is possible, it does not always have to be done. For example, at the end of the game, silver that can sideways retreat is sometimes more effective than gold, which is much less maneuverable when retreating. But for pawns, rooks and bishops, a coup is always carried out, because a coup leaves all the original moves and adds new ones.
As a result, after all the moves have been generated and their heuristic evaluation has been carried out, it is necessary to sort them by this evaluation, and submit an alpha-beta algorithm that looks something like this:
function AB (POS: TRPosition; color: TColor; Depth: byte; A, B: real): real;
var
Moves: TAMoves;
i, MovesCount: byte;
OLDPos: TRPosition;
begin
MovesCount: = 0;
if (Depth = 0) or Mate (POS.HandSente, POS.HandGote, color) then
A: = EstimatePos
else
begin
if color = sente then
MovesCount: = GenerateMoves (POS.Board, color, POS.HandSente, Moves)
else
MovesCount : = GenerateMoves (POS.Board, color, POS.HandGote, Moves);
for i: = 1 to MovesCount do
begin
if A> = B then
Break;
OLDPOS: = POS;
MakeMove (POS, Color, Moves [i]);
Moves [i] .r: = - AB (POS, opcolor (color), Depth-1, -B, -A);
POS: = OLDPos;
if Moves [i] .r> A then
A: = Moves [i] .r;
end;
end;
AB: = A;
end;
Final implementation
As a result, I wrote a small program ( download ), which, in my opinion, plays shogi quite well. Of course, it is far from perfect, and there are many things in it that require correction and refinement. It would be nice to add moves - threats to the king in a heuristic assessment, it would be great to finalize the program and teach it how to play full-fledged shogi, but all these are plans for the future, but for now you can try your hand at this interesting game.