Fear and Loath Threat Intelligence or 8 TI Practical Tips

We had two commercial APT subscriptions, ten information exchanges, about ten free feeds, and a Torah exit-node list. And also heels of strong reversers, master powershell scripts, loki-scanner and paid subscription to virustotal. Not that without this the monitoring center does not work, but if you are used to catching complex attacks, then you have to go to this hobby to the end. Most of all, we were worried about the potential automation of checking for indicators of compromise. There is nothing more immoral than artificial intelligence, replacing a person at work, where you have to think. But we understood that with an increase in the number of customers, sooner or later we will plunge into it.
Many say that Threat Intelligence is tasty, but not everyone fully understands how to prepare it. Even fewer of those who understand what processes need to be built for TI to work and bring profit. And very few people know how to choose a feed provider, where to check the indicator for fols, and whether it is necessary to block the domain that the colleague sent to WhatsApp.
For several years of constant work with TI, we managed to go through different rakes and today we want to give some practical tips that will help newcomers avoid mistakes.
Council number 1. Do not feed high hopes to catch something in the hash: most of the malware has long been polymorphic
In the last article, we talked about what TI is and gave a few examples of how the work process is organized. Let me remind you that information about threats (threat intelligence) comes in different formats and views: these can be both IP addresses of botnet control centers, email addresses of senders of phishing emails, and articles describing circumvention techniques that APT groups have -He will begin to use. In general, a lot of things happen.
To streamline all this mess, a few years ago, David Bianco proposed the so-called "pyramid of pain . " It describes quite well the relationship between the types of indicators that you use to detect an attacker and how much pain you give an attacker if you can detect a specific type of indicator.
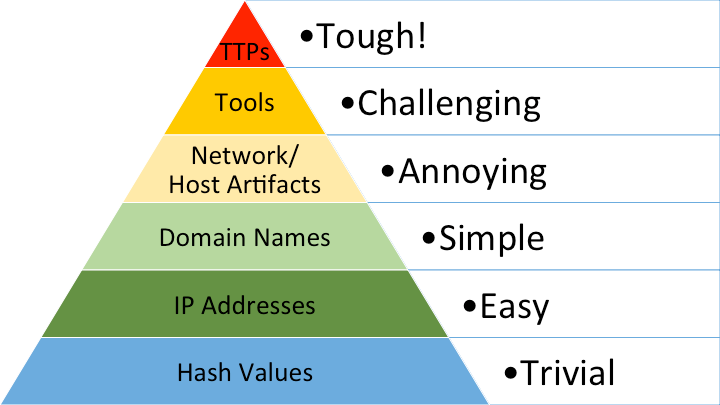
For example, if you know the MD5 hash of a malicious file, it can be quite easily and accurately detected. However, this will bring very little pain to the attacker - just add 1 bit of information to the file, and the hash is different.
Council number 2. Try to use those indicators, the change of which will be technically difficult or uneconomical for an attacker.
Anticipating the question of how to find out if there is a file with this hash on the workstations of our enterprise, I answer: there are different ways. One of the easiest is to install Kaspersky Security Center, which contains the database of MD5 hashes of all executable files in an enterprise, to which you can make a SELECT.
Let's go back to the pyramid of pain. In contrast to hash detection, it will be more productive if you can detect the attacker's TTP (tactics, technique, procedure). It is more complicated and requires more effort, but then you will deliver more pain.
For example, if you know that the APT-group, aimed at your sector of the economy, distributes phishing emails with * .HTA files, developing a detection rule that searches for files in mail with similar attachments will hit the attacker a lot. He will have to change the tactics of mailing, perhaps even by investing hard-earned $ in the purchase of 0-day or 1-day exploits, but this is not cheap ...
Council number 3. Do not have high hopes regarding the detection rules that you did not develop, you will have to check for false positives and refine

When designing detection rules, there is always a temptation to use ready-made rules. A free example is the Sigma repository - a SIEM-independent format of detection rules, which allows translating rules from the Sigma language into ElasticSearch requests and Splunk or Arcsight rules. At the same time, the repository contains about 200 rules, of which ~ 130 describe attacks on Windows. At first glance, very cool, but the devil, as always, in the details.
Let's take a closer look at one of the rules for detecting mimikatz:
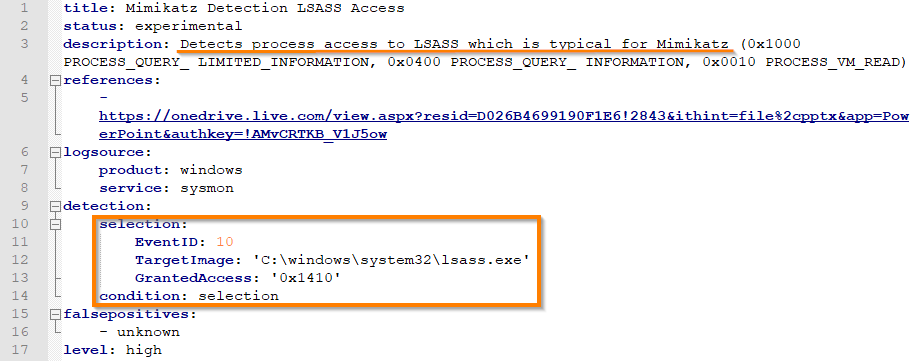
The rule detects processes that have attempted to read the memory of the lsass.exe process. Mimikatz does this when trying to get NTLM hashes, and the rule detects the malware.
However, we, as specialists who deal not only with detection, but also with incident response, it is extremely important that this really be a mimikatz. Unfortunately, in practice there are many other legitimate processes that read lsass.exe memory with the same masks (some antiviruses, for example). Therefore, in a real combat environment, such a rule will bring more false positives than good.
There are even more interesting incidents associated with the automatic translation of rules from Sigma to SIEM rules:

At one of the webinars, colleagues from SOC Prime, who supply paid detection rules, showed a non-working example of such a translation: the deviceProduct field in the SIEM should be equal to both Sysmon and Microsoft Windows, which is impossible.
I do not want to blame anyone and poke a finger - everyone folsyat, this is normal. However, Threat Intelligence consumers need to understand that re-checking and refinement of the rules obtained from both public and private sources is still necessary.
Tip # 4. Check domain names and IP addresses for damage not only on the proxy server and the firewall, but also in the DNS server logs, paying attention to both successful and unsuccessful resolution attempts.
Malicious domains and IP addresses are the best indicator in terms of ease of detection and the amount of pain you give an attacker. But with them, everything is simple only at first glance. At a minimum, it is worth wondering where to get the domain log.
If we confine ourselves to checking only the proxy server logs, you can miss out on malicious software that tries to contact the network directly or requests a non-existent domain name generated via DGA, not to mention DNS tunnels - all this will not be in the corporate proxy logs.
Council number 5. “Monitor cannot be blocked” - put a comma only after you have learned what kind of indicator it is and you have realized the possible consequences of blocking

Before each practitioner by the security officer there was a difficult question: to block the threat or monitor and, if there are any signs of trouble, start an investigation? In some regulations and instructions they directly write - block, and sometimes this action is wrong.
If the indicator is the domain name used by the APT grouping, do not put it on the lock , but start monitoring. Modern tactics of targeted attacks imply the presence of an additional covert backup communication channel, which can only be revealed during a detailed investigation. Automatic blocking in this case will impede the search for this channel, and comrades on the other side of the barricades will quickly understand what you have learned about their activities.
On the other hand, if the indicator is an encryption domain, then it is alreadyIt is worth putting on the lock . But do not forget to monitor unsuccessful attempts to contact blocked domains - several management server addresses can be embedded in the cryptographer configuration. Some of them may be missing in the feeds and, accordingly, will not be blocked. Sooner or later, the malware will contact them to obtain the key, which will instantly encrypt the host. To ensure that you have blocked all the addresses of the management server, only the sample can reverse-analyze.
Council number 6. Check all incoming indicators for relevance before putting them on monitoring or blocking.
Remember that information about threats is created by people who are prone to make mistakes, or machine learning algorithms, which suffer from it all the more. We have already witnessed how various providers of paid reports on the activities of APT-groups accidentally add quite legitimate samples to the lists of malicious MD5. Even if paid reports on threats contain poor-quality indicators, what can we say about indicators obtained by means of intelligence from open sources. TI analysts do not always check the indicators they create for false positives; as a result, such a check falls on the shoulders of the consumer.
For example, if you received the IP address of the next modification of Zeus or Dimnie, before using it in the detection systemscheck if it is part of the hosting or service that says your IP . Otherwise it will be unpleasant to disassemble a huge number of false positives, when users of the site hosted on this hosting will go to completely non-malicious sites. This check can be easily performed using:
- Categorization services that will tell you about the site’s activities. For example, ipinfo.io directly writes type: “hosting”.
- Reverse IP services that tell you how many domains are registered on this IP address. If a lot of them, with a high probability in front of you hosting sites.
So, for example, the result of testing the indicator, which is an indicator of the Cobalt APT-grouping (according to the report of a respected TI-vendor), looks like:
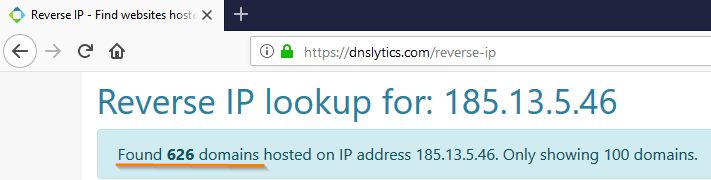
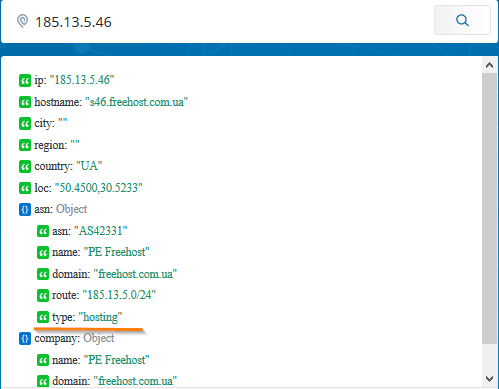
We, the response specialists, understand that the gentlemen from Cobalt must have used this IP address. However, there is no benefit from this indicator - it is irrelevant because it gives too many false positives.
Council number 7. Automate all the processes for dealing with information about threats. Start simple - fully automate testing for false positives through a stop-list with further setting of non-expansive indicators for monitoring in SIEM
Preventing a large number of false positives related to intelligence and obtained from open sources can be a preliminary search for these indicators in stop lists (warning lists). Such lists can be formed based on Alexa rating (top 1000), addresses of internal subnets, domains of major service providers like Google, Amazon AWS, MS Azure and other hosts. Also, a solution that dynamically changes stop-lists consisting of top domains / IP addresses visited by employees in the last week or month will be extremely effective.
Developing such lists and a verification system can be difficult for an average SOC, so it makes sense here to think about implementing so-called Threat Intelligence platforms. About half a year ago, Anti-malware.ru had a good review. paid and free solutions of this class.
Council number 8. Scan the host indicators for the entire enterprise, not just the hosts that are connected to the SIEM.
Due to the fact that, as a rule, not all enterprise hosts are connected to SIEM, it is not possible to check them for the presence of a malicious file with a specific name or path using only standard SIEM functionality. Get out of this situation in the following ways:
- Use IoC scanners like Loki . You can run it on all hosts of the enterprise through the same SCCM, and redirect the output to a shared network folder.
- Use vulnerability scanners. Some of them have compliance-regimes in which you can check the availability of a specific file for a specific path.
- Write the powershell script and run it through WinRM. If you write laziness yourself, you can use one of the numerous scripts, for example, this one .
As I said at the beginning, this article does not imply comprehensive information on how to work correctly with Threat Intelligence. However, in our experience, compliance with even these simple rules will allow beginners not to step on the rake and begin immediately with effective work with various indicators of compromise.