Machine learning security: effective protection methods or new threats?
One of the most popular and discussed news over the past few years has been - who has added artificial intelligence to where and what hackers have broken what and where. Having connected these topics, very interesting studies appear, and in Habré there have already been several articles devoted to the fact that there is an opportunity to deceive machine learning models, for example: an article about the limitations of deep learning , about how to embed neural networks . Further, I would like to consider in more detail this topic from the point of view of computer security:

Consider the following questions:
- Important terms.
- What is machine learning, if suddenly you still did not know.
- What does computer security have to do with it ?!
- Is it possible to manipulate a machine learning model to conduct a targeted attack?
- Is it possible to degrade system performance?
- Can I use the limitations of machine learning models?
- Categorization of attacks.
- Ways of protection.
- Possible consequences.
1. The first thing I would like to start with is terminology.
A possible statement may cause a large holivar from both the scientific and professional community due to several articles already written in Russian, but I would like to note that the term “adversarial intelligence” is translated as “enemy intelligence”. And the word “adversarial” itself would be worth translating not with the legal term “adversary”, but with a more appropriate term from the security “malicious” (there is no complaint about the translation of the name of the neural network architecture). Then all related terms in Russian acquire a much brighter meaning, such as “adversarial example” - a malicious instance of data, “adversarial settings” - a harmful environment. And the area itself, which we will consider “adversarial machine learning”, is harmful machine learning.
At least within the framework of this article such terms will be used in Russian. I hope, it will be possible to show that this topic is much more about security in order to fairly use terms from this particular area, and not the first example from the translator.
So, now that we are ready to speak the same language, we can begin as a matter of fact :)
2. What is machine learning, if suddenly you still did not know
Под методами машинного обучения обычно мы понимаем такие методы построения алгоритмов, которые способны обучаться и действовать без явного программирования их поведения на заранее подобранных данных. Под данными мы можем подразумевать все что угодно, если мы можем описать это какими-то признаками либо измерить. Если есть какой-то признак, который для части данных неизвестен, а нам он очень нужен, мы применяем методы машинного обучения, чтобы, основываясь на уже известных данных, этот признак восстановить или предсказать.
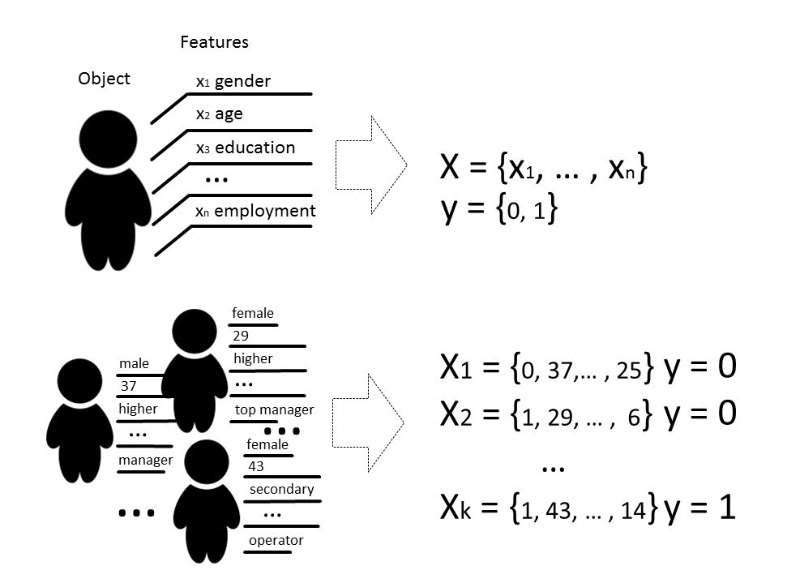
Существует несколько видов задач, которые решаются с помощью машинного обучения, но мы будем говорить по большей части о задаче классификации.
Классически цель стадии обучения модели классификатора — подобрать такую зависимость (функцию), которая покажет соответствие между признаками конкретного объекта и одним из известных классов. В более сложном случае требуется предсказание вероятности принадлежности к той или иной категории.
То есть задачей классификации является построение такой гиперплоскости, которая разделит пространство, где, как правило, его размерностью является размер вектора признаков, — чтобы объекты разных классов лежали по разные стороны от этой гиперплоскости.
Для двумерного пространства такая гиперплоскость это линия. Рассмотрим простой пример:

На рисунке можно увидеть два класса, квадраты и треугольники. Найти зависимость и наиболее точно разделить их линейной функцией невозможно. Поэтому с помощью машинного обучения можно подобрать такую нелинейную функцию, которая бы наилучшим образом разделяла эти два множества.
Задача классификации — довольно типичная задача обучения с учителем. Для обучения модели необходим такой набор данных, чтобы можно было выделить признаки объекта и его класс.
3. What does computer security have to do with it ?!
In computer security, various machine learning methods have long been used in spam filtering, traffic analysis, fraud or malware detection.
And in a sense, this is a game where, by making a move, you expect the reaction of the opponent. Therefore, while playing this game, one constantly has to correct models, teaching them with new data, or change them completely in view of the latest achievements of science.
For example, while antiviruses use signature-based analysis, heuristics and manual rules that are rather difficult to maintain and expand, the security industry still argues about the real benefits of antivirus and many consider antiviruses to be a dead product. Malefactors bypass all these rules, for example, by means of obfuscation and polymorphism. As a result, preference is given to tools that use more intelligent techniques, such as machine learning methods that allow you to automatically select features (even those that are not interpreted by humans), can quickly process large amounts of information, compile them and make decisions quickly.
That is, on the one hand, machine learning is used for protection as a tool. On the other hand, this tool is used for more intelligent attacks.
See if this tool can be vulnerable?
For any algorithm it is very important not only the selection of parameters, but also the data on which the algorithm is trained. Of course, in an ideal situation it is necessary that there is enough data for training, classes would be balanced, and the time for training will pass unnoticed, which in real life is almost impossible.
The quality of a trained model is usually understood as the classification accuracy for data that the model has not yet “seen”, in general - as a ratio of correctly classified data instances to the total amount of data that we transmitted to the model.
In general, all quality assessments are directly related to assumptions about the expected distribution of system input data and do not take into account harmful environmental conditions ( adversarial settings ), which often go beyond the expected distribution of input data. A malicious environment is an environment where there is an opportunity to confront or interact with the system. Typical examples of such environments are environments that use spam filters, fraud detection algorithms, malware analysis systems.
Thus, accuracy can be considered as a measure of the average performance of the system in its average use, while the safety assessment is interested in its worst performance.
That is, machine learning models are usually tested in a rather static environment where accuracy depends on the amount of data from each particular class, but in reality the same distribution cannot be guaranteed. And we are interested in the model being mistaken. Accordingly, our task is to find as many such vectors as possible that give an incorrect result.
When people talk about the security of a system or service, they usually imply that it is impossible to violate the security policy within a given threat model in hardware or software, trying to check the system both at the design stage and at the testing stage. But today, a huge number of services operate on the basis of data analysis algorithms, so the risks are hidden not only in vulnerable functionality, but also in the data itself, on the basis of which the system can make decisions.
No one stands still, and hackers are also learning something new. And the methods that help investigate machine learning algorithms for the possibility of compromise by an attacker who can use knowledge of how the model works are called adversarial machine learning , or in Russian, nevertheless, harmful machine learning .
If we talk about the safety of machine learning models from the point of view of information security, then I would like to consider a few questions conceptually.
4. Is it possible to manipulate the machine learning model to conduct a targeted attack?
Let's give a clear example with search engine optimization. People learn how intelligent search engine algorithms work and manipulate their site data to be higher in search rankings. The issue of the safety of such a system in this case is not so acute, as long as it does not compromise any data or cause serious damage.
An example of such a system is the services that basically use online model training, that is, such training, in which the model receives data in a sequential order to update the current parameters. Knowing how the system learns, you can plan the attack and submit to the system pre-prepared data.
For example, in this way biometric systems are deceived , which gradually update their parameters as small changes in a person’s appearance, for example, with a natural age change , which is an absolutely natural and necessary service functionality in this case. Using this property of the system, you can prepare the data and submit it to the biometric system, updating the model until it updates the parameters to another person. In this way, the attacker will retrain the model and be able to identify himself instead of the victim.

5. Can an attacker pick up such valid data that will always work incorrectly, which will lead to a deterioration in system performance to the extent that it will have to be disabled?
This problem arises quite naturally from the fact that the machine learning model is often tested in a fairly static environment, and its quality is assessed with the distribution of data on which the model was trained. At the same time, very often very specific questions are put to data analysts who need to be answered by the model:
- Is the file malicious?
- Does this transaction relate to fraud?
- Is current traffic legitimate?
And it is quite expected that the algorithm cannot be 100% accurate, it can only relate an object to some class with some probability, so you have to look for compromises in case of errors of the first and second kind, when our algorithm cannot be completely sure in his choice and still wrong.
Take a system that very often gives errors of the first and second kind. For example, the antivirus blocked your file because it considered it malicious (although this is not the case), or the antivirus missed the file that was malicious. In this case, the user of the system considers it to be ineffective and most often simply turns it off, although it is quite likely that a set of such data was simply caught.
And the data set, on which the model shows the result worst of all, always exists. And the task of the attacker becomes the search for such data to force the system to turn off. Such situations are rather unpleasant, and of course, the model should avoid them. And you can imagine the scale of the consequences of investigations of all false incidents!
Errors of the first kind are perceived as a waste of time, while errors of the second kind are perceived as a missed opportunity. Although in fact the cost of these types of errors for each particular system may be different. If the first kind of error can be cheaper for the antivirus, because it is better to be safe and say that the file is malicious, and if the client disconnects the system and the file really turns out to be malicious, then the antivirus “warns” and the responsibility remains on the user. If we take, for example, a system for medical diagnostics, then both errors will be quite expensive, because the patient in any of the cases is at risk of improper treatment and risk to health.
6. Can an attacker use the properties of the machine learning method to disrupt the system? That is, without interfering in the learning process, to find such limitations of the model, which deliberately give incorrect predictions.
It would seem that deep learning systems are practically protected from human intervention in the selection of signs, so one could say that there is no human factor in making any decisions by the model. The beauty of deep learning is that it is enough to submit practically “raw” data to the model input, and the model itself, through multiple linear transformations, selects features that it “considers” to be the most significant, and makes a decision. However, is it really that good?
There are works that describe the methods of preparing such malicious examples on the deep learning model, which the system classifies incorrectly. One of the few, but popular examples is the article on effective physical attacks on the deep learning model ( Robust Physical-World Attacks on Deep Learning Models ).
The authors have done experiments and suggested methods for circumventing models based on limiting in-depth training that deceive “vision” systems using the example of traffic sign recognition. For a positive result, it is enough for attackers to find such areas on the object that most knock down the classifier, and he is mistaken. The experiments were carried out on the “STOP” sign, which, thanks to the changes of the researchers, was qualified by the model as a “SPEED LIMIT 45” sign. They checked their approach on other signs and got a positive result.
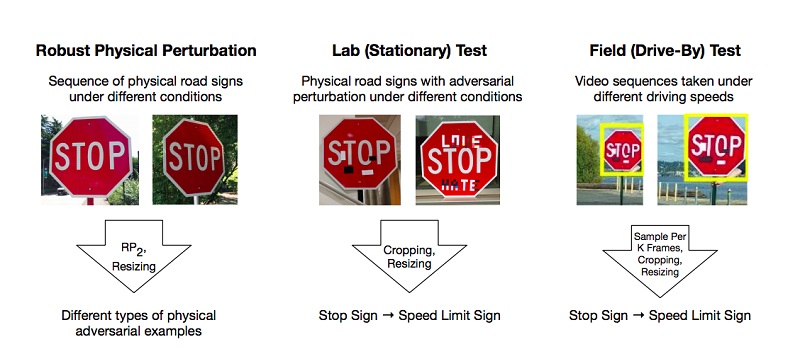
As a result, the authors proposed two ways by which you can deceive the machine learning system: Poster-Printing Attack, which involves a series of small changes around the perimeter of the sign, called camouflage, and Sticker Attacks, when some stickers were layered on a sign in certain areas.
But these are quite life situations - when a sign in the mud is from roadside dust or when young talents have left their creativity on it. It is likely that artificial intelligence and art have no place in one world.

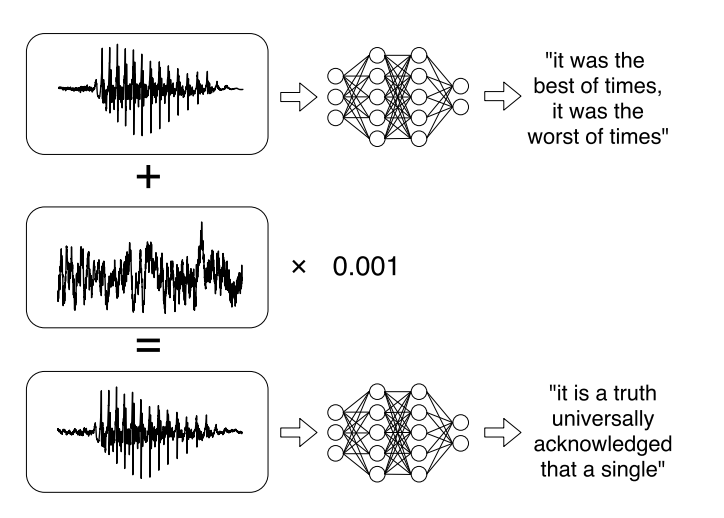
Or recent research on targeted attacks on automatic speech recognition systems . Voice messages have become quite a fashionable trend when communicating on social networks, but listening to them is not always convenient. Therefore, there are services that allow you to broadcast audio to text. The authors of the work learned to analyze the original audio, take into account the sound signal, and then learn how to create another sound signal that is 99% similar to the original, by adding a small change to it. As a result, the classifier decrypts the record as the attacker wants.
7. In this regard, it would be possible to categorize existing attacks in several ways :
By way of exposure (Influence):
- Causative attacks affect the learning of the model through interference with the training sample.
- Exploratory attacks use classifier errors without affecting the training set.
Security violation:
- Integrity attacks compromise the system through errors of the second kind.
- Availability attacks cause the system to shut down, usually based on errors of the first kind.
Specificity:
- Targeted attack (Targeted attack) is aimed at changing the prediction of the classifier to a particular class.
- Mass attack (Indiscriminate attack) is aimed at changing the response of the classifier to any class, except the correct one.
The purpose of security is to protect resources from an attacker and to comply with the requirements, the violation of which leads to partial or complete compromise of the resource.
Different machine learning models are used for security. For example, virus detection systems have the goal of reducing their exposure to viruses by detecting them before infecting the system, or to detect an existing one for removal. Another example is intrusion detection systems (IDS), which detect that a system has been compromised by detecting malicious traffic or suspicious behavior in the system. Another close task is intrusion prevention system (IPS), which detect intrusion attempts and prevent interference with the system.
In the context of security tasks, the goal of machine learning models is generally to separate malicious events and prevent them from interfering with the system.
In general, the goal can be divided into two:
integrity : to prevent an attacker from accessing system resources
availability : to prevent an intruder from interfering with normal operation.
Here is a clear connection between second-type errors and integrity violations: malicious instances that pass into the system can be detrimental. Also, errors of the first kind usually violate accessibility, since the system itself rejects valid data instances.
8. What are the ways to protect against intruders who manipulate machine learning models?
At the moment, it is more difficult to protect the machine learning model from malicious attacks than to attack it. Just because no matter how much we train the model, there is always a data set on which it will work the worst.
And today there are not enough effective ways to make the model work with 100% accuracy. But there are some tips that can make the model more resistant to malicious examples.
Here is the main one: if there is an opportunity not to use machine learning models in a malicious environment, it is better not to use them. There is no point in abandoning machine learning if you are faced with the task of classifying pictures or generating memes. Here it is hardly possible to cause any significant damage that would lead to some social or economically significant consequences in the event of an intentional attack. However, if the system is associated with performing really important functions, for example, diagnosing diseases, detecting attacks on industrial facilities or driving an unmanned vehicle, then, of course, the consequences of compromising the security of such a system can be catastrophic.
If we recall the simplified formulation of the classification problem that it is important for us to construct such a hyperplane that would divide the space into classes, then we can notice some contradiction. Let's draw an analogy on two-dimensional space.
On the one hand, we are trying to find a function that as accurately as possible will divide the two classes into different groups. On the other hand, we cannot build an exact line, because, as a rule, we do not have a general set of data, so our task is to find a function in which the classification error will be minimal. That is, on the one hand, we are trying to build an exact line, on the other hand, we are trying to avoid retraining on specific data that we have now, and yet predict the behavior of others.
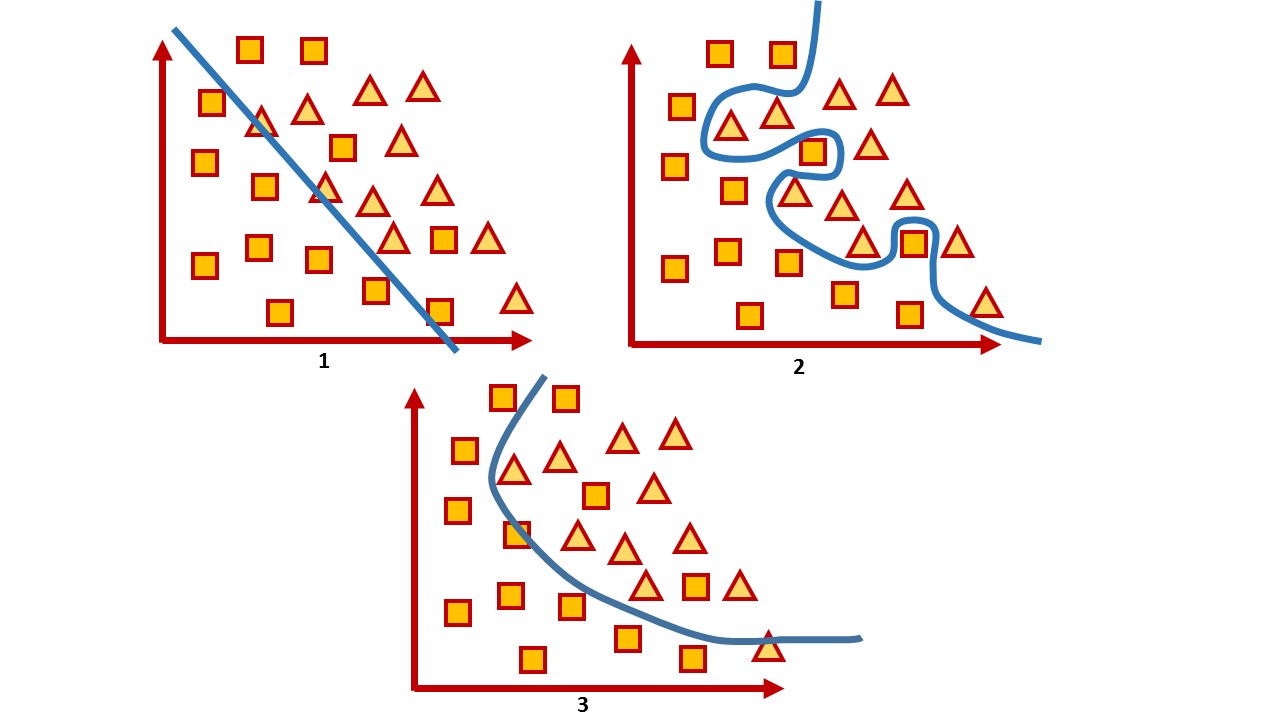
1 - under-training, 2 - re-training, 3 - the best option
How to deal with the under-training of the model seems to be understandable: most often this is an increase in the complexity of the model. For retraining apply regularization methods. In fact, they make the model more resistant to small emissions, but not to harmful examples.
The problem of misclassifying malicious examples is actually obvious. The model did not see such examples in its training set, so it will often be wrong. A fully working solution would be to supplement your training set with such malicious examples as to prevent yourself from being deceived by at least them. But to generate all possible malicious examples and get 100% accuracy is unlikely to succeed again due to the fact that we are trying to find a compromise between re-training on test data and under-training.
You can also use the generative-consensual neural network, which in its structure consists of two neural networks - the generative and discriminative. The task of the discriminative model is to learn how to distinguish fake data from real ones, and the task of the generative model is to learn how to generate such data in order to deceive the first model. Finding a compromise between the discriminator’s sufficient quality classification and its patience regarding the time it takes to learn, you can get a model that is quite resistant to harmful examples.
But despite the use of such methods, you can still pick up a set of data on which the model will make the wrong decision.
9. What are the potential security implications of machine learning?
There have long been debates about the responsibility of machine learning models for errors and for their social consequences. For the process of creating and operating such intelligent systems, several roles influencing the final result can be distinguished: those who develop the algorithm, who provide the data and those who exploit the system, being its owners in the end.
At first glance, it seems that the system developer has a huge impact on the final result. From the choice of a specific algorithm to the selection of parameters and testing. But in fact, the developer only makes some software that must meet the requirements. As soon as the model begins to comply with them, the work of the developer usually ends, and the model enters the stage of operation, where some “bugs” may appear.
On the one hand, this is due to the fact that, at the training stage, developers do not have the entire general set of data. But on the other hand, it may simply be from the data that is in reality. A very vivid example is the chat bot for Twitter, created by Microsoft, which as a result has been trained on real data and began to write racist tweets .
Is it still a bug or a feature? The algorithm learned from the data that he saw, and began to imitate them - it would seem that this is an amazing achievement of the developers, to which everyone was striving. On the other hand, the data turned out to be exactly as they were, therefore, from a moral point of view, this bot turned out to be unusable - simply because it learned so well to do what they wanted from it.
Perhaps Ilon Musk is right in asserting that “artificial intelligence is the greatest risk that we face as a civilization”?