Neyrobogurt. How we taught the neural network to invent memes a year earlier than Stanford
This article (+ research ) about the invention of the meme generator by scientists from Stanford University pushed me to write the article . In my article, I will try to show that you don’t need to be a Stanford scientist to do interesting things with neural networks. In the article, I describe how in 2017 we trained a neural network on a corpus of approximately 30,000 texts and forced it to generate new Internet memes and memes (communication signs) in a sociological sense of the word. We describe the machine learning algorithm we used, the technical and administrative difficulties that we encountered.
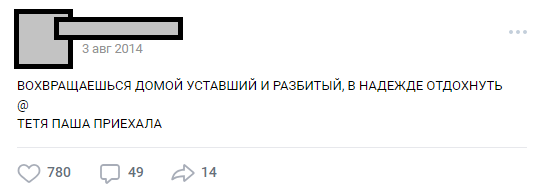
A little background on how we came to the idea of a neuropresenter and what exactly it was about. In 2017, we made a project for one “Vkontakte” public, the title and screenshots from which the Habrahabr moderators forbade publishing, considering its mention of “self” PR. Public exists since 2013 and combines posts with the general idea of decomposing humor through a line and separating lines with the “@” symbol: The number of lines can vary, the plot can be any one. Most often it is humor or sharp social notes about the infuriating facts of reality. In general, this design is called "buhurt". One of the typical buhurts
Over the years of its existence, the public was overgrown with internal lori (characters, plots, locations), and the number of posts exceeded 30,000. At the time of their parsing for the needs of the project, the number of source lines exceeded half a million.
In the wake of the mass popularity of neural networks, the idea of teaching the ANN on our texts soared in the air for about six months, but was finally formulated with the help of E7su in December 2016. Then the name was invented (“Neurobugurt”). At that time, the team interested in the project consisted of only three people. We were all students without practical experience in algorithms and neural networks. Worse, we didn’t even have any suitable GPUs for training. All we had was the enthusiasm and confidence that this story could be interesting.
Our hypothesis turned out to be the assumption that if you mix all the texts published for three and a half years and train a neural network on this corpus, you might get:
a) more creative than people
b) funny
Even if words or letters turn out to be machine-confused and located in bugurt chaotically - we believed that it could work as fan service and would still please the readers.
The task was greatly simplified by the fact that the format of buhurts is, in fact, textual. So, we did not need to dive into machine vision and other complex things. Another good news was that the whole corpus of texts is very homogeneous. This made it possible not to use reinforcement training — at least in the early stages. At the same time, we clearly understood that it was not so easy to create a neural network writer with a readable output more than once. The risk of having a monster that would randomly fling letters out was very high.
It is believed that the preparation stage can take a very long time, as it is associated with the collection and cleaning of data. In our case, it turned out to be quite short: a small parser was written , which pumped about 30k posts from the community wall and put them into a txt file .
We did not clear the data before the first training. Later, this played a cruel joke on us, because due to an error that had crept in at this stage, we could not bring the results into a readable form for a long time. But more about that a little further.
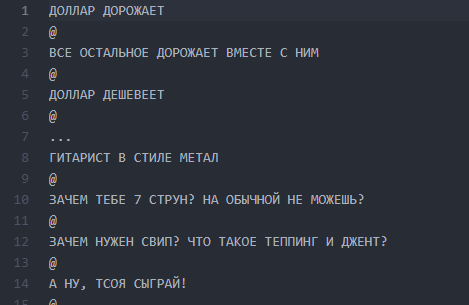
Screen file with burgers
We used the available resource - a huge number of public subscribers. The assumption was that among 300,000 readers there are several enthusiasts who own neural networks at a sufficient level to fill gaps in the knowledge of our team. We started from the idea of widely announcing the competition and attracting machine learning enthusiasts to discuss the formulated problem. Having written the texts, we told people about our idea and hoped for a response.
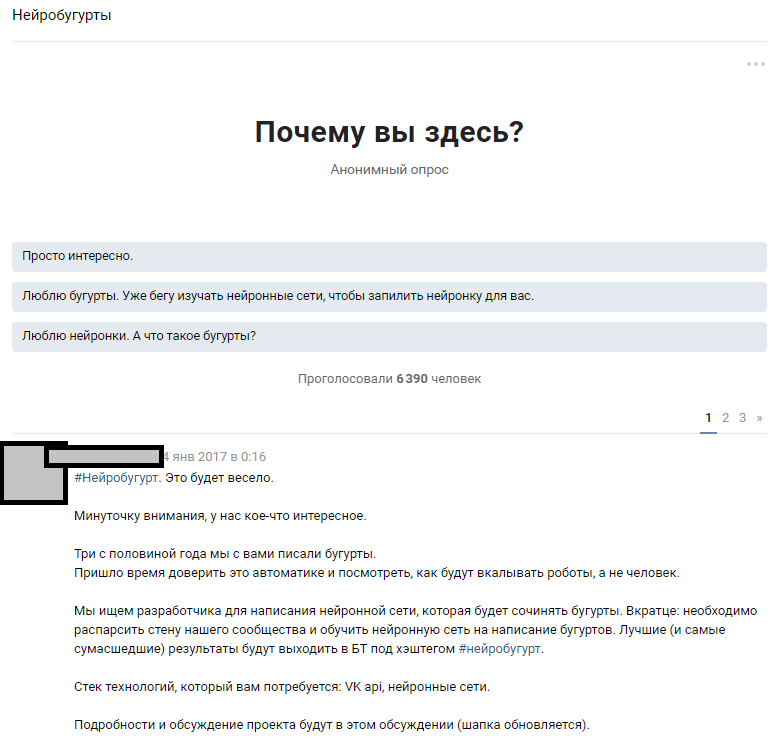
Announcement in thematic discussion
The reaction of people exceeded our wildest expectations. The discussion of the very fact that we are going to train a neural network spread a holivar with almost 1000 comments. Most of the readers simply went crazy and tried to imagine what the result would look like. About 6000 people looked into the thematic discussion, and the comments were left by more than 50 interested lovers, to whom we issued a test set of 814 lines of buhurts for conducting primary tests and training. Everyone interested could take a dataset and train the algorithm that is most interesting to him, and then discuss it with us and with other enthusiasts. We announced in advance that we will continue to work with those participants whose results will be the most readable.
The work began to spin: someone silently assembled a generator on Markov's chains, someone tried various implementations with a githab, and the majority simply faded away in discussion and foamed at the mouth to convince us that nothing would come of it. This started the technical part of the project.
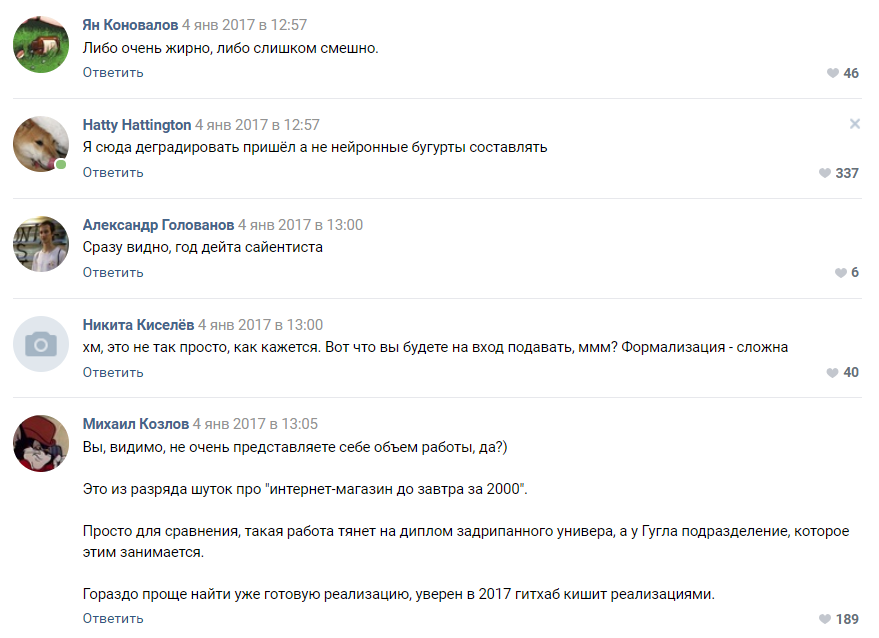
Some suggestions of enthusiasts.
People offered dozens of options for implementation:
Assessment of the complexity of the project from one of the subscribers
Most of the commentators agreed that our project is doomed to failure and we will not even reach the prototype stage. As we understood later, people are still prone to perceive neural networks as some kind of black magic that takes place in “Zuckerberg’s head” and secret divisions of Google.
After some time, the campaign for crowdsourcing ideas for the algorithm started by us began to yield the first results. We received about 30 working prototypes, most of which were absolutely unreadable nonsense.
At this stage, we first encountered the demotivation of the team. All the results were very weakly similar to buhurts and most often were an abracadabra of letters and symbols. The works of dozens of enthusiasts were ashes and this demotivated both them and us.
PyTorch based algorithm showed itself better than others. It was decided to base this implementation and the LSTM algorithm. We recognized the subscriber who offered it, the winner and started working on improving the algorithm together with him. Our distributed team has increased to four people. The funny thing here is thatthe winner of the competition , as it turned out, was only 16 years old. The victory was his first real prize in the field of Data Science.
For the first training, a cluster of 8 graphic cards was rented. GXT1080 Card Cluster
Management Console
The original repository and all the manuals for the Torch-rnn project are here:
github.com/jcjohnson/torch-rnn . Later, on its basis, we published our repository , in which there are our source codes, ReadMe for installation, as well as the ready neyuroburts themselves.
The first few times we learned using the pre-configured configuration on a paid GPU cluster. Setting it up was not so difficult - just instructions from the Torch developer and the help of the hosting administration, which is included in the payment.
However, very quickly we encountered a difficulty: every training was worth the time to rent a GPU - and therefore money, which the project simply did not have. Because of this, in January-February 2017, we conducted training on purchased capacities, and tried to start generation on our local machines.
Any text is suitable for learning the model. Before training, it must be preprocessing, for which Torch has a special algorithm preprocess.py, which converts your my_data.txt into two files: HDF5 and JSON:
The preprocessing script runs like this:
After preprocessing, two files appear on which the neural network will be further trained.
Various flags that can be changed at the preprocessing stage are described here . It is also possible to launch Torch from Docker , but the author of the article did not check it.
After preprocessing, you can proceed to the training model. In the folder with HDF5 and JSON, you need to run the th utility, which came to you if you installed Torch correctly:
Training takes a huge amount of time and generates files like cv / checkpoint_1000.t7, which are the weights of our neural network. These files weigh an impressive number of megabytes and contain the values of the strength of the connections between specific letters in your original dataset.
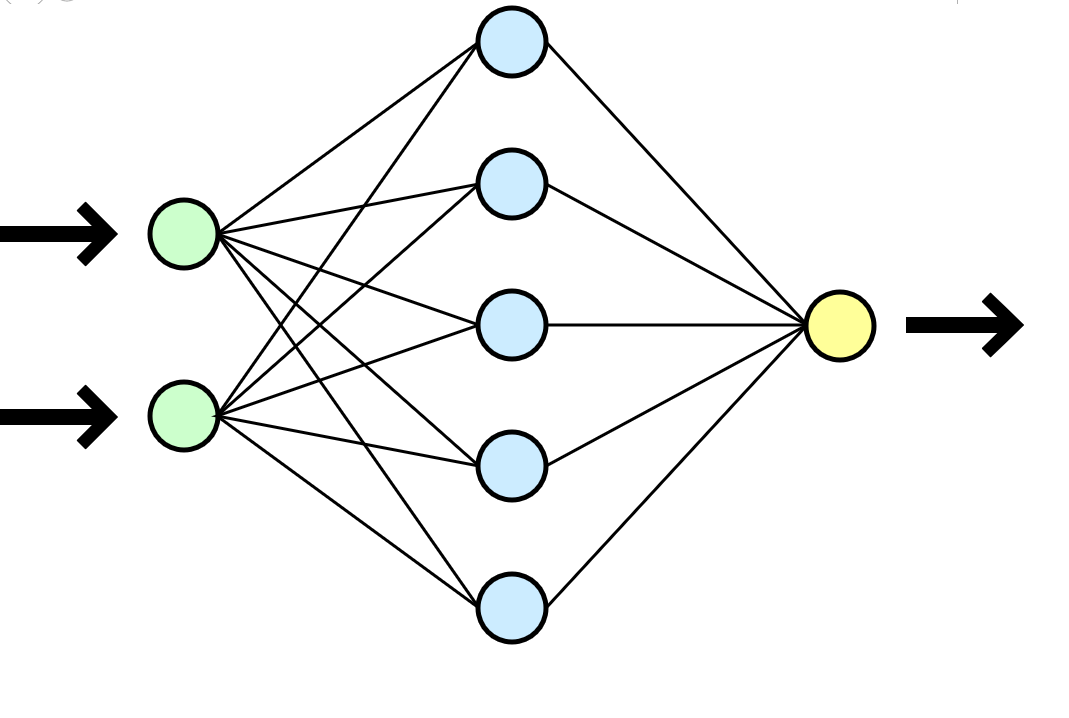
The neural network is often compared with the human brain, but it seems to me that the analogy with a mathematical function that takes input parameters (your data) and gives the result (new data) output is much more understandable.
In our case, each training on a cluster of 8 GTX 1080 in a 500,000-line data set took about an hour or two, and similar training on a used i3-2120 CPU took about 80-100 hours. In the case of longer trainings, the neural network began to retrain hard — the characters too often repeated each other, falling into long cycles from prepositions, conjunctions, and introductory words.
It is convenient that you can choose the frequency of the checkpoint placement and in the course of one training you can immediately get a lot of models: from the least trained (checkpoint_1000) to the retrained (checkpoint_1000000). Only space would be enough.
Having received at least one ready-made file with weights (checkpoint _ *******), you can proceed to the next and most interesting stage: start generating texts. For us, it was a real moment of truth, because for the first time we got some tangible result - a bugurt, written by a machine.
By this time, we finally stopped using the cluster and all the generations were performed on our low-power machines. However, when trying to start locally, just follow the instructions and install Torch, we did not succeed. The first barrier was the use of virtual machines. On a virtual Ubuntu 16, the stick just doesn't take off - forget it. StackOverflow often came to the rescue, but some errors were so nontrivial that the answer could only be found with great difficulty.
Installing Torch on a local machine stalled the project for a good couple of weeks: we encountered all sorts of installation errors for numerous necessary packages, and also struggled with virtualization (virtualenv .env) and eventually did not use it. Several times the stand was demolished to the level of sudo rm -rf and simply installed again.
Using the resulting file with weights, we were able to start generating texts on our local machine:

One of the first conclusions
Another obvious difficulty was that the topic of posts is very different, and our algorithm does not involve any division and considers all 500,000 lines as a single text. We considered various options for clustering datasets and were even ready to manually break the corpus of texts by subject or place tags on several thousand buhurts (there was a necessary human resource for this), but constantly faced with technical difficulties in presenting clusters in LSTM training. Changing the algorithm and holding a contest again seemed not the most sensible idea in terms of project timing and motivation of participants.
It seemed that we were at a dead end - we could not cluster bugurts, and learning on a single huge dataset gave a dubious result. To take a step back and change the algorithm that almost took off and the implementation didn’t want to either - the project could simply fall into a coma. The team desperately lacked the knowledge to solve the situation normally, but the good old SME-KAL-OCHK-A came to the rescue. The final solution of thecrutch turned out to be simple to genius: in the source dataset, separate existing buhurts from each other with empty lines and train LSTM again.
We placed the spacing in 10 vertical spaces after each buhurt, re-conducted training, and when generating set a limit on the output of 500 characters (the average length of one “plot” buhurth in the original dataset).
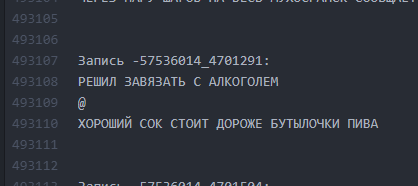
As it was. Intervals between texts are minimal.
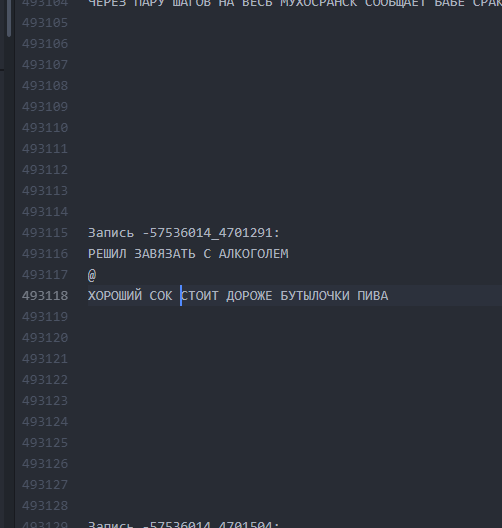
As it became. The 10-line intervals give LSTM to “understand” that one bugurt has ended and another has begun.
Thus, it was possible to achieve that about 60% of all generated buhurts began to have a readable (although often very delusional) storyline along the entire length of the buhurth from beginning to end. The length of one plot was, on average, from 9 to 13 lines.
Having estimated the economics of the project, we decided not to spend money on renting a cluster, but to invest in the purchase of our own cards. Training time would have increased, but having bought a card once, we could generate new buhurts all the time. At the same time, it was often unnecessary to conduct training constantly.
Fighting settings on a local machine
At the turn of March-April 2017, we re-trained the neural network, specifying the temperature parameters and the number of learning epochs. As a result, the quality of the output texts slightly increased.
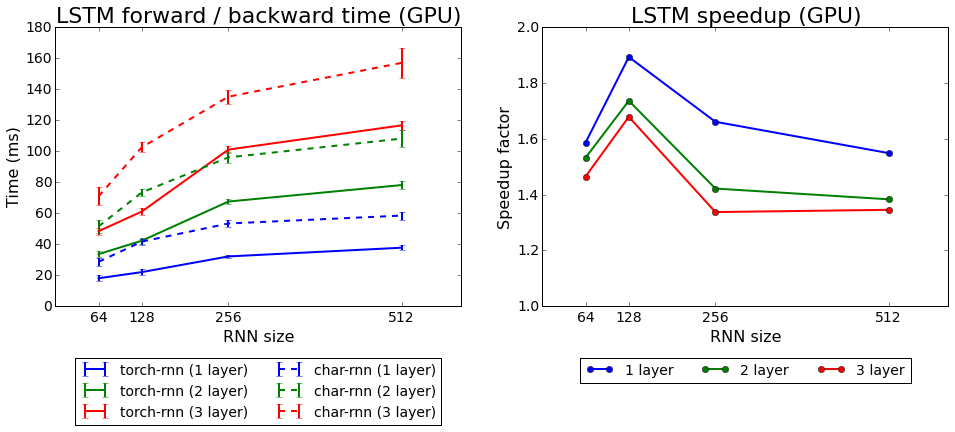
Learning speed torch-rnn versus char-rnn
We tested both algorithms that come with Torch: rnn and LSTM. The second showed itself better.
The first neurobugurt was published on January 17, 2017 — immediately after training in the cluster — and on the first day, more than 1000 comments were collected.

One of the first neurobugurts Neurobugurts
went so well to the audience that they became a separate section that for a year went out under the hashtag #neurobugurt and amused subscribers. In total, in 2017 and the beginning of 2018, we generated more than 18,000 neyrobugurts , an average of 500 characters each. In addition, a whole movement of public parodies appeared, whose participants portrayed neyrobugurts, randomly rearranging phrases in places.

With this article I wanted to show that even if you do not have experience in neural networks, this grief does not matter. You do not need to work at Stanford to do simple but interesting things with neural networks. All participants of our project were ordinary students with their current tasks, diplomas, works, but the common cause allowed us to bring the project to the final. Thanks to the thought-out idea, planning and energy of the participants, we managed to get the first imputed results less than a month after the final formulation of the idea (most of the technical and organizational work came in the winter holidays 2017).
Over 18,000 machine-generated buhurts
I hope this article will help someone plan their own ambitious project with neural networks. Please do not judge strictly, since this is my first article on Habré. If you, like me, are an ML enthusiast, let's be friends .
A little background on how we came to the idea of a neuropresenter and what exactly it was about. In 2017, we made a project for one “Vkontakte” public, the title and screenshots from which the Habrahabr moderators forbade publishing, considering its mention of “self” PR. Public exists since 2013 and combines posts with the general idea of decomposing humor through a line and separating lines with the “@” symbol: The number of lines can vary, the plot can be any one. Most often it is humor or sharp social notes about the infuriating facts of reality. In general, this design is called "buhurt". One of the typical buhurts
СЕТАП
@
РАЗВИТИЕ СЕТАПА
@
ПАНЧЛАЙНOver the years of its existence, the public was overgrown with internal lori (characters, plots, locations), and the number of posts exceeded 30,000. At the time of their parsing for the needs of the project, the number of source lines exceeded half a million.
Part 0. The emergence of ideas and teams.
In the wake of the mass popularity of neural networks, the idea of teaching the ANN on our texts soared in the air for about six months, but was finally formulated with the help of E7su in December 2016. Then the name was invented (“Neurobugurt”). At that time, the team interested in the project consisted of only three people. We were all students without practical experience in algorithms and neural networks. Worse, we didn’t even have any suitable GPUs for training. All we had was the enthusiasm and confidence that this story could be interesting.
Part 1. Formulation hypotheses and objectives
Our hypothesis turned out to be the assumption that if you mix all the texts published for three and a half years and train a neural network on this corpus, you might get:
a) more creative than people
b) funny
Even if words or letters turn out to be machine-confused and located in bugurt chaotically - we believed that it could work as fan service and would still please the readers.
The task was greatly simplified by the fact that the format of buhurts is, in fact, textual. So, we did not need to dive into machine vision and other complex things. Another good news was that the whole corpus of texts is very homogeneous. This made it possible not to use reinforcement training — at least in the early stages. At the same time, we clearly understood that it was not so easy to create a neural network writer with a readable output more than once. The risk of having a monster that would randomly fling letters out was very high.
Part 2. Preparation of the corpus of texts
It is believed that the preparation stage can take a very long time, as it is associated with the collection and cleaning of data. In our case, it turned out to be quite short: a small parser was written , which pumped about 30k posts from the community wall and put them into a txt file .
We did not clear the data before the first training. Later, this played a cruel joke on us, because due to an error that had crept in at this stage, we could not bring the results into a readable form for a long time. But more about that a little further.
Screen file with burgers
Part 3. Announcement, refinement of the hypothesis, the choice of algorithm
We used the available resource - a huge number of public subscribers. The assumption was that among 300,000 readers there are several enthusiasts who own neural networks at a sufficient level to fill gaps in the knowledge of our team. We started from the idea of widely announcing the competition and attracting machine learning enthusiasts to discuss the formulated problem. Having written the texts, we told people about our idea and hoped for a response.
Announcement in thematic discussion
The reaction of people exceeded our wildest expectations. The discussion of the very fact that we are going to train a neural network spread a holivar with almost 1000 comments. Most of the readers simply went crazy and tried to imagine what the result would look like. About 6000 people looked into the thematic discussion, and the comments were left by more than 50 interested lovers, to whom we issued a test set of 814 lines of buhurts for conducting primary tests and training. Everyone interested could take a dataset and train the algorithm that is most interesting to him, and then discuss it with us and with other enthusiasts. We announced in advance that we will continue to work with those participants whose results will be the most readable.
The work began to spin: someone silently assembled a generator on Markov's chains, someone tried various implementations with a githab, and the majority simply faded away in discussion and foamed at the mouth to convince us that nothing would come of it. This started the technical part of the project.
Some suggestions of enthusiasts.
People offered dozens of options for implementation:
- Markov chains.
- Find a ready implementation of something like GitHub and train it.
- A random phrase generator written in Pascal.
- Adopt a Ghostwriter to be randomly write nonsense, and we will issue it for the output of the neural network.
Assessment of the complexity of the project from one of the subscribers
Most of the commentators agreed that our project is doomed to failure and we will not even reach the prototype stage. As we understood later, people are still prone to perceive neural networks as some kind of black magic that takes place in “Zuckerberg’s head” and secret divisions of Google.
Part 4. Selection of the algorithm, training and expansion of the team
After some time, the campaign for crowdsourcing ideas for the algorithm started by us began to yield the first results. We received about 30 working prototypes, most of which were absolutely unreadable nonsense.
At this stage, we first encountered the demotivation of the team. All the results were very weakly similar to buhurts and most often were an abracadabra of letters and symbols. The works of dozens of enthusiasts were ashes and this demotivated both them and us.
PyTorch based algorithm showed itself better than others. It was decided to base this implementation and the LSTM algorithm. We recognized the subscriber who offered it, the winner and started working on improving the algorithm together with him. Our distributed team has increased to four people. The funny thing here is thatthe winner of the competition , as it turned out, was only 16 years old. The victory was his first real prize in the field of Data Science.
For the first training, a cluster of 8 graphic cards was rented. GXT1080 Card Cluster
Management Console
The original repository and all the manuals for the Torch-rnn project are here:
github.com/jcjohnson/torch-rnn . Later, on its basis, we published our repository , in which there are our source codes, ReadMe for installation, as well as the ready neyuroburts themselves.
The first few times we learned using the pre-configured configuration on a paid GPU cluster. Setting it up was not so difficult - just instructions from the Torch developer and the help of the hosting administration, which is included in the payment.
However, very quickly we encountered a difficulty: every training was worth the time to rent a GPU - and therefore money, which the project simply did not have. Because of this, in January-February 2017, we conducted training on purchased capacities, and tried to start generation on our local machines.
Any text is suitable for learning the model. Before training, it must be preprocessing, for which Torch has a special algorithm preprocess.py, which converts your my_data.txt into two files: HDF5 and JSON:
The preprocessing script runs like this:
python scripts/preprocess.py \
--input_txt my_data.txt \
--output_h5 my_data.h5 \
--output_json my_data.jsonAfter preprocessing, two files appear on which the neural network will be further trained.
Various flags that can be changed at the preprocessing stage are described here . It is also possible to launch Torch from Docker , but the author of the article did not check it.
Neural network training
After preprocessing, you can proceed to the training model. In the folder with HDF5 and JSON, you need to run the th utility, which came to you if you installed Torch correctly:
th train.lua -input_h5 my_data.h5 -input_json my_data.jsonTraining takes a huge amount of time and generates files like cv / checkpoint_1000.t7, which are the weights of our neural network. These files weigh an impressive number of megabytes and contain the values of the strength of the connections between specific letters in your original dataset.
The neural network is often compared with the human brain, but it seems to me that the analogy with a mathematical function that takes input parameters (your data) and gives the result (new data) output is much more understandable.
In our case, each training on a cluster of 8 GTX 1080 in a 500,000-line data set took about an hour or two, and similar training on a used i3-2120 CPU took about 80-100 hours. In the case of longer trainings, the neural network began to retrain hard — the characters too often repeated each other, falling into long cycles from prepositions, conjunctions, and introductory words.
It is convenient that you can choose the frequency of the checkpoint placement and in the course of one training you can immediately get a lot of models: from the least trained (checkpoint_1000) to the retrained (checkpoint_1000000). Only space would be enough.
Generation of new texts
Having received at least one ready-made file with weights (checkpoint _ *******), you can proceed to the next and most interesting stage: start generating texts. For us, it was a real moment of truth, because for the first time we got some tangible result - a bugurt, written by a machine.
By this time, we finally stopped using the cluster and all the generations were performed on our low-power machines. However, when trying to start locally, just follow the instructions and install Torch, we did not succeed. The first barrier was the use of virtual machines. On a virtual Ubuntu 16, the stick just doesn't take off - forget it. StackOverflow often came to the rescue, but some errors were so nontrivial that the answer could only be found with great difficulty.
Installing Torch on a local machine stalled the project for a good couple of weeks: we encountered all sorts of installation errors for numerous necessary packages, and also struggled with virtualization (virtualenv .env) and eventually did not use it. Several times the stand was demolished to the level of sudo rm -rf and simply installed again.
Using the resulting file with weights, we were able to start generating texts on our local machine:
One of the first conclusions
Part 5. Text Cleaning
Another obvious difficulty was that the topic of posts is very different, and our algorithm does not involve any division and considers all 500,000 lines as a single text. We considered various options for clustering datasets and were even ready to manually break the corpus of texts by subject or place tags on several thousand buhurts (there was a necessary human resource for this), but constantly faced with technical difficulties in presenting clusters in LSTM training. Changing the algorithm and holding a contest again seemed not the most sensible idea in terms of project timing and motivation of participants.
It seemed that we were at a dead end - we could not cluster bugurts, and learning on a single huge dataset gave a dubious result. To take a step back and change the algorithm that almost took off and the implementation didn’t want to either - the project could simply fall into a coma. The team desperately lacked the knowledge to solve the situation normally, but the good old SME-KAL-OCHK-A came to the rescue. The final solution of the
We placed the spacing in 10 vertical spaces after each buhurt, re-conducted training, and when generating set a limit on the output of 500 characters (the average length of one “plot” buhurth in the original dataset).
As it was. Intervals between texts are minimal.
As it became. The 10-line intervals give LSTM to “understand” that one bugurt has ended and another has begun.
Thus, it was possible to achieve that about 60% of all generated buhurts began to have a readable (although often very delusional) storyline along the entire length of the buhurth from beginning to end. The length of one plot was, on average, from 9 to 13 lines.
Part 6. Re-training
Having estimated the economics of the project, we decided not to spend money on renting a cluster, but to invest in the purchase of our own cards. Training time would have increased, but having bought a card once, we could generate new buhurts all the time. At the same time, it was often unnecessary to conduct training constantly.
Fighting settings on a local machine
Part 7. Balancing Results
At the turn of March-April 2017, we re-trained the neural network, specifying the temperature parameters and the number of learning epochs. As a result, the quality of the output texts slightly increased.
Learning speed torch-rnn versus char-rnn
We tested both algorithms that come with Torch: rnn and LSTM. The second showed itself better.
Part 8. What have we achieved?
The first neurobugurt was published on January 17, 2017 — immediately after training in the cluster — and on the first day, more than 1000 comments were collected.
One of the first neurobugurts Neurobugurts
went so well to the audience that they became a separate section that for a year went out under the hashtag #neurobugurt and amused subscribers. In total, in 2017 and the beginning of 2018, we generated more than 18,000 neyrobugurts , an average of 500 characters each. In addition, a whole movement of public parodies appeared, whose participants portrayed neyrobugurts, randomly rearranging phrases in places.
Part 9. Instead of conclusion
With this article I wanted to show that even if you do not have experience in neural networks, this grief does not matter. You do not need to work at Stanford to do simple but interesting things with neural networks. All participants of our project were ordinary students with their current tasks, diplomas, works, but the common cause allowed us to bring the project to the final. Thanks to the thought-out idea, planning and energy of the participants, we managed to get the first imputed results less than a month after the final formulation of the idea (most of the technical and organizational work came in the winter holidays 2017).
Over 18,000 machine-generated buhurts
I hope this article will help someone plan their own ambitious project with neural networks. Please do not judge strictly, since this is my first article on Habré. If you, like me, are an ML enthusiast, let's be friends .