How AI learns to generate images of cats
- Transfer

Translation How the AI CAN learn to the generate pictures of cats .
Published in 2014, the research work Generative Adversarial Nets (GAN) was a breakthrough in the field of generative models. Lead researcher Yann Lekun called adversarial nets "the best idea in machine learning over the past twenty years." Today, thanks to this architecture, we can create an AI that generates realistic images of cats. Cool!

DCGAN during training
All working code lies in the Github repository . It will be useful to you if you have any experience of programming in Python, deep learning, working with Tensorflow and convolutional neural networks.
And if you are new to deep learning, I recommend to get acquainted with the excellent series of articles Machine Learning is Fun!
What is DCGAN?
Convolutional generative adversarial deep learning networks (Deep Convolutional Generative Adverserial Networks, DCGAN) are a deep learning architecture that generates data similar to data from a training set.
This model replaces the completely connected layers of the generative adversary network with convolutional layers. To understand how DCGAN works, let us use the metaphor of confrontation between an art expert and a forger.
The forger (“generator”) is trying to create a fake Van Gogh painting and pass it off as a real one.
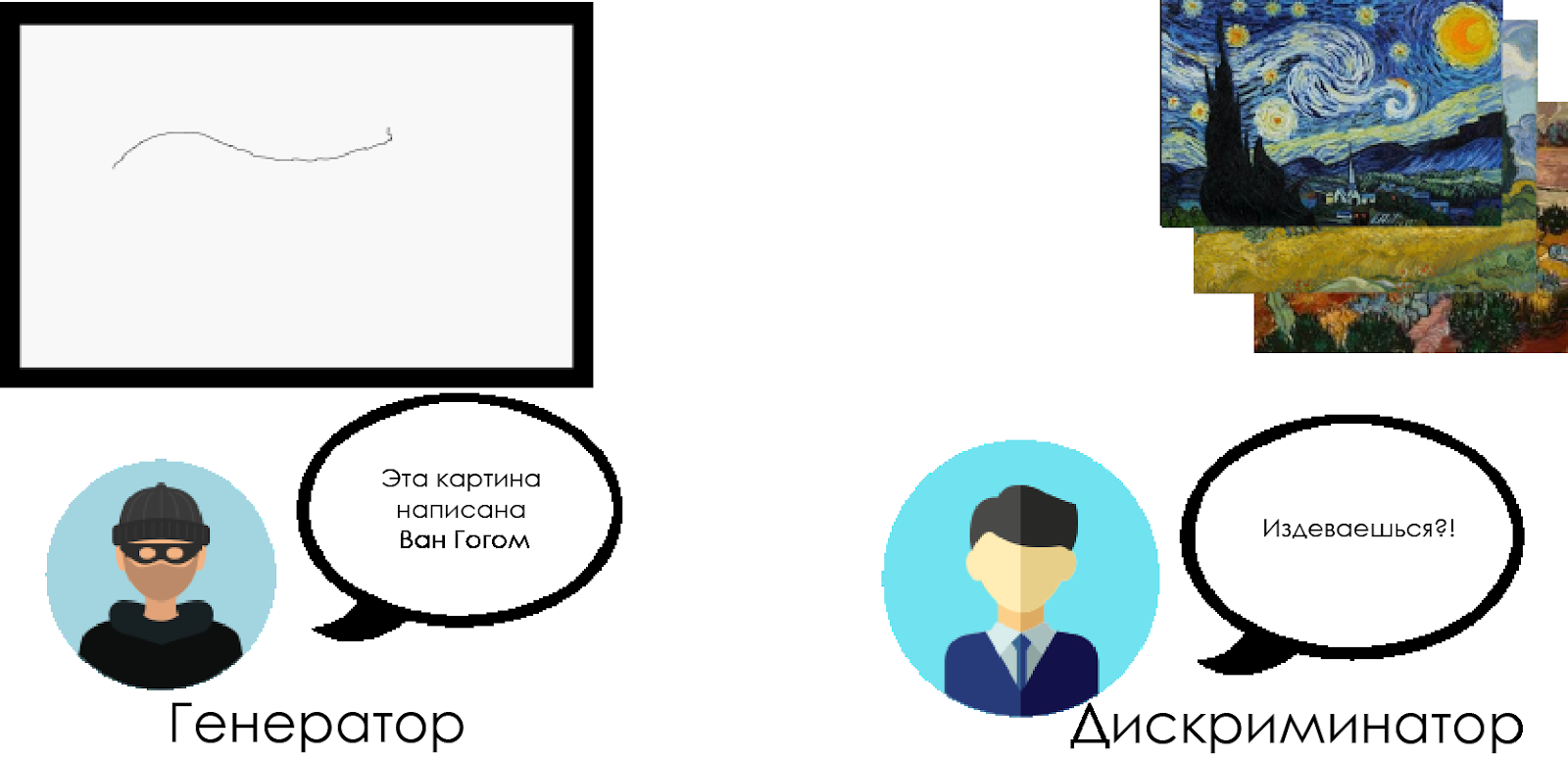
The art historian ("discriminator") tries to catch the forger using his knowledge of the real Van Gogh canvases.
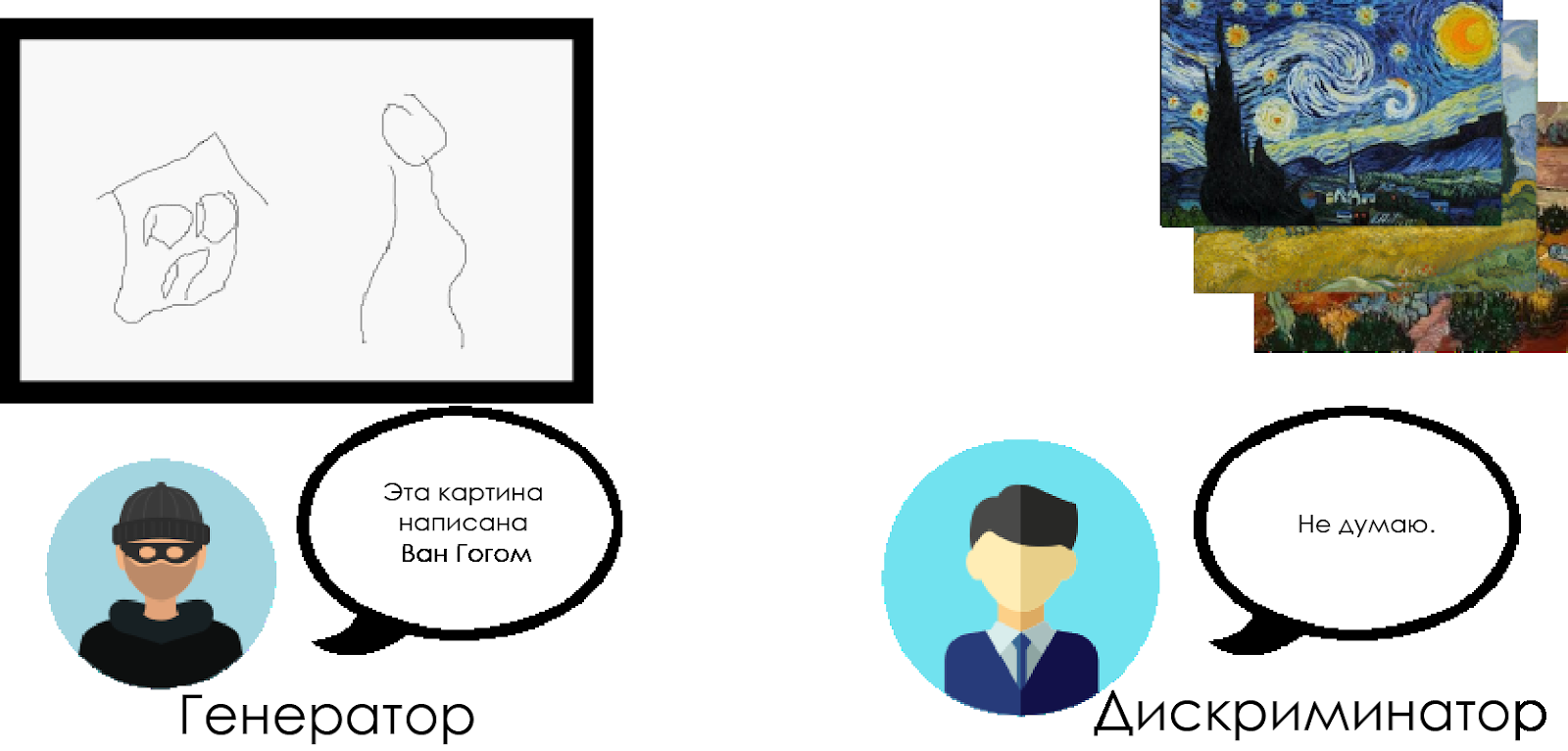
Over time, the art historian is better at detecting fakes, and the forger makes them more and more perfect.

As you can see, DCGANs are made up of two separate deep learning neural networks that compete with each other.
- The generator is trying to create data that looks believable. He does not know what the real data is, but he learns from the responses of the enemy's neural network, changing the results of his work with each iteration.
- The discriminator tries to identify fake data (comparing with the real data), avoiding false alarms as far as possible with respect to the data as much as possible. The result of this model is feedback for the generator.
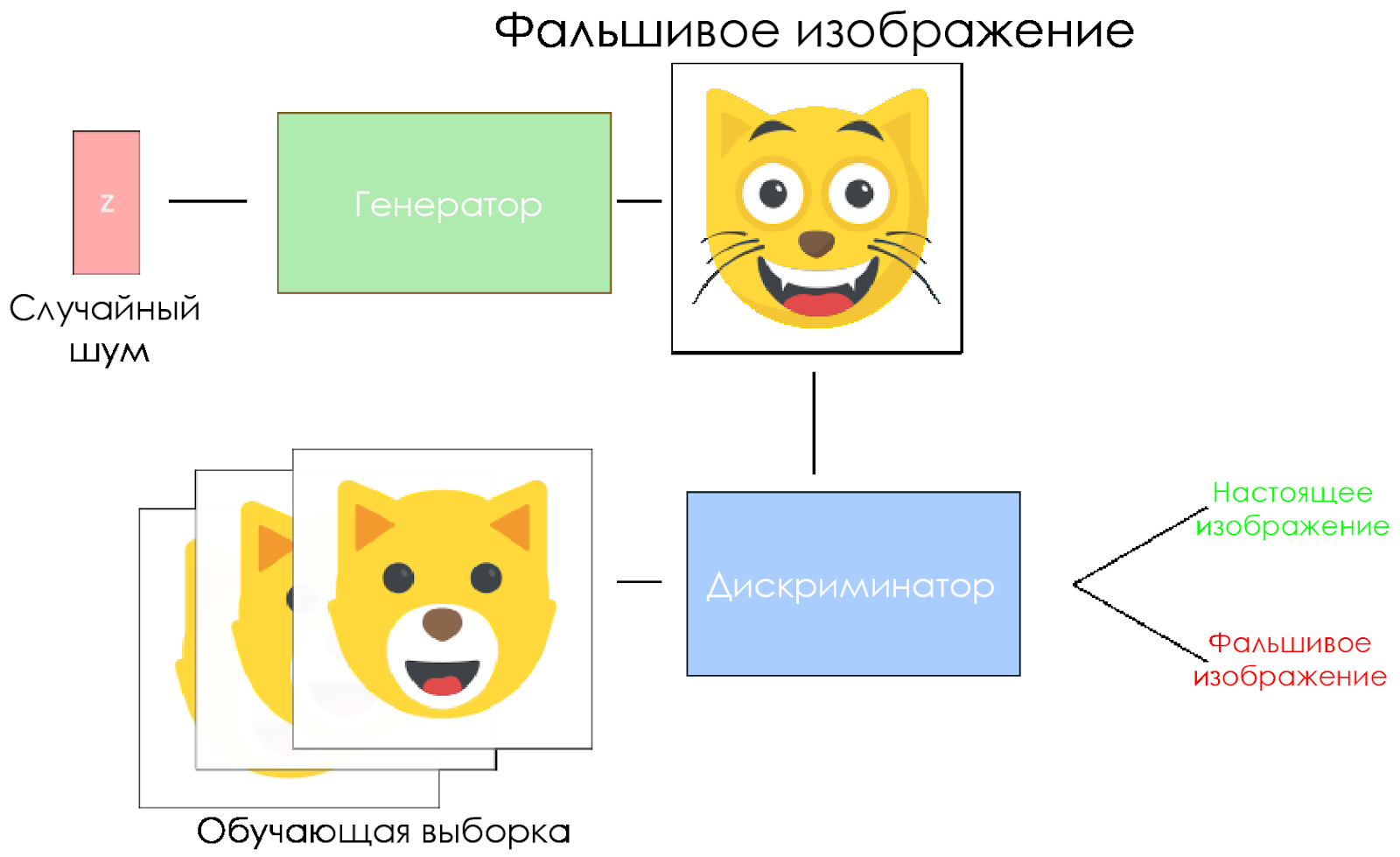
DCGAN scheme.
- The generator takes a random noise vector and generates an image.
- The picture is given to the discriminator, he compares it with the training sample.
- The discriminator returns a number - 0 (fake) or 1 (real image).
Let's create a DCGAN!
Now we are ready to create our own AI.
In this part we will focus on the main components of our model. If you want to see all the code, go here .
Input data
Create stubs for input data:
inputs_realfor the discriminator and inputs_zfor the generator. Please note that we will have two learning rates (learning rates), separately for the generator and the discriminator. DCGANs are very sensitive to hyperparameters, so it is very important to fine-tune them.
def model_inputs(real_dim, z_dim):"""
Create the model inputs
:param real_dim: tuple containing width, height and channels
:param z_dim: The dimension of Z
:return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D)
"""# inputs_real for Discriminator
inputs_real = tf.placeholder(tf.float32, (None, *real_dim), name='inputs_real')
# inputs_z for Generator
inputs_z = tf.placeholder(tf.float32, (None, z_dim), name="input_z")
# Two different learning rate : one for the generator, one for the discriminator
learning_rate_G = tf.placeholder(tf.float32, name="learning_rate_G")
learning_rate_D = tf.placeholder(tf.float32, name="learning_rate_D")
return inputs_real, inputs_z, learning_rate_G, learning_rate_DDiscriminator and generator
We use
tf.variable_scopefor two reasons. First, to make sure that the names of all variables begin with generator / discriminator. Later it will help us in learning two neural networks.
Secondly, we will reuse these networks with different input data:
- We will train the generator, and then take a sample of the images generated by it.
- In the discriminator, we will share variables for fake and real input images.

Let's create a discriminator. Remember that he takes a real or fake image as input and returns 0 or 1 in response.
A few notes:
- We need to double the size of the filter in each convolutional layer.
- It is not recommended to use downsampling. Instead, only strided convolutional layers are applicable.
- In each layer we use batch normalization (with the exception of the input layer), since this reduces the covariance shift. You can read more in this wonderful article .
- As an activation function, we use Leaky ReLU, it will help to avoid the effect of a “fading” gradient.
defdiscriminator(x, is_reuse=False, alpha = 0.2):''' Build the discriminator network.
Arguments
---------
x : Input tensor for the discriminator
n_units: Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out, logits:
'''with tf.variable_scope("discriminator", reuse = is_reuse):
# Input layer 128*128*3 --> 64x64x64# Conv --> BatchNorm --> LeakyReLU
conv1 = tf.layers.conv2d(inputs = x,
filters = 64,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv1')
batch_norm1 = tf.layers.batch_normalization(conv1,
training = True,
epsilon = 1e-5,
name = 'batch_norm1')
conv1_out = tf.nn.leaky_relu(batch_norm1, alpha=alpha, name="conv1_out")
# 64x64x64--> 32x32x128# Conv --> BatchNorm --> LeakyReLU
conv2 = tf.layers.conv2d(inputs = conv1_out,
filters = 128,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv2')
batch_norm2 = tf.layers.batch_normalization(conv2,
training = True,
epsilon = 1e-5,
name = 'batch_norm2')
conv2_out = tf.nn.leaky_relu(batch_norm2, alpha=alpha, name="conv2_out")
# 32x32x128 --> 16x16x256# Conv --> BatchNorm --> LeakyReLU
conv3 = tf.layers.conv2d(inputs = conv2_out,
filters = 256,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv3')
batch_norm3 = tf.layers.batch_normalization(conv3,
training = True,
epsilon = 1e-5,
name = 'batch_norm3')
conv3_out = tf.nn.leaky_relu(batch_norm3, alpha=alpha, name="conv3_out")
# 16x16x256 --> 16x16x512# Conv --> BatchNorm --> LeakyReLU
conv4 = tf.layers.conv2d(inputs = conv3_out,
filters = 512,
kernel_size = [5, 5],
strides = [1, 1],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv4')
batch_norm4 = tf.layers.batch_normalization(conv4,
training = True,
epsilon = 1e-5,
name = 'batch_norm4')
conv4_out = tf.nn.leaky_relu(batch_norm4, alpha=alpha, name="conv4_out")
# 16x16x512 --> 8x8x1024# Conv --> BatchNorm --> LeakyReLU
conv5 = tf.layers.conv2d(inputs = conv4_out,
filters = 1024,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv5')
batch_norm5 = tf.layers.batch_normalization(conv5,
training = True,
epsilon = 1e-5,
name = 'batch_norm5')
conv5_out = tf.nn.leaky_relu(batch_norm5, alpha=alpha, name="conv5_out")
# Flatten it
flatten = tf.reshape(conv5_out, (-1, 8*8*1024))
# Logits
logits = tf.layers.dense(inputs = flatten,
units = 1,
activation = None)
out = tf.sigmoid(logits)
return out, logits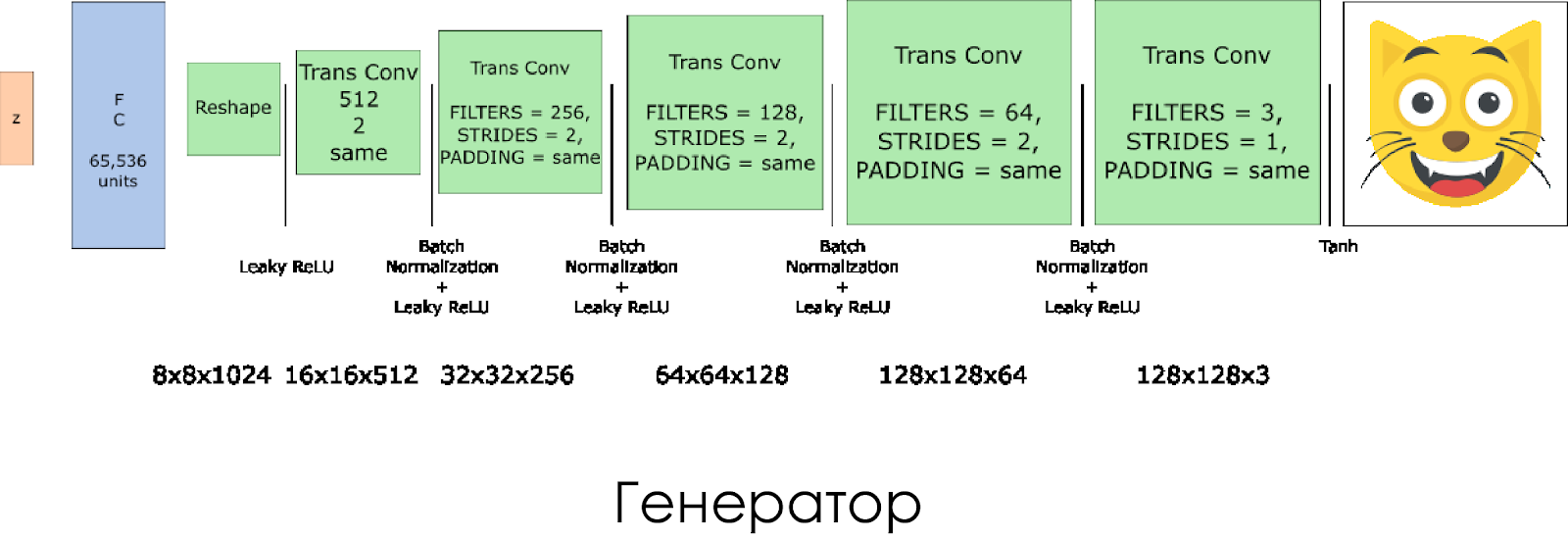
We created a generator. Remember that it takes as its input a noise vector (z) and due to the transposed convolution layers it creates a fake image.
On each layer, we reduce the filter size by half, and also double the size of the image.
Best of all, the generator works when used
tanhas an output activation function.defgenerator(z, output_channel_dim, is_train=True):''' Build the generator network.
Arguments
---------
z : Input tensor for the generator
output_channel_dim : Shape of the generator output
n_units : Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out:
'''with tf.variable_scope("generator", reuse= not is_train):
# First FC layer --> 8x8x1024
fc1 = tf.layers.dense(z, 8*8*1024)
# Reshape it
fc1 = tf.reshape(fc1, (-1, 8, 8, 1024))
# Leaky ReLU
fc1 = tf.nn.leaky_relu(fc1, alpha=alpha)
# Transposed conv 1 --> BatchNorm --> LeakyReLU# 8x8x1024 --> 16x16x512
trans_conv1 = tf.layers.conv2d_transpose(inputs = fc1,
filters = 512,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv1")
batch_trans_conv1 = tf.layers.batch_normalization(inputs = trans_conv1, training=is_train, epsilon=1e-5, name="batch_trans_conv1")
trans_conv1_out = tf.nn.leaky_relu(batch_trans_conv1, alpha=alpha, name="trans_conv1_out")
# Transposed conv 2 --> BatchNorm --> LeakyReLU# 16x16x512 --> 32x32x256
trans_conv2 = tf.layers.conv2d_transpose(inputs = trans_conv1_out,
filters = 256,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv2")
batch_trans_conv2 = tf.layers.batch_normalization(inputs = trans_conv2, training=is_train, epsilon=1e-5, name="batch_trans_conv2")
trans_conv2_out = tf.nn.leaky_relu(batch_trans_conv2, alpha=alpha, name="trans_conv2_out")
# Transposed conv 3 --> BatchNorm --> LeakyReLU# 32x32x256 --> 64x64x128
trans_conv3 = tf.layers.conv2d_transpose(inputs = trans_conv2_out,
filters = 128,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv3")
batch_trans_conv3 = tf.layers.batch_normalization(inputs = trans_conv3, training=is_train, epsilon=1e-5, name="batch_trans_conv3")
trans_conv3_out = tf.nn.leaky_relu(batch_trans_conv3, alpha=alpha, name="trans_conv3_out")
# Transposed conv 4 --> BatchNorm --> LeakyReLU# 64x64x128 --> 128x128x64
trans_conv4 = tf.layers.conv2d_transpose(inputs = trans_conv3_out,
filters = 64,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv4")
batch_trans_conv4 = tf.layers.batch_normalization(inputs = trans_conv4, training=is_train, epsilon=1e-5, name="batch_trans_conv4")
trans_conv4_out = tf.nn.leaky_relu(batch_trans_conv4, alpha=alpha, name="trans_conv4_out")
# Transposed conv 5 --> tanh# 128x128x64 --> 128x128x3
logits = tf.layers.conv2d_transpose(inputs = trans_conv4_out,
filters = 3,
kernel_size = [5,5],
strides = [1,1],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="logits")
out = tf.tanh(logits, name="out")
return outLosses in the discriminator and generator
Since we are simultaneously training the generator and the discriminator, we need to calculate the losses for both neural networks. The discriminator should produce 1 when it “considers” the image as real, and 0 if it is false. In accordance with this and need to adjust the loss. The loss of the discriminator is calculated as the sum of the losses for the real and fake image:
d_loss = d_loss_real + d_loss_fake where
d_loss_realis the loss when the discriminator considers the image as false, and in fact it is real. It is calculated as:- We use
d_logits_real, all labels are equal 1 (because all data is real). labels = tf.ones_like(tensor) * (1 - smooth). We use label smoothing: we will reduce the label values from 1.0 to 0.9 to help the discriminator generalize better.
d_loss_fake - this is a loss when the discriminator considers the image to be real, but in fact it is false.- Use
d_logits_fake, all labels are 0.
For the loss of the generator is used
d_logits_fakefrom the discriminator. This time, all labels are equal to 1, because the generator wants to deceive the discriminator.defmodel_loss(input_real, input_z, output_channel_dim, alpha):"""
Get the loss for the discriminator and generator
:param input_real: Images from the real dataset
:param input_z: Z input
:param out_channel_dim: The number of channels in the output image
:return: A tuple of (discriminator loss, generator loss)
"""# Generator network here
g_model = generator(input_z, output_channel_dim)
# g_model is the generator output# Discriminator network here
d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
d_model_fake, d_logits_fake = discriminator(g_model,is_reuse=True, alpha=alpha)
# Calculate losses
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_model_real)))
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_model_fake)))
d_loss = d_loss_real + d_loss_fake
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_model_fake)))
return d_loss, g_lossOptimizers
After calculating the losses, it is necessary to update the generator and the discriminator separately. To do this,
tf.trainable_variables()we will create a list of all variables defined in our graph.defmodel_optimizers(d_loss, g_loss, lr_D, lr_G, beta1):"""
Get optimization operations
:param d_loss: Discriminator loss Tensor
:param g_loss: Generator loss Tensor
:param learning_rate: Learning Rate Placeholder
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:return: A tuple of (discriminator training operation, generator training operation)
"""# Get the trainable_variables, split into G and D parts
t_vars = tf.trainable_variables()
g_vars = [var for var in t_vars if var.name.startswith("generator")]
d_vars = [var for var in t_vars if var.name.startswith("discriminator")]
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
# Generator update
gen_updates = [op for op in update_ops if op.name.startswith('generator')]
# Optimizerswith tf.control_dependencies(gen_updates):
d_train_opt = tf.train.AdamOptimizer(learning_rate=lr_D, beta1=beta1).minimize(d_loss, var_list=d_vars)
g_train_opt = tf.train.AdamOptimizer(learning_rate=lr_G, beta1=beta1).minimize(g_loss, var_list=g_vars)
return d_train_opt, g_train_optTraining
Now we implement the learning function. The idea is quite simple:
- We keep our model every five periods (epoch).
- We save the picture in the folder with images every 10 trained batches.
- Every 15 periods we display
g_loss,d_lossand the generated image. This is necessary because Jupyter notebook may fail when displaying too many pictures. - Or we can directly generate real images by loading a saved model (this will save 20 hours of training).
deftrain(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha):"""
Train the GAN
:param epoch_count: Number of epochs
:param batch_size: Batch Size
:param z_dim: Z dimension
:param learning_rate: Learning Rate
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:param get_batches: Function to get batches
:param data_shape: Shape of the data
:param data_image_mode: The image mode to use for images ("RGB" or "L")
"""# Create our input placeholders
input_images, input_z, lr_G, lr_D = model_inputs(data_shape[1:], z_dim)
# Losses
d_loss, g_loss = model_loss(input_images, input_z, data_shape[3], alpha)
# Optimizers
d_opt, g_opt = model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1)
i = 0
version = "firstTrain"with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Saver
saver = tf.train.Saver()
num_epoch = 0if from_checkpoint == True:
saver.restore(sess, "./models/model.ckpt")
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
else:
for epoch_i in range(epoch_count):
num_epoch += 1if num_epoch % 5 == 0:
# Save model every 5 epochs#if not os.path.exists("models/" + version):# os.makedirs("models/" + version)
save_path = saver.save(sess, "./models/model.ckpt")
print("Model saved")
for batch_images in get_batches(batch_size):
# Random noise
batch_z = np.random.uniform(-1, 1, size=(batch_size, z_dim))
i += 1# Run optimizers
_ = sess.run(d_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_D: learning_rate_D})
_ = sess.run(g_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_G: learning_rate_G})
if i % 10 == 0:
train_loss_d = d_loss.eval({input_z: batch_z, input_images: batch_images})
train_loss_g = g_loss.eval({input_z: batch_z})
# Save it
image_name = str(i) + ".jpg"
image_path = "./images/" + image_name
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
# Print every 5 epochs (for stability overwize the jupyter notebook will bug)if i % 1500 == 0:
image_name = str(i) + ".jpg"
image_path = "./images/" + image_name
print("Epoch {}/{}...".format(epoch_i+1, epochs),
"Discriminator Loss: {:.4f}...".format(train_loss_d),
"Generator Loss: {:.4f}".format(train_loss_g))
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, False, True)
return losses, samplesHow to start
All this can be run directly on your computer, if you are ready to wait 10 years. So it is better to use cloud-based GPU-services like AWS or FloydHub. Personally, I trained this DCGAN for 20 hours on Microsoft Azure and their Deep Learning Virtual Machine . I do not have a business relationship with Azure, I just like their customer service.
If you have any difficulties running on a virtual machine, refer to this wonderful article .
If you improve the model, feel free to make a pull request.
