How to find a girl in 250 microseconds
In contrast to Europe and America, a cautious attitude prevails in dating sites in Russia. However, the hope of clicking on the magic button and finding love for yourself does not fade in the hearts of many. And we must justify this hope. Of course, we do not promise to immediately find the perfect “mate”, but we are simply obliged to offer dozens, hundreds or in some cases thousands of options that meet your exact needs. What we do, and very quickly.
An average search in a database of 11 million profiles with 4 to 30 parameters each takes on average 3.5 milliseconds. And at the same time, in addition to searching, the Mamba daemon-sercher performs the following, including not quite traditional tasks:
Despite the fact that from the very beginning our search was developed on our own, from time to time there were thoughts to use something already known, run-in and guaranteed to be effective. Well, if we think about the search, Sphinx comes to mind first. At some point, we decided to check whether it could give us serious advantages, and were somewhat surprised at the results. On a test base of 2 million questionnaires, Sphinx showed an average result of 100-120 ms depending on the request, while in the index we (since this is still a test) included only part of the fields. Our search on the same base and on the same equipment spends from 0.2 to 1.1 ms per request.
As further practice has shown, half of the success of a search lies in creating the right index. In our understanding, the correct index is the most fully consistent with the search tasks and provides the highest processing speed. After a general analysis of the database, it was decided to divide the index into several components:
But the main tricks are hidden in the structure of each part of the general index, which are constructed as follows:
What does this mean for a search? For example, we have an index on the fields “gender” and “age”, where the gender can take the values “M” and “F”, and the age can be from 18 to 21. Imagine that the user wants to find a girl 20 years old (i.e. .conditions are satisfied only by one value of each field).
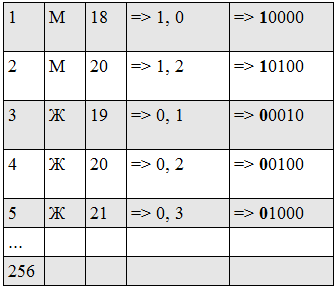
Suppose we have such profiles (1 block is shown, since the minimum age is 18, then 18 years old is encoded as 0000, 19 as 0010, 20 as 0100, and so on)
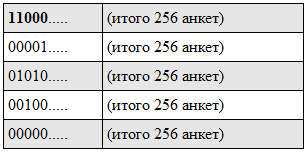
After processing, an index of the following type is obtained (the first bit is highlighted in bold, before and after):
For some fields, the value is stored non-compactly. For example, a real age field takes 64 values. You can store 1 bit per possible value, that is, the field will take 64 bits, but the search will take only 1 operation, and the range search will take 2 operations. A more traditional option is to store it as a number, then it will take log2 (64) = 6 bits, but searching for a specific age will take 6 operations, and searching over a range of more than 12 (the exact value depends on the length of the comparison condition recorded as DNF).
The search process itself is as follows:
The most interesting is the field validation code. In the results segment, each questionnaire corresponds to 1 bit, which indicates whether the questionnaire is suitable for the request or not.
The request is processed as follows:
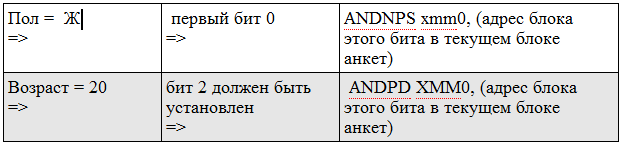
After that, it remains only to go through the bitmap with the result and see which profiles are set to 1.
In our example, the result will be 00010, that is, only profile number 4 will satisfy the request.
The Mamba search daemon is called up from a significant part of all site pages. I think it is worth noting that, along with several other "main" daemons, it uses the JSON-RPC protocol and as a whole creates a "single demonic space".
Real search statistics are as follows:
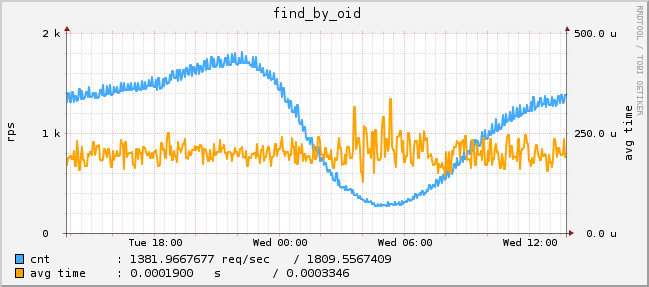
Fig. 1 Search requests by id profile (graph from one server)

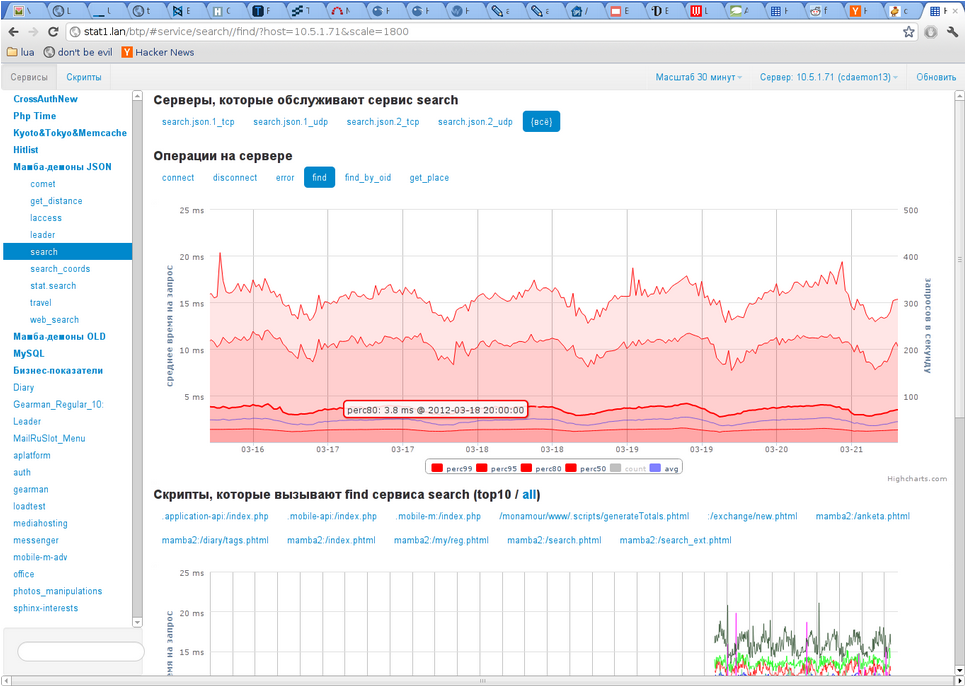
Fig. 2 Requests to search by parameters (graph from one server)
In total, the search runs on two machines, the peak performance of one is 20k search operations for profiles by parameters with a complete calculation of the number of profiles found per second (this is the longest operation, the rest work much faster). Workload - about 800 rps search + 1000 rps for getting a place + 1500 rps for receiving personal data.

Fig. 3 Displaying the place of the questionnaire in the search results (graph from one server)
Distribution of the total response time (i.e. taking into account network interaction) from all (two) search servers. The average is 2.5 ms, the median is 1.5 ms, 5% of requests take more than 10 ms and 1% of requests takes more than 15 ms.
An average search in a database of 11 million profiles with 4 to 30 parameters each takes on average 3.5 milliseconds. And at the same time, in addition to searching, the Mamba daemon-sercher performs the following, including not quite traditional tasks:
- for each specific questionnaire gives its place in the search (each user, entering his profile, sees the message "You are on the Nth place in the search")
- gives a specific profile from the list by primary key
- makes a direct search for the profile according to the specified parameters
Despite the fact that from the very beginning our search was developed on our own, from time to time there were thoughts to use something already known, run-in and guaranteed to be effective. Well, if we think about the search, Sphinx comes to mind first. At some point, we decided to check whether it could give us serious advantages, and were somewhat surprised at the results. On a test base of 2 million questionnaires, Sphinx showed an average result of 100-120 ms depending on the request, while in the index we (since this is still a test) included only part of the fields. Our search on the same base and on the same equipment spends from 0.2 to 1.1 ms per request.
Sphinx: source - mysql, индексировались только int поля через sql_attr_uint. Весь индекс в памяти.As further practice has shown, half of the success of a search lies in creating the right index. In our understanding, the correct index is the most fully consistent with the search tasks and provides the highest processing speed. After a general analysis of the database, it was decided to divide the index into several components:
- profiles located in Moscow and the region with photographs (this is the most frequently requested type of profiles)
- VIP users index (VIP users have certain advantages, including search results, therefore they are processed separately)
- full index of all types of profiles for all fields of each profile
But the main tricks are hidden in the structure of each part of the general index, which are constructed as follows:
- profiles are divided into blocks of 256 profiles per block
- each block is placed in the index: first, the first bit of the first field of each questionnaire, then the second bit from each questionnaire, etc. Thus, the data of one bit from the field of all profiles goes in a row
What does this mean for a search? For example, we have an index on the fields “gender” and “age”, where the gender can take the values “M” and “F”, and the age can be from 18 to 21. Imagine that the user wants to find a girl 20 years old (i.e. .conditions are satisfied only by one value of each field).
Suppose we have such profiles (1 block is shown, since the minimum age is 18, then 18 years old is encoded as 0000, 19 as 0010, 20 as 0100, and so on)
After processing, an index of the following type is obtained (the first bit is highlighted in bold, before and after):
For some fields, the value is stored non-compactly. For example, a real age field takes 64 values. You can store 1 bit per possible value, that is, the field will take 64 bits, but the search will take only 1 operation, and the range search will take 2 operations. A more traditional option is to store it as a number, then it will take log2 (64) = 6 bits, but searching for a specific age will take 6 operations, and searching over a range of more than 12 (the exact value depends on the length of the comparison condition recorded as DNF).
The search process itself is as follows:
- the daemon accepts and parses the request
- memory is allocated for the results (by bit for each profile in the index)
- a memory segment is allocated for a compiled request, a run flag is set for it
- in this segment is written:
- initialization code, loop header
- for each field by which to filter the result, a code is written that checks the value of this field
- the end of the cycle, checking the boundaries, counting the number of found
- this segment is launched through a regular long jump
The most interesting is the field validation code. In the results segment, each questionnaire corresponds to 1 bit, which indicates whether the questionnaire is suitable for the request or not.
The request is processed as follows:
After that, it remains only to go through the bitmap with the result and see which profiles are set to 1.
In our example, the result will be 00010, that is, only profile number 4 will satisfy the request.
The Mamba search daemon is called up from a significant part of all site pages. I think it is worth noting that, along with several other "main" daemons, it uses the JSON-RPC protocol and as a whole creates a "single demonic space".
Real search statistics are as follows:
Fig. 1 Search requests by id profile (graph from one server)
Fig. 2 Requests to search by parameters (graph from one server)
In total, the search runs on two machines, the peak performance of one is 20k search operations for profiles by parameters with a complete calculation of the number of profiles found per second (this is the longest operation, the rest work much faster). Workload - about 800 rps search + 1000 rps for getting a place + 1500 rps for receiving personal data.
Fig. 3 Displaying the place of the questionnaire in the search results (graph from one server)
Distribution of the total response time (i.e. taking into account network interaction) from all (two) search servers. The average is 2.5 ms, the median is 1.5 ms, 5% of requests take more than 10 ms and 1% of requests takes more than 15 ms.