How JS Works: Storage Systems
- Transfer
When designing a web application is extremely important to choose the appropriate means for local data storage. We are talking about a mechanism that will reliably store information, will help reduce the amount of data transmitted between the server and client parts of the application, and at the same time does not worsen the speed of the application's response to the user's impact. A well-thought-out local data caching strategy is central to the development of mobile web applications that can work without being connected to the Internet. Modern users more and more often regard such opportunities as something familiar and expected.

Today, in the translation of the 16th part of a series of materials devoted to everything related to JavaScript, we will talk about client-side data storage mechanisms that can be used in web development, and the choice of data storage system for a specific project.
The data model defines the internal organization of the stored data. It affects all aspects of a web application device, it contains solutions, often trade-offs, on which the efficiency of the application and the ability of the storage system to solve its tasks depend. There is no "best" approach to the design of data models, there are no universal solutions that are suitable for all applications. The choice of data model is based on the features and needs of a particular application. Consider a few basic data storage models from which you can choose something appropriate for a particular project.
The data storage methods used in web applications can be analyzed in terms of the persistent storage time for such data.
Nowadays, there are quite a few browser-based APIs that allow you to organize data storage. We will look at some of them and compare them in order to make it easier for you to choose the right API.
To begin with, however, we will focus on a few general questions that should be taken into account before choosing a specific technology for data storage. Of course, first of all you need to understand how your application will be used, how its support will be organized, how it is planned to be developed. At the same time, even if you have clear answers to these questions, you can end up with several options for data storage systems from which you will need to choose the most suitable one. Here is what you should pay attention to when choosing a storage system:
In this section, we will look at some of the existing storage systems available to web developers, and compare them by the indicators described above.
Now let's talk more about these methods of data storage.

Using the FileSystem API, web applications can work with a dedicated area of a user's local file system. The application can view the contents of the repository, create files, perform read and write operations.
This API consists of the following main parts:
The API is
The interface of
This interface does not give the webpage access to the user's file system. Instead, it allows you to work with something like a virtual disk, which is located in the sandbox created by the browser. If your application needs access to the user's file system, you will need to use other mechanisms.
A web application can request access to the virtual file system by making a call
If you call
After you gain access to the file system, you can perform most standard file and directory operations.
The API is
Among the options for using the API
This is how things stand with API support by

Browser API FileSystem Support

The LocalStorage API , or local storage, allows you to work with the Storage object of the Document object , taking into account the principle of the same source. Data is not lost between sessions. The API is
Note that the data placed in the local or session storage is tied to the page source, which is determined by the combination of protocol, host, and port.
Here is information on API support by

Browser LocalStorage API support
The SessionStorage API allows you to work with a session's Storage object . The API is
Here is information about API support by
Browser SessionStorage API support

Cookies (cookies, web cookies, browser cookies) are small pieces of information that the server sends to the browser. The browser can save them and send them to the server, using them when making requests to it. They are usually used to identify a specific instance of the browser from which requests are being received. For example - in order that the user, after logging in to the system, would remain in it. A cookie is something like a session state information storage system for the HTTP protocol , which treats every request, even coming from the same browser, as completely independent of others.
Cookies are used to solve three main tasks:
At one time, cookies were used as a general-purpose data store. Although this is quite a normal way to use cookies, especially when they were the only way to store data on the client, nowadays it is not recommended to use them as such, preferring a more modern API. Cookies are sent with each request, so they can degrade performance (especially on mobile devices).
There are two types of cookies:
Please note that confidential or other important information should not be stored in cookies or transferred to HTTP cookies, since the whole mechanism for working with cookies is inherently insecure.
If we talk about the support of cookies, they, as you probably already understood, are supported by all browsers.

The Cache interface provides a storage mechanism for cached Request / Response object pairs . This interface is defined in the same specifications as service workers, but it is available not only to workers. The interface
Some source may have several named objects
In addition, the developer is responsible for periodic cache flushing. Each browser has a hard-coded limit on the size of the cache that is allocated to a particular source. You can find out the approximate value of the cache quota by using the StorageEstimate API .
The browser does everything in its power to maintain a certain amount of available cache space, but it can delete the cache for some source. Usually, the browser either deletes the entire cache or doesn’t touch it at all. Using caches, do not forget to distinguish them according to the versions of your scripts, for example, including the version of the script in the name of the cache. This is done in order to ensure the safe operation of various versions of scripts with a cache. Details on this can be found here .
The CacheStorage interface provides storage for Cache objects . Here are the tasks for which this interface is responsible:
To get an instance of an object
To find out if a Request object is the key of an object
You

The IndexedDB API is a DBMS that allows you to store data using browser tools. Since it allows you to create web applications that have the ability to work with complex data sets even without an internet connection, such applications can feel equally good even with a connection to the server and without it. IndexedDB is used in applications that need to store large amounts of data (for example, such an application can be something like a movie catalog of a certain service that rents them), and which do not have to maintain a permanent connection to the network for normal operation (for example, email clients , task managers, notebooks, and so on).
Here we will pay IndexedDB a bit more attention than other data storage technologies on the client, since, on the one hand, the other APIs are more widely known, and on the other, because IndexedDB is becoming increasingly popular due to the increasing complexity of web applications. .
The API
Have
You should not start working with IndexedDB, based on ideas derived from the experience of working with other DBMS. Instead, it will be useful to carefully review the documentation for this database and use the methods for which it is designed for working with it. Here is a brief overview of the core concepts of IndexedDB:
The IndexedDB system is designed to ensure that its capabilities should be enough to solve most of the data storage tasks on the client side. It is clear that it is not a universal system suitable for any use cases. Here are a few situations for which it is not designed:
In addition, when working with IndexedDB, consider that the browser may delete the database in the following cases:
In general, it can be noted that browser developers strive not to delete IndexedDB databases unless absolutely necessary.
Here is information about IndexedDB support in various browsers.
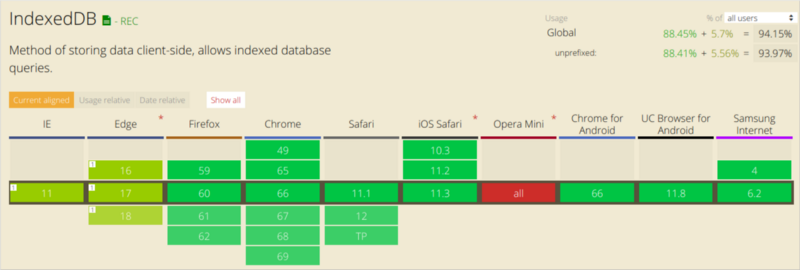
IndexedDB support by various browsers
As already mentioned, taking into account the needs of the application, it is best to choose those storage systems that have broad browser support and work in asynchronous mode, which minimizes their impact on the user interface. These criteria quite naturally lead to the following technologies:
The author of this material says that SessionStack uses various APIs to store data. For example, a library that is integrated into web applications to collect data about their work, uses cookies and session storage. The application that is intended to reproduce what was happening on the page uses cookies for the purpose of authenticating users.
Dear readers! What client-side storage technologies do you use in your web applications?

Today, in the translation of the 16th part of a series of materials devoted to everything related to JavaScript, we will talk about client-side data storage mechanisms that can be used in web development, and the choice of data storage system for a specific project.
[We advise you to read] Other 19 parts of the cycle
Часть 1: Обзор движка, механизмов времени выполнения, стека вызовов
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Data model
The data model defines the internal organization of the stored data. It affects all aspects of a web application device, it contains solutions, often trade-offs, on which the efficiency of the application and the ability of the storage system to solve its tasks depend. There is no "best" approach to the design of data models, there are no universal solutions that are suitable for all applications. The choice of data model is based on the features and needs of a particular application. Consider a few basic data storage models from which you can choose something appropriate for a particular project.
- Structured data storage model. When using this model, data is stored in tables with predefined fields. This approach is typical for database management systems based on SQL. Such systems are well adapted to work with them using queries. A well-known example of a structured browser data store is IndexedDB (although this is a NoSQL DBMS).
- Key / value data storage model. Storage for data organized in the form of key / value pairs, and associated NoSQL DBMS, allow the developer to store unstructured data and retrieve it from the storage using their unique keys. Such storages are similar to hash tables in the sense that they allow organizing access to indexed data of opaque types. A good example of a key / value value storage is the Cache API in the browser and the Apache Cassandra server DBMS.
- Data storage model in the form of sequences of bytes. When using this simple model, data is stored as a sequence of bytes of variable length. The task of the internal organization of these data is entirely solved at the application level. This model is used in file systems and other hierarchically organized data stores like cloud storage.
Methods of permanent storage of data available to the browser
The data storage methods used in web applications can be analyzed in terms of the persistent storage time for such data.
- Data storage within the session. Data in this category is stored only as long as there is a specific web session or the browser tab is active. An example of the mechanism for storing session data is the SessionStorage API.
- Storage of data on the device without reference to the lifetime of the session. This data is stored on a specific device and in between sessions, for example, when closing a browser tab with a web application page, is not deleted. An example of the mechanism for storing data for web applications on devices is the API Cache.
- Permanent data storage using global storage. This approach involves storing data that is not lost between sessions and is not tied to a specific device. Such data can be shared by various devices by users. As a result, it is the most reliable and long-term data storage method. Such data cannot be stored on the device itself, which means that to organize such a data storage scheme, you need to use some server storage. We will not go into it, since our main task is to consider ways of storing web application data on devices.
Client-side storage evaluation
Nowadays, there are quite a few browser-based APIs that allow you to organize data storage. We will look at some of them and compare them in order to make it easier for you to choose the right API.
To begin with, however, we will focus on a few general questions that should be taken into account before choosing a specific technology for data storage. Of course, first of all you need to understand how your application will be used, how its support will be organized, how it is planned to be developed. At the same time, even if you have clear answers to these questions, you can end up with several options for data storage systems from which you will need to choose the most suitable one. Here is what you should pay attention to when choosing a storage system:
- Browser support. Here it is necessary to take into account the fact that it is best to give preference to a standardized, developed API. Firstly, they are distinguished by a rather long lifespan, and secondly - they are supported by many browsers. Similar APIs, in addition, usually have good documentation and an active developer community.
- Transaction support Sometimes it is important that when working with a repository, a set of related operations have the property of atomicity, that is, that the execution of a set of operations is either completed successfully, if all operations are completed successfully, or, if at least one of them fails, it completes with an error. Databases traditionally support this feature by leveraging a transaction model, in which associated data updates can be grouped into arbitrary blocks.
- Synchronous or asynchronous operation. Some data storage APIs are synchronous, in the sense that saving or loading data from such APIs blocks the active thread until the corresponding request is completed. Using synchronous APIs can lead to blocking of the main thread, which can be expressed in the “brakes” of the user interface. Therefore, if possible, try to use asynchronous APIs.
Storage Comparison
In this section, we will look at some of the existing storage systems available to web developers, and compare them by the indicators described above.
| API | Data model | Storage technique | Browser Support | Transaction support | Synchronous or asynchronous |
|---|---|---|---|---|---|
| FileSystem | Byte sequence | Device | 52% | Not | Asynchronous |
| LocalStorage | Key / Value | Device | 93% | Not | Synchronous |
| SessionStorage | Key / Value | Session | 93% | Not | Synchronous |
| Cookie | Structured data | Device | 100% | Not | Synchronous |
| Cache | Key / Value | Device | 60% | Not | Asynchronous |
| IndexedDB | Hybrid model | Device | 83% | Yes | Asynchronous |
Now let's talk more about these methods of data storage.
API FileSystem
Using the FileSystem API, web applications can work with a dedicated area of a user's local file system. The application can view the contents of the repository, create files, perform read and write operations.
This API consists of the following main parts:
- Mechanisms to manage files and read files:
File/Blob,FileList,FileReader - Mechanisms for the creation of files and records of their data:
Blob,FileWriter - Mechanisms for working with directories and file system:
DirectoryReader,FileEntry/DirectoryEntry,LocalFileSystem
The API is
FileSystemnot standard, so it should not be used in production, as it will not work for all users. Different implementations of this API can vary greatly, and it’s also very likely that it may change in the future. The interface of
filesystemthis API is used to represent the file system. Access to the relevant objects can be obtained through the filesystem property . Some browsers offer additional APIs for creating and managing file systems.This interface does not give the webpage access to the user's file system. Instead, it allows you to work with something like a virtual disk, which is located in the sandbox created by the browser. If your application needs access to the user's file system, you will need to use other mechanisms.
A web application can request access to the virtual file system by making a call
window.requestFileSystem():// Примечание: Здесь используются префиксы Google Chrome 12:window.requestFileSystem = window.requestFileSystem || window.webkitRequestFileSystem;
window.requestFileSystem(type, size, successCallback, opt_errorCallback)If you call
requestFileSystem()for the first time, a new repository will be created for your application. It is important to remember that this is an isolated storage, that is, one web application cannot work with storage created by another application. After you gain access to the file system, you can perform most standard file and directory operations.
The API is
FileSystemvery different from other similar systems used by web applications, as it is aimed at solving data storage tasks on the client, which are not very well solved by means of databases. In general, these are applications that work with large pieces of binary data, or exchange data with applications external to the browser. Among the options for using the API
FileSystem The following can be noted:- Data uploading systems. When a user selects a file or folder that needs to be uploaded to any server, this data is copied to the local isolated storage, and then, in parts, sent to the server.
- Applications that handle large volumes of multimedia data - games, music players.
- Applications for editing sound and images that work without an Internet connection or use a large amount of local cache to speed up work. The data that such applications work with is a sequence of bytes that can be quite large. Storage for such data must support the ability to write and read them.
- Offline video players. Such programs need to download large files that can be viewed without connecting to the Internet. This may be necessary when streaming data, and to organize a convenient system for navigating the file.
- Offline email clients. Such programs can download files attached to emails and save them locally.
This is how things stand with API support by
FileSystembrowsers.Browser API FileSystem Support
LocalStorage API
The LocalStorage API , or local storage, allows you to work with the Storage object of the Document object , taking into account the principle of the same source. Data is not lost between sessions. The API is
LocalStoragesimilar to the SessionStorage API , session storage, the difference is that the data in the session storage is deleted after the page session is completed, and the data in the local storage is permanently stored. Note that the data placed in the local or session storage is tied to the page source, which is determined by the combination of protocol, host, and port.
Here is information on API support by
LocalStoragevarious browsers.Browser LocalStorage API support
API SessionStorage
The SessionStorage API allows you to work with a session's Storage object . The API is
SessionStoragesimilar to the API LocalStoragewe talked about above. The difference between them, as already mentioned, is in the storage time of the data, namely, in the case of SessionStoragedata stored as long as the session lasts. It lasts as long as the browser is open, while it persists after reloading the page. Opening a page in a new tab or window will lead to the initiation of a new session, this is different from the behavior of session cookies. At the same time, working with both SessionStorage, and with LocalStorage, it is necessary to remember that the data in such storages is tied to the source of the page. Here is information about API support by
SessionStoragevarious browsers:Browser SessionStorage API support
API Cookie
Cookies (cookies, web cookies, browser cookies) are small pieces of information that the server sends to the browser. The browser can save them and send them to the server, using them when making requests to it. They are usually used to identify a specific instance of the browser from which requests are being received. For example - in order that the user, after logging in to the system, would remain in it. A cookie is something like a session state information storage system for the HTTP protocol , which treats every request, even coming from the same browser, as completely independent of others.
Cookies are used to solve three main tasks:
- Session management. The use of cookies is based on mechanisms such as log-in systems for web applications, shopping carts in online stores, and storage of points scored in browser games. It is about storing all that the server needs to know while working with the user.
- Personalization. Cookies are used to store data about the user's preferences, about the themes of the site design chosen by him, and about other similar things.
- User monitoring. Cookies record and analyze user behavior.
At one time, cookies were used as a general-purpose data store. Although this is quite a normal way to use cookies, especially when they were the only way to store data on the client, nowadays it is not recommended to use them as such, preferring a more modern API. Cookies are sent with each request, so they can degrade performance (especially on mobile devices).
There are two types of cookies:
- Session cookies. They are deleted after the session. Web browsers can use the session recovery technique, thanks to which most session cookies are stored permanently, resulting in the session being saved even after closing and restarting the browser and opening the corresponding page.
- Permanent cookies. Persistent cookies do not lose relevance after the session. They have a certain shelf life, which is determined by either a certain date (attribute
Expires) or a certain period of time (attributeMax-Age).
Please note that confidential or other important information should not be stored in cookies or transferred to HTTP cookies, since the whole mechanism for working with cookies is inherently insecure.
If we talk about the support of cookies, they, as you probably already understood, are supported by all browsers.
API Cache
The Cache interface provides a storage mechanism for cached Request / Response object pairs . This interface is defined in the same specifications as service workers, but it is available not only to workers. The interface
Cacheis also available in the object scope window, it is not necessary to use it only with service workers. Some source may have several named objects
Cache. The developer is responsible for the implementation of how his script (for example, in the service worker) keeps the cache up to date. Items stored in the cache are not updated until an explicit request to update them is made, their storage does not expire, they can only be deleted from the cache. To open a named cache object, you can use the CacheStorage.open () command , after which, referring to it, you can call the cache management commands. In addition, the developer is responsible for periodic cache flushing. Each browser has a hard-coded limit on the size of the cache that is allocated to a particular source. You can find out the approximate value of the cache quota by using the StorageEstimate API .
The browser does everything in its power to maintain a certain amount of available cache space, but it can delete the cache for some source. Usually, the browser either deletes the entire cache or doesn’t touch it at all. Using caches, do not forget to distinguish them according to the versions of your scripts, for example, including the version of the script in the name of the cache. This is done in order to ensure the safe operation of various versions of scripts with a cache. Details on this can be found here .
The CacheStorage interface provides storage for Cache objects . Here are the tasks for which this interface is responsible:
- Provide a list of all the named caches that a service worker can work with , or another type of worker. You can work with the cache through the window object .
- Supports mapping between string names and corresponding type objects
Cache.
To get an instance of an object
Cache, use the CacheStorage.open () command . To find out if a Request object is the key of an object
Cacheit manages CacheStorage, use the CacheStorage.match () method . You
CacheStoragecan access it through the global caches property .IndexedDB API
The IndexedDB API is a DBMS that allows you to store data using browser tools. Since it allows you to create web applications that have the ability to work with complex data sets even without an internet connection, such applications can feel equally good even with a connection to the server and without it. IndexedDB is used in applications that need to store large amounts of data (for example, such an application can be something like a movie catalog of a certain service that rents them), and which do not have to maintain a permanent connection to the network for normal operation (for example, email clients , task managers, notebooks, and so on).
Here we will pay IndexedDB a bit more attention than other data storage technologies on the client, since, on the one hand, the other APIs are more widely known, and on the other, because IndexedDB is becoming increasingly popular due to the increasing complexity of web applications. .
▍Internal IndexedDB mechanisms
The API
IndexedDBallows you to save into the database and read from it the data of objects using the "key". All changes made to the database occur in transactions. Like most similar solutions, IndexedDB follows the policy of one source . As a result, an application can access only data from its own domain, but not data from other domains. IndexedDB- this is an asynchronous API that can be used in most contexts, including the web workers . Previously, there was also a synchronous version of this API, intended for web workers, but it was removed from the specification because it was not particularly interesting to web developers. Have
IndexedDBthere was a competitor in the WebSQL database, but work on this standard was discontinued by the W3C many years ago. While IndexedDB and WebSQL are solutions for storing data on the client, their functionality is different. WebSQL is a relational DBMS, and IndexedDB is a system based on indexed tables. You should not start working with IndexedDB, based on ideas derived from the experience of working with other DBMS. Instead, it will be useful to carefully review the documentation for this database and use the methods for which it is designed for working with it. Here is a brief overview of the core concepts of IndexedDB:
- IndexedDB databases store data in key / value format. Values can be complex structured objects, and keys can be properties of such objects. Indexes can be created on the basis of any property of the object, which can speed up the search for data and simplify their sorting. Keys are also binary objects.
- DBMS IndexedDB is based on a transactional model. All operations performed with the database always occur in the context of a transaction . As a result, for example, you cannot execute commands or open cursors outside of transactions. In addition, transactions are confirmed automatically; you cannot manually confirm them.
- The IndexedDB API, for the most part, is asynchronous. This API does not provide the requested data, simply returning it in response to some command. Instead, when requesting data, you must pass the callback function to the appropriate method. The synchronous approach is not used either to save data to the database or to load it from it. Instead, the application performs a database query that describes the desired operation. After the operation is completed, an event occurs, notifying the application that the operation was either successful or not. This approach is not particularly different from the operation of the XMLHttpRequest API , or many other JavaScript mechanisms.
- IndexedDB uses many queries. Requests are objects that receive events about the success or failure of the operation. They have properties
onsuccessandonerrorwhich can be assigned to the corresponding event listeners, as well as - propertiesreadyState,result,errorCodeanalyzing which can be found on the status of the request. - IndexedDB is an object-oriented database. This is not a relational DBMS, the tables of which are collections of rows and columns. This fundamental feature affects the way in which they design and build applications using IndexedDB.
- IndexedDB does not use SQL. This DBMS uses queries on indexes that return cursors that are used to work with data sets that are the results of queries. If you are not familiar with NoSQL systems, take a look at this material.
- A single source policy is applied to IndexedDB repositories. A source is a combination of the domain, protocol, and port URL of the document in which the script runs. Each source can work only with its own set of databases, and each database has a unique name that identifies it within the databases of the same source.
Index IndexedDB Restrictions
The IndexedDB system is designed to ensure that its capabilities should be enough to solve most of the data storage tasks on the client side. It is clear that it is not a universal system suitable for any use cases. Here are a few situations for which it is not designed:
- Sort data taking into account the features of different languages. Not all languages have strings equally sorted, and IndexedDB does not support sorting, taking into account the characteristics of different languages. At the same time, although the database cannot perform such sorting, the information obtained from the database can be sorted by means of the application.
- Synchronization. The API was not designed with the ability to synchronize the local database with the server. Of course, such synchronization is possible, but the developer will have to implement the corresponding mechanisms independently.
- Full text search. The IndexedDB API does not support something like the LIKE operator from SQL.
In addition, when working with IndexedDB, consider that the browser may delete the database in the following cases:
- The user gave the command to delete data. Many browsers have settings sections in which there are tools that allow the user to delete all data saved for a certain website, including cookies, bookmarks, saved passwords, and IndexedDB data.
- The browser works in anonymous mode. Such modes are called in different browsers in different ways. In Chrome, this is “incognito mode,” in Firefox, “private mode.” After completing an anonymous session, the browser will delete the database.
- Disk overflow or reaching a certain specified limit.
- Data corruption.
In general, it can be noted that browser developers strive not to delete IndexedDB databases unless absolutely necessary.
Here is information about IndexedDB support in various browsers.
IndexedDB support by various browsers
Choosing a storage system
As already mentioned, taking into account the needs of the application, it is best to choose those storage systems that have broad browser support and work in asynchronous mode, which minimizes their impact on the user interface. These criteria quite naturally lead to the following technologies:
- For offline storage, use API Cache . It is available in any browser that supports the service workers needed to create web applications that can work without being connected to the Internet. The Cache API is the perfect choice for storing some page-related resources.
- To store data that forms the state of the application, or some kind of information created by users, use IndexedDB. This technology, in comparison with caching, supports more browsers, which expands the possibilities of users of applications based on IndexedDB to work offline.
Results
The author of this material says that SessionStack uses various APIs to store data. For example, a library that is integrated into web applications to collect data about their work, uses cookies and session storage. The application that is intended to reproduce what was happening on the page uses cookies for the purpose of authenticating users.
Dear readers! What client-side storage technologies do you use in your web applications?