Architectural flaw CouchDB
My favorite topic in programming is to delve into the negative effects that are presented to us by the most, in our opinion, trivial operations.
One such issue is deleting records in the database. This operation, according to most programmers, speeds up work with the database and makes it more compact. The trick is that this is not true. And if with relational databases this is only partially true, then with NoSQL it can be a complete lie.
We’ll talk about such a problem in Apache CouchDB later.
Picture in topic:
Data in any database is stored on the principle of a file system: there is a data placement map and a file in which they are directly placed. For SQL, this is usually a table, and for NoSQL, it is usually a tree.
When we delete data, as in the case of the file system, the database will not waste time re-creating the map file and data file without the record that we want to delete. It will simply mark the entry as deleted on the map. This is easy to verify, for this we will create a simple table in MySQL using MyISAM, add one record there, then delete and see the statistics:

To optimize this, we need to recreate the map file and data file. Run:
and get:

Interestingly, the table in the non-optimized version, oddly enough, works almost as fast as in the optimized one. This happens because the very principle of storing relational data is usually quite simple and easy to calculate how much seek needs to be done to skip deleted records. The foregoing, of course, does not mean that overhead can be ignored, but it is enough to write a simple bash script that will optimize the data according to a schedule, and you will not have to do any additional work in the program code.
Take a simple document:
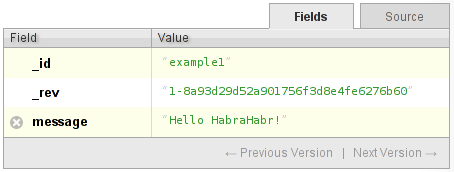
and delete it. What's happening? The database marks the document as deleted. How does she do it? It reads the document, removes all fields from it, inserts the additional _deleted: true property, and writes the document under a new revision. Example:

Now, if you try to get the latest version of the document, you will receive a 404 error indicating that the document has been deleted. However, if you turn to the first revision of the document, it will be available.
Next we make compact. For deleted documents, the database will automatically delete all revisions, except the one that says that the document has been deleted. This is done in order to inform another database about this during replication. This revision remains forever in the database and cannot be deleted. (True, you can use _purge, but it's a crutch with a lot of negative effects and is not recommended for production.)
In CouchDB, data is stored as a B + tree . A deleted document, even though it is a dummy, remains part of the tree. This means that this dead record is taken into account. And it is taken into account not only when building indexes, but also during the usual insertion of a document, since when a document is inserted, a tree may be rebuilt, and the more records there are, the slower the process.
Finally, it remains to be understood how fast Erlang is. Now, if we take synthetic tests , we can see that Erlang's performance is close to PHP. That is, the B + tree is not manipulated by the fastest language.
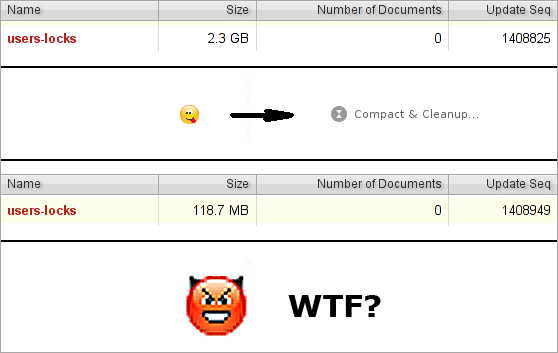
If WRITE is not the rarest operation, then having several million documents in the tree, you may suddenly (and unexpectedly) discover that the database is starting to slow down a lot. For example, you use CouchDB to store documents with low life expectancy (sessions, lock files, queues). Let's take a graph from real production:
It can be seen from the graph that the peaks are pretty sharp. A sharp increase in peak is not always predictable. Sometimes we have about 2 million database updates (about 1 million documents in the tree) and it works quite well, but another 100 thousand appear, and the performance crashes into the pipe. A sharp decline in peak occurs because we re-create the base and performance for several weeks becomes acceptable.
One such issue is deleting records in the database. This operation, according to most programmers, speeds up work with the database and makes it more compact. The trick is that this is not true. And if with relational databases this is only partially true, then with NoSQL it can be a complete lie.
We’ll talk about such a problem in Apache CouchDB later.
Picture in topic:
How data is stored
Data in any database is stored on the principle of a file system: there is a data placement map and a file in which they are directly placed. For SQL, this is usually a table, and for NoSQL, it is usually a tree.
When we delete data, as in the case of the file system, the database will not waste time re-creating the map file and data file without the record that we want to delete. It will simply mark the entry as deleted on the map. This is easy to verify, for this we will create a simple table in MySQL using MyISAM, add one record there, then delete and see the statistics:
To optimize this, we need to recreate the map file and data file. Run:
OPTIMIZE TABLE guest;and get:
Interestingly, the table in the non-optimized version, oddly enough, works almost as fast as in the optimized one. This happens because the very principle of storing relational data is usually quite simple and easy to calculate how much seek needs to be done to skip deleted records. The foregoing, of course, does not mean that overhead can be ignored, but it is enough to write a simple bash script that will optimize the data according to a schedule, and you will not have to do any additional work in the program code.
It should be noted that the above is not entirely suitable for InnoDB, where there are even more nuances, but today there is an article about CouchDB, and not about MySQL.
How removal works in CouchDB
Take a simple document:
and delete it. What's happening? The database marks the document as deleted. How does she do it? It reads the document, removes all fields from it, inserts the additional _deleted: true property, and writes the document under a new revision. Example:
Now, if you try to get the latest version of the document, you will receive a 404 error indicating that the document has been deleted. However, if you turn to the first revision of the document, it will be available.
Next we make compact. For deleted documents, the database will automatically delete all revisions, except the one that says that the document has been deleted. This is done in order to inform another database about this during replication. This revision remains forever in the database and cannot be deleted. (True, you can use _purge, but it's a crutch with a lot of negative effects and is not recommended for production.)
How does it affect work?
In CouchDB, data is stored as a B + tree . A deleted document, even though it is a dummy, remains part of the tree. This means that this dead record is taken into account. And it is taken into account not only when building indexes, but also during the usual insertion of a document, since when a document is inserted, a tree may be rebuilt, and the more records there are, the slower the process.
Control head
Finally, it remains to be understood how fast Erlang is. Now, if we take synthetic tests , we can see that Erlang's performance is close to PHP. That is, the B + tree is not manipulated by the fastest language.
How it slows down in reality
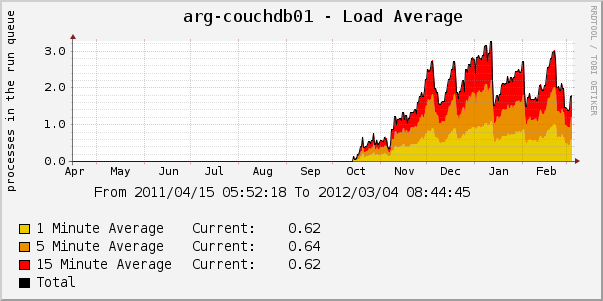
If WRITE is not the rarest operation, then having several million documents in the tree, you may suddenly (and unexpectedly) discover that the database is starting to slow down a lot. For example, you use CouchDB to store documents with low life expectancy (sessions, lock files, queues). Let's take a graph from real production:
It can be seen from the graph that the peaks are pretty sharp. A sharp increase in peak is not always predictable. Sometimes we have about 2 million database updates (about 1 million documents in the tree) and it works quite well, but another 100 thousand appear, and the performance crashes into the pipe. A sharp decline in peak occurs because we re-create the base and performance for several weeks becomes acceptable.
conclusions
- CouchDB stores all documents in a B + tree, which is periodically rebuilt. Erlang is not the fastest language for this. Do not use CouchDB for documents with a low lifespan, otherwise you will have too large a tree, because documents will never be deleted from it.
- Even if you do not delete documents, you will get a lag to add new ones when you have several million records.
- I advise you to pay attention to article 16 practical tips for working with CouchDB .
- It becomes clear why Damien Katz, creator of CouchDB, has decided to fork CouchBase and rewrite the kernel in C . By the way, CouchBase contains built-in memcached, which allows you to store documents with low life expectancy in a separate area.