Monitoring System for Windows servers on pure SQL, and how I had secretly dragged it into the Production
A long time ago in a galaxy far, far away there was a company grown from a startup to something much bigger, but for a while the IT department was still compact and very efficient. That company hosted on prem hundreds of virtual Windows servers, and of course these servers were monitored. Even before I joined the company, NetIQ had been chosen as a monitoring solution.
One of my new tasks was to support NetIQ. The person, who worked with NetIQ before, said a lot about his experience with NetIQ, unfortunately, if I try to put it here it would be just a long line of ‘****’ characters. Soon I realized why. Steve Jobs is probably spinning in his grave looking at the interface like this:
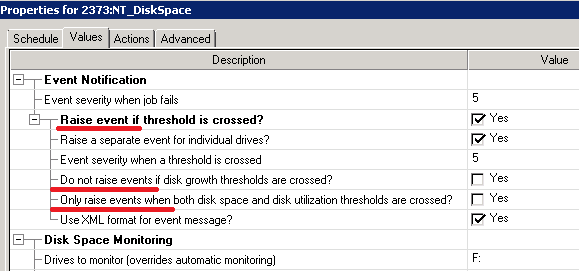
In the one line the logic of checkbox is positive (raise event), in the next one is negative (Do not raise event). So how ‘Raise event only if’ works? I have no idea.
However, there was much worse thing about NetIQ: it’s monitoring agent was very fragile. Much more vulnerable than Windows itself. Low memory? Agent is down. CPU is 100%? Agent is unresponsive. 0 free bytes left on a disk drive? Well, to send an alert message an agent must first save it to a file on a disk… So yes, you don’t get any alerts in that case.
However, “don’t fix what is not broken”, and somehow, we lived with it until our company was purchased by a much bigger one. When a huge company buys a small one, the small one dissipates as a droplet of water in a sea. However, in our case we (from the IT perspective) were not much smaller than the IT of a bigger company, and it was obvious from the very beginning that the merger would be very tricky. So tricky that for a while we were left alone as an independent department and all business and IT processes were kept the same – just under the umbrella of the new name. It reminds me about the moment, when THE RING was laying on the lava but haven’t started melting yet.

Meanwhile, I had upgraded NetIQ from version 7 to 8, and later to version 9. This was when all our problems started. We were using NetIQ to monitor only few basic things: availability of a server, memory, CPU, disk space and the most important for us – status of home-grown services. When any home-grown service startup type was set to “Automatic” then it should be always running (otherwise we consider it crashed). There should be no cases like this one:

So, NetIQ stopped monitoring the status of the services. After a week of experimentation and another week of calls with NetIQ support, we had learned that “it was not a bug, it was a feature” and alert was triggered only when a process exited with a specific exit code. And our services crashed with ANY codes.
At that point it was too late to roll back. As you understand, as soon as we had discovered that our critical infrastructure was not monitored we had immediately … eh… done nothing. Because at that time the process of “melting” of our company into a bigger one reached an active phase, and it looked like this:
I heard sounds of thunder from very far above, and it looked like the gods on Olympus were deciding the fate of the world, while I was trying to distract them with my tiny technical problem. At the same time, I couldn’t sleep knowing that our monitoring system was half blind.
After I had realized that there was nothing to wait, I decided to create a quick and dirty solution – tiny service scanner which should go over all servers to check the services and to send emails for services which were down, exactly like the old version of NetIQ did. You might think that the PowerShell script is the best way to do it but… If all you have is a hammer, everything looks like a nail. If you are a DBA who worked with SQL since the version 6.0 then… Here is a short extract from the code, so you can understand what I am talking about:
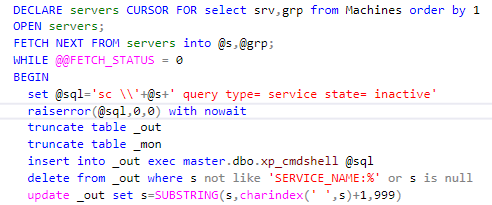
It took me only few hours to write the first solution. During next few days I added an audit, parameters and other fancy things. After I examined what WMIC command could do, I was not able to stop. I don’t remember exactly what happened during next 2 weeks — everything was kinda blurry, but when I woke up from it all features of NetIQ were implemented using pure SQL.
I haven’t just copied the NetIQ functionality “as is”, I had implemented everything I ever dreamed of. In LOWDISK email alert you also get a PDF attached with a disk usage growth chart so you can instantly understand if the growth was genuine or something went wrong. Low memory – and you get not only the chart, but also a memory distribution by process, plus for w3wp.exe you get a pool name appended. I had also implemented smart reminders with flood protection and many other fancy things. BTW, the list of virtual servers was pulled automatically from VMware repositories. Just looking on the alert subjects in a mobile client you could instantly say what was going on – even without opening the emails:

Modern developers got used to create abstraction levels to an extent that it harms their ability to write a simple straightforward code. They can’t create a monitoring system without saying: “Ok, so for any server we can run any set of scripts with rules from a repository… How flexible…”. But the monitoring of few fundamental things like Memory, CPU, disk, services status is unique. By implementing the verification of these basic conditions with a level of abstraction they end with a code which works equally bad for all cases. This is an example from the SCOM system. I am sure it was implemented exactly by the specs:

But the major advantage of the new system was that there was no agent at all. No agents – nothing to install, nothing to be broken. The system was simple and reliable as a hummer.
Few next month I came to work and spent an hour or two working on my new creation – slowly, without any deadlines and ETAs, leaving almost no technical debt. After a while I forced myself to stop.
NetIQ was still in the production, but people definitely preferred alerts from the new system, more reliable and informative. Gradually I moved all alert “subscribers” to the new system, keeping, however, the old system alive. Meanwhile, the process of “melting” of our old company into a bigger one had reached its final stage:

Well, everything has an end. I was even surprised that I had a chance to play with such things in a big bureaucratic company. After a month of preparation, I was told that “ok, in a week we shut down NetIQ and move to SCOM as a corporate standard”. I shut down NetIQ (I have to admit, I hated it so much that it was one of the happiest moments in my career) and started to wait for SCOM to arrive. But there was none. Nothing since a week, and month, and even a quarter.
We got SCOM only after full 6 months – someone had forgotten about the cost of licenses for the huge number of servers we had. In these 6 months many departments became so dependent of the new system, which kept not only the alerts but also the performance metrics and inventories that it was out of the question to shut it down. It became a second, backup system. For the auditors there is SCOM, for the really useful things – there is my creation.
From time to time managers on different levels of hierarchy stepped over the alerts of that system and asked – what is it? Recently I had explained the whole story behind this product. They laughed and let that system live, and for me it was a chance to write a code like when I was a student – guided not by specs but based on my own understanding, like a hobby. It was a great fun.
Article in russian
One of my new tasks was to support NetIQ. The person, who worked with NetIQ before, said a lot about his experience with NetIQ, unfortunately, if I try to put it here it would be just a long line of ‘****’ characters. Soon I realized why. Steve Jobs is probably spinning in his grave looking at the interface like this:
In the one line the logic of checkbox is positive (raise event), in the next one is negative (Do not raise event). So how ‘Raise event only if’ works? I have no idea.
However, there was much worse thing about NetIQ: it’s monitoring agent was very fragile. Much more vulnerable than Windows itself. Low memory? Agent is down. CPU is 100%? Agent is unresponsive. 0 free bytes left on a disk drive? Well, to send an alert message an agent must first save it to a file on a disk… So yes, you don’t get any alerts in that case.
However, “don’t fix what is not broken”, and somehow, we lived with it until our company was purchased by a much bigger one. When a huge company buys a small one, the small one dissipates as a droplet of water in a sea. However, in our case we (from the IT perspective) were not much smaller than the IT of a bigger company, and it was obvious from the very beginning that the merger would be very tricky. So tricky that for a while we were left alone as an independent department and all business and IT processes were kept the same – just under the umbrella of the new name. It reminds me about the moment, when THE RING was laying on the lava but haven’t started melting yet.
Meanwhile, I had upgraded NetIQ from version 7 to 8, and later to version 9. This was when all our problems started. We were using NetIQ to monitor only few basic things: availability of a server, memory, CPU, disk space and the most important for us – status of home-grown services. When any home-grown service startup type was set to “Automatic” then it should be always running (otherwise we consider it crashed). There should be no cases like this one:
So, NetIQ stopped monitoring the status of the services. After a week of experimentation and another week of calls with NetIQ support, we had learned that “it was not a bug, it was a feature” and alert was triggered only when a process exited with a specific exit code. And our services crashed with ANY codes.
At that point it was too late to roll back. As you understand, as soon as we had discovered that our critical infrastructure was not monitored we had immediately … eh… done nothing. Because at that time the process of “melting” of our company into a bigger one reached an active phase, and it looked like this:
I heard sounds of thunder from very far above, and it looked like the gods on Olympus were deciding the fate of the world, while I was trying to distract them with my tiny technical problem. At the same time, I couldn’t sleep knowing that our monitoring system was half blind.
After I had realized that there was nothing to wait, I decided to create a quick and dirty solution – tiny service scanner which should go over all servers to check the services and to send emails for services which were down, exactly like the old version of NetIQ did. You might think that the PowerShell script is the best way to do it but… If all you have is a hammer, everything looks like a nail. If you are a DBA who worked with SQL since the version 6.0 then… Here is a short extract from the code, so you can understand what I am talking about:
It took me only few hours to write the first solution. During next few days I added an audit, parameters and other fancy things. After I examined what WMIC command could do, I was not able to stop. I don’t remember exactly what happened during next 2 weeks — everything was kinda blurry, but when I woke up from it all features of NetIQ were implemented using pure SQL.
I haven’t just copied the NetIQ functionality “as is”, I had implemented everything I ever dreamed of. In LOWDISK email alert you also get a PDF attached with a disk usage growth chart so you can instantly understand if the growth was genuine or something went wrong. Low memory – and you get not only the chart, but also a memory distribution by process, plus for w3wp.exe you get a pool name appended. I had also implemented smart reminders with flood protection and many other fancy things. BTW, the list of virtual servers was pulled automatically from VMware repositories. Just looking on the alert subjects in a mobile client you could instantly say what was going on – even without opening the emails:
Modern developers got used to create abstraction levels to an extent that it harms their ability to write a simple straightforward code. They can’t create a monitoring system without saying: “Ok, so for any server we can run any set of scripts with rules from a repository… How flexible…”. But the monitoring of few fundamental things like Memory, CPU, disk, services status is unique. By implementing the verification of these basic conditions with a level of abstraction they end with a code which works equally bad for all cases. This is an example from the SCOM system. I am sure it was implemented exactly by the specs:
But the major advantage of the new system was that there was no agent at all. No agents – nothing to install, nothing to be broken. The system was simple and reliable as a hummer.
Few next month I came to work and spent an hour or two working on my new creation – slowly, without any deadlines and ETAs, leaving almost no technical debt. After a while I forced myself to stop.
NetIQ was still in the production, but people definitely preferred alerts from the new system, more reliable and informative. Gradually I moved all alert “subscribers” to the new system, keeping, however, the old system alive. Meanwhile, the process of “melting” of our old company into a bigger one had reached its final stage:
Well, everything has an end. I was even surprised that I had a chance to play with such things in a big bureaucratic company. After a month of preparation, I was told that “ok, in a week we shut down NetIQ and move to SCOM as a corporate standard”. I shut down NetIQ (I have to admit, I hated it so much that it was one of the happiest moments in my career) and started to wait for SCOM to arrive. But there was none. Nothing since a week, and month, and even a quarter.
We got SCOM only after full 6 months – someone had forgotten about the cost of licenses for the huge number of servers we had. In these 6 months many departments became so dependent of the new system, which kept not only the alerts but also the performance metrics and inventories that it was out of the question to shut it down. It became a second, backup system. For the auditors there is SCOM, for the really useful things – there is my creation.
From time to time managers on different levels of hierarchy stepped over the alerts of that system and asked – what is it? Recently I had explained the whole story behind this product. They laughed and let that system live, and for me it was a chance to write a code like when I was a student – guided not by specs but based on my own understanding, like a hobby. It was a great fun.
Article in russian