Geo-referencing sites: how is this done?
Every day more and more information accumulates on the Internet. And it is thanks to the Internet that every person can get access to the data necessary for him. On the other hand, it is almost impossible to navigate in such a large array without using special tools. And search engines, of course, become such an instrument, helping people to navigate the ever-expanding sea of information.

From the moment that search engines have taken their first steps, developers spend a huge amount of effort on improving the organization, navigation and search of documents. Today, perhaps the most used technique is a keyword search, giving users the ability to find information on a given topic. At the same time, the global expansion of the Internet leads to the fact that the amount of information found by a person when searching using only keywords is too large. By typing the same word in the search bar, different people may want different results.
The figures show how the same query looks like, asked by users living in the cities of Novosibirsk and Yekaterinburg. It is clear that asking the search engine the word "airport", people want to get the address of the website of the city airport terminal:
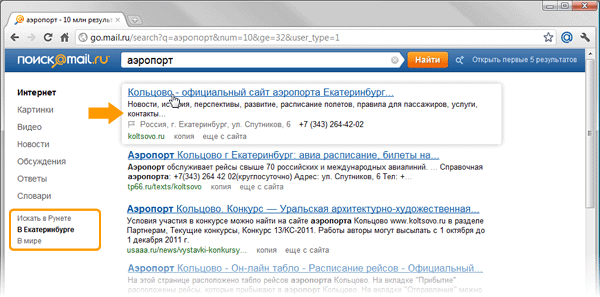

It is impossible to solve such a problem using a keyword search. In the same time. it becomes the starting point for the formation of high-level semantic queries that can be used to find such information. Thus, additional metadata can be attached to the page, using which. improve the quality of the search engine response. For example, for geo-dependent queries, such metadata will be information about the geographical location of the resource. Knowing where the desired object is physically located and having knowledge of the user's position, one can relate these data and give the person information about the desired object.
In the general case, the task can be divided into two parts:
a) determining the location of the user;
b) determining the location of the resource sought.
In the article, we propose a solution to the second part of the problem, i.e. How to determine the location of the Internet resource.
There are many sources where you can get information about the geography of the site. These include the following: WHOIS base, directories, page context, etc. In this article, we will consider how you can link a site to geography based on an analysis of the page context.
As a rule, the sources that can supply information about geography are the sites of organizations where data on their locations — addresses and telephones — are published. In our case, we will divide the solution to the problem of extracting information into several parts:
• definition of standard site templates on which information about the location of the organization can be placed;
• extracting candidates for subsequent binding of the site to geographical information;
• filtering candidates.
At this stage, we try to determine the set of search patterns for pages on which the proposed address is located. One of the most common locations for contact information is the root page. At the same time, this page is not always a reliable source of information, because there are sites, for example, posting ads that include well-readable addresses, some of which can go to the main page, so we will filter the addresses extracted from the main page in the future . Another common location for contact information is the Contact page. As a rule, there are links to it from the main page, and in most cases they are subject to a number of rules. For example, the text of the link may contain the word “contacts”, “About us”, etc.
After analyzing the site structure of various organizations, we select the most common typical page templates on which you can find the address. Briefly, you can record the following three steps:
• Search for addresses on the root page of the site.
• Search for links to the Contact page.
• Search for addresses on the Contact page.
As we said above, at the first stage we get the most likely pages on which contact information can be placed. From these pages you can extract something that is very similar to the address. Why is it “very similar” ?, because for extraction we will use the hidden Markov model.
Before starting to build our model, we will decide on the data and try to simplify things a bit. To begin with, we will determine that the number of significant cities in Russia is finite and, accordingly, can be described by a dictionary. Got the first simplification - using the dictionary of cities, you can find the reference point on the page. It can be assumed that if we are on the most likely contact page, then the city we found may be included in the address.
Move on. If you move from the entry point to the left or right. you can get the address, but you need a system for evaluating the sequence of characters that are likely to be in the address. HMM or the hidden Markov model can help us with this. But to build the model, we need to determine the following data:
• the states of the model s belonging to the set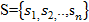 , that is, what can be taken as states;
, that is, what can be taken as states;
• elements of the sequence v belonging to the set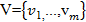 ; i.e., what can be taken as elements of a sequence.
; i.e., what can be taken as elements of a sequence.
For example, take the address: 654007, Novokuznetsk, st. Ordzhonikidze, 36, and select elements of the sequence V and state S.
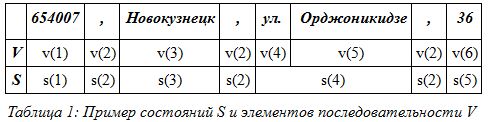
As you can see table 1, we got six elements of the sequence and five states of the model. Thus, if we take individual words for the elements of the sequence, we can imagine what this will lead to when calculating the model. But we will make several simplifications to reduce the number of states of the set S and the number of elements in the sequence of the set V. If you look closely at table 1, you will notice that the state elements s (2) and the elements of the sequence v (2) are repeated. If all the elements of the address are divided into types, then this will lead us to a decrease in the state of the model. For example, you can combine all street modifiers into one element. In this case, the street, highway, lane ... form an element of the sequence . Thus, we get the second simplification - the translation of many well-known geographical names into one element of the sequence. Let us give an example in the form of a table:
. Thus, we get the second simplification - the translation of many well-known geographical names into one element of the sequence. Let us give an example in the form of a table:

Thus, we get only 19 typed elements of the set V. The same can be done with the set S, that is, with the states of the model. For example, if during the analysis the model gives out information about the street, we say that the model is in state S (street), if the model gives out information about the city, we say. that the model is in state T (city). We get the third simplification of the model states. Examples are given in table 3.

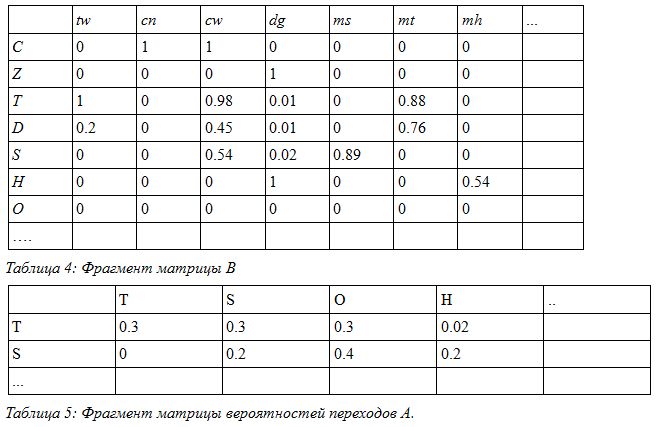
Now, knowing the description of the model states and sequence elements, we create the training set on which our model is built. From the training set, we need to obtain the transition probability matrix A and B as the probability matrix for obtaining data from the set V at the moment when the model is in state s.
For example, in our case, fragments of the matrix B and A look as follows:
For completeness, we also need to take into account the initial distributions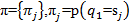 . And now, when we have built the model, in a short record it looks like
. And now, when we have built the model, in a short record it looks like 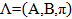 we take our sequence D surrounding the found city and find the probability that the words, that is, the data, are similar to the model. We consider the probability:
we take our sequence D surrounding the found city and find the probability that the words, that is, the data, are similar to the model. We consider the probability:
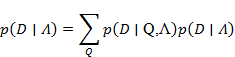
Since in this problem it is only necessary to calculate the probability of an address sequence appearing in the vicinity of the city, we use the “forward-backward” algorithm to solve it.
The extracted addresses are filtered. The first stage of filtering is that additional information is also extracted from the page, such as a phone, which is mapped to one or more addresses extracted from the page.
One of the comparisons is checking the region code indicated in the phone number against the city specified in the address.
The second stage of filtering includes a set of rules of thumb that are superimposed on the selected address. Such rules, for example, include a restriction on the possible number of digits contained in the house number. After applying a number of rules, the extracted address is either accepted as one of the addresses describing the location of the organization, or rejected.
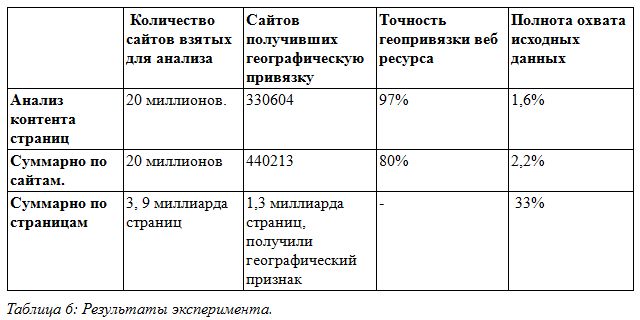
For the experiments, we took a database of pages downloaded from the Internet, containing about 20 million sites and 3.9 billion pages. From this data, based on the analysis of the content of the pages, the site was geo-referenced using the algorithm described above. The results are presented in table 6.
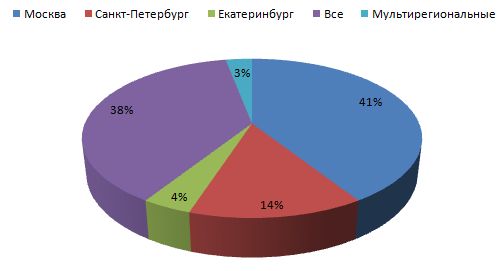
As experiments have shown, the described method is quite accurate. In his case, the accuracy reaches 97%. This is due to a number of restrictions, namely: the use of predefined templates to find a page with an address; using the dictionary of cities; matching phone numbers and cities, as well as existing formal rules for recording addresses. All these restrictions allow you to achieve high accuracy when determining the geography of a web resource. On the other hand, these restrictions lead to a decrease in completeness in cases where the address is recorded without a direct indication of the city or with an unknown city, if the contact page is located at an address that is not described in the known search templates. Diagram 1 shows the distribution of sites by region - as can be seen from the diagram, the largest region in which the sites fall,
At the moment, we use the described method as one of the methods for extracting information about the geo-referencing of sites and add it to the index of a search engine. Thus, a person can search for information on the sites of his region. Additionally, the extracted address can be displayed in address snippets.
Dmitry Solovyov Search
Developer Mail.Ru
From the moment that search engines have taken their first steps, developers spend a huge amount of effort on improving the organization, navigation and search of documents. Today, perhaps the most used technique is a keyword search, giving users the ability to find information on a given topic. At the same time, the global expansion of the Internet leads to the fact that the amount of information found by a person when searching using only keywords is too large. By typing the same word in the search bar, different people may want different results.
The figures show how the same query looks like, asked by users living in the cities of Novosibirsk and Yekaterinburg. It is clear that asking the search engine the word "airport", people want to get the address of the website of the city airport terminal:
It is impossible to solve such a problem using a keyword search. In the same time. it becomes the starting point for the formation of high-level semantic queries that can be used to find such information. Thus, additional metadata can be attached to the page, using which. improve the quality of the search engine response. For example, for geo-dependent queries, such metadata will be information about the geographical location of the resource. Knowing where the desired object is physically located and having knowledge of the user's position, one can relate these data and give the person information about the desired object.
In the general case, the task can be divided into two parts:
a) determining the location of the user;
b) determining the location of the resource sought.
In the article, we propose a solution to the second part of the problem, i.e. How to determine the location of the Internet resource.
There are many sources where you can get information about the geography of the site. These include the following: WHOIS base, directories, page context, etc. In this article, we will consider how you can link a site to geography based on an analysis of the page context.
We analyze the content of the site pages
As a rule, the sources that can supply information about geography are the sites of organizations where data on their locations — addresses and telephones — are published. In our case, we will divide the solution to the problem of extracting information into several parts:
• definition of standard site templates on which information about the location of the organization can be placed;
• extracting candidates for subsequent binding of the site to geographical information;
• filtering candidates.
We define standard patterns
At this stage, we try to determine the set of search patterns for pages on which the proposed address is located. One of the most common locations for contact information is the root page. At the same time, this page is not always a reliable source of information, because there are sites, for example, posting ads that include well-readable addresses, some of which can go to the main page, so we will filter the addresses extracted from the main page in the future . Another common location for contact information is the Contact page. As a rule, there are links to it from the main page, and in most cases they are subject to a number of rules. For example, the text of the link may contain the word “contacts”, “About us”, etc.
After analyzing the site structure of various organizations, we select the most common typical page templates on which you can find the address. Briefly, you can record the following three steps:
• Search for addresses on the root page of the site.
• Search for links to the Contact page.
• Search for addresses on the Contact page.
Retrieving the Address
As we said above, at the first stage we get the most likely pages on which contact information can be placed. From these pages you can extract something that is very similar to the address. Why is it “very similar” ?, because for extraction we will use the hidden Markov model.
Before starting to build our model, we will decide on the data and try to simplify things a bit. To begin with, we will determine that the number of significant cities in Russia is finite and, accordingly, can be described by a dictionary. Got the first simplification - using the dictionary of cities, you can find the reference point on the page. It can be assumed that if we are on the most likely contact page, then the city we found may be included in the address.
Move on. If you move from the entry point to the left or right. you can get the address, but you need a system for evaluating the sequence of characters that are likely to be in the address. HMM or the hidden Markov model can help us with this. But to build the model, we need to determine the following data:
• the states of the model s belonging to the set
, that is, what can be taken as states; • elements of the sequence v belonging to the set
; i.e., what can be taken as elements of a sequence. For example, take the address: 654007, Novokuznetsk, st. Ordzhonikidze, 36, and select elements of the sequence V and state S.
As you can see table 1, we got six elements of the sequence and five states of the model. Thus, if we take individual words for the elements of the sequence, we can imagine what this will lead to when calculating the model. But we will make several simplifications to reduce the number of states of the set S and the number of elements in the sequence of the set V. If you look closely at table 1, you will notice that the state elements s (2) and the elements of the sequence v (2) are repeated. If all the elements of the address are divided into types, then this will lead us to a decrease in the state of the model. For example, you can combine all street modifiers into one element. In this case, the street, highway, lane ... form an element of the sequence
. Thus, we get the second simplification - the translation of many well-known geographical names into one element of the sequence. Let us give an example in the form of a table: Thus, we get only 19 typed elements of the set V. The same can be done with the set S, that is, with the states of the model. For example, if during the analysis the model gives out information about the street, we say that the model is in state S (street), if the model gives out information about the city, we say. that the model is in state T (city). We get the third simplification of the model states. Examples are given in table 3.
Now, knowing the description of the model states and sequence elements, we create the training set on which our model is built. From the training set, we need to obtain the transition probability matrix A and B as the probability matrix for obtaining data from the set V at the moment when the model is in state s.
For example, in our case, fragments of the matrix B and A look as follows:
For completeness, we also need to take into account the initial distributions
. And now, when we have built the model, in a short record it looks like we take our sequence D surrounding the found city and find the probability that the words, that is, the data, are similar to the model. We consider the probability:Since in this problem it is only necessary to calculate the probability of an address sequence appearing in the vicinity of the city, we use the “forward-backward” algorithm to solve it.
We filter the received data
The extracted addresses are filtered. The first stage of filtering is that additional information is also extracted from the page, such as a phone, which is mapped to one or more addresses extracted from the page.
One of the comparisons is checking the region code indicated in the phone number against the city specified in the address.
The second stage of filtering includes a set of rules of thumb that are superimposed on the selected address. Such rules, for example, include a restriction on the possible number of digits contained in the house number. After applying a number of rules, the extracted address is either accepted as one of the addresses describing the location of the organization, or rejected.
What did you get?
For the experiments, we took a database of pages downloaded from the Internet, containing about 20 million sites and 3.9 billion pages. From this data, based on the analysis of the content of the pages, the site was geo-referenced using the algorithm described above. The results are presented in table 6.
As experiments have shown, the described method is quite accurate. In his case, the accuracy reaches 97%. This is due to a number of restrictions, namely: the use of predefined templates to find a page with an address; using the dictionary of cities; matching phone numbers and cities, as well as existing formal rules for recording addresses. All these restrictions allow you to achieve high accuracy when determining the geography of a web resource. On the other hand, these restrictions lead to a decrease in completeness in cases where the address is recorded without a direct indication of the city or with an unknown city, if the contact page is located at an address that is not described in the known search templates. Diagram 1 shows the distribution of sites by region - as can be seen from the diagram, the largest region in which the sites fall,
At the moment, we use the described method as one of the methods for extracting information about the geo-referencing of sites and add it to the index of a search engine. Thus, a person can search for information on the sites of his region. Additionally, the extracted address can be displayed in address snippets.
Dmitry Solovyov Search
Developer Mail.Ru