Parsing a job interview with Google: synonymous queries
- Transfer

This is a new article from the analysis of tasks with interviews in Google . When I worked there, I offered candidates such tasks. Then there was a leak, and they were banned. But the medal has a downside: now I can freely explain the solution.
For a start, great news: I left Google! I am glad to announce that I am now working as a technical manager for Reddit in New York! But this series of articles will still be continued.
Disclaimer: although interviewing candidates is one of my professional duties, on this blog I share personal observations, stories and personal opinions. Please do not consider this as an official statement of Google, Alphabet, Reddit, any other person or organization.
Question
After the last two articles about the course of the horse in dialing a phone number, I received critical comments that this is not a realistic problem. However useful it is to study the thinking skills of a candidate, but I have to admit: the task is really a bit unrealistic. Although I have some thoughts about the correlation between the questions at the interviews and the reality, but for the time being I will keep them with me. Be sure, I read comments everywhere and I have something to answer, but not now.
But when the task about the knight's move was banned a few years ago, I took the criticism to heart and tried to replace it with a question that is a little more related to Google. And what could be more relevant for Google than search engine mechanics? So I found this question and used it for a long time before it got into public too and was banned. As before, I will formulate the question, immerse myself in its explanation, and then tell you how I used it in interviews and why I like it.
So the question is.
Imagine that you run a popular search engine and see two requests in the logs: let's say Obama's approval ratings and Obama's popularity level (if I remember correctly, these are real examples from the question base, although now they are a bit outdated ...) . We see different requests, but everyone will agree: users are essentially looking for the same information, so requests should be considered equivalent when calculating the number of requests, showing results, etc. How to determine that two requests are synonymous?
Let's formalize the problem. Suppose there are two sets of pairs of lines: pairs of synonyms and pairs of queries.
Specifically, here is an example of input for illustration:
SYNONYMS = [
('rate', 'ratings'),
('approval', 'popularity'),
]
QUERIES = [
('obama approval rate', 'obama popularity ratings'),
('obama approval rates', 'obama popularity ratings'),
('obama approval rate', 'popularity ratings obama')
]It is necessary to produce a list of logical values: are the queries in each pair synonymous?
All new questions ...
At first glance, this is a simple task. But the longer you think, the harder it becomes. Can a word have several synonyms? Does word order matter? Are synonymous relations transitive, that is, if A is synonymous with B and B is synonymous with C, is A a synonym for C? Can synonyms cover a few words, as “US” is a synonym for the phrases “United States of America” or “United States”?
Such ambiguity immediately gives the opportunity to prove himself a good candidate. The first thing he does is seeks out such ambiguities and tries to resolve them. Everyone does it differently: some approach the board and try to manually solve specific cases, while others look at the question and immediately see the spaces. In any case, identifying these problems at an early stage is crucial.
The “problem understanding” phase is important. I like to call software engineering a fractal discipline. Like fractals, approximation reveals additional complexity. You think that you understand the problem, then look closer - and see that you have missed some subtlety or implementation detail that can be improved. Or a different approach to the problem.

The Mandelbrot
Caliber Engineer's set is largely determined by how deeply he can understand the problem. Transforming a vague formulation of the problem into a detailed set of requirements is the first step in this process, and deliberate innuendo allows you to assess how well the candidate fits into new situations.
Let us leave aside trivial questions like “Do capital letters matter?”, Which do not affect the basic algorithm. I always give the simplest answer to these questions (in this case, “Suppose that all the letters have already been processed and reduced to lower case”)
Part 1. (Not really) a simple case.
If candidates ask questions, I always start with the simplest case: a word can have several synonyms, word order matters, synonyms are not transitive. This gives a fairly limited functionality to the search engine, but it has enough subtleties for an interesting interview.
The high-level review looks like this: break up the word query (for example, by spaces) and compare the corresponding pairs to search for identical words and synonyms. Visually, it looks like this:
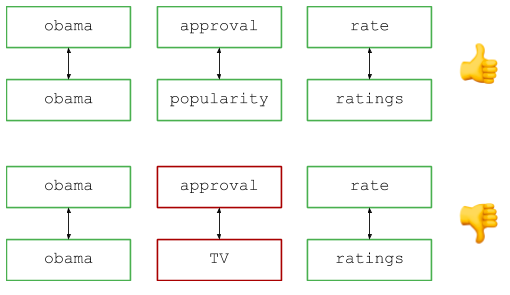
In the code:
defsynonym_queries(synonym_words, queries):'''
synonym_words: iterable of pairs of strings representing synonymous words
queries: iterable of pairs of strings representing queries to be tested for
synonymous-ness
'''
output = []
for q1, q2 in queries:
q1, q2 = q1.split(), q2.split()
if len(q1) != len(q2):
output.append(False)
continue
result = Truefor i in range(len(q1)):
w1, w2 = q1[i], q2[i]
if w1 == w2:
continueelif words_are_synonyms(w1, w2):
continue
result = Falsebreak
output.append(result)
return outputEasy, right? Algorithmically, this is pretty simple. No dynamic programming, recursion, complex structures, etc. Simple manipulation of the standard library and an algorithm that works in linear time, right?
But there are more nuances than it seems at first glance. Of course, the most difficult component is the comparison of synonyms. Although the component is easy to understand and describe, there are many ways to go wrong. I'll tell you about the most common mistakes.
For clarity: no errors disqualify a candidate; If anything, I just point out an error in the implementation, it fixes it, and we move on. However, an interview is, above all, a struggle with time. You will make, notice and correct mistakes, but it takes time that can be spent on another, for example, to create a more optimal solution. Practically everyone makes mistakes, this is normal, but candidates who make them smaller show better results simply because they spend less time correcting.
That's why I like this problem. If the knight's move requires insight in understanding the algorithm, and then (hopefully) a simple implementation, then the solution here is a lot of steps in the right direction. Each step represents a tiny obstacle through which the candidate can either gracefully jump over or stumble and climb. Good candidates due to experience and intuition avoid these little traps - and get a more detailed and correct solution, while the weaker spend time and energy on errors and usually stay with the wrong code.
At each interview I saw a different combination of successes and failures, here are the most common mistakes.
Random performance killers
First, some candidates implemented synonym detection using a simple traversal of the list of synonyms:
...
elif (w1, w2) in synonym_words:
continue
...At first glance, this seems reasonable. But on closer inspection, the idea turns out to be very, very bad. For those of you who do not know Python, the keyword
in is syntactic sugar for the contains method and works on all standard Python containers. This is a problem because it synonym_words is a list that implements the in keyword with a linear search. Python users are especially sensitive to this error, because the language hides types, but C ++ and Java users also sometimes made similar errors.In my entire career, I have only written a code with a linear search a few times, and each in a list no more than two dozen elements in length. And even in this case, he wrote a long commentary explaining why he chose such a seemingly non-optimal approach. I suspect that some candidates used it simply because they did not know how the keyword
inin the standard Python library worked with lists . This is a simple mistake, not fatal, but a poor acquaintance with your favorite language is not very good. In practice, this error is easy to avoid. First, never forget your object types, even if you use an untyped language such as Python! Second, remember that when you use a keyword inin the list starts a linear search. If there is no guarantee that this list will always remain very small, it will kill the performance.
In order for the candidate to come to his senses, it is usually enough to remind him that the input structure is a list. It is very important to observe how the candidate responds to the hint. The best candidates immediately try to somehow pre-process synonyms, which is a good start. However, this approach is not devoid of its pitfalls ...
Use the correct data structure
From the above code, it is immediately obvious that in order to implement this algorithm in linear time, it is necessary to quickly find synonyms. And when we talk about quick search, it is always a map or an array of hashes.
I don't care if the candidate chooses a card or an array of hashes. The important thing is that he will invest there (by the way, never use dict / hashmap with the transition to
Trueor False). Most candidates choose some kind of dict / hashmap. The most common mistake is a subconscious assumption that each word has no more than one synonym:...
synonyms = {}
for w1, w2 in synonym_words:
synonyms[w1] = w2
...
elif synonyms[w1] == w2:
continueI do not punish candidates for this mistake. The task is specifically formulated so as not to focus on the fact that words may have several synonyms, and some candidates simply did not encounter such a situation. Most quickly correct the error when I point it out. Good candidates notice it at an early stage and usually do not spend a lot of time.
A slightly more serious problem is the unawareness that the relationship of synonyms spreads in both directions. Note that this is taken into account in the code above. But there are implementations with an error:
...
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
synonyms[w1].append(w2)
synonyms[w2].append(w1)
...
elif w2 in synonyms.get(w1, tuple()):
continueWhy do two inserts and use twice the memory?
...
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
synonyms[w1].append(w2)
...
elif (w2 in synonyms.get(w1, tuple()) or
w1 in synonyms.get(w2, tuple())):
continueConclusion: always think how to optimize the code ! In retrospect, rearranging the search functions is an obvious optimization, otherwise it can be concluded that the candidate did not think about the optimization options. Again, I'm glad to give a hint, but it's better to guess by myself.
Sorting?
Some smart candidates want to sort the list of synonyms, and then use binary search. In fact, this approach has an important advantage: it does not require additional space, except for the list of synonyms (provided that the list can be changed).
Unfortunately, time complexity interferes: sorting the list of synonyms takes
Nlog(N)time, and thenlog(N)to search for each pair of synonyms, while the preprocessing solution described occurs in linear and then constant time. In addition, I am categorically opposed to forcing the candidate to implement sorting and binary search on the blackboard, because: 1) the sorting algorithms are well known, therefore, as far as I know, the candidate can issue it without thinking; 2) these algorithms are devilishly difficult to implement correctly, and often even the best candidates will make mistakes that say nothing about their programming skills.Whenever a candidate proposed such a solution, I was interested in the program execution time and asked if there was a better option. For information: if the interviewer asks you if there is a better option, the answer is almost always yes. If I ever ask you this question, the answer will definitely be.
Finally, the solution
In the end, the candidate offers something correct and reasonably optimal. Here is the implementation in linear time and linear space for the given conditions:
defsynonym_queries(synonym_words, queries):'''
synonym_words: iterable of pairs of strings representing synonymous words
queries: iterable of pairs of strings representing queries to be tested for
synonymous-ness
'''
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
synonyms[w1].add(w2)
output = []
for q1, q2 in queries:
q1, q2 = q1.split(), q2.split()
if len(q1) != len(q2):
output.append(False)
continue
result = Truefor i in range(len(q1)):
w1, w2 = q1[i], q2[i]
if w1 == w2:
continueelif ((w1 in synonyms and w2 in synonyms[w1])
or (w2 in synonyms and w1 in synonyms[w2])):
continue
result = Falsebreak
output.append(result)
return outputA few quick notes:
- Pay attention to use
dict.get(). You can implement a check to see if the key is in dict and then get it, but this is a complicated approach, although in this way you will show your knowledge of the standard library. - I personally am not a fan of code with frequent ones
continue, and some style guides forbid or recommend them . I myself in the first edition of this code forgot the operatorcontinueafter checking the length of the request. This is not a bad approach, just know that it is error prone.
Part 2: It's getting harder!
Good candidates still have ten to fifteen minutes left after solving the problem. Fortunately, there are a lot of additional questions, although we are unlikely to write a lot of code during this time. However, this is not necessary. I want to know about the candidate two things: is he able to develop algorithms and can he encode? The task with the knight's move first answers the question about the development of the algorithm, and then checks the coding, and here we get the answers in the reverse order.
By the time the candidate completed the first part of the question, he had already solved the problem with (surprisingly non-trivial) coding. At this stage, I can talk with confidence about his ability to develop rudimentary algorithms and translate ideas into code, as well as about getting to know his favorite language and the standard library. Now the conversation becomes much more interesting, because the requirements for programming can be mitigated, and we dive into the algorithms.
To this end, let us return to the basic tenets of the first part: the word order is important, synonyms are nontransitive, and for each word there can be several synonyms. As the interview progresses, I change each of these limitations, and in this new phase we have a purely algorithmic discussion with the candidate. Here I will give examples of the code to illustrate my point of view, but in a real interview we are only talking about algorithms.
Before you begin, I will explain my position: all subsequent actions at this stage of the interview are mainly “bonus points”. My personal approach is to identify candidates who accurately pass the first stage and are suitable for work. The second stage is needed to highlight the best. The first rating is already very strong and means that the candidate is good enough for the company, and the second rating says that the candidate is excellent and his hiring will be a great victory for us.
Transitivity: naive approaches
First, I like to remove the restriction on transitivity, so if the synonyms are the pairs A − B and B − C, then the words A and C are also synonyms. Smart candidates will quickly understand how to adapt their previous solution, although with the further removal of other constraints, the basic logic of the algorithm will stop working.
However, how to adapt it? One common approach is to maintain a complete set of synonyms for each word based on transitive relationships. Every time we insert a word into a set of synonyms, we also add it to the appropriate sets for all the words in this set:
synonyms = defaultdict(set)
for w1, w2 in synonym_words:
for w in synonyms[w1]:
synonyms[w].add(w2)
synonyms[w1].add(w2)
for w in synonyms[w2]:
synonyms[w].add(w1)
synonyms[w2].add(w1)Please note that when creating the code, we have already gone deep into this solution.
This solution works, but is far from being optimal. To understand the reasons, let us estimate the spatial complexity of this solution. Each synonym must be added not only to the set of the initial word, but also to the sets of all its synonyms. If the synonym is one, then one entry is added. But if we have 50 synonyms, we have to add 50 entries. In the figure, it looks like this:

Notice that we switched from three keys and six records to four keys and twelve records. A word with 50 synonyms will require 50 keys and almost 2500 entries. The required space for representing a single word grows quadratically with an increase in the set of synonyms, which is quite wasteful.
There are other solutions, but I will not go too deeply in order not to inflate the article. The most interesting of them is the use of the synonyms data structure for building a directed graph, and then a wide search to find the path between two words. This is an excellent solution, but the search becomes linear in the size of the set of synonyms for the word. Since we perform this search for each query several times, this approach is not optimal.
Transitivity: the use of disjoint sets
It turns out that the search for synonyms is possible in (almost) constant time thanks to a data structure called disjoint sets. This structure offers slightly different possibilities than a regular data set (set).
A regular set structure (hashset, treeset) is a container that allows you to quickly determine whether an object is inside or outside of it. Non-intersecting sets solve a completely different problem: instead of defining a specific element, they allow one to determine whether two elements belong to the same set . Moreover, the structure does it in a blindingly fast time
O(a(n)), wherea(n)- Ackermann inverse function. If you have not studied advanced algorithms, you may not know this function, which for all reasonable inputs is actually performed in constant time. At a high level, the algorithm works as follows. Sets are represented by trees with parents for each element. Since each tree has a root (an element that is itself a parent), we can determine if two elements belong to the same set by tracing their parents to the root. If two elements have one root, they belong to the same set. Combining sets is also easy: just find the root elements and make one of them the root of the other.
So far so good, but not yet seen blinding speed. The genius of this structure is in a procedure called compression. Suppose you have the following tree:
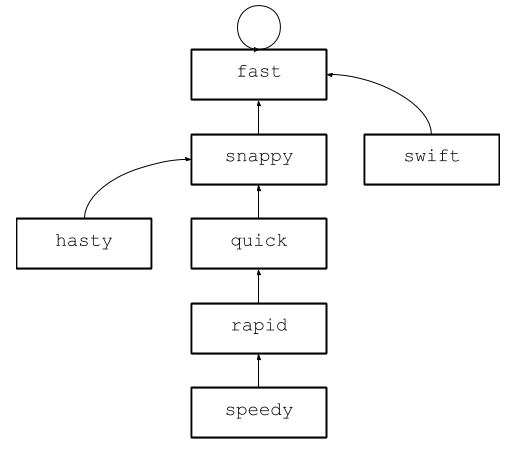
Imagine that you want to find out if the words speedy and hasty are synonymous . Follow the parents of each one and find the same fast root . Now suppose that we perform a similar test for the words speedy and swift . Again we go up to the root, and from speedy we go the same route. Is it possible to avoid duplication of work?
It turns out you can. In a sense, every element in this tree is destined to come to fast . Instead of going through the whole tree every time, why not change the parent for all descendants of fastto shorten the route to the root? This process is called compression, and in non-intersecting sets it is embedded in the root search operation. For example, after the first operation, compared to speedy and hasty, the structure will understand that they are synonymous, and will compress the tree as follows:

For all words between speedy and fast, the parent has been updated, the same thing happened with hasty
Now all subsequent calls will occur in constant time, because each node in this tree indicates fast . It is not very easy to assess the time complexity of operations: in fact, it is not constant, because it depends on the depth of the trees, but is close to constant, because the structure is quickly optimized. For simplicity, we assume that time is constant.
With this concept, we implement unrelated sets for our problem:
classDisjointSet(object):def__init__(self):
self.parents = {}
defget_root(self, w):
words_traversed = []
while self.parents[w] != w:
words_traversed.append(w)
w = self.parents[w]
for word in words_traversed:
self.parents[word] = w
return w
defadd_synonyms(self, w1, w2):if w1 notin self.parents:
self.parents[w1] = w1
if w2 notin self.parents:
self.parents[w2] = w2
w1_root = self.get_root(w1)
w2_root = self.get_root(w2)
if w1_root < w2_root:
w1_root, w2_root = w2_root, w1_root
self.parents[w2_root] = w1_root
defare_synonymous(self, w1, w2):return self.get_root(w1) == self.get_root(w2)Using this structure, you can pre-process synonyms and solve the problem in linear time.
Rating and notes
At this point, we have reached the limit of what the candidate can show in 40–45 minutes of an interview. For all candidates who have coped with the introductory part and made significant progress in describing (not implementing) unrelated sets, I assigned the rating “It is strongly recommended to hire” and allowed them to ask any questions. I have never seen a candidate go so far and have a lot of time left.
In principle, there are still variants of the problem with transitivity: for example, remove the restriction on the word order or on several synonyms for a word. Each decision will be difficult and delightful, but I will leave them for later.
The advantage of this task is that it allows candidates to make mistakes. Daily software development consists of endless cycles of analysis, execution and refinement. This problem enables candidates to demonstrate their abilities at each stage. Consider the skills needed to get the maximum score on this issue:
- Analyze the formulation of the problem and determine where it is not clearly formulated , develop an unambiguous formulation. Continue doing this as new issues are resolved. For maximum efficiency, perform these operations as early as possible, because the further the work has gone, the longer it takes to correct the error.
- Formulate the problem in such a way that it is easier to approach and solve. In our case, the most important is the observation that the corresponding words in the queries line up relative to each other.
- Implement your decision . This includes choosing the optimal data structure and algorithms, as well as designing logic that is readable and easily changeable in the future.
- Go back, try to find bugs and errors . These could be actual errors, as I forgot to insert the statement
continueabove, or performance errors, like using the wrong data structure. - When the definition of a problem changes, repeat the whole process: adapt your solution where necessary , or discard it if it does not fit. Understanding when to do one thing or the other is a critical skill in both the interview and the real world.
- Master the data structures and algorithms . Non-intersecting sets is not a very well-known structure, but in fact is not so rare and refined. The only way to guarantee the knowledge of the tools for the job - to learn as much as possible.
None of these skills can be learned from textbooks (with the possible exception of data structures and algorithms). The only way to acquire these is their regular and extensive practice, which agrees well with what the employer needs: experienced candidates who are able to effectively apply their knowledge. The meaning of interviews is to find such people, and the task from this article has helped me for a long time.
Future plans
As you could understand, the task eventually became known to the public . Since then, I have used several other questions, depending on what was asked by past interviewers and on my mood (it’s boring to ask one question all the time). I still use some questions so far, so I’ll keep them secret, but not some! You can learn them in the following articles.
In the near future I am planning two articles. First, as promised above, I will explain the solution of the two remaining problems for this problem. I never asked them at interviews, but they are interesting in themselves. In addition, I will share my thoughts and personal views on the procedure for finding employees in IT, which I am particularly interested in now, because I am looking for engineers for my team in Reddit.
As always, if you want to learn about new articles, follow me on Twitter or on Medium . If you liked this article, do not forget to vote for it or leave a comment.
Thanks for reading!
P. S .: You can examine the code of all the articles in the repository GitHub or play with them live thanks to my good friends from repl.it .