Column DBMS vs lowercase, how about a compromise?

Column DBMS actively developed in zero years, at the moment they have found their niche and practically do not compete with traditional lowercase systems. Under the cat, the author understands whether a universal solution is possible and how expedient it is.
“There is progress in everything.… You shouldn’t be afraid that they will call you in the office and say:” We conferred here, and tomorrow you will be quartered or burned by your own choice. “It would be a difficult choice. I think he would have confused many of us. ”
Yaroslav Hasek. The adventures of the brave soldier Schweik.
Prehistory
How many databases exist, so much this ideological confrontation lasts. The author, out of curiosity, found in the bins the book of J. Martin from IBM [1] of 1975 and immediately came across words on it (p. 183): “Binary relations are used in [...], i.e. relationship of only two domains. It is known that binary relations give the most flexibility to the base. However, in commercial tasks, relations of various degrees are convenient. ”Relationships are understood here as relational relations. And the mentioned works are dated 1967 ... 1970.
Let Sybase IQ be the first industrially used column DBMS, but at least at the idea level, everything was spoken 25 years before it.
At the moment, the following DBMSs are column-based or in one way or another support this feature (taken mainlyhere ):
Commercial
- 1010data's Tenbase database
- Alterian's engine
- Aster Data Systems
- Calpont InfiniDB Enterprise Edition
- EXASOL
- FAME
- Fluididb
- Greenplum
- Hive Intelligence Ltd Hex Engine
- Infobright Enterprise Edition
- KDB
- Kickfire
- Microsoft SQL Server 2012+ (Enterprise Edition)
- Oracle Retail Predictive Application Server (RPAS)
- Paraccel Analytic Database
- SAND CDBMS
- SAP HANA
- SenSage
- Sybase iq
- Vectorwise
- Vertica
Free & open source
- Calpont InfiniDB Community Edition
- Clickhouse
- Infobright Community Edition
- Greenplum Community Edition
- Luciddb
- Metakit
- Monetdb
- C-Store
- S bilingual programming and GNU statistics
Differences
A relational relationship is a collection of tuples, essentially a two-dimensional table. Accordingly, there are two storage options - row or column. The separation is a bit artificial, logical. Database developers are no longer engaged in planning records for drums and tracks. Optimally decomposing DBMS data by file system (moms) is the task of DBMS administrators, and how the file system manages the data on physical disks is known mainly to the developers of file systems.
It would be logical to provide the DBMS itself to decide in which order to store the data. Here we are talking about some hypothetical DBMS that supports both storage options and has the ability to assign a table to any of them. We do not consider quite a popular option to support two databases - one for work, the second for analytics / reports. As well as column indexes a la Microsoft SQL Server. Not because it is bad, but to test the hypothesis that there is some more elegant way.
Unfortunately, no most hypothetical DBMS can choose how best to store data. Because does not have an understanding of how we are going to use this data. And without this, the choice is impossible, although it is very important.
The most valuable quality of a DBMS is the ability to quickly process data (and the ACID requirements , of course). The speed of the DBMS is mainly determined by the number of disk operations. From here there are two extreme cases:
- Data is rapidly changing / added, it is necessary to have time to write. The obvious solution is that the line (tuple) is, if possible, located on one page, it is not done faster.
- The data changes extremely rarely or does not change at all, we repeatedly read the data, and only a small number of columns are involved at the same time. In this situation, it is logical to use the column-based storage option, then when reading the minimum possible number of pages will rise.
But these are extreme cases, in life everything is not so obvious.
- If you want to read the entire table, then in terms of the number of pages, it does not matter line by line or column-wisely located data. Ie, there is some difference, of course, in the column-based version we have the opportunity to better compress the information, but at the moment it does not matter.
- But in terms of performance, there is a difference. with line-by-line writing, reading from disk will be more linear. A smaller number of forwarding of the hard disk heads speeds up reading. More predictable file reading with line-by-line writing allows the operating system (OS) to use disk cache more efficiently. This is important even for SSD disks, since the download by assumption ( read ahead ) leads to success more often.
- Update does not always change the entire record. Suppose a frequent case - a change in two columns. Then it will be good if the data of these columns will be on the same page, because you only need one page lock to write instead of two. On the other hand, if the data is divided into pages, this allows different transactions to change the data of one row without conflicts.
Here is a closer look. The hypothetical choice is to make the table lowercase or columnar, the DBMS must make it at the time of its creation. But to make this choice it would be nice to know, for example, how we are going to change this table. Maybe we should throw a coin? - Suppose we use a tree structure for storage (ex: clustered index). In this case, adding data or even changing it can lead to re-balancing of the tree or its part. In case of line storage, there is a (minimum) lock on the record, which can affect a significant part of the table. In the column version, such stories occur much more often, but cause much less damage because relate only to a specific column.
- Consider a sample with filtering by index. Suppose the sample is sparse enough. Then the line entry has a preference, because in this case the ratio of useful information to the read for the company is better.
- If the filtering gives a more dense flow and only a small part of the columns is required, it becomes cheaper by the column option. Where is the dividing line between these cases, how to define it?
In other words, under no circumstances will our hypothetical DBMS assume the responsibility of choosing between the row and column-based storage options, the designer of the database must do so.
However, given the above, and the database designer will be in a situation of very difficult choice. He would be stumped by many of us.
What if
In essence, both the column and inline variants are extreme cases of the same idea — cut the table into “ribbons” and store data line by line within each tape. Just in one case, the tape is one, in the other the tape degenerates into one column.
So why not allow intermediate options - if the data of some columns come / read together, let them be on the same tape. And if there was no data in the tape (NULLs), then nothing needs to be stored. At the same time, the problem of the maximum row size is removed - you can split the table when there is a risk that the row does not fit on one page.
This idea is not so special that the author has ever seen it and applied it himself. The element of novelty is to enable the DB designer to determine for himself how exactly his table will be split into parts and in what form the data will get on the disk.
We did it for ourselves as follows:
- When creating a table, information about our preferences is passed to the SQL processor using pragmas.
- initially, when creating a table, it is assumed that the entire string will be located on the same B-tree page
- however, you can use - - #pragma page_break
to tell the SQL processor that the following columns will be located on another page (in another tree) - using - - #pragma column_based
allows you to concisely say that the columns going further are located each on its own tree - - - #pragma row_based
cancels column_based action - thus, the table consists of one or more B-trees, the first element of which key is the hidden IDENTITY field. There is an opinion that the order in which records are created (may well correlate with the order in which records will be read) also matters and should not be neglected. The primary key is a separate tree, however, this no longer applies to the topic.
How can it look like in practice?
For example:
CREATETABLE twomass_psc (
ra doubleprecision,
decl doubleprecision,
…
-- #pragma page_break
j_m real,
j_cmsig real,
j_msigcom real,
j_snr real,
h_m real,
h_cmsig real,
h_msigcom real,
h_snr real,
k_m real,
k_cmsig real,
k_msigcom real,
k_snr real,
-- #pragma page_break
…
coadd_key integer,
coadd smallint
);For example, the main table of the atlas 2MASS is taken , the legend is here and here .
J , H , K are infrared sub-ranges, it makes sense to store data on them together, because in research they are processed together. Here, for example :

First available picture.
Or that's even more beautiful:
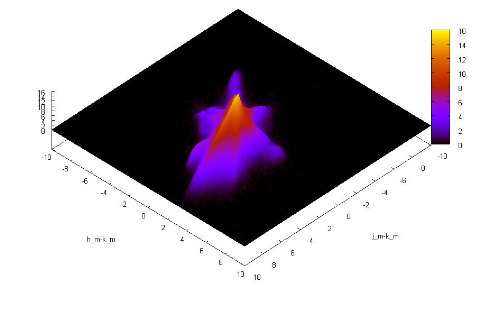
It's time to confirm that this has some practical meaning.
results
Below is:
- phase diagram (X-number of the recorded page, Y-number of the last previously recorded) order of recording pages (logical numbers) to disk when creating a table in two versions
- column- wise , it is designated as by_1
- and for a table cut into 16 columns, it is designated as by_16
- total columns 181

Let's take a closer look at how it works:
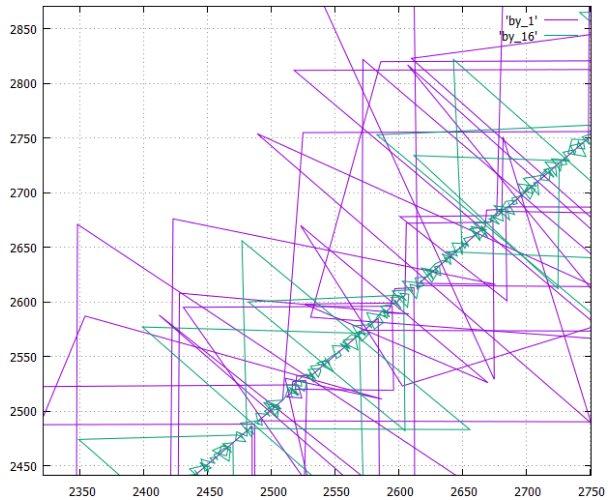
- The by_16 variant is much smaller, which is logical, the limiting one - the lowercase variant would give just a straight line (with outliers).
- Triangular overshoots — record intermediate B-tree pages.
- Data recording is shown, obviously, the reading will look something like this.
- It was said above that all the variants record the same amount of information and the flow to be subtracted is approximately the same (± compression efficiency).
But here it is very clearly shown that in the column-based version, trees grow at different speeds due to the specifics of the data (in one column they often repeat and shrink very well, in the other column noise from the point of view of the compressor). As a result, some trees are running ahead, others are late; when reading, we objectively get a “ragged” reading mode that is very unpleasant for the file system. - So, the by_16 option is much preferable for reading than column-wide, it is almost equal in comfort in the line version.
- But at the same time, the by_16 variant possesses the main advantages of the column option in the case when a small number of columns is required. Especially if you split the table not mechanically by 16 pieces, but meaningfully, after analyzing the probabilities of their sharing.
Sources
[1] J.Martin. Database organization in computing systems. Mir, 1978
[2] Column indices, features of use
[3] Daniel J. Abadi, Samuel Madden, Nabil Hachem. ColumnStores vs. RowStores: How Different Are They Really? , Proceedings of the ACM SIGMOD International Conference on Data Management, Vancouver, BC, Canada, June 2008
[4] Michael Stonebraker, Uğur Çetintemel. “One Size Fits All”: An Idea Whose Time Has Come and Gone , 2005