Are prompting services prompting well? We measure the usefulness of auto-completion web services
 About a month ago, there was one episode with me that made me think about the usefulness of the auto-completion functions, which are often embedded on online store sites. Usually it looks like this: you start placing an order, enter your name, phone number and delivery address, and while you slowly type in the address, you will see prompts with street names so that you don’t strain the keyboard and select the desired address from the list provided.
About a month ago, there was one episode with me that made me think about the usefulness of the auto-completion functions, which are often embedded on online store sites. Usually it looks like this: you start placing an order, enter your name, phone number and delivery address, and while you slowly type in the address, you will see prompts with street names so that you don’t strain the keyboard and select the desired address from the list provided. So, in February I needed to quickly feed a large group of friends at home, and I decided to order pizza in one fairly popular institution. In general, I usually adhere to the principles of a healthy diet, but the situation was exceptional ...
You say Habr - not a place for stories about pizza, and you will be absolutely right, but this story is not entirely about pizza, it is more about modeling human behavior, about stress testing, a little about programming, and more about a numerical assessment of the usefulness of several modern ajax auto-completion services and tips.
But the impetus for writing this article was still pizza and the fact that I had to place its order twice due to the fact that the site used hints when filling out the field with the delivery address. The trick was that until you select a street from the proposed list, you will not be allowed to indicate the house number. Since out of habit, I type in my address very quickly, and the tips on that site worked very slowly, it turned out that this whole ajax mechanism with the loading of tips did not have time to work out. As a result, I could not indicate the house number. I had to press F5, place the order again and re-enter my address slowly but surely.
The whole story ended well, and the pizza was delivered to the address, but the sediment remained. I decided to ask myself whether it is possible to somehow measure or evaluate the usefulness of using these types of services, because auto-completion functions are found everywhere.
As a result, this question resulted in a full-fledged study, with the development of scripts to test the usefulness of six currently available online email completion services. The results of these studies are the subject of this article.
Utility formula
A utility study needs to start by defining a formula for calculating it. The following is intuitively clear.
- If you enter data, and instead of hints you see a spinning wheel, this is not very useful. And vice versa, if the prompts pop up faster than you have time to type, this is good.
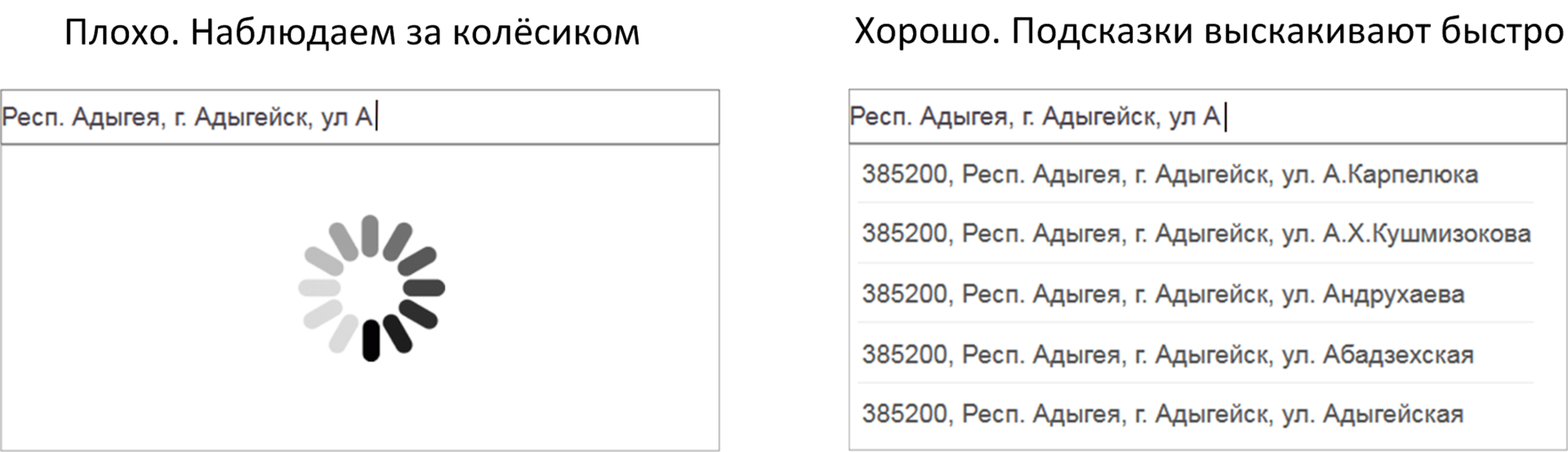
- If you long and hard to fill out the form letter by letter, but the tips do not prompt what you need, then their benefits are doubtful. And vice versa, if you enter a couple of letters, and the tips have already materialized the desired, then there is an obvious profit from their use.
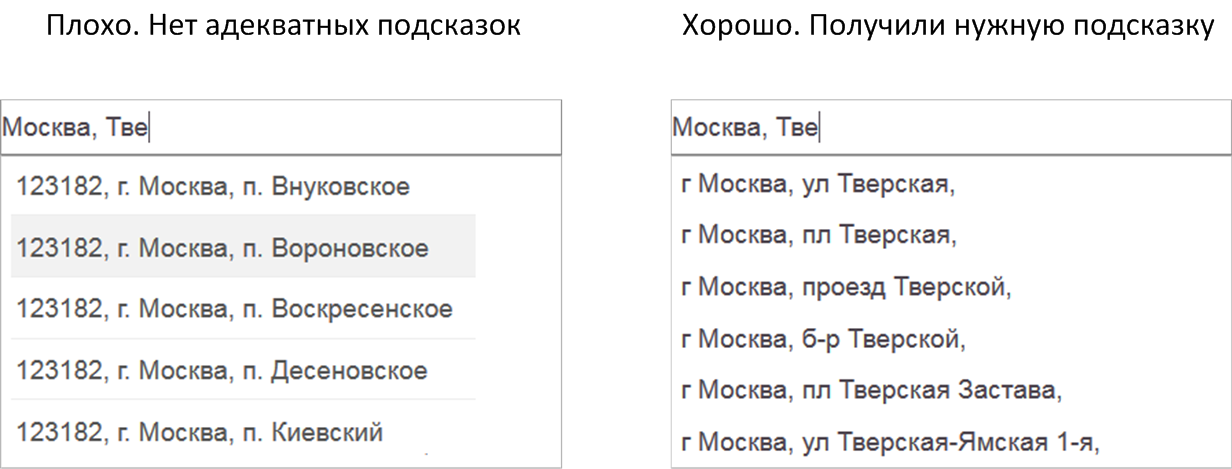
All these thoughts led me to the following formula, which estimates the usefulness of the auto-completion service.

Here
 - the total time that the user spends on entering the address when using prompts,
- the total time that the user spends on entering the address when using prompts,  - the total time that the user spends waiting for prompts from the service,
- the total time that the user spends waiting for prompts from the service,  - The total time that the user would spend on entering data without using prompts.
- The total time that the user would spend on entering data without using prompts. You ask why separate
because ajax is an asynchronous thing and the response time does not delay the user when typing. But, as noted above, this article is about modeling human behavior. When a user sees that they are being offered prompts, his work at the keyboard changes, namely, it looks like this:- I pressed the key with the next letter to be entered.
- Waited for clues.
- I was convinced that there are no correct prompts, and returned to point 1.
As you can see, synchronous work is quite possible for ourselves, so the time that the user spends on entering data is determined precisely by the sum
 .
. In good condition when the amount
less denominator , the value of the function falls into the range [0 ... 1] and, in fact, shows the percentage of time that the user saves using prompts. But there are also abnormal conditions (remember about pizza), which we will consider a little later. In the meantime, we will write what is and . Will accept
 where
where  - the number of letters that make up the address and which the user needs to enter,
- the number of letters that make up the address and which the user needs to enter,  - the time that the user spends on average searching for letters on the keyboard and pressing the corresponding button. This time depends on the user's ability to work with the keyboard. We will distinguish three classes of users: “slow-moving”, “middle peasant” and “haste”. For each of these classes, we will later set the corresponding value, as a result, for each class of users, the utility value will be separately obtained.
- the time that the user spends on average searching for letters on the keyboard and pressing the corresponding button. This time depends on the user's ability to work with the keyboard. We will distinguish three classes of users: “slow-moving”, “middle peasant” and “haste”. For each of these classes, we will later set the corresponding value, as a result, for each class of users, the utility value will be separately obtained. Will accept
 Where
Where  - the number of letters of the address that the user actually has to enter using hints. Upon receipt of the correct prompt, the user stops typing the address, instead, he simply selects it from the proposed list. In this case
- the number of letters of the address that the user actually has to enter using hints. Upon receipt of the correct prompt, the user stops typing the address, instead, he simply selects it from the proposed list. In this case . If the user does not receive a suitable hint, then he has to enter the address completely, in such situations
. If the user does not receive a suitable hint, then he has to enter the address completely, in such situations . Second term
. Second term reflects the time that the user spends to select from the proposed list of suitable tips. In general, the user can use the hints
reflects the time that the user spends to select from the proposed list of suitable tips. In general, the user can use the hints times, for example, when entering the city - the first time, and when entering the street - the second time. When choosing a hint, the user, as a rule, presses the down arrow button on the keyboard several times to select the desired hint, and then clicks on a button (for example, Enter) to confirm his choice. These actions do not require searching for the necessary buttons on the keyboard, therefore this time can be taken as a constant, which depends on the user's class: “slow-moving” does not have a good command of the keyboard, therefore it will be slower to press arrows compared to “haste”. Therefore, I linked this constant to, and the coefficient
times, for example, when entering the city - the first time, and when entering the street - the second time. When choosing a hint, the user, as a rule, presses the down arrow button on the keyboard several times to select the desired hint, and then clicks on a button (for example, Enter) to confirm his choice. These actions do not require searching for the necessary buttons on the keyboard, therefore this time can be taken as a constant, which depends on the user's class: “slow-moving” does not have a good command of the keyboard, therefore it will be slower to press arrows compared to “haste”. Therefore, I linked this constant to, and the coefficient  was empirically selected (see experimental results at the end of the article). It is important to remember that
was empirically selected (see experimental results at the end of the article). It is important to remember that in situations where the service did not return suitable prompts and, as a result, the user did not perform actions related to selecting a prompt from the list.
in situations where the service did not return suitable prompts and, as a result, the user did not perform actions related to selecting a prompt from the list. Substituting all these expressions into the utility formula, we obtain the following

that he spends on generating and issuing prompts, get the number of letters that the user actually has to enter when typing the address, as well as the number of times that the user has to choose hints. From the formula it follows that the smaller these indicators, the higher the usefulness of the tips. In an ideal situation, when the user has not started to enter anything yet, and the form with the address is already filled with the correct data, there is ,
,  and . In this case, the utility is 1. This situation is ideal and at the moment, it is probably not possible to achieve it using terrestrial technologies, but there is something to strive for.
and . In this case, the utility is 1. This situation is ideal and at the moment, it is probably not possible to achieve it using terrestrial technologies, but there is something to strive for. In the worst case scenario, the user enters the entire address, and after entering each letter, he additionally expects a hint in the hope that it will save him from further input. In this case
and , as a result, we get negative utility  , which reflects the additional time spent by the user due to the useless waiting for prompts. In such a situation, if there were no prompts at all, the user would enter the address faster.
, which reflects the additional time spent by the user due to the useless waiting for prompts. In such a situation, if there were no prompts at all, the user would enter the address faster.Overview of auto-completion services
So, the formula I invented had to be checked on something. Searching the Internet, I found six suitable services that let me send fragments of address data and get hints for them through the REST API (I recommended another service in the comments, so I ended up with seven). All the services I have reviewed work the same way, namely:
- Using the GET or POST method, an HTTP request is received with the address fragment already entered.
- Return an array with suggested hints in JSON format.
Of course, the structure of the JSON response for each service has its own, but the semantics are more or less the same. To simulate the user’s work with each of these services, I wrote the appropriate script. This script simulates a set of email addresses on the keyboard, and in the process of such a simulation analyzes the returned hints for their adequacy. Sources of all scripts can be taken on github, the link is attached at the end of the article.
All the considered services, with the exception of Yandex and Google, use the address directories KLADR or FIAS as a data source, or both of them at the same time. Both directories are maintained by the Federal Tax Service of Russia. You can find information on them on the following sites: KLADR - http://gnivc.ru , FIAS - fias.nalog.ru. Yandex and Google most likely use data from their cards to generate hints.
A brief overview of all the services that participated in my experiments is given below. During the review and in the results of the experiments, the services are sorted alphabetically.
Achanter
The service is available at ahunter.ru . Judging by whois, the service appeared on RuNet in early 2009. Tips for addresses are offered on a free basis, regarding the limits on the site it is separately said that they are not.
You can test the tips directly in the demo section of the service here . To implement hints on third-party sites, webmasters are advised to use the jQuery-Autocomplete plugin, which can be taken on the github at the following link . To write a bot script, I used the documentation for the service API directly, which can be read here .
Additionally, in addition to prompts for addresses, the authors of the service suggest correcting and structuring addresses by KLADR and FIAS and receiving geo-coordinates for them, but this is for a separate fee.
Google Places API Web Service
In fact, several services are hidden under this name, of which we are interested in “Place Tips”. Information on this service is available here . Quite serious quotas have been set for the use of the service; only 1000 requests per day can be processed for free. However, if you specify your credit card information in the account, then 150,000 requests per day will be available for free. Anything beyond this is paid separately.
To embed on your site you need to use the JavaScript address library in Google Maps. Information on it is available here . There is also the opportunity to test and watch the demo. To write a bot script, I used the documentation on the service API, available at the link above.
Additionally, with the help of other services of this group, you can separately request the geo-coordinates of the addresses received in the prompts.
Dadata
The service is available at dadata.ru . According to whois, the service appeared on RuNet in late 2012. To use the tips you need to buy a subscription for a year, or fit into the daily free limit.
A demo page of tips is available, it is available at the following link . For implementation on their website, the service authors suggest using a jQuery plug-in of their own design. To write a bot script, I used the documentation on the service API, available at the following link .
For a fee, part of the addresses on the site offer the same additional options as on Akhanter.
CLADER in the cloud
The service is available at kladr-api.ru . According to whois, the service appeared in early 2012. The authors suggest buying a subscription for three months or a year, or fit into the free daily limits.
A demo page where you can find tips is available at the following link . To use hints on third-party sites, the authors suggest using a plug-in specially developed for this jQuery service, which can be taken on the github here .
To develop a bot script, I used the documentation on the service website, available here , it is not very detailed, but you can figure it out.
Fias24
The service is available at fias24.ru . Judging by whois, this is still a young service, it appeared on RuNet at the end of 2016. To use the tips you need to buy a subscription for a year.
A demo page of tips is available, it is available on the main page of the service. For implementation on sites, the authors of the service suggest using a jQuery plugin of their own design. There is no full-fledged documentation for the REST API on the site, so to write a bot script, I had to turn on my intuition and the experience gained with working with other services.
Yandex maps
Here, I think, additional descriptions are not required, since the service is well known even among housewives. No explicit limits were observed in the conditions of using this service, however Yandex warns that it is necessary to negotiate separately for large projects, and in case of which it may at any time restrict access at its discretion. During my experiments, access denials were not noticed.
How the tips in Yandex Maps work, you can look at ... Yandex Maps, so I will not give a link to the “demo”. Yandex hints have a separate API for embedding on third-party websites, the documentation can be found here https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/SuggestView-docpage/ .
Unbelievable, but the fact, in addition to hints, the service offers additional options for working with coordinates, though for this you need to use a different API.
Iqdq
This service was added to the article at the request of its authors after the publication of the article on Habré. The service is available at iqdq.ru . According to whois, the service appeared at the end of 2013. Tips for addresses are offered for free.
A demo page where you can find tips is available at the following link . To use hints on third-party sites, authors provide examples of JavaScript code using jQuery. To write a bot script, I used the documentation on the service API, available here .
For a fee, part of the addresses on the site offer additional options, the same as on the services of Achanter and Dadata.
Experiment description
For each service from this review, we need to measure the response time
and the number of letters , which the user has to enter before he receives a suitable prompt, or until the address is typed in its entirety. For this, I prepared a test sample. A total of 3591 streets from 406 cities of Russia were included in it. For each city, no more than 10 streets were selected, and the streets were chosen so as to cover the entire alphabet if possible. Small settlements (villages and towns) were not included in the test sample, since residents of fairly large cities are still a potential target audience for prompt services.Test Sample Description
A test sample can be downloaded along with the source. The selection is a JSON array, each element of which corresponds to a test address, the input of which we will emulate to get hints. An example with a description of the fields of these addresses is given below:
{
"id" : 1,
"reg" : "Адыгея",
"reg_type" : "Респ",
"reg_kladr" : "0100000000000",
"city" : "Адыгейск",
"city_type" : "г",
"city_kladr" : "0100000200000",
"street" : "8 Марта",
"street_type" : "ул",
"street_kladr" : "01000002000003800"
}
Here id is the unique identifier of the test address within the sample, reg is the name of the region to which the address belongs, reg_type is the type of region, reg_kladr is the code for the region KLADR. Similarly, the city, city_type, city_kladr fields are entered for the city, and the street, street_type, street_kladr fields are entered for the city.
Testing algorithm
For each address of our sample, you need to create an imitation of its input to track the hints received from the tested service. At the same time, we believe that the user enters only the name of the city and street, he does not need to enter the name of the region, because he lives in one of the 406 fairly large cities in Russia. In our imitation, first, letter by letter, the name of the city is typed. Each new letter added to the end of the entered name generates a new service request. Among the hints received, the expected address is searched, which we know in advance, because it is for this reason that it is present in the test sample.
If the city you enter is among the first five tips of the list, then further imitation of the city name is stopped. It is believed that the user saw the name and selected it. Therefore, the user then proceeds to set the street name. To do this, a simulating script sequentially, letter by letter, builds the name of the street and adds it to the city selected in the previous step. After each letter added, the resulting address fragment is again sent to the service.
Well and further, by analogy with the city, we look for the street to be entered among the first five prompts, if it was received, then further imitation of the street entry stops, otherwise - go to the next letter and send the request again.
This simple test allows you to measure the response time of the service
and the number of letters that the user needs to enter in order to get the desired address in the prompts. Separately, it is necessary to stipulate situations when the user did not receive a suitable hint until the end of entering the name of the city. In this case, our simulated user understands that the service is not able to help him enter this particular address. Therefore, further street entry is performed without using prompts. In this case, the user no longer expects anything from the service, so that the response time ceases to influence his behavior, in which case you can accept, however, the user will have to type the full street name, so will match .Source code
All scripts are written in Perl. Sources have the following structure.
- The run_test.pl script is the main and only script that needs to be run to run the test for any service.
- The TestWorker.pm package contains the implementation of the testing algorithm described above.
- The TestStorage.pm package is needed to work with the storage of test results. All results are stored in the sqlite database so that after passing all the tests you can perform all the necessary calculations.
- The packages AhunterAPI.pm, GoogleAPI.pm, DadataAPI.pm, KladrAPI.pm, Fias24API.pm, YandexAPI.pm and IqdqAPI.pm contain the implementation of working with the API of the corresponding service. What service each package corresponds to can be guessed by its name.
- suggest_test_full.json is a file containing our 3591 test address.
The test run line for some service has the following form:
run_test.pl <полный путь к файлу с тестами> <Имя API-пакета сервиса> <Ключ API>For example, to test a service from Google, you need to run a test as follows.
run_test.pl /home/user/suggest_test_full.json GoogleAPI ABCDEFGHere /home/user/suggest_test_full.json is the full path to the test file, GoogleAPI is the name of the package corresponding to the tested service, ABCDEFG is the key for working with the service through the API, which you need to receive in your account’s personal account. Akhanter and Yandex services do not require registration, so for them you can pass an arbitrary string as an API key.
Features of passing tests
When passing tests for each service, feature
At Akhunter, in the prompts for addresses from the Chuvash Republic, the name of this region is returned as follows: “Res Chuvash (Chuvashia)”. Therefore, as part of AhunterAPI.pm, we had to implement in a special way a comparison of the tips for this republic with its reference name.
Google also has features in the names of several regions, for example, “Tuva” returns as “Tuva”, and “Udmurt Republic” returns as “Udmurtia”. They also had to write a separate comparison. In addition, it was not possible to get tips for all addresses from the Republic of Crimea. A potential user will have to enter all addresses from this region entirely without prompts, this automatically increases
and reduces the overall usefulness of the service. The situation is similar with the cities of New Moscow, for which Google returns tips from the Moscow region. All of these tests were not passed, because formally, the service does not prompt the address that actually takes place. The Dadat service has a problem with tips for cities whose names coincide with the names of streets or districts in other cities. For example, for the city of Mirny it offers addresses such as Samara Region, Tolyatti, Mirny 2nd Passage, and for the city of Berezovsky it offers addresses like Krasnodar, the Berezovsky Village District. At the same time, the name of the city could not be obtained in the tips, even if you enter it completely. Because of this
grows, and utility decreases, because in the absence of prompts, such addresses are entered completely. Fias24 found similar problems with cities whose names coincide with the districts, or when the city name is a prefix for the name of the region to which this city belongs. For example, for the city of Krasnodar, the service returns options from the Krasnodar Territory, but the city itself is not in the prompts. This can be seen on the demo page of the service.
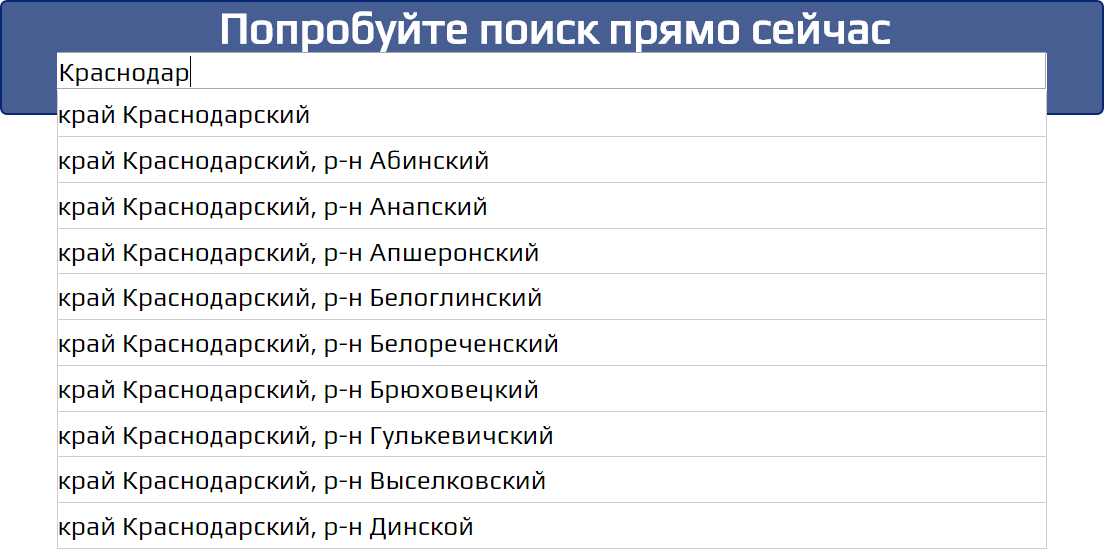
Because of this problem, for about 370 tests, no clues were received for the city name. As a result, when calculating the utility formula, based on our algorithm, a set of streets for these test addresses was carried out without taking into account prompts. It affects the increase
. The “KLADR in the cloud” service has a similar situation, only about 700 tests have not been passed. Also, this service does not show streets without explicitly indicating their types. Examples can be found on the demo page of the service:
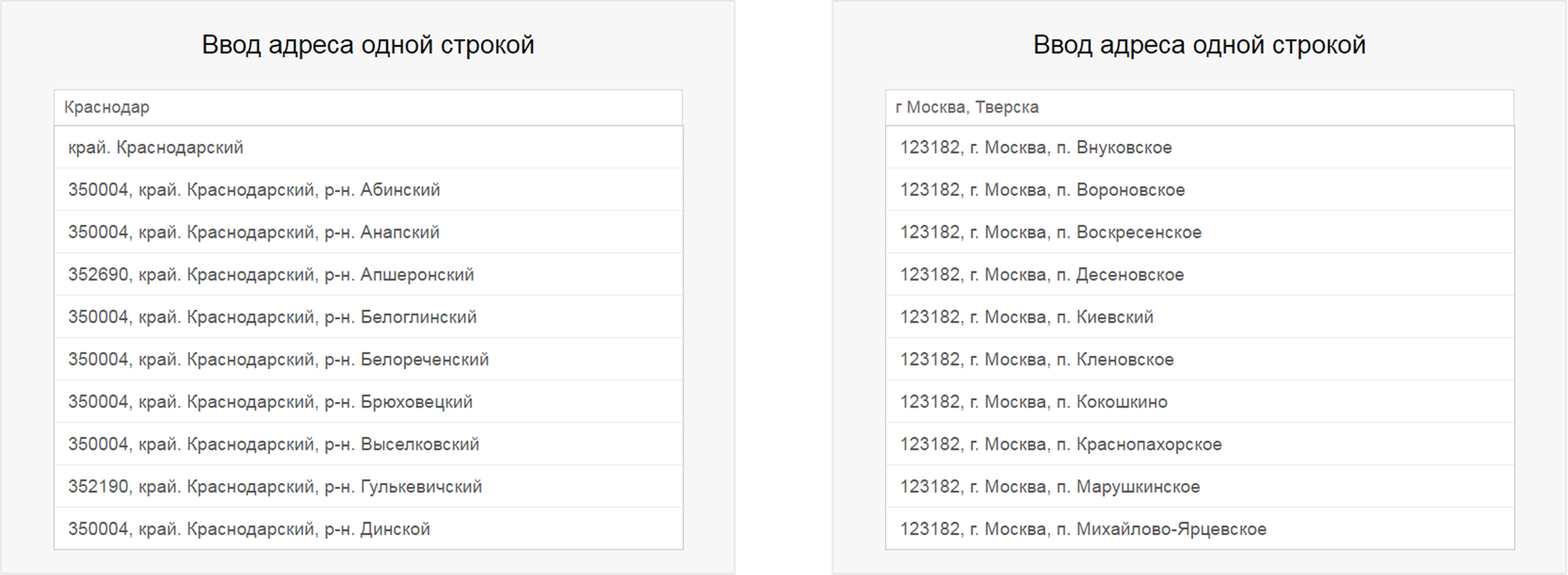
Therefore, an exception was specifically made for this service, when generating queries for the name of the street, its type was previously inserted before each name. Consequently
for this service there will always be more by the number of letters that make up the name of the type of street. About the same number of tests were not passed by the Iqdq service. This is mainly due to similar problems - the name of the city, even after full input, either does not fall into the issuance at all (for example, Izhevsk), or does not fall into the first 5 issuance tips (for example, Bryansk).

In addition, the same problems are encountered as in the Dadat service, when instead of the city the district of the same name returns, for example, for the "city of Zhukovsky" we get "Bryansk region, Zhukovsky district". Additionally, you can select the addresses where, instead of the expected city, the village of the same name returns, for example, instead of “Pionersky city”, the service returns “Res Udmurt, Igrinsky district, Pionersky was evicted”. All this leads to the fact that such problem cities have to be entered completely without prompts. According to the conditions of our tests, streets in such addresses also have to be entered without prompts. As a result, all such addresses
rises to , and this reduces the utility. Yandex as well as the other services discussed above have problems with some cities. Instead, he returns the street names of other cities. For example, for the city "October" returns "Russia, Moscow region, Lyubertsy, October Avenue." There was also a problem with tips for streets that have initials in their names. For example, at the request “Russia, the Republic of Adygea, Adygeysk, Chicha” you can get the answer “Russia, the Republic of Adygea, Adygeysk, P.S. Chicha. " If this response is resent as a request, Yandex returns an empty result. Because of this feature, it was necessary to exclude all street names with initials from the test set and repeat all the tests for all services again.
Separately, a reservation should be made for services that use maps as sources of hints. These sources cover the address space of Russia worse than the rest of the survey participants. As a result, one of the main reasons why these services did not return prompts is the lack of a test address on the map. This in turn automatically increases
, since without a prompt the user has to enter all the letters of the address.Experiment Results
After the test is completed, the run_test.pl script displays various statistical indicators characterizing the result of passing the test. Also, the screen displays three totals of the utility of the service for the three corresponding classes of users - "slow-moving", "average" and "rush."
The first four indicators that are displayed on the screen have the following meaning.
- city_avg () - the average time for waiting for prompts from the service when entering the name of the city, measured in milliseconds.
- street_avg () - similar to the previous one, but for street names.
- city_avg () - the average number of letters by which the service guesses the name of the city.
- street_avg () - the average number of letters by which the service guesses the name of the street.
These indicators do not directly participate in the utility formula, they are interesting in themselves. Below is a table with their values for all tested services.
| Achanter | Dadata | CLADER in the cloud | Fias24 | Yandex | Iqdq | ||
|---|---|---|---|---|---|---|---|
| city_avg () (ms) | 15.98 | 85.93 | 78.55 | 104.05 | 73.88 | 22.46 | 176.73 |
| street_avg () (ms) | 18.69 | 86.76 | 106.79 | 154.68 | 189.70 | 30.67 | 277.28 |
| city_avg () (letters) | 2.48 | 2.71 | 3.89 | 4.27 | 3.68 | 4.42 | 4.75 |
| street_avg () (letters) | 1.63 | 2.18 | 1.61 | 3.28 | 1.90 | 2.20 | 1.84 |
The first two indicators reflect the average responsiveness of the service. They can be used to judge whether this service will be useful for users with high typing speed on the keyboard. The shorter the response time of the service, the more users it will be useful. It is also noticeable here that all services spend less time forming tips for the city, while tips for the street take more of their time and energy.
But of particular interest are indicators city_avg (
) and street_avg () It turns out that less than five letters are enough to guess the name of the city, since city_avg () <5. In the best case, for correctly guessing the name of the city, approximately two and a half letters are enough! At least that’s how much Achanter and Google demonstrate with the first city_avg () = 2.48, and the second city_avg () = 2.71. Correct guessing of the street name requires even less letters. The four services examined (Akhanter, Dadata, Fias24 and Iqdq) predict the street in less than two letters. Now consider the characteristics that you need to directly substitute in the utility formula, so I will give this formula again so that it is before your eyes.
must contain the total number of letters that the user had to type on the keyboard in the process of entering all the addresses of our sample. This value corresponds to the indicator The script displays. This indicator is calculated as follows.
The script displays. This indicator is calculated as follows. For all tests, the total amount of letters in the names of cities and streets that were typed during the test is determined. If a hint was not received for a city or street, then this amount includes the length of the entire name of this city or street, because it is believed that without a hint the user enters the entire name. Otherwise, only the number of letters that were actually typed before the prompt was received is included in the total amount.
Additionally, the length of the regions from those tests for which it was not possible to get a hint for the city is included in this amount. I assume that if the user has not received a hint for a city, then he will have to enter not only the name of the city, but also the name of the region in which this city is located. For cities for which the correct prompt was received, the region does not need to be entered, therefore, the regions of successful tests do not contribute to this amount.
Further, the term in the numerator of the first fraction of the utility formula
 . Coefficientreflects the time involved in choosing the tooltip from the proposed list. I said earlier that this coefficient was chosen empirically. This constant is protected in the script code and has a value of 3. That is, the user spends as much time choosing a hint as he takes to enter 3 arbitrary letters of the address. This coefficient is multiplied by- the number of times that prompts were used during a set. To do this, the test script gives a characteristic
. Coefficientreflects the time involved in choosing the tooltip from the proposed list. I said earlier that this coefficient was chosen empirically. This constant is protected in the script code and has a value of 3. That is, the user spends as much time choosing a hint as he takes to enter 3 arbitrary letters of the address. This coefficient is multiplied by- the number of times that prompts were used during a set. To do this, the test script gives a characteristic so that we have
so that we have  . Perfectlyshould be equal to twice the number of addresses in our sample, because Ideally, the prompts should be used twice for each address — once when entering the city, and the second time when entering the street. But in practice, services have shown less importance.
. Perfectlyshould be equal to twice the number of addresses in our sample, because Ideally, the prompts should be used twice for each address — once when entering the city, and the second time when entering the street. But in practice, services have shown less importance. Further in the utility formula we meet
, this is the total time that the user was waiting for prompts from the service. To receive it, the script gives a characteristic , so that
, so that  . During the tests, the script records the time that it takes to wait for a response from the service for each sent request. All this information for all queries is stored in a local sqlite database, and is summarized at the end of the test.
. During the tests, the script records the time that it takes to wait for a response from the service for each sent request. All this information for all queries is stored in a local sqlite database, and is summarized at the end of the test. The last participant in the utility formula is
, this is simply the total number of letters of all the addresses in the sample. This value does not depend on the test result; it just characterizes the sample itself. The script prints this number under the name . For our sample, it has a value of 137704. Exactly as many letters are contained in the names of regions, cities, and streets of all tests in the sample, as well as in the names of their types.
. For our sample, it has a value of 137704. Exactly as many letters are contained in the names of regions, cities, and streets of all tests in the sample, as well as in the names of their types. The total values of the characteristics described above are shown in the following table. For clarity, time
translated in minutes.| Achanter | Dadata | CLADER in the cloud | Fias24 | Yandex | Iqdq | ||
|---|---|---|---|---|---|---|---|
| 14808 | 33191 | 22397 | 50863 | 32820 | 36549 | 50092 |
| 7180 | 5848 | 7043 | 5588 | 6387 | 6057 | 5415 |
| 4.20 (min) | 39.29 (min) | 29.19 (min) | 58.81 (min) | 39.29 (min) | 14.67 (min) | 82.70 (min) |
for each of the three classes of users: "slow-moving", "average" and "rush." In my calculations, I used the following values. For the "low-speed" milliseconds, for the "average" - 500 milliseconds, and for the "rush" - 300 milliseconds. I selected these values empirically, asking several of my friends to type their mailing addresses on the keyboard, while measuring how much time it took them to search and enter a single letter. The final results are presented in the following table, for convenience, the utility values in the table are converted to percentages.
milliseconds, for the "average" - 500 milliseconds, and for the "rush" - 300 milliseconds. I selected these values empirically, asking several of my friends to type their mailing addresses on the keyboard, while measuring how much time it took them to search and enter a single letter. The final results are presented in the following table, for convenience, the utility values in the table are converted to percentages.| Achanter | Dadata | CLADER in the cloud | Fias24 | Yandex | Iqdq | ||
|---|---|---|---|---|---|---|---|
| Slug | 73% | 61% | 67% | 48% | 60% | 59% | 48% |
| Middling | 73% | 60% | 66% | 46% | 59% | 59% | 46% |
| Torozhzhka | 72% | 57% | 64% | 42% | 56% | 58% | 40% |
The CLADR in the cloud problems have been described above, the main contribution to low utility has made a big difference
since when typing a street for this service you need to enter its type - "ul", "per", etc. So in total, the user spends more time typing. Nevertheless, even with this in mind, a 42% time savings is a good indicator. At Iqdq, low response rates were influenced by a large response time, as well as problems with missed large cities issuing with prompts. Because of this, all addresses from these cities were entered completely, this led to an increase in the number of letters
that the user had to type. I was surprised that the usefulness of Google tips was not much affected by problems with addresses from New Moscow and Crimea, for which this service did not give the correct tips. It affected the overall good guessing ability of this service. If you look at the first table (see above), you will see that Google guesses the city by fewer letters than some of the considered services, which, due to their specialization, should do this in theory better.
The resulting utility values from Yandex are primarily due to the fact that this service guesses the city by a larger number of letters than all other services. I used to write that instead of hints for the city, he was drawn to offering streets from other cities.
If we analyze the utility of services in terms of user classes, then it can be seen that all services are more useful in relation to users who have poor keyboard skills. Indeed, “slow-moving” will be glad to any prompts, just to not enter data manually. However, for users who skillfully use the keyboard, the usefulness of the hints is slightly lower. To bring maximum benefit to them, the service should have a short response time.
In this section, all services can be divided into three groups - fast, medium and slow. For fast services (Akhanter and Yandex), the utility does not greatly depend on the speed of the user. Indeed, even if the user types quickly on the keyboard, fast services manage to return the correct hints, as a result, he gets the opportunity to use them. Medium-sized services (Google, Dadata, Fias24) are slightly more sensitive to the speed of the user's work, “rush” these services will bring less benefit than “slow-moving” and “middle peasants”. Well, for slow services this effect is noticeable even more.
Conclusion
Returning to the question posed in the title of the article, we can unequivocally answer “Yes,” modern web-based tooltips prompt well. I was able to quantify the benefits that they bring to ordinary inhabitants of the Runet. The figures obtained reflect the time savings that can be achieved by connecting these types of services to web forms, where you need to dial email addresses. In this case, you can save up to 70% of user time.
At the same time, remembering my history with pizza, I want to remind you that the formula proposed at the beginning of the article also implies negative utility values. I know at least one tooltip service for which the utility will be close to zero, and maybe even negative. Therefore, I would like to ask the authors who have already made or are making similar decisions: use my test and check if your development is so useful, as you think.
Test sources and test samples can be found on the github here . I also want to appeal to those who plan to repeat my experiments. If you manage to find inaccuracies or errors in the algorithms, please tell me, I will readily make corrections and adjust the results.
Well, thank the readers for their attention. I will be glad to answer questions in the comments.