Using the Tanimoto coefficient to search for people with the same preferences
Solving the exercises for the book “Programming the collective mind”, I decided to share the implementation of one of the algorithms mentioned in this book (Chapter 2 - Exercise 1).
The initial conditions are as follows: suppose we have a dictionary with critical ratings:
The higher the score, the more you like the movie.
It is necessary to calculate: how similar are the interests of the critics in order, for example, to be able to recommend films to the other based on the ratings of one?
Coefficient Tanimoto - describes the degree of similarity of the two sets. On the Internet, I found several options for the formula to calculate it. And I decided to dwell on the following:
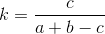
where k is the Tanimoto coefficient (a number from 0 to 1), the closer it is to 1, the more similar the sets;
a is the number of elements in the first set;
b is the number of elements in the second set;
c is the number of common elements in two sets;
Now we need to compare the ratings of two critics.
Just want to clarify one point. What should be considered a common element in our two sets? It is clear that presenting the assessment in its current form will not allow to accurately determine people with similar interests. Indeed, in essence, the same ratings of 3.5 and 4.0 for this algorithm are completely different numbers. Therefore, the Tanimoto coefficient, in my opinion, should be used if the number of rating options is no more than 2-3 (for example, “I liked it, I didn’t like it” or “I recommend it, I didn’t watch it, I don’t recommend it”) I decided to slightly change the dictionary for more convenient work and applied the following transformation to the ratings: If the rating is less than 3, then the film was not liked (the rating becomes - 0), otherwise it was liked (the rating becomes - 1). Data in this form are more suitable for our experiment.
At the output we get the following dictionary:
And then we write a function that calculates the similarity coefficient of the ratings of two critics.
Check the functionality of the tanimoto function.
>>> print tanimoto (critics, 'Gene Seymour', 'Lisa Rose')
>>> 0.5
In my opinion, the result is correct. It should be noted that with an increase in the number of ratings for each critic, the accuracy of calculating the similarity coefficient will increase.
If we had a database of assessments, it would be possible to calculate the coefficients of similarity of interests of people and begin to give recommendations on the Tanimoto method.
You can download the example text here .
You can download the full text of all examples from the book on the author's website . There you can find a more complete array with critical ratings.
The initial conditions are as follows: suppose we have a dictionary with critical ratings:
critics = {'Lisa Rose': {'Superman Returns': 3.5,' You, Me and Dupree ': 2.5,' The Night Listener ': 3.0},
' Gene Seymour ': {' Superman Returns': 5.0, 'The Night Listener ': 3.5,' You, Me and Dupree ': 3.5}}
The higher the score, the more you like the movie.
It is necessary to calculate: how similar are the interests of the critics in order, for example, to be able to recommend films to the other based on the ratings of one?
Coefficient Tanimoto - describes the degree of similarity of the two sets. On the Internet, I found several options for the formula to calculate it. And I decided to dwell on the following:
where k is the Tanimoto coefficient (a number from 0 to 1), the closer it is to 1, the more similar the sets;
a is the number of elements in the first set;
b is the number of elements in the second set;
c is the number of common elements in two sets;
Now we need to compare the ratings of two critics.
Just want to clarify one point. What should be considered a common element in our two sets? It is clear that presenting the assessment in its current form will not allow to accurately determine people with similar interests. Indeed, in essence, the same ratings of 3.5 and 4.0 for this algorithm are completely different numbers. Therefore, the Tanimoto coefficient, in my opinion, should be used if the number of rating options is no more than 2-3 (for example, “I liked it, I didn’t like it” or “I recommend it, I didn’t watch it, I don’t recommend it”) I decided to slightly change the dictionary for more convenient work and applied the following transformation to the ratings: If the rating is less than 3, then the film was not liked (the rating becomes - 0), otherwise it was liked (the rating becomes - 1). Data in this form are more suitable for our experiment.
def prepare_for_tanimoto (critics_arr):
arr = critics_arr.copy ()
for critic in arr:
for film in arr [critic]:
if arr [critic] [film] <3:
arr [critic] [film] = 0
else:
arr [ critic] [film] = 1
return arr
At the output we get the following dictionary:
critics = {'Lisa Rose': {'Superman Returns': 1,' You, Me and Dupree ': 0,' The Night Listener ': 1},
' Gene Seymour ': {' Superman Returns': 1, 'The Night Listener ': 1,' You, Me and Dupree ': 1}}
And then we write a function that calculates the similarity coefficient of the ratings of two critics.
def tanimoto (critics_arr, critic1, critic2):
arr = prepare_for_tanimoto (critics_arr)
a = len (arr [critic1])
b = len (arr [critic2])
c = 0.0
for film in arr [critic1]:
if arr [critic1] [film] == arr [critic2] [film]:
c = c + 1
koef = c / (a + b - c)
return koef
Check the functionality of the tanimoto function.
>>> print tanimoto (critics, 'Gene Seymour', 'Lisa Rose')
>>> 0.5
In my opinion, the result is correct. It should be noted that with an increase in the number of ratings for each critic, the accuracy of calculating the similarity coefficient will increase.
If we had a database of assessments, it would be possible to calculate the coefficients of similarity of interests of people and begin to give recommendations on the Tanimoto method.
You can download the example text here .
You can download the full text of all examples from the book on the author's website . There you can find a more complete array with critical ratings.