Can we open the black box of artificial intelligence?
- Transfer

Dean Pomerleau still remembers how he first had to deal with the black box problem. In 1991, he made one of the first attempts in that area, which is now being studied by everyone who is trying to create a ro-mobile: learning to drive a computer.
And this meant that you need to sit behind the wheel of a specially prepared Humvi (army all-terrain vehicle), and ride through the streets of the city. So talks about this Pomelo, at that time a former graduate student in robotics at Carnegie Mellon University. A computer programmed to track through the camera, interpret what was happening on the road and memorize all movements of the driver went along with him. Pomelo hoped that the car would eventually build enough associations for independent driving.
For each trip, Pomelo coached the system for several minutes and then let her steer on his own. Everything seemed to be going well - until one day Humvee, driving up to the bridge, suddenly turned to the side. Man managed to avoid an accident, only quickly grabbing the steering wheel and returning control.
In the laboratory, Pomelo tried to sort out a computer error. “One of the tasks of my scientific work was to open the 'black box' and find out what he was thinking about,” he explains. But how? He programmed the computer as a “neural network” - a type of artificial intelligence that simulates the brain, promising to be better than standard algorithms in handling complex situations involving the real world. Unfortunately, such networks are as opaque as the real brain. They do not store everything studied in a neat block of memory, but instead smear the information so that it is very difficult to decipher. Only after a wide range of tests of the software’s reaction to various input parameters, Pomelo discovered a problem: the network used grass along the edges of the roads to determine directions, and therefore the appearance of the bridge confused her.
After 25 years, deciphering black boxes has become exponentially more difficult, while increasing the urgency of this task. There has been an explosive increase in the complexity and prevalence of technology. Pomelo, a part-time teaching robot at Carnegie Mellon, describes his long-standing system as a “neural network for the poor”, compared to the huge neural networks implemented on modern machines. The technique of deep learning (GO), in which networks are trained on archives of “big data”, finds various commercial applications, from robotic vehicles to product recommendations on sites made on the basis of browsing history.
Technology promises to be ubiquitous in science. Future radio observatories will use HOs to search for meaningful signals in data arrays thatotherwise you will not rake . Gravitational wave detectors will use them to understand and eliminate small noises. Publishers will use them to filter and tag millions of research papers and books. Some believe that in the end, computers using GO will be able to demonstrate imagination and creativity. “You can just drop the data into the car, and it will give you back the laws of nature,” says Jean-Roch Vlimant, a physicist at the California Institute of Technology.
But such breakthroughs will make the black box problem even more acute. How exactly does the car find meaningful signals? How can you be sure that her findings are correct? How much should people trust deep learning? “I think that with these algorithms we have to give in,” says robotics specialist Hod Lipson from Columbia University in New York. He compares the situation with a meeting with intelligent aliens, whose eyes see not only red, green and blue, but also the fourth color. According to him, it will be very difficult for people to understand how these aliens see the world, and for them to explain it to us. Computers will have the same problems explaining their decisions, he says. "At some point, it will begin to resemble attempts to explain Shakespeare to a dog."
Having encountered such problems, AI researchers react in the same way as Pomelo - they open the black box and perform actions resembling neurology to understand the operation of networks. The answers are not intuitive, says Vincenzo Innocente, a CERN physicist who first used AI in his field. “As a scientist, I am not satisfied with the simple ability to distinguish dogs from cats. A scientist should be able to say: the difference is in this and that. ”
Good trip
The first neural network was created in the early 1950s, almost immediately after the advent of computers capable of working on the necessary algorithms. The idea is to emulate the work of small counting modules - neurons - arranged in layers and connected to digital “synapses”. Each module in the lower layer receives external data, such as image pixels, then spreads this information upwards to some of the modules in the next layer. Each module in the second layer integrates the input data from the first layer according to a simple mathematical rule, and transmits the result further. As a result, the upper layer gives the answer - for example, it relates the original image to "cats" or "dogs".
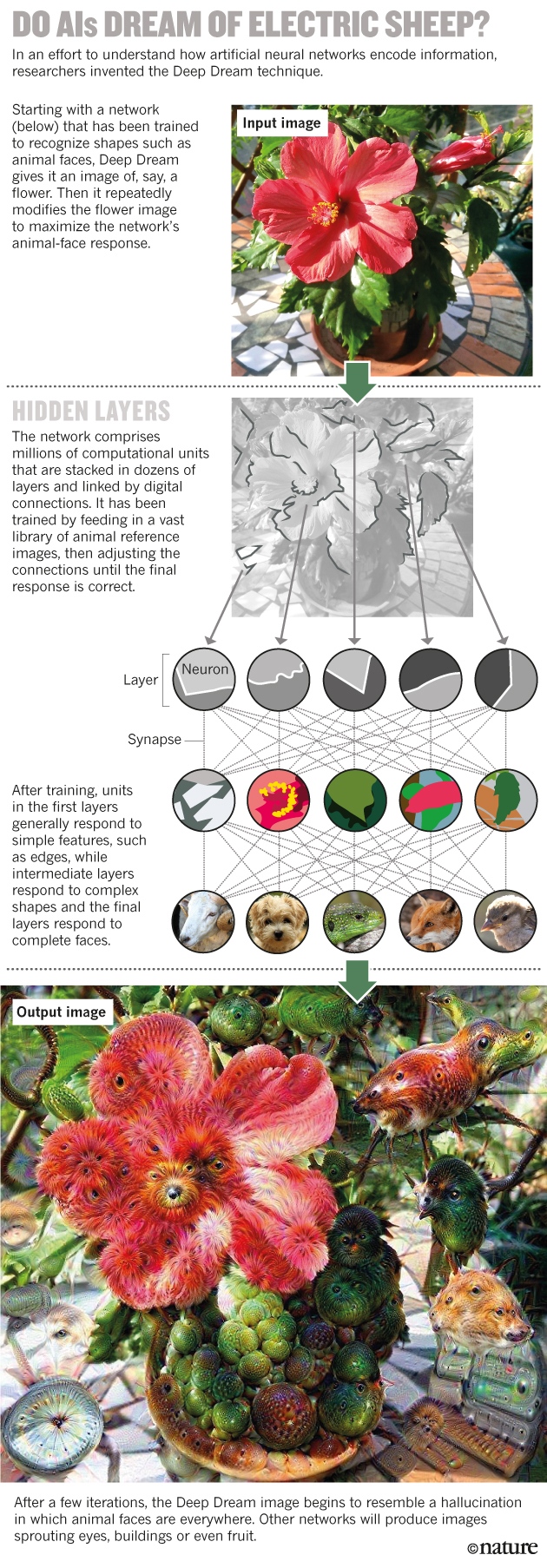
Do AI dream of electricians? The Deep Dream technology (Deep Dream) provides as input data for a neural network trained on facial recognition, an image of, say, a flower - and then sequentially changes it to get the maximum response from the neural network.
After training, the first layer of the network on average responds to simple forms like boundaries, medium ones to complex forms, and the latter is already working with people entirely.
The result of Deep Dream is reminiscent of a hallucination.
The capabilities of such networks stem from their ability to learn. By learning on the initial data set with the given correct answers, they gradually improve their characteristics, adjusting the influence of all connections to produce the correct results. The process emulates the training of the brain that strengthens and weakens the synapses, and gives the output a network capable of classifying data that was originally not part of the training set.
The possibility of learning tempted physicists from CERN in the 1990s, when they were among the first to adapt large neural networks to work for science. Neural networks have greatly helped in the reconstruction of the trajectories of subatomic shrapnel, scattered to the side during collisions of particles at the Large Hadron Collider.
This form of learning is also the reason that the information is very smeared over the network: as in the brain, its memory is encoded in the strength of various compounds, and not stored in certain places, as in a familiar database. “Where is the first digit of your phone number stored in your brain? Perhaps in a set of synapses, perhaps not far from the rest of the numbers, ”says Pierre Baldi, a machine learning specialist (MO) from the University of California. But there is no certain sequence of bits encoding the number. As a result, according to computer science expert Jeff Clune from the University of Wyoming, “although we create these networks, we can understand them no better than the human brain.”
For scientists working with big data, this means that GO must be used carefully. Andrea Vedaldi, an informatics specialist at the University of Oxford, explains: Imagine that in the future the neural network will be trained on mammograms , which will indicate whether the women in question have breast cancer. After that, let us assume that the tissues of a certain healthy woman seem to be susceptible to the machine. “A neural network can learn to recognize tumor markers — those that we don’t know about but can predict cancer.”
But if the machine cannot explain how it determines it, then, according to Vedaldi, for doctors and patients this will become a serious dilemma. It is not easy for a woman to undergo preventive removal of the mammary gland due to the presence of genetic features that can lead to cancer. And it will be even more difficult to make such a choice, since it will even be unknown what this factor is - even if the predictions of the machine turn out to be accurate.
“The problem is that knowledge is embedded in the network, not in us,” says Michael Tyka, a biophysicist and programmer at Google. “Have we understood anything? No - this is a network understood. ”
Several groups of scientists dealt with the problem of the black box in 2012. A team led by Geoffrey Hinton, a MoD specialist from the University of Toronto, participated in a computer vision competition, and for the first time demonstrated that using GO to classify photographs from a database containing 1.2 million images exceeded any other approach with using AI.
Understanding how this is possible, the Vedaldi group took the Hinton algorithms, designed to improve the neural network, and drove them backwards. Instead of learning the network for the correct interpretation of the answer, the team took a pre-trained network and tried to recreate the pictures that they trained. This helped the researchers determine how the machine presents some features — it was as if they were asking for some hypothetical neural network predicting cancer, “What part of a mammogram pushed you to the mark about cancer risk?”.
Last year, Taika and his colleagues at Google used a similar approach. Their algorithm, which they called Deep Dream, begins with a picture of, say, a flower, and modifies it to improve the response of a certain top-level neuron. If the neuron likes to mark images of, say, birds, then the modified picture will begin to show birds everywhere. The final pictures resemble visions under LSD, where birds are visible in faces, buildings, and many more. “I think this is very similar to a hallucination,” says Taika, who is also an artist. When he and his colleagues saw the potential of the algorithm in the creative field, they decided to make it free to download. Within a few days, this topic became viral.
Using techniques that maximize the output of any neuron, and not just one of the top ones, the Cluna team in 2014 found that the black box problem could be more difficult than it seemed before. Neural networks are very easy to fool with pictures that people perceive as random noise or abstract patterns. For example, the network can take wavy lines and decide that it is a starfish, or confuse black and white stripes with a school bus. Moreover, the same trends have arisen in networks that have been trained on other data sets.
Researchers have proposed several solutions to the problem of fooling networks, but a common solution has not yet been found. In real applications this can be dangerous. One of the frightening scenarios, according to Clun, is that hackers learn to use these network flaws. They can send the mobile phone to a billboard, which he will take for the road, or deceive the retina scanner at the entrance to the White House. “We need to roll up our sleeves and conduct in-depth scientific research in order to make the MoD more reliable and clever,” concludes Klun.
Such problems have led some computer scientists to think that it is not worth dwelling on neural networks alone. Zubin Gahramani [Zoubin Ghahramani], a MoD researcher at the University of Cambridge, says that if an AI has to give answers that people can easily interpret, this will lead to "a lot of problems that GO cannot help to cope with." One of the fairly understandable scientific approaches was first shown in 2009 by Lipson and computational biologist Michael Schmidt, who worked at Cornell University at the time. Their algorithm, Eureqa, demonstrated the process of re-discovering Newton's laws by observing a simple mechanical object — a system of pendulums — in motion.
Starting with a random combination of mathematical bricks like +, -, sine and cosine, Eureqa by trial and error, similar to Darwinian evolution, changes them until it comes to the formulas describing the data. She then offers experiments to test the models. One of its advantages is simplicity, says Lipson. “The model developed by Eureqa usually has a dozen parameters. Neural networks have millions of them. ”
On autopilot
Last year, Garahmani published the algorithm for automating the work of a scientist based on data, from raw data to finished scientific work. His software, Automatic Statistician, notices trends and anomalies in data sets and gives a conclusion, including a detailed explanation of the reasoning. This transparency, in his words, is “completely critical” for use in science, but also important for commercial applications. For example, in many countries, banks that refuse to borrow, are required by law to explain the reason for the refusal - and this may be impossible for the GO algorithm.
The same concerns apply to different organizations, explains Ellie Dobson, director of data science at Arundo Analytics in Oslo. If, say, in Britain, something goes wrong due to a change in the base rate, the Bank of England cannot simply say “it's all because of the black box”.
But, despite all these fears, computer scientists say that attempts to create a transparent AI should be an addition to the GO, and not a replacement for this technology. Some transparent techniques may work well in areas already described as a set of abstract data, but they cannot cope with perception — the process of extracting facts from raw data.
As a result, according to them, the complex answers received thanks to the Ministry of Defense should be part of the toolkit of science, since the real world is complex. For phenomena such as the weather or the financial market, reductionist, synthetic descriptions may simply not exist. “There are things that cannot be described in words,” says Stéphane Mallat, an applied mathematician at the Paris Polytechnic School. “When you ask the doctor why he made such a diagnosis, he will give you reasons,” he says. - But why then do you need 20 years to become a good doctor? Because information is received not only from books. ”
According to Baldi, a scientist should accept GO and not much to bathe about the black boxes. They have such a black box in their head. "You constantly use the brain, you always trust it, and you do not understand how it works."