The main secret to developing good Electron applications
- Transfer
Some fiercely hate Electron applications. That the application includes the Chromium browser seems, to put it mildly, strange. This feeling is enhanced during the work with such applications. They consume a lot of memory, load slowly and do not have a particularly high reaction rate to user interactions. It is not easy to develop a good web application. Why are web technologies dragged into the desktop environment? After all, there is a feeling that in this environment they create a bunch of problems?
The author of the material, the translation of which we publish today, says that he will not play the role of defender of Electron, although everything speaks of the success of this platform. True, no one is going to discount the excesses that are inherent in Electron applications. Is it possible, while developing such applications, to kill two birds with one stone in one shot?

Some of Electron's problems (large file sizes, slow loading) are a legacy of the technologies on which this platform is based. They need to be addressed at a low level. More serious problems (memory consumption, slowness of interfaces) can be solved at the level at which Electron-applications are being developed. However, solving these problems is not easy. What if there is a secret, knowing which you can, in automatic mode, minimize these shortcomings?
If you like to read program code, you can immediately look into this repository. Here is the project that will be considered in this material.
The secret to developing high-quality Electron applications is to perform the bulk of the calculations on the local system, in the background processes. The less you rely on cloud services, and the more work you put into background processes, the more you can experience the following positive effects:
Here I am not talking about other advantages of local data storage, for example, about the possibility of working without connecting to a network.
Take a look at how much memory my Electron application consumes - Actual's personal finance manager . This program stores all its data locally. Data synchronization between different devices is an optional feature, it does not affect the main functionality. I suppose, given that this application is designed to work with large amounts of data, its memory consumption figures speak for themselves.
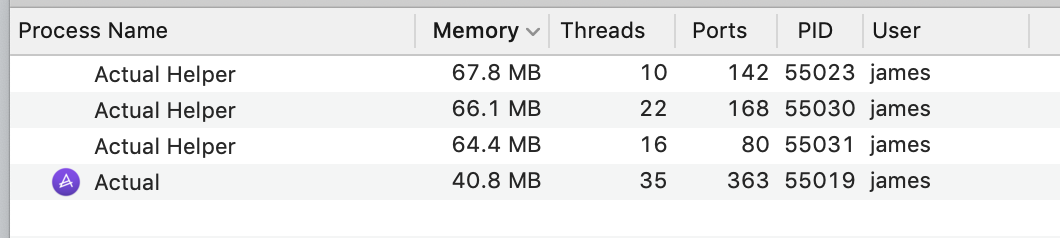
Memory consumption by the Actual
application An application that does not perform any active actions consumes a total of 239.1 MB of memory. This indicator may be more, it depends on what exactly is happening in the application, but it is possible to take just the specified number as the base. This is not perfect, but not so bad. At least - better than the 1371 MB of memory that is required on my Slack computer. I must say that Slack is an atypical example of an Electron application, characterized by specific problems. There was some sensation around Electron due to Slack. Other applications, such as Notion or Airtable, consume approximately 400-600 MB of memory. And this means that my application wins well in this regard and they have.
I must say that the figure of 239.1 MB was obtained by me before any optimization. I plan to rewrite some of the extremely important and memory intensive parts of the application in Rust. This should significantly reduce the memory requirements of the application.
The background server can optimize its own memory consumption by loading into the memory only the data that is needed at a certain point in time. It is best to use something like SQLite for data storage. This DBMS is already seriously optimized for solving such problems (seriously - just use SQLite). In addition, it should be noted that moving various calculations to background processes allows the user interface of the application to respond to user influences as quickly as possible.
It turned out that using a background server in an Electron application gives the developer interesting opportunities. In the next section, we will talk about all those incredible things that can be done with its use.
Even if your application is seriously tied to cloud data, you may need a background process if you intend to work with the Node.js API. Interaction with these APIs is possible only from background processes. As a matter of fact, whatever your Electron application may be, I believe that getting to know the project that we are going to examine now can give you some useful ideas.
I created the electron-with-server-example application in order to show everything that needs to be configured to develop truly local Electron applications using its example. I did this in an effort to captivate programmers by creating similar projects. I would like to meet a similar project at a time when I was just starting to work with Electron.
Technical information about the application can be found in the file
Now let's slow down a bit and take a closer look at the last item on this list. In development mode, can you interact with the server through a separate browser window?
Client and server parts of the application
Yes, the way it is. After I learned how to start background processes, I realized, firstly, that I have at my disposal the tools of the Chromium developer. And secondly - I realized that, for debugging purposes, I can use them to debug Node.js code. As a result, I’m talking about the fact that you can interact with Node.js through a browser. This allows you to use the rich Chromium-based browser developer toolkit to debug server code.
Now let's look at all the interesting things that we can do thanks to the application of the above application launch scheme.
I added the
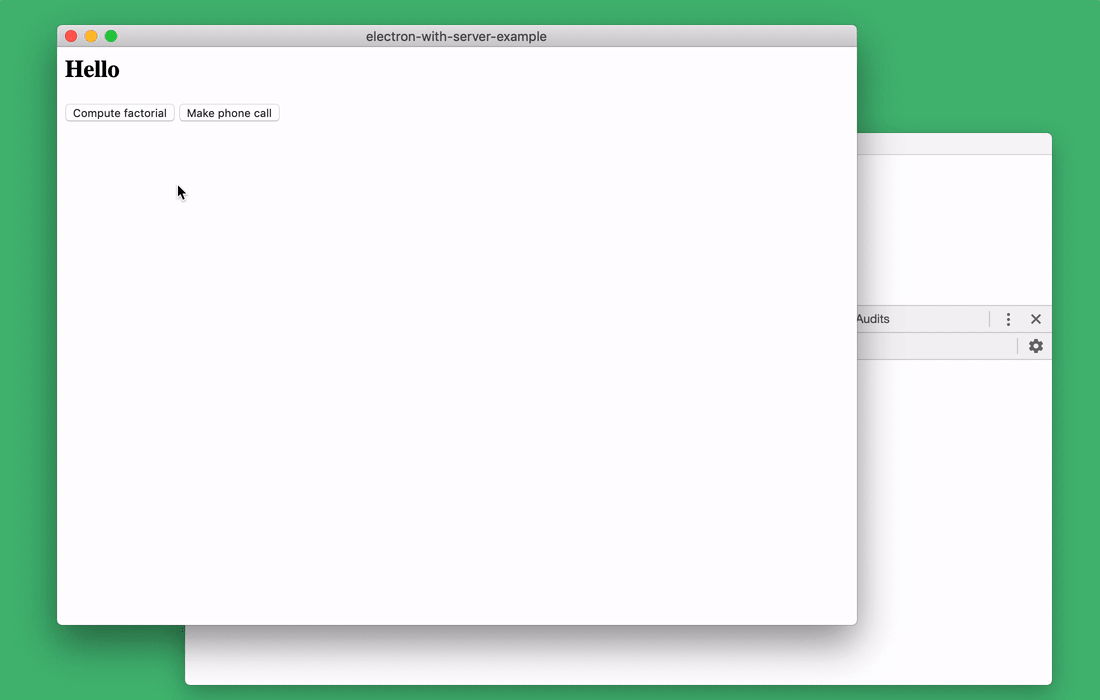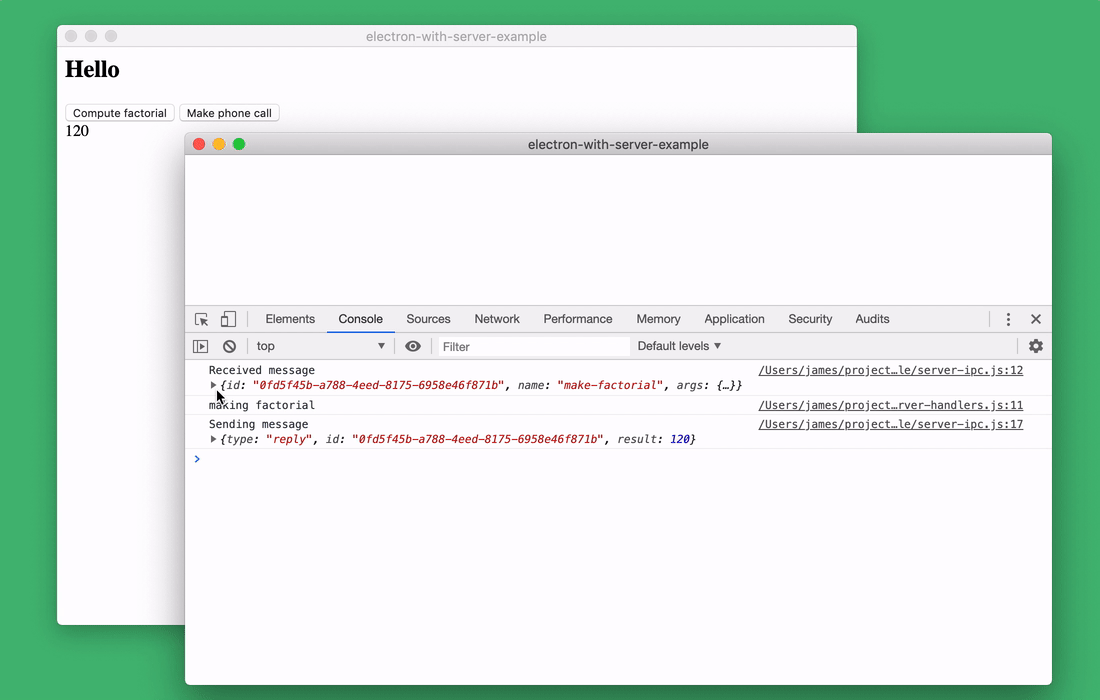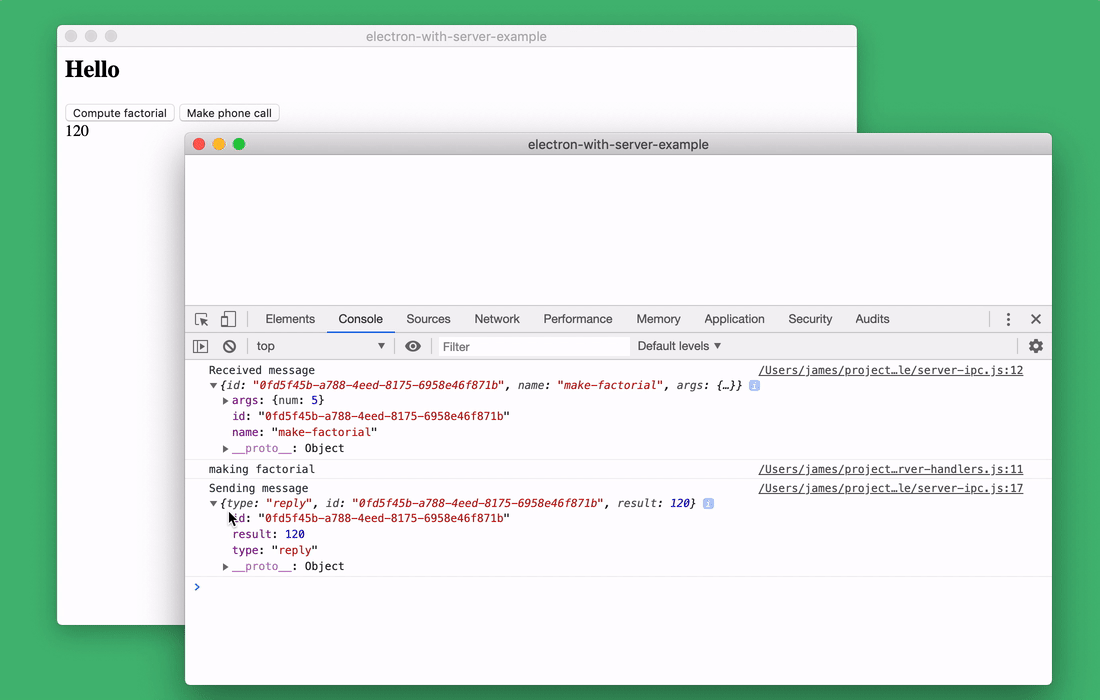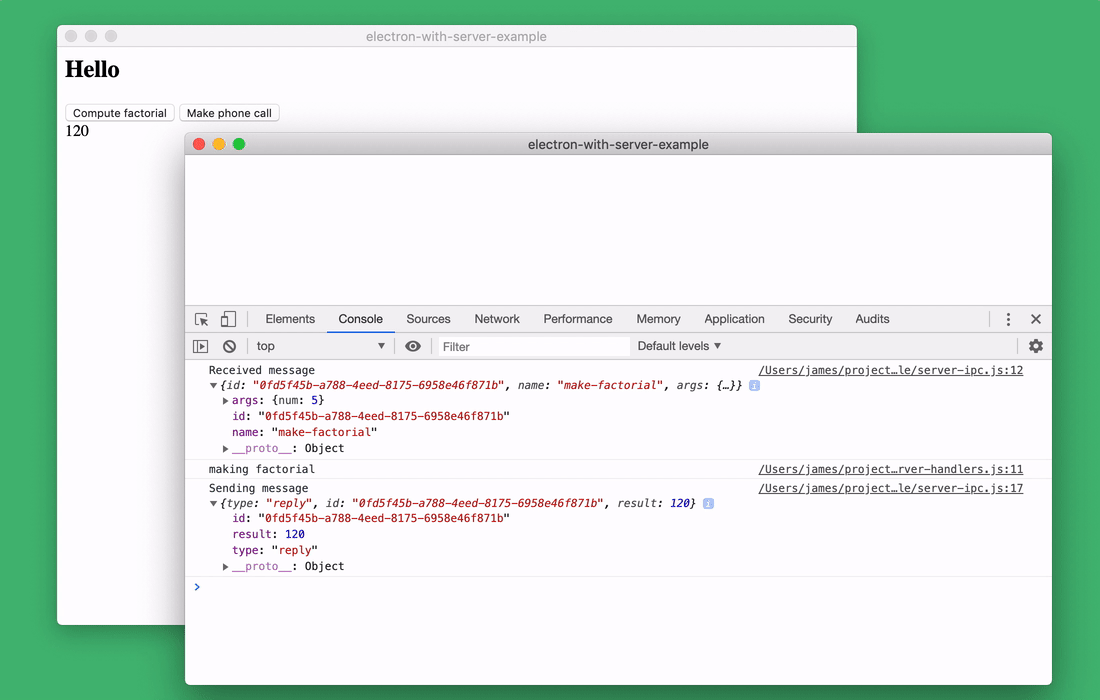
Debugging Node.js applications in the browser console
When debugging the server side of the application using a browser, you can use step-by-step code execution. This is not to say that it is something absolutely fantastic. But it’s very convenient that this feature is always at hand and does not require the use of additional programs.
Step-by-step code execution
Maybe this is my favorite tool. This is a brilliant standard tool for researching code performance, which allows you to profile the server side of the application.
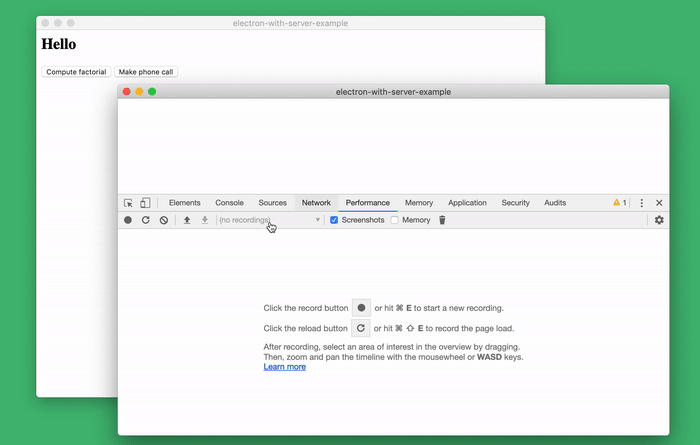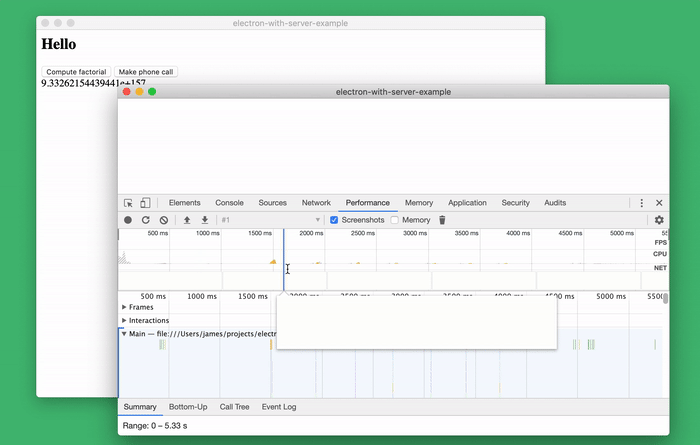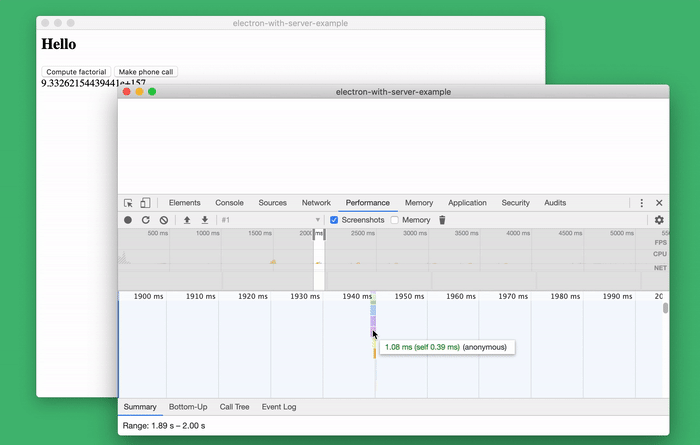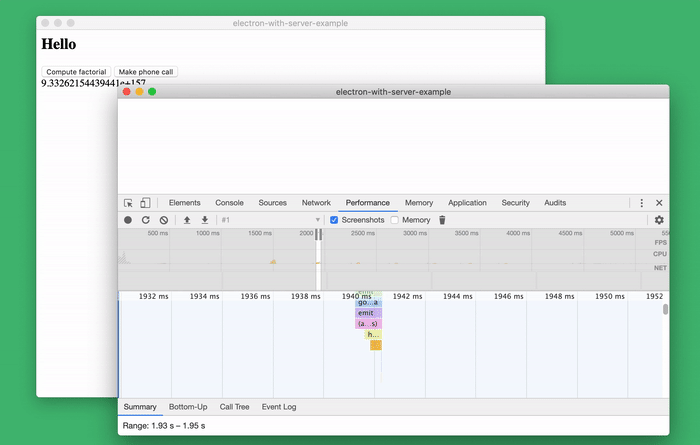
Researching the performance of server code
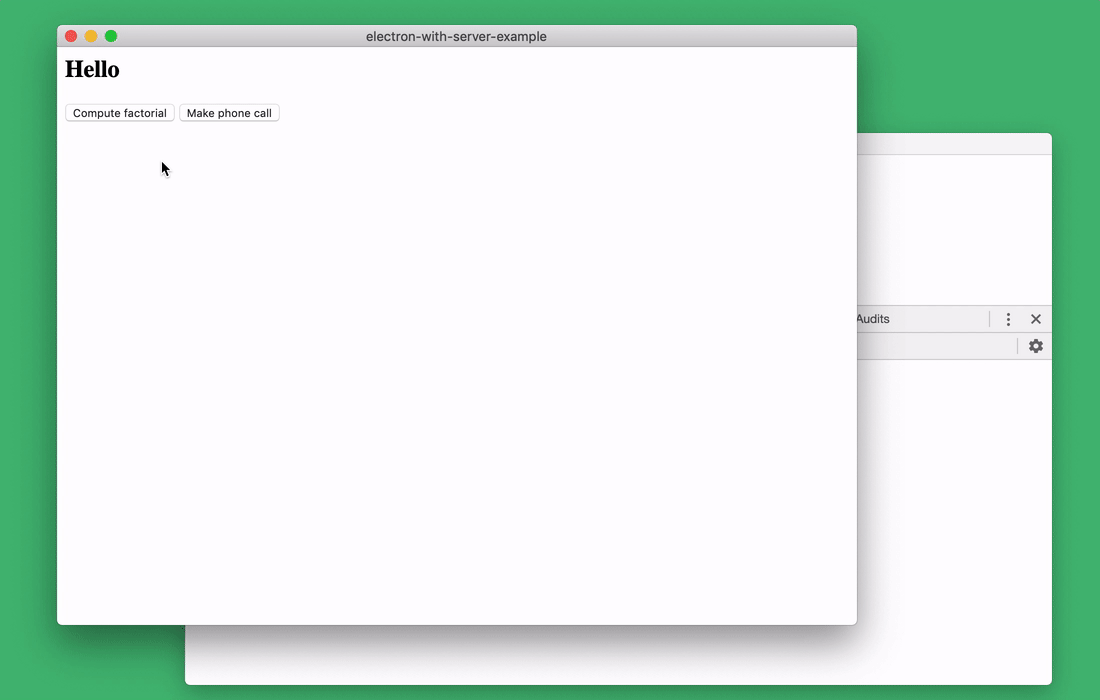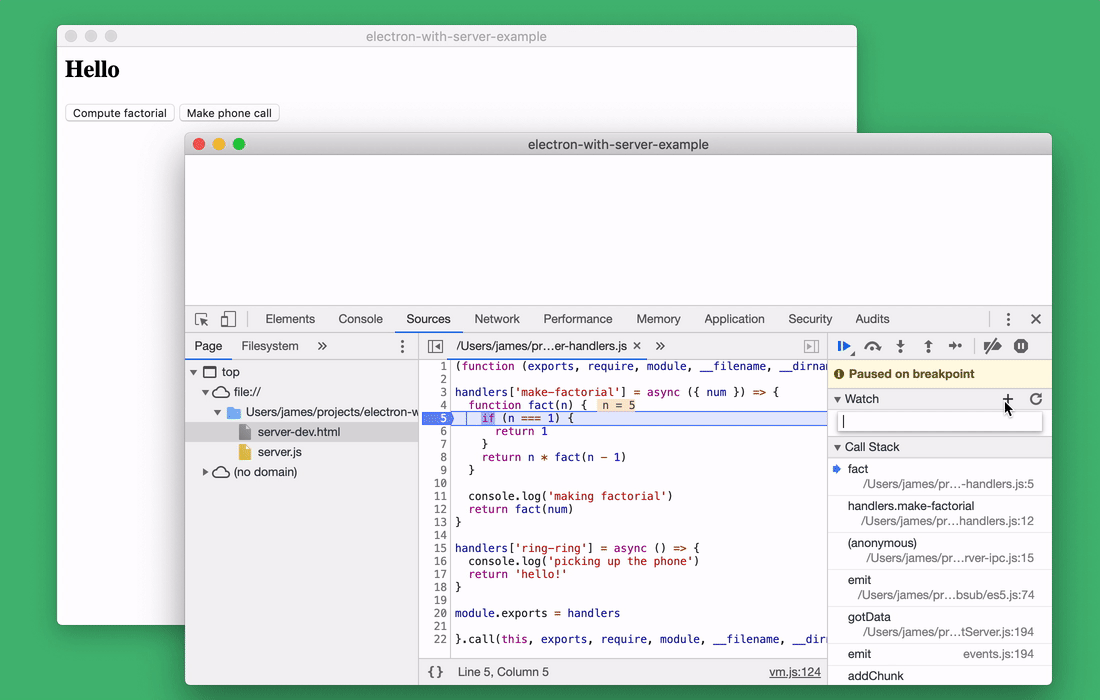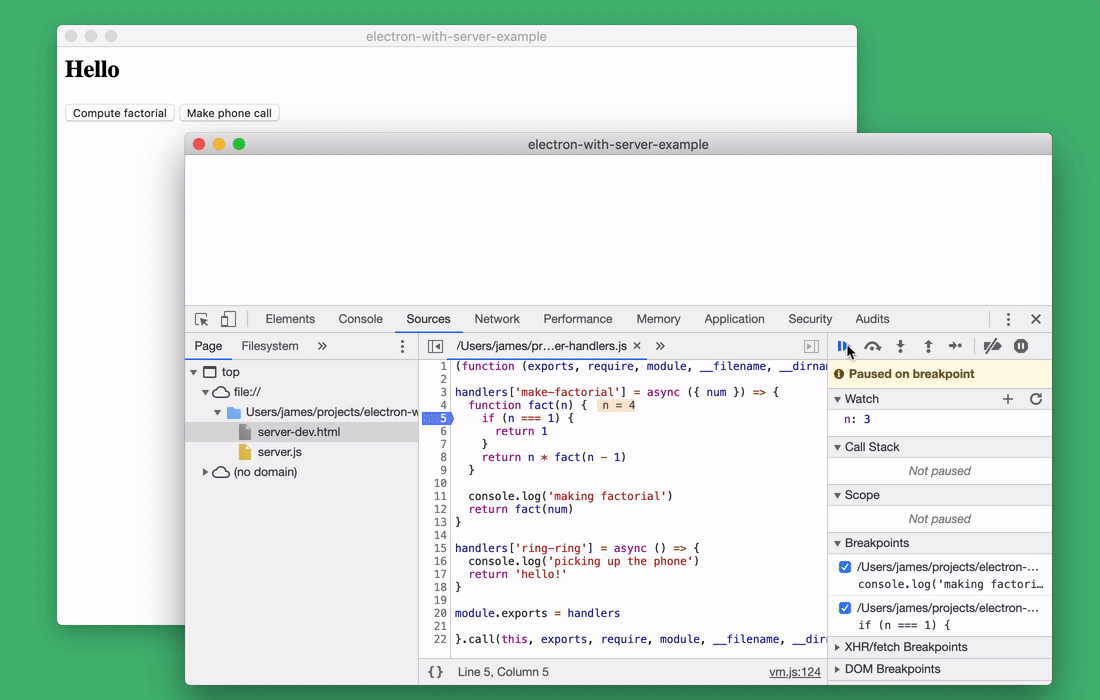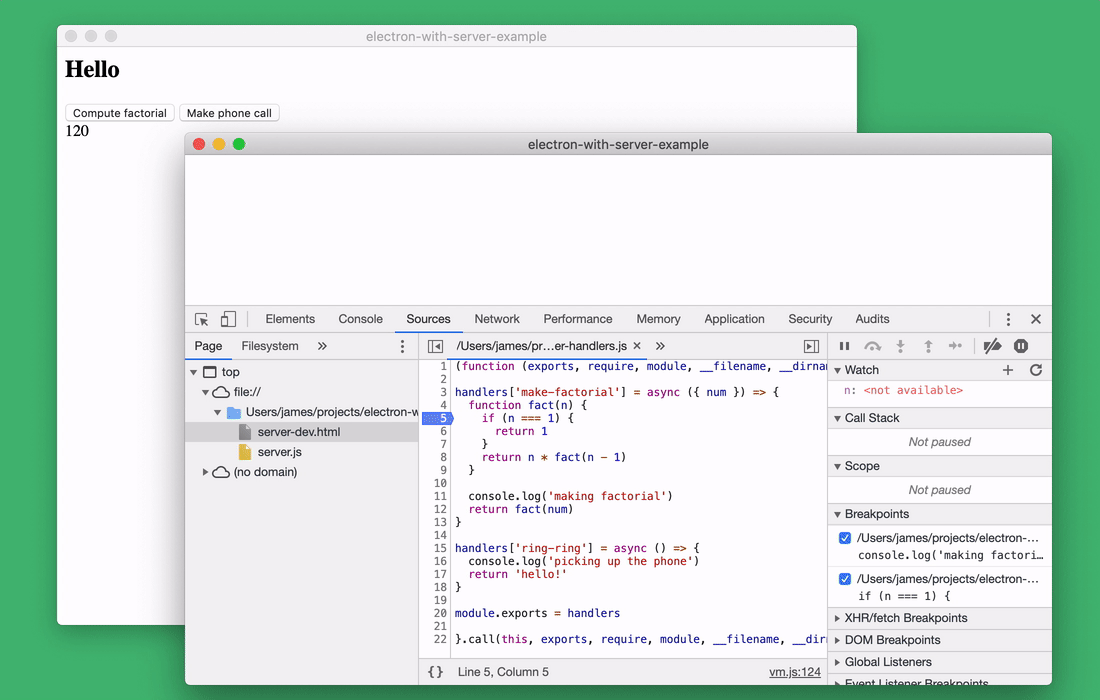
Using the tools of the browser developer, you can even examine what happens when the background process starts (this is most likely the hardest part of starting the application).
In order to do this, just start the process of recording indicators and reload the window. Rebooting will cause the server to restart. This leads us to the next step.
Another of the options for debugging server code in a browser is that since server debugging is performed in a browser window, simply reloading the contents of the window causes the server to restart! It is enough to use a key combination
The following figure shows how, by changing the server code, I reloaded the page by clicking
Server reboot
Usually, when debugging a server, I simply add commands to the necessary places in the code
In the console, you can use the Node.js command
Suppose we need to work with a module
Let's create a system to store server status. In our case, it will be a list of all data passed to the function
You can examine the status of the server from the console by connecting the appropriate module and looking at
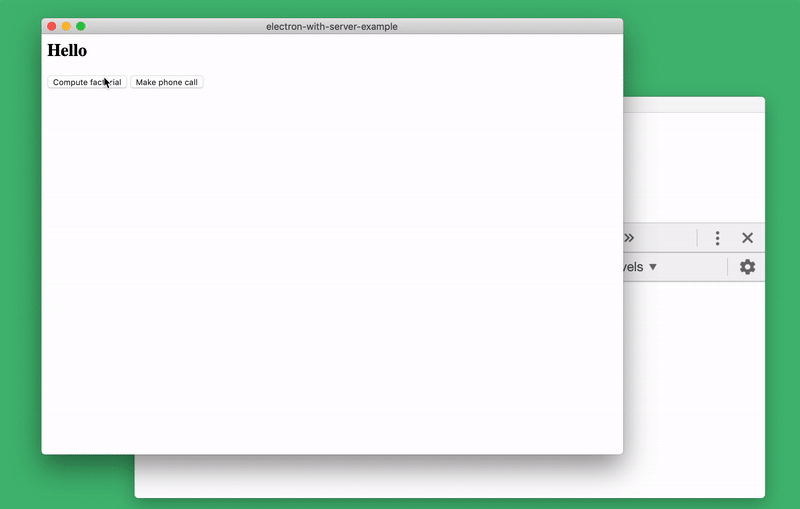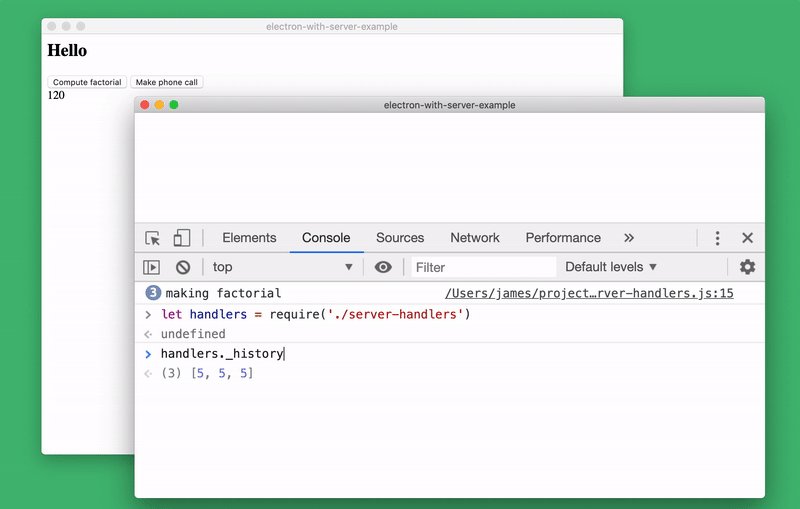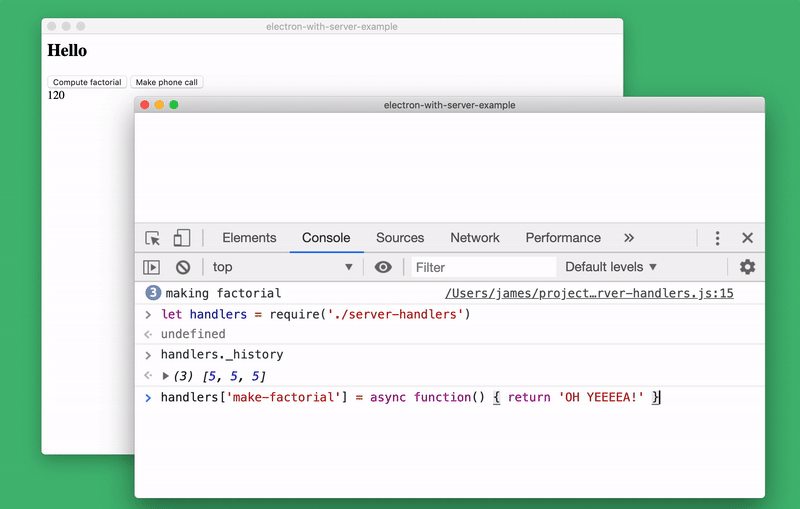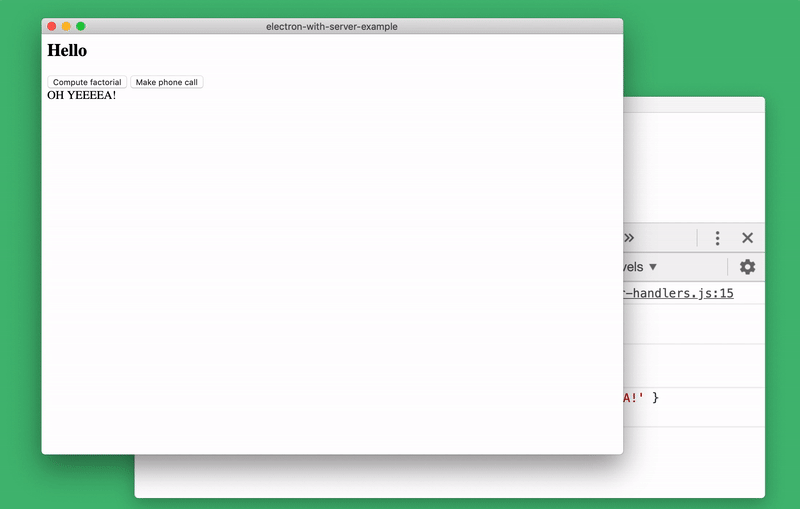
Server Status Research
Take a look at the electron-with-server-example repository in order to read about the details of the project implementation and see the code of the server side of the Electron application.
If you use Visual Studio Code, then you may be used to a high-quality integration of developer tools with the Node.js server. With this approach, you can start the server yourself, separately from the Electron application. After that, you can tell Electron that you need to connect to the process owned by VS Code. However, I prefer to use existing Electron development tools.
This means that the programmer has the opportunity to use any third-party code editing tools and at the same time have full access to all browser developer tools.
Over the past few years, I have been developing the Actual application and constantly use what I just talked about. And I want to say that I really like all this. Perhaps the work on the Node.js part of this application has become the source of the most pleasant programming experience I have ever experienced.
In addition, it’s very important that the principles described above help us develop truly local applications. We already have all the technologies necessary for this. The main thing is to use them correctly.
Dear readers! How do you feel about Electron based apps?

The author of the material, the translation of which we publish today, says that he will not play the role of defender of Electron, although everything speaks of the success of this platform. True, no one is going to discount the excesses that are inherent in Electron applications. Is it possible, while developing such applications, to kill two birds with one stone in one shot?
Some of Electron's problems (large file sizes, slow loading) are a legacy of the technologies on which this platform is based. They need to be addressed at a low level. More serious problems (memory consumption, slowness of interfaces) can be solved at the level at which Electron-applications are being developed. However, solving these problems is not easy. What if there is a secret, knowing which you can, in automatic mode, minimize these shortcomings?
If you like to read program code, you can immediately look into this repository. Here is the project that will be considered in this material.
The essence of the secret
The secret to developing high-quality Electron applications is to perform the bulk of the calculations on the local system, in the background processes. The less you rely on cloud services, and the more work you put into background processes, the more you can experience the following positive effects:
- Instant data loading. Application users will never have to wait for data to download over the network. Data is downloaded from local storage. This immediately gives the application a tangible performance boost.
- Low caching requirements. The client application does not need to worry particularly about caching. This is because all the data he needs is available locally. In order for a web application to reach a decent level of performance, it usually needs to load an impressive amount of data into its local state. This is one of the reasons for the very high memory consumption of Electron applications.
Here I am not talking about other advantages of local data storage, for example, about the possibility of working without connecting to a network.
Take a look at how much memory my Electron application consumes - Actual's personal finance manager . This program stores all its data locally. Data synchronization between different devices is an optional feature, it does not affect the main functionality. I suppose, given that this application is designed to work with large amounts of data, its memory consumption figures speak for themselves.
Memory consumption by the Actual
application An application that does not perform any active actions consumes a total of 239.1 MB of memory. This indicator may be more, it depends on what exactly is happening in the application, but it is possible to take just the specified number as the base. This is not perfect, but not so bad. At least - better than the 1371 MB of memory that is required on my Slack computer. I must say that Slack is an atypical example of an Electron application, characterized by specific problems. There was some sensation around Electron due to Slack. Other applications, such as Notion or Airtable, consume approximately 400-600 MB of memory. And this means that my application wins well in this regard and they have.
I must say that the figure of 239.1 MB was obtained by me before any optimization. I plan to rewrite some of the extremely important and memory intensive parts of the application in Rust. This should significantly reduce the memory requirements of the application.
The background server can optimize its own memory consumption by loading into the memory only the data that is needed at a certain point in time. It is best to use something like SQLite for data storage. This DBMS is already seriously optimized for solving such problems (seriously - just use SQLite). In addition, it should be noted that moving various calculations to background processes allows the user interface of the application to respond to user influences as quickly as possible.
It turned out that using a background server in an Electron application gives the developer interesting opportunities. In the next section, we will talk about all those incredible things that can be done with its use.
Even if your application is seriously tied to cloud data, you may need a background process if you intend to work with the Node.js API. Interaction with these APIs is possible only from background processes. As a matter of fact, whatever your Electron application may be, I believe that getting to know the project that we are going to examine now can give you some useful ideas.
Electron-with-server-example application
I created the electron-with-server-example application in order to show everything that needs to be configured to develop truly local Electron applications using its example. I did this in an effort to captivate programmers by creating similar projects. I would like to meet a similar project at a time when I was just starting to work with Electron.
Technical information about the application can be found in the file
README. Here is a general overview of the project:- It creates the usual Node.js process, used to execute server code in the background.
- In it, using node-ipc , an IPC channel is created, which is designed to organize direct interaction between the backend and the user interface of the application.
- If the project is launched in development mode, then the server does not start as a background process. You can interact with it through a separate browser window. This is for debugging purposes.
Now let's slow down a bit and take a closer look at the last item on this list. In development mode, can you interact with the server through a separate browser window?
Client and server parts of the application
Yes, the way it is. After I learned how to start background processes, I realized, firstly, that I have at my disposal the tools of the Chromium developer. And secondly - I realized that, for debugging purposes, I can use them to debug Node.js code. As a result, I’m talking about the fact that you can interact with Node.js through a browser. This allows you to use the rich Chromium-based browser developer toolkit to debug server code.
Now let's look at all the interesting things that we can do thanks to the application of the above application launch scheme.
Using console
I added the
server-ipc.jsrequest and response logging commands to the file . I can explore them using the browser console.Debugging Node.js applications in the browser console
Step-by-step code execution
When debugging the server side of the application using a browser, you can use step-by-step code execution. This is not to say that it is something absolutely fantastic. But it’s very convenient that this feature is always at hand and does not require the use of additional programs.
Step-by-step code execution
Profiling
Maybe this is my favorite tool. This is a brilliant standard tool for researching code performance, which allows you to profile the server side of the application.
Researching the performance of server code
Using the tools of the browser developer, you can even examine what happens when the background process starts (this is most likely the hardest part of starting the application).
In order to do this, just start the process of recording indicators and reload the window. Rebooting will cause the server to restart. This leads us to the next step.
Rebooting the server using the key combination Cmd + R or Ctrl + R
Another of the options for debugging server code in a browser is that since server debugging is performed in a browser window, simply reloading the contents of the window causes the server to restart! It is enough to use a key combination
Cmd+R(or, for Windows, Ctrl+R), and at your disposal are the latest changes made to the server code. In this case, the front-end data is saved. This means that you can continue working with the client part of the application, but, after restarting the server, the client part will already work with the new version of the server code. This is reminiscent of something like a “hot” code swap on a running server. The following figure shows how, by changing the server code, I reloaded the page by clicking
Cmd+R. After that, I continued to work with the client, which is now interacting with the new version of the server.Server reboot
Researching the running server side of the application and hot-swapping code
Usually, when debugging a server, I simply add commands to the necessary places in the code
console.log()and restart it. But sometimes, in especially difficult cases, it happens that it would be extremely useful to look at what is happening in a running server, rather than rebooting it. It is possible that not only “look” inside the server, but also change something in it in order to look at how this will affect the problem. In the console, you can use the Node.js command
require. This means that with its help you can connect any server modules and work with them in the console. Suppose we need to work with a module
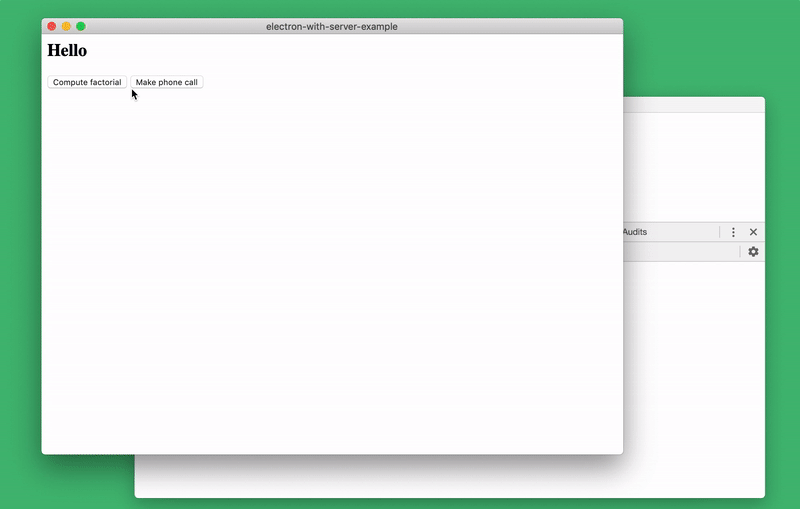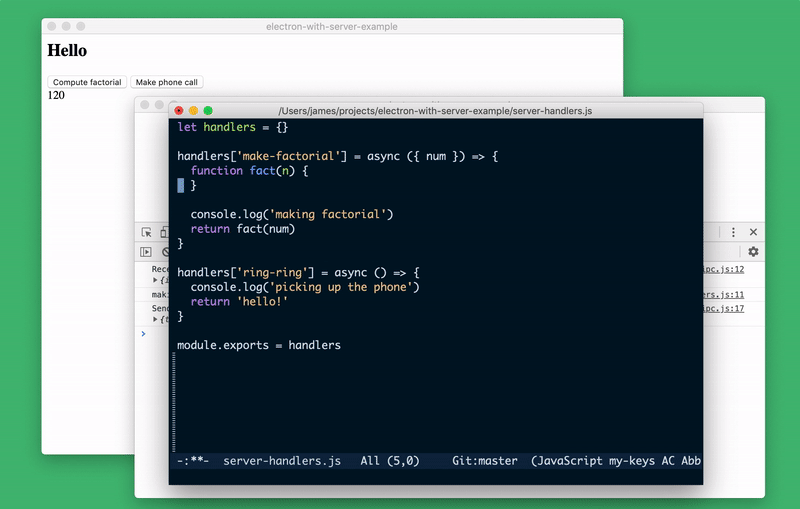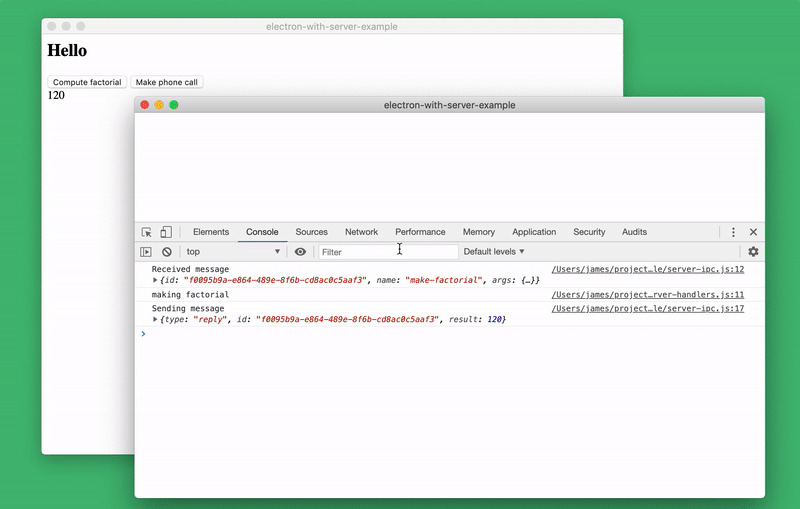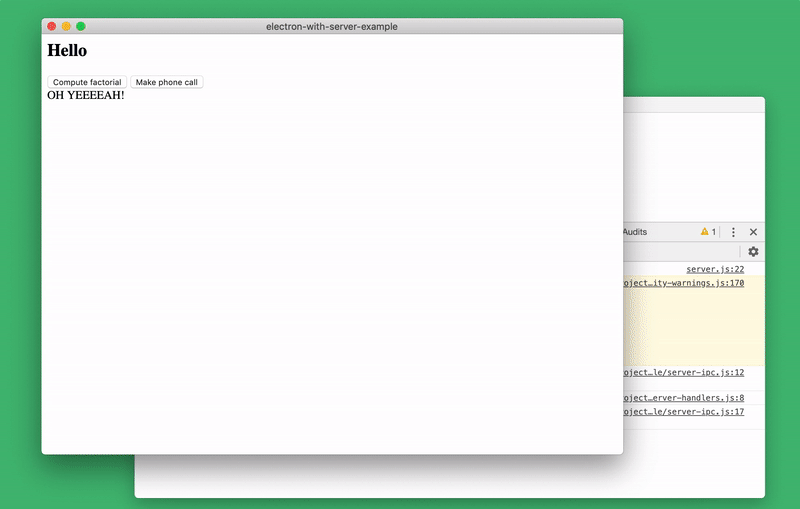
server-handler.js. To do this, just run the command in the console let handlers = require('./server-handlers'). Let's create a system to store server status. In our case, it will be a list of all data passed to the function
make-factorial (the server state of the real application will be much more complicated):handlers._history = []
handlers['make-factorial'] = async ({ num }) => {
handlers._history.push(num)
}You can examine the status of the server from the console by connecting the appropriate module and looking at
handlers._history. If desired, during the execution of the program, we can even completely replace the implementation make-factorial!Server Status Research
Summary
Take a look at the electron-with-server-example repository in order to read about the details of the project implementation and see the code of the server side of the Electron application.
If you use Visual Studio Code, then you may be used to a high-quality integration of developer tools with the Node.js server. With this approach, you can start the server yourself, separately from the Electron application. After that, you can tell Electron that you need to connect to the process owned by VS Code. However, I prefer to use existing Electron development tools.
This means that the programmer has the opportunity to use any third-party code editing tools and at the same time have full access to all browser developer tools.
Over the past few years, I have been developing the Actual application and constantly use what I just talked about. And I want to say that I really like all this. Perhaps the work on the Node.js part of this application has become the source of the most pleasant programming experience I have ever experienced.
In addition, it’s very important that the principles described above help us develop truly local applications. We already have all the technologies necessary for this. The main thing is to use them correctly.
Dear readers! How do you feel about Electron based apps?