Not another programming language. Part 1: Domain Logic
- Tutorial

Recently, a huge number of new programming languages have appeared on the market: Go, Swift, Rust, Dart, Julia, Kotlin, Hack, Bosque - and this is only one of those that are heard.
The value of what these languages bring to the world of programming is hard to overestimate, but as Y Combinator noted right last year when speaking about development tools:
Frameworks are getting better, languages are a little smarter, but basically we do the same.This article will talk about a language built on an approach that is fundamentally different from the approaches used in all existing languages, including those listed above. By and large, this language can be considered a general-purpose language, although some of its capabilities and the current implementation of the platform built on it, nevertheless, probably limit its application to a slightly narrower area - the development of information systems.
I’ll make a reservation right away, it’s not about an idea, a prototype, or even MVP, but about a full-fledged production-ready language with all the necessary infrastructure language - from the development environment (with a debugger) to the automatic support of several versions of the language (with automatic merge bugfixes between them , release-note, etc.). In addition, using this language, several dozen projects of complexity of the ERP level have already been implemented, with hundreds of simultaneous users, terabyte databases, “yesterday's deadlines”, limited budgets and developers without experience in IT. And all this at the same time. Well, of course, it should be noted that now is not the year 2000, and all these projects were implemented on top of existing systems (which wasn’t there), which means that at first it was necessary to do “as it was” gradually, without stopping the business, and then, also gradually make "as it should be." In general, this is how to sell the first electric cars not to wealthy hipsters in California, but to low-cost taxi services somewhere in Omsk.
A platform built in this language is released under the LGPL v3 license. Honestly, I didn’t want to write it right in the introduction, since this is far from the most important advantage of it, but, talking to people working in one of its main potential markets - ERP platforms, I noticed one feature: all these people without exception say that even if you do the same that is already on the market, but for free, then it will already be very cool. So leave it here.
Bit of theory
Let's start with the theory to highlight the difference in the fundamental approaches used in this and other modern languages.
A small disclaimer, further considerations to some extent are an attempt to pull an owl on a globe, but with a fundamental theory in programming, in principle, let's say bluntly, not really, so you have to use what you have.
One of the very first and main tasks solved by programming is the task of calculating the values of functions. From the point of view of computational theory, there are two fundamentally different approaches to solving this problem.
The first such approach is various machines (the most famous of which is a Turing machine) - a model that consists of the current state (memory) and a machine (processor), which at each step changes this current state in one way or another. This approach is also called Von Neumann architecture, and it is he who underlies all modern computers and 99 percent of existing languages.
The second approach is based on the use of operators; it is used by so-called partially recursive functions(hereinafter CRF). Moreover, the most important difference of this approach is not in the use of operators as such (operators, for example, are also in structural programming using the first approach), but in the possibility of iterating over all values of the function (see the operator of minimizing the argument) and in the absence of state in calculation process.
Like the Turing machine, partially recursive functions are Turing complete, that is, they can be used to specify any possible calculation. Here, we immediately clarify that both the Turing machine and the CRF are only minimal bases, and then we will talk about them just as approaches, that is, a model with a processor memory and a model with operators without using variables and the possibility of iteration over all values functions respectively.
The CRF as an approach has three main advantages:
- It is much better optimized. This applies both directly to the optimization of the process of calculating the value, and the possibility of parallelism of such a calculation. In the first approach, the aftereffect, on the contrary, introduces a very great complexity into these processes.
- It is much better incremented, that is, for a constructed function, it can be much more efficient to determine how its values will change when the values of the functions that this built function uses change. Strictly speaking, this advantage is a special case of the first, but it is precisely this that gives a huge number of possibilities, which basically cannot be in the first approach, therefore it is highlighted as a separate item.
- It is much easier to understand. That is, roughly speaking, the description of the function of calculating the sum of one indicator in the context of two other indicators is much easier to understand than if the same is described in terms of the first approach. However, in algorithmically complex problems the situation is diametrically opposite, but it is worth noting that algorithmically complex problems in the vast majority of areas are good if 5%. In general, to summarize a little, the CRF is mathematics, and Turing machines are computer science. Accordingly, mathematics is studied almost in kindergarten, and computer science is optional and from high school. So-so comparison, of course, but still gives some kind of metric in this matter.
Turing machines have at least two advantages:
- Already mentioned best applicability in algorithmically complex problems
- All modern computers are built on this approach.
Plus, in this comparison we are talking only about data computation tasks; in problems of changing data, Turing machines can’t get along anyway.
Having read to this place, any attentive reader will ask a reasonable question: “If the CRF approach is so good, why is it not used in any common modern language?”. So, in fact, this is not so, it is used, moreover, in the language that is used in the vast majority of existing information systems. As you might guess, this language is SQL. Here, of course, the same attentive reader will reasonably object that SQL is the language of relational algebra (that is, working with tables, not functions), and it will be right. Formally. In fact, we can recall that the tables in the DBMS are usually in the third normal form, that is, they have key columns, which means that any remaining column of this table can be considered as a function of its key columns. Not obvious, frankly. And then why SQL has not grown from a relational algebra language into a full-fledged programming language (that is, working with functions) is a big question. In my opinion, there are many reasons for this, the most important of which is “a Russian (actually any) person cannot work on an empty stomach, but does not want to work on a well-fed one,” in the sense that, as practice shows, the work necessary for this it’s truly titanic and carries too many risks for small companies, and for large companies - firstly, everything is fine, and secondly, it is impossible to force this work with money - quality is more important than quantity. Actually, the most obvious illustration of what happens when people try to solve a problem the most important of which is “a Russian (in fact, any) person cannot work on an empty stomach, but doesn’t want a full one,” in the sense that, as practice shows, the work required for this is truly titanic and carries too many risks for small companies, and for large companies - firstly, everything is fine, and secondly, it’s impossible to force money to do this work - here quality is more important than quantity. Actually, the most obvious illustration of what happens when people try to solve a problem the most important of which is “a Russian (in fact, any) person cannot work on an empty stomach, but doesn’t want a full one,” in the sense that, as practice shows, the work required for this is truly titanic and carries too many risks for small companies, and for large companies - firstly, everything is fine, and secondly, it’s impossible to force money to do this work - here quality is more important than quantity. Actually, the most obvious illustration of what happens when people try to solve a problem it’s impossible to force money to do this — quality is more important than quantity. Actually, the most obvious illustration of what happens when people try to solve a problem it’s impossible to force money to do this — quality is more important than quantity. Actually, the most obvious illustration of what happens when people try to solve a problemthe quantity, not the quality , is Oracle, which even managed to implement the most basic application of incrementality - updated materialized representations - so that this mechanism has a number of restrictions that are several pages in size (in fairness, Microsoft is still worse ). However, this is a separate story, perhaps there will be a separate article about it.
At the same time, it is not that SQL is bad. Not. At its level of abstraction, it performs its functions perfectly, and the current platform implementation uses it a little less than fully (in any case, much more than all other platforms). Another thing is that immediately after its birth, SQL actually stopped in development and did not become what it could become, namely, the language that will be discussed now.
But enough theory, it's time to go directly to the language.
So, we meet :

Specifically, this article will be the first part of three (since there is still too much material, even for two articles), and it will only talk about the logical model - that is, only about what is directly related to the functionality of the system and has nothing to do with processes development and implementation (performance optimization). Moreover, we will talk only about one of the two parts of the logical model - the logic of the subject area. This logic determines what information the system stores and what you can do with this information (when developing business applications, it is also often called business logic).
Graphically, all concepts of domain logic in lsFusion can be represented by the following picture:
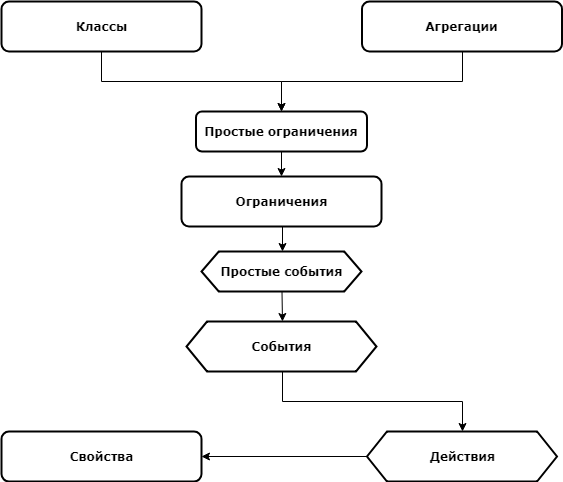
The arrows in this picture indicate the directions of use by the concepts of each other, thus, the concepts form a kind of stack, and, accordingly, it is in the order of this stack that I will talk about them.
Table of contents
- Properties
- Actions
- Loop (FOR), Recursive Loop (WHILE)
- Call (EXEC), Sequence ({...}), Branching (CASE, IF), Interrupt (BREAK), Exit (RETURN)
- Property Change (CHANGE)
- Adding Objects (NEW)
- Deleting Objects (DELETE)
- Change Sessions
- Creating Sessions (NEWSESSION, NESTEDSESSION)
- Apply Changes (APPLY), Cancel Changes (CANCEL)
- Change Operators (PREV, CHANGED, SET, DROPPED)
- Events
- Limitations
- Classes
- Aggregations
Properties
A property is an abstraction that takes one or more objects as parameters and returns some object as a result. The property has no aftereffect, and, in fact, is a pure function, however, unlike the latter, it can not only calculate values, but also store them. Actually, the name “property” itself is borrowed from other modern programming languages, where it is used for approximately the same purposes, but it is nailed to encapsulation and, therefore, is supported only for functions with one parameter. Well, the fact that this very word “property” is shorter than “pure function”, plus has no unnecessary associations, played in favor of using this very term.
Properties are set recursively using a predefined set of operators. There are a lot of these operators, so we will consider only the main ones (these operators cover 95% of any average-static project).
Primary Property (DATA)
The primary property is a property whose value is stored in the database and can change as a result of the corresponding action (about it a little later). By default, the value of each such property for any set of parameters is equal to a special NULL value.
quantity = DATA INTEGER (Item); |
In fact, this operator generalizes fields and collections in modern languages. So:
class X {
Y y;
Map f;
Map> m;
List n;
LinkedHashSet l; // упорядоченное множество
static Set s;
}
Equivalent to:
y = DATA Y (X); |
Composition (JOIN), Constant, Arithmetic (+, -, /, *), Logical (AND, OR), String (+, CONCAT), Comparison (>, <, =), Choice (CASE, IF), Belonging to the class (IS)
f(a) = IF g(h(a)) > 5 AND a IS X THEN ‘AB’ + ‘CD’ ELSE x(5); |
- In logical operators and selection operators, as conditions, one can use not only properties with values of logical types, but any properties in general. Accordingly, the condition in this case is the certainty of the property value (that is, the difference from NULL). Actually, the logical type in lsFusion itself is, in fact, a constant, that is, its set of values consists of exactly one element - the TRUE value (the FALSE role is NULL), no roof-bearing 3-states.
- For arithmetic and string operators, there are special forms of working with NULL: (+), (-), CONCAT with a separator. When using these forms:
- in arithmetic operators: NULL at the input is interpreted as 0, and at the output, on the contrary, 0 is replaced by NULL (i.e. 5 (+) NULL = 5, 5 (-) 5 = NULL, but 5 + NULL = NULL and 5 - 5 = 0).
- in string operators: NULL at the input is ignored and accordingly the separator is not added (i.e. CONCAT '', 'John', 'Smith' = 'John Smith', and CONCAT '', 'John', NULL = 'John', but ' John '+' '+ NULL = NULL).
- in arithmetic operators: NULL at the input is interpreted as 0, and at the output, on the contrary, 0 is replaced by NULL (i.e. 5 (+) NULL = 5, 5 (-) 5 = NULL, but 5 + NULL = NULL and 5 - 5 = 0).
- For the simple choice operator (IF), there is (and is very often used) a postfix form: f (a) IF g (a), which returns f (a) if g (a) is not NULL, and NULL otherwise.
Grouping (GROUP)
Grouping is the most commonly used set operator. This operator takes a property and for all its values calculates some aggregate function (for example, the sum) in the context of the values of other properties.
In terms of syntax, there are two forms of this operator:
- Functional: This form allows closure to the lexical context, that is, inside the operator you can use the parameters of the external context (in the examples above, the parameters i and sk). The peculiarity of the functional form is that it can be used in expressions, that is, to write something like:
sum(Invoice i) = GROUP SUM sum(InvoiceDetail id) IF invoice(id) = i;
currentBalance(Sku sk) = GROUP SUM currentBalance(sk, Stock st);x() = (GROUP SUM f(a)) + 5; - SQL style:Unlike the functional, this form of the operator can be used only when declaring properties (like, say, the operator of creating a primary property)
sum = GROUP SUM sum(InvoiceDetail id) BY invoice(id);
currentBalance = GROUP SUM currentBalance(Sku sk, Stock st) BY sk;
From the point of view of conciseness of the code, it makes sense to use the first form when the grouping is by parameters (example with the remainder), the second - by properties (example with an invoice). Although, by and large, this is still a matter of taste, to whom it is more familiar (for people who worked more with functional programming, the first form would be more familiar, for those working with SQL - the second). By the way, if you wish, you can use a mixture of these forms (that is, when you can access the upper parameters and use the BY option), something like:
// BY отображается только на неиспользованные параметры, то есть s |
As an aggregating function, in addition to the amount, the following are also supported:
- High / low
- String concatenation in the given order
- The last value in the given order.
Partitioning / Organizing (PARTITION ... ORDER)
The grouping operator described above splits all objects (or rather, sets of objects) in the system into groups, after which it calculates a certain value for each group. However, in some cases, the value needs to be calculated not for the group itself, but for directly grouped sets of objects (but to do this in the context of the group into which this set belongs). To perform this kind of computation, a special splitting / ordering operator exists in the language.
place(Team t) = PARTITION SUM 1 ORDER DESC points(t) BY conference(t); |
The analogue of this operator in SQL (and the means by which it is implemented) are window functions (OVER PARTITION BY ... ORDER BY).
Recursion (RECURSION)
Recursion is probably the most complex operator for working with sets. It is needed to implement calculations with an unknown number of iterations in advance, in particular, to work with graphs.
For the recursion operator, you must specify the initial property and the step property. Accordingly, the algorithm for calculating this operator is as follows (hereinafter an almost verbatim quote from the documentation):
- First, an intermediate property (result) is constructed recursively with an additional first parameter (operation number) as follows:
- result (0, o1, o2, ..., oN) = initial (o1, ..., oN), where initial is the initial property
- result (i + 1, o1, o2, ..., oN) = step (o1, ..., oN, $ o1, $ o2, ..., $ oN) IF result (i, $ o1, $ o2 , ..., $ oN), where step is the property of the step.
- result (0, o1, o2, ..., oN) = initial (o1, ..., oN), where initial is the initial property
- Then, for all values of the obtained property, the sum is calculated in the context of all its parameters, with the exception of the operation number (that is, o1, o2, ..., oN). Theoretically, instead of a sum, there can be any aggregating function, but in the current implementation only the sum is supported.
Not the most obvious definition, frankly, therefore, the essence of this operator is probably easier to understand from the examples:
// итерация по integer от from до to (это свойство по умолчанию входит в модуль System) |
By the way, it is funny that although the definition of this operator is very similar to the definition of the primitive recursion operator in the ChRF, in the ChRF primitive recursion can be applied only if the number of iterations is known in advance, and vice versa in lsFusion.
Recursive CTEs are an analogue of the recursion operator in SQL, however, the platform rarely uses them when executed, since there are a very large number of restrictions. In particular, in Postgres it is impossible to use GROUP BY for a step, which, in essence, means that when you run through the graph for vertices you cannot use marks, which means that the number of iterations grows exponentially. Therefore, in practice, the platform, as a rule, uses table functions with WHILE inside.
This concludes the description of property creation operators. These are not all operators, but the rest are either much less commonly used or belong to other levels of language abstraction and will be considered there.
Actions
An action is an abstraction that takes some objects as parameters and, using them in one way or another, changes the state of the system (both the one in which this action is performed and the state of any other external system). Here, of course, one could probably use the term “procedure”, but, firstly, it has already become obsolete quite a while, and secondly, the word itself is more cumbersome and incomprehensible than “action”.
In general, properties and actions are a kind of Yin and Yang programming in lsFusion. Properties use the HRF approach, actions use the Turing machine approach. Properties are processed on the database server, actions are processed on the application server (there really is a lot of magic here when the platform moves these processes between servers, so it’s more about where these abstractions are processed by default). Properties are responsible for storing and computing data; actions are responsible for changing. Etc.
It is worth noting that the division into properties and actions is implicit in other languages. So arithmetic / logical operators, variables, fields, and in general everything that can be used in expressions can be attributed to the logic of properties, everything else to the logic of actions. But if in other languages this ratio is good if 3 by 97, then in lsFusion in an average project it is at least 60 by 40.
Actions, like properties, are set recursively using a predefined set of operators. These operators, again, are quite numerous (in fact, they are several times larger than the operators for creating properties), therefore, we also consider only the main ones.
Let's start with the operators responsible for the execution order:
Loop (FOR), Recursive Loop (WHILE)
Despite the same name, the loop in lsFusion differs significantly from the same concept in other programming languages, and is built on the iteration operation mentioned above for all sets of objects for which the value of the specified property is not NULL (we will call this property a loop condition).
FOR selected(Team team) DO |
showAllDetails(Invoice i) { |
A recursive loop (WHILE) differs from a regular loop only in that:
- continues execution until there is at least one non-NULL value for the loop condition (in this sense, it is very similar to the recursion operator in properties)
- not required to enter a new parameter
Call (EXEC), Sequence ({...}), Branching (CASE, IF), Interrupt (BREAK), Exit (RETURN)
f(a) { |
Property Change (CHANGE)
This operator allows you to change the values of primary properties. At the same time, he can do this, not only for one set of values of objects, but also for all sets of objects for which the value of the specified property is not NULL. For instance:
// изменить скидку для выбранных товаров для клиента |
setDiscount(Customer c) { |
Adding Objects (NEW)
This operator adds an object of a given class (about classes now very soon, although there is nothing special, in any case, in their way of specifying, no). As well as for a property change operator, you can add not one, but many objects at once for a given condition.
The syntax of the add object operator is similar to the syntax of the property change operator:
newSku () { |
FOR iterate(i, 1, 3) NEW s=Sku DO { |
NEW s=Sku DO { |
Deleting Objects (DELETE)
Here, everything is quite simple and in many ways similar to the two upper operators - the delete operator removes one or many objects for a given condition:
DELETE Sku s WHERE name(s) = 'MySku'; |
Before moving on to the next operators, it is necessary to talk about another important concept used in the logic of actions.
Change Sessions
As mentioned earlier, an action as a result of its execution can change the state of the system in which it is executed. It is not always desirable to record these changes directly to the database, both from the point of view of integrity and from the point of view of ergonomics of the system. Therefore, the platform has the ability to accumulate these changes locally in the so-called change sessions.
Changes in a session can be changes to primary properties, as well as changes to object classes. The former are implemented using the property change operator described above, and the latter are implemented using the add / delete operators of objects.
Each time an action is performed, depending on the execution context, the current session is determined for it. For example, if an action is called as a handler for some event of the form (the most common case), then the session of this form will be the current session for it.
If an action refers to some property during the execution, then its value is calculated taking into account the changes made in the current session of this action. For example:
LOCAL f = INTEGER (INTEGER, INTEGER); |
Creating Sessions (NEWSESSION, NESTEDSESSION)
Sessions are created automatically at the highest operations on the stack (for example, calling an action from the navigator, through an http request, etc.). However, in the process of performing one action, it is often necessary to perform another action in a new session other than the current one. Usually, such a need arises if the context of the execution of the action is unknown, and by applying the changes to the current session “blindly”, one can accidentally apply “alien” changes (that is, those that were not to be applied). To implement this feature, the platform has a special NEWSESSION operator, when wrapped in which the action will be performed in a new session (in this case, at the end of this action, the session will automatically close). For instance:
run() { |
run(Store s) { |
g = DATA LOCAL NESTED INTEGER (); |
- all changes of the current session are automatically copied to the created session, that is, roughly speaking, a nested session <- the current session
- when canceling changes in a nested session, it is not cleared, but returns to the state at the time of creation: nested session <- current session
- when applying changes in a nested session, all its changes are copied back to the current session: current session <- nested session.
The mechanism of nested sessions is very convenient when you need to organize the input of a large amount of information (possibly consisting of several stages), but you must either apply all the changes at the end at the same time, or not apply anything at all. So, for example, if you need to enter some kind of large document, during the input of which, in turn, you must be able to enter the product if it is not there, but in order to:
- the user could cancel the entry of this product and continue entering the document
- if the user cancels the entry of the entire document, the entry of this product must also be canceled
Apply Changes (APPLY), Cancel Changes (CANCEL)
Application and cancellation of changes are operations for which sessions were actually created. In the description of the sessions, they have already been mentioned, and their semantics follows from their name. One thing worth noting:
- When applying and reverting changes, all changes to the local primary properties are deleted. Sometimes this behavior is undesirable, therefore, as for creating sessions, the NESTED option is supported for these statements (with similar behavior).
- При применении изменений есть возможность указать дополнительное действие, которое будет выполнено сразу после начала транзакции. Главное отличие выполнения этого дополнительного действия внутри транзакции от его выполнения сразу перед применением изменения заключается в том, что если применение по какой-либо причине будет отменено, то и изменения, сделанные в этом дополнительном действии, также будут отменены. Более того, если причиной отмены применения был конфликт записи (update conflict), а значит, применение будет автоматически выполнено еще раз, то в этом случае указанное дополнительное действие также будет выполнено еще раз. К примеру, такое поведение можно использовать для реализации долгосрочной пессимистичной блокировки:
// -------------------------- Object locks ---------------------------- // |
The next set of operators are the operators of creating properties, not actions, but they are by their nature closer to the logic of changes, not calculations, therefore they are described here (and not in properties).
Change Operators (PREV, CHANGED, SET, DROPPED)
For the session, a set of operators for working with changes is supported: obtaining the previous value in the session (PREV), determining whether the property value in the session (CHANGED) has changed, whether it has changed from NULL to a non-NULL value (SET), etc. In general, these operators are mainly used in the logic of events (about them a little later), but if necessary, they can be used inside actions called from anywhere, for example:
f = DATA INTEGER (INTEGER); |
Events
Actions answer the question “What to do?”, But do not answer the question “When to do this?”. To determine the moments when you need to perform certain actions, events exist in the platform.
I’ll make a reservation right away, we will go on about the events of the subject area, in addition to them, there are also form events in the presentation logic. These are two completely unrelated mechanisms, and we will dwell on the events of the form in an article on presentation logic. But in the future, events without specifying their type will be considered events of the subject area.
Domain events are of two types:
- Synchronous - occur immediately after data change.
- Asynchronous - occur at arbitrary points in time as the server manages to complete all specified processing and / or after a certain period of time.
In turn, from the point of view of the scope of changes, events can be divided into:
- Local - occur locally for each session of changes.
- Global - occur globally for the entire database.
Thus, events can be synchronous local, synchronous global, asynchronous local, and asynchronous global.
Advantages of synchronous events:
- If necessary, you can cancel changes in the process if, for example, these changes do not satisfy the necessary conditions.
- They guarantee greater integrity, since after the end of the recording of changes, the user is guaranteed to work with the updated data.
Benefits of asynchronous events:
- You can immediately release the user, and perform the processing "in the background." This improves the ergonomics of the system, however, it is possible only when updating the data is not critical for the user's further work (for global events, for example, within the next 5-10 minutes, until the server has time to complete the next processing cycle).
- Processing is grouped for a large number of changes, including those made by various users (in the case of global events), and, accordingly, are performed fewer times, thereby improving the overall system performance.
Benefits of local events:
- The user sees the results of event processing immediately, and not just after he has saved them to a common database.
Benefits of global events:
- They provide better performance and integrity, both due to the fact that processing is performed only after the changes are saved to a common database (that is, significantly less often), and due to the use of numerous DBMS capabilities related to working with transactions.
So far, only synchronous global and asynchronous local ones are supported in the platform (as the most commonly used, support for other types of events is also planned in the future), so we will simply talk about global and local events in the future.
ON { // по умолчанию глобальное, то есть будет выполняться при каждом APPLY |
// отправить email, когда остаток в результате применения изменений сессии стал меньше нуля |
In fact, simple events are nothing more than syntactic sugar. So, the first event is equivalent to:
ON { |
Triggers are some analogue of simple events in SQL (or rather its extensions). However, triggers are limited to one table, they work entirely for writing, they are performed for each table separately (that is, they cannot be executed by one query), and there are many other things, and they are not used by the platform for implementing simple events.
It is important to note that inside the processing of events of the subject area, the behavior of some operators changes:
- Discard changes - cancels the application of changes, and does not clear the session (this operator can only be used inside synchronous events)
- Operators of work with changes - return the value at the time the processing of the previous event is completed, and not the current value in the database. However, for global events, these values coincide, plus using a special option you can “return” these operators to standard mode and return the current value in the database.
Limitations
Platform restrictions determine which values may have primary properties and which may not. In general, a constraint is defined as a property whose value should always be NULL:
// остаток не меньше 0 |
As well as for events, there is a special subspecies for restrictions - simple restrictions (syntactic sugar for the most common cases of restrictions), but as practice has shown, in addition to limiting that a given property must be set (everything is more or less obvious here), simple restrictions are used very rarely, so we will not dwell on them in detail.
Classes
Well, here we come to the classes. Usually it is customary to start with them, but, strictly speaking, logically, classes are no more than one of the types of restrictions. For example:
f = DATA A (INTEGER); |
f = Object (INTEGER); |
In general, the concept of classes in lsFusion is not very different from that in OOP. True, unlike OOP, lsFusion has no encapsulation. Anyway, bye. But even if encapsulation in lsFusion appears, it is only in the form of syntactic sugar, something like:
CLASS A { |
CLASS Animal; |
Polymorphism
In the current version of lsFusion, polymorphism is explicit. To implement it, an abstract property or action is first declared for some, possibly abstract, class:
speed = ABSTRACT LONG (Transport); |
CLASS Breed; |
CLASS Thing; |
speed(Transport t) = CASE |
In the future, it is planned that, in addition to explicit polymorphism, the language will also support implicit polymorphism, that is:
speed(Horse h) = speed(breed(h)); |
Inline classes
Above we talked only about custom classes, that is, classes that developers create. At the same time, the platform also supports the so-called built-in (primitive) classes: numbers, strings, dates, and so on. There is nothing much special in comparison with other languages, they must, however, be taken into account that in the current implementation they cannot be mixed with each other or with user classes. That is, a property cannot return a non-NULL value at the same time for a certain number or an object, that is, you cannot do this:
f = DATA LONG (LONG); |
Static Objects
Static (or built-in) objects - objects that are created at server startup and which cannot be deleted. In addition, static objects can be accessed as constants directly in the language:
CLASS Direction 'Направление' { |
The analogs of static objects in modern programming languages are enum'y, respectively, usually static objects are used exactly for the same purpose.
Aggregations
The class mechanism (both in lsFusion and in other languages) has at least three limitations:
- Belonging to a class cannot be calculated (only set explicitly when adding and changing the class of an object).
- A class is defined for only one object (and not for a set of objects).
- It is not possible to inherit the same class several times.
To circumvent these restrictions, the platform has a mechanism of so-called aggregations.
Aggregation refers to the creation of a unique (aggregated) object corresponding to each non-NULL value of some aggregated property. For such an object, it is assumed that there are properties that map this object to each of the parameters of the aggregated property, and a property that, on the contrary, maps the parameters of the aggregated property to this object.
For instance:
// для каждого A создается объект класса B |
CLASS Shipment 'Поставка'; |
We’ll end with the logic of the domain, this is certainly not all, but even so, perhaps too much for one article. However, soon there will be at least two more articles describing the features of the language, one about the presentation logic, the second about the physical model, and there, unfortunately or fortunately, it will be difficult to manage with the phrases “everything is more or less standard here”, so as they say, do not go far from your screens.
Conclusion
Of course, in contrasting lsFusion with general-purpose languages, there is a certain share of cunning in the introduction. Yes, classes, aggregations, restrictions, events and other abstractions of the language, by and large, really do not belong to any specific subject area, and in one form or another exist, including in system programming (that is, for example, in the development conditional OS or DBMS). But implementing a virtual machine that supports the entire lsFusion specification (even without ACID), which will not be as heavy as modern SQL servers, will be very difficult. As a result, getting rid of the DSL lsFusion label is unlikely to succeed, which means that it is hardly necessary to rely on the favor of most system programmers - the main consumers of general-purpose languages. Strictly speaking, and SQL most of them do not like, there is too much magic under the hood, and in lsFusion this magic is even more. Of course, we will try to maximize this effect - a free license, github sources (both the platform itself and its entire infrastructure), the maximum use of existing ecosystems (IDE, reporting, VCS, automatic assemblies), slack and telegram channels communication, the presence in public repositories (linux and maven, again with the source), and, in principle, general openness in interaction with developers, but we will be realistic if the average system programmer will simply not like lsFusion less than SQL, ABAP and 1C is already success.
On the other hand, it is clear that in the near future the main market for lsFusion will be not system but application programming (the already mentioned development of IP), and now there are five main players: ERP platforms, SQL servers with procedural extensions, ORM frameworks , RAD frameworks, and just spreadsheets. The first, fourth and fifth types of platforms have a user interface in the kit; in the second and third, third-party technologies are used for this.
Each of these five types of platforms has its own niche, where they mainly live:
- SQL servers with procedural extensions — business applications with relatively complex logic and large amounts of data — are usually retail and banks.
- ERP-platforms - other business applications with complex logic - wholesale, manufacturing, finance, etc.
- ORM-фреймворки – веб-приложения (сервисы, порталы), ну и очень высоконагруженные приложения с относительно несложной логикой.
- RAD – узкоспециализированные низконагруженные бизнес-приложения с простой логикой, там где, как правило, сильно ограничен IT-бюджет.
- Электронные таблицы – используются там же, где и RAD, правда, из-за низкого порога вхождения их можно встретить везде, где только можно, начиная от крупных корпораций и заканчивая полной автоматизацией малого бизнеса чисто на Excel (да, такое тоже встречается, и даже не знаю, какие ощущения это больше вызывает – восторг или страх).
In my purely subjective opinion, in the global perspective, lsFusion can completely replace the ERP, RAD and SQL platforms that lsFusion surpasses in all non-functional requirements (and in many of them it exceeds by an order of magnitude). True, with regard to SQL, it is more likely not about a replacement, but about an add-in, that is, just like, say, Fortran and C replaced the assembler (you can still write in assembler, but it is not clear why). With ORM frameworks, it will obviously be hard to compete in extreme flexibility and scalability, and with spreadsheets with entry thresholds in very simple tasks and in working with unstructured data. Although, nevertheless, it is possible that they will be able to win back some part of the market from them.
Well, in the medium term, the focus will mainly be on SMEs (which have limited human resources and IT budgets, but have great needs for flexibility and ergonomics of the solutions used), as well as non-standard tasks (where there are few ready-made solutions and their customization according to surpasses these solutions themselves). That is, to occupy the niche that 1C currently occupies in Russia, but only do it on a global scale.
This all, of course, sounds too ambitious, but after the path that has already been completed to just get all this technology to work (and it took almost 12 years), this task no longer seems so impossible.
UPD: The second part of the article can be found here .