The book Kafka Streams in action. Real-time applications and microservices »
 Hi, habrozhiteli! This book is suitable for any developer who wants to understand streaming processing. Understanding distributed programming will help you better understand Kafka and Kafka Streams. It would be nice to know the Kafka framework itself, but this is not necessary: I will tell you everything you need. Thanks to this book, experienced Kafka developers, like novices, will learn how to create interesting streaming applications using the Kafka Streams library. Intermediate and high level Java developers already familiar with concepts such as serialization will learn how to apply their skills to create Kafka Streams applications. The source code of the book is written in Java 8 and essentially uses the syntax of lambda expressions of Java 8, so the ability to work with lambda functions (even in another programming language) is useful to you.
Hi, habrozhiteli! This book is suitable for any developer who wants to understand streaming processing. Understanding distributed programming will help you better understand Kafka and Kafka Streams. It would be nice to know the Kafka framework itself, but this is not necessary: I will tell you everything you need. Thanks to this book, experienced Kafka developers, like novices, will learn how to create interesting streaming applications using the Kafka Streams library. Intermediate and high level Java developers already familiar with concepts such as serialization will learn how to apply their skills to create Kafka Streams applications. The source code of the book is written in Java 8 and essentially uses the syntax of lambda expressions of Java 8, so the ability to work with lambda functions (even in another programming language) is useful to you.Excerpt. 5.3. Aggregation and window operations
In this section, we move on to the most promising parts of Kafka Streams. So far we have covered the following aspects of Kafka Streams:
- creating a processing topology;
- use of state in streaming applications;
- making data stream connections;
- differences between event streams (KStream) and update streams (KTable).
In the following examples, we will put all these elements together. In addition, you will be introduced to window operations - another great feature of streaming applications. Our first example will be simple aggregation.
5.3.1. Aggregation of stock sales by industry
Aggregation and grouping are vital tools for working with streaming data. Examining individual records as they become available is often not enough. To extract additional information from the data, their grouping and combination are necessary.
In this example, you have to try on the suit of an intraday trader who needs to track the volume of sales of shares of companies in several industries. In particular, you are interested in the five companies with the largest share sales in each industry.
For such aggregation, you will need several of the following steps to translate the data into the desired form (in general terms).
- Create a topic-based source that publishes raw stock trading information. We will have to map an object of type StockTransaction to an object of type ShareVolume. The fact is that the StockTransaction object contains sales metadata, and we only need data on the number of shares sold.
- Group ShareVolume data by stock symbols. After grouping by symbols, you can collapse this data to subtotals of stock sales. It is worth noting that the KStream.groupBy method returns an instance of type KGroupedStream. And you can get a KTable instance by calling the KGroupedStream.reduce method later.
What is the KGroupedStream Interface?
The KStream.groupBy and KStream.groupByKey methods return an instance of KGroupedStream. KGroupedStream is an intermediate representation of the event stream after grouping by key. It is not at all intended for working directly with it. Instead, KGroupedStream is used for aggregation operations, the result of which is always KTable. And since the result of aggregation operations is KTable and they use state storage, it is possible that not all updates as a result are sent further down the pipeline.
The KTable.groupBy method returns a similar KGroupedTable - an intermediate representation of the stream of updates regrouped by key.
Let's take a short break and look at fig. 5.9, which shows what we have achieved. This topology should already be familiar to you.
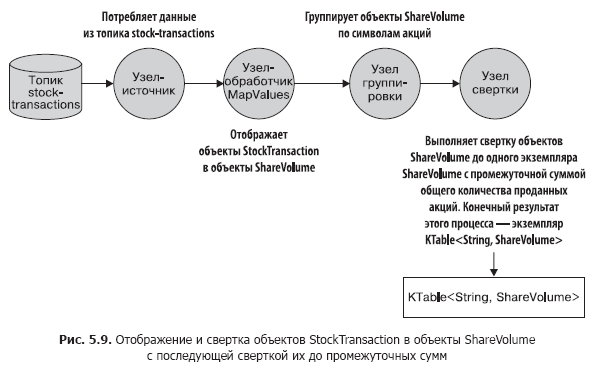
Now let's take a look at the code for this topology (it can be found in the src / main / java / bbejeck / chapter_5 / AggregationsAndReducingExample.java file) (Listing 5.2).

The given code differs in brevity and a large volume of actions performed in several lines. In the first parameter of the builder.stream method, you can notice something new for yourself: the value of the enumerated type AutoOffsetReset.EARLIEST (there is also LATEST), set using the Consumed.withOffsetResetPolicy method. Using this enumerated type, you can specify a strategy for resetting offsets for each of KStream or KTable; it has priority over the parameter for resetting offsets from the configuration.
GroupByKey and GroupBy
The KStream interface has two methods for grouping records: GroupByKey and GroupBy. Both return KGroupedTable, so you might have a legitimate question: what is the difference between them and when to use which one?
The GroupByKey method is used when the keys in KStream are already non-empty. And most importantly, the flag “requires re-partitioning” has never been set.
The GroupBy method assumes that you changed the keys for grouping, so the re-partitioning flag is set to true. Performing connections, aggregations, etc. after the GroupBy method will lead to automatic re-partitioning.
Summary: You should use GroupByKey rather than GroupBy whenever possible.
What the mapValues and groupBy methods do is understandable, so take a look at the sum () method (it can be found in the src / main / java / bbejeck / model / ShareVolume.java file) (Listing 5.3).

The ShareVolume.sum method returns the subtotal of the stock sales volume, and the result of the entire calculation chain is a KTable
Further, with the help of this KTable, we perform aggregation (by the number of shares sold) in order to obtain the five companies with the highest share sales in each industry. Our actions in this case will be similar to the actions during the first aggregation.
- Perform another groupBy operation to group individual ShareVolume objects by industry.
- Proceed to summarize ShareVolume objects. This time, the aggregation object is a priority queue of a fixed size. Only five companies with the largest number of shares sold are kept in such a fixed-size queue.
- Display the lines from the previous paragraph in a string value and return the five best-selling by the number of shares by industry.
- Write the results in string form to the topic.
In fig. 5.10 shows a graph of the topology of data movement. As you can see, the second round of processing is quite simple.
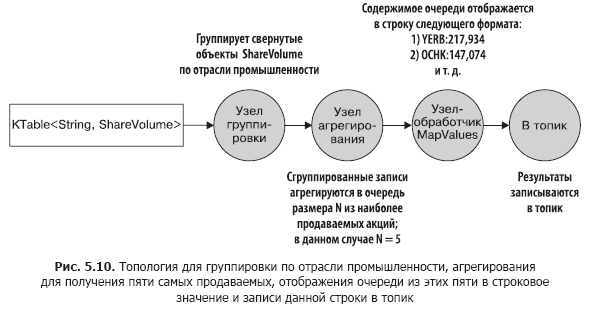
Now that you have clearly understood the structure of this second round of processing, you can refer to its source code (you will find it in the file src / main / java / bbejeck / chapter_5 / AggregationsAndReducingExample.java) (Listing 5.4).
There is a fixedQueue variable in this initializer. This is a custom object - an adapter for java.util.TreeSet, which is used to track N highest results in decreasing order of the number of shares sold.

You have already encountered calls to groupBy and mapValues, so we won’t stop on them (we call the KTable.toStream method, since the KTable.print method is deprecated). But you have not yet seen the KTable version of the aggregate () method, so we will spend some time discussing it.
As you remember, KTable is distinguished by the fact that records with the same keys are considered updates. KTable replaces the old record with the new one. Aggregation occurs in the same way: the last records with one key are aggregated. When a record arrives, it is added to an instance of the FixedSizePriorityQueue class using an adder (the second parameter in the call to the aggregate method), but if another record with the same key already exists, the old record is deleted using the subtracter (the third parameter in the call to the aggregate method).
This all means that our aggregator, FixedSizePriorityQueue, does not aggregate all values with one key, but stores the moving sum of the quantities N of the best-selling types of stocks. Each entry contains the total number of shares sold so far. KTable will give you information on which stocks of companies are currently being sold the most; rolling aggregation of each update is not required.
We learned to do two important things:
- group values in KTable by a key common to them;
- Perform useful operations such as convolution and aggregation on these grouped values.
The ability to perform these operations is important for understanding the meaning of the data moving through the Kafka Streams application and figuring out what information they carry.
We have also brought together some of the key concepts discussed earlier in this book. In Chapter 4, we talked about how important a fail-safe, local state is for a streaming application. The first example in this chapter showed why the local state is so important - it makes it possible to track what information you have already seen. Local access avoids network delays, making the application more productive and error resistant.
When performing any convolution or aggregation operation, you must specify the name of the state store. Convolution and aggregation operations return a KTable instance, and KTable uses a state store to replace old results with new ones. As you have seen, not all updates are sent further down the pipeline, and this is important, since aggregation operations are designed to obtain the final information. If the local state is not applied, KTable will send further all aggregation and convolution results.
Next, we look at the execution of operations such as aggregation, within a specific period of time - the so-called windowing operations.
5.3.2. Window Operations
In the previous section, we introduced “rolling” convolution and aggregation. The application performed a continuous convolution of stock sales with the subsequent aggregation of the five best-selling stocks.
Sometimes such continuous aggregation and convolution of results is necessary. And sometimes you need to perform operations only on a given period of time. For example, calculate how many stock exchange transactions have been made with shares of a particular company in the last 10 minutes. Or how many users clicked on a new banner ad in the last 15 minutes. An application can perform such operations multiple times, but with results related only to specified time intervals (time windows).
Counting Exchange Transactions by Buyer
In the following example, we will engage in tracking exchange transactions for several traders - either large organizations or smart single-handed financiers.
There are two possible reasons for this tracking. One of them is the need to know what market leaders are buying / selling. If these large players and sophisticated investors see opportunities for themselves, it makes sense to follow their strategy. The second reason is the desire to notice any possible signs of illegal transactions using inside information. To do this, you will need to analyze the correlation of large spikes in sales with important press releases.
Such tracking consists of such steps as:
- creating a stream for reading from the stock-transactions topic;
- grouping of incoming records by customer ID and stock symbol of the stock. A call to the groupBy method returns an instance of the KGroupedStream class;
- KGroupedStream.windowedBy returns a data stream bounded by a temporary window, which allows window aggregation. Depending on the type of window, either TimeWindowedKStream or SessionWindowedKStream is returned;
- Counting transactions for an aggregation operation. The window data stream determines whether a particular record is taken into account in this calculation;
- writing results to a topic or outputting them to the console during development.
The topology of this application is simple, but its visual picture does not hurt. Take a look at the pic. 5.11.
Further we will consider the functionality of window operations and the corresponding code.
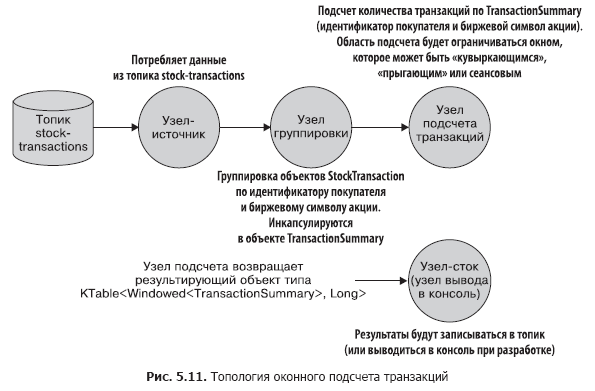
Window types
There are three types of windows in Kafka Streams:
- session
- Tumbling (tumbling);
- sliding / "jumping" (sliding / hopping).
Which one to choose depends on the business requirements. “Tumbling” and “jumping” windows are limited in time, while session restrictions are associated with user actions - the duration of the session (s) is determined solely by how actively the user behaves. The main thing is not to forget that all types of windows are based on date / time stamps of records, and not on system time.
Next, we implement our topology with each of the window types. The full code will be given only in the first example, nothing will change for other types of windows, except for the type of window operation.
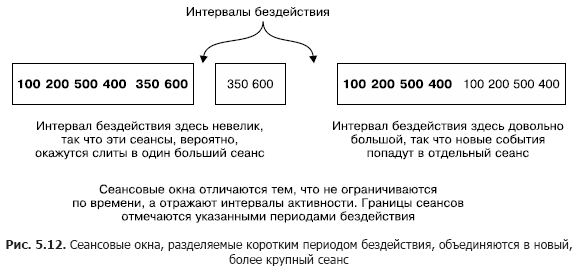
Session windows
Session windows are very different from all other window types. They are limited not so much by time as by the activity of the user (or the activity of the entity that you would like to track). Session windows are delimited by periods of inactivity.
Figure 5.12 illustrates the concept of session windows. A smaller session will merge with the session to its left. And the session on the right will be separate, since it follows a long period of inactivity. Session windows are based on user actions, but apply date / time stamps from records to determine which session the record belongs to.
Using Session Windows to Track Exchange Transactions
We will use session windows to capture information about exchange transactions. The implementation of the session windows is shown in Listing 5.5 (which can be found in src / main / java / bbejeck / chapter_5 / CountingWindowingAndKTableJoinExample.java).

You have already met most of the operations of this topology, so there is no need to consider them here again. But there are several new elements that we will discuss now.
For any groupBy operation, some kind of aggregation operation (aggregation, convolution, or counting) is usually performed. You can perform either cumulative aggregation with a cumulative total, or window aggregation, in which records are taken into account within a given time window.
The code in Listing 5.5 counts the number of transactions within session windows. In fig. 5.13 these actions are analyzed step by step.
By calling windowedBy (SessionWindows.with (twentySeconds) .until (fifteenMinutes)) we create a session window with an idle interval of 20 seconds and a retention interval of 15 minutes. An inactivity interval of 20 seconds means that the application will include any record that arrives within 20 seconds from the end or beginning of the current session in the current (active) session.
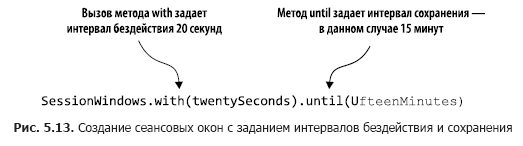
Next, we indicate which aggregation operation to perform in the session window — in this case, count. If the incoming record falls outside the inactivity interval (on either side of the date / time stamp), the application creates a new session. The save interval means maintaining the session for a certain time and allows late data that goes beyond the period of inactivity of the session, but can still be attached. In addition, the start and end of a new session resulting from the merge correspond to the earliest and latest date / time stamp.
Let's look at a few entries from the count method to see how the sessions work (Table 5.1).

Upon receipt of records, we look for already existing sessions with the same key, the end time is less than the current date / time stamp - the inactivity interval and the start time is more than the current date / time stamp + inactivity interval. With this in mind, four records from the table. 5.1 merge into a single session as follows.
1. Record 1 comes first, so the start time is equal to the end time and is 00:00:00.
2. Next comes record 2, and we look for sessions that end no earlier than 23:59:55 and begin no later than 00:00:35. Find record 1 and combine sessions 1 and 2. Take the start time of session 1 (earlier) and the end time of session 2 (later), so that our new session starts at 00:00:00 and ends at 00:00:15.
3. Record 3 arrives, we look for sessions between 00:00:30 and 00:01:10 and do not find any. Add a second session for the key 123-345-654, FFBE, starting and ending at 00:00:50.
4. Record 4 arrives, and we look for sessions between 23:59:45 and 00:00:25. This time there are both sessions - 1 and 2. All three sessions are combined into one, with a start time of 00:00:00 and an end time of 00:00:15.
From what is said in this section, it is worth remembering the following important nuances:
- Sessions are not fixed-size windows. The duration of a session is determined by activity within a given period of time;
- Date / time stamps in the data determine whether an event falls into an existing session or in a period of inactivity.
Further we will discuss the following type of windows - “somersault” windows.
Tumbling windows
“Tumbling” windows capture events that fall within a certain period of time. Imagine that you need to capture all the exchange transactions of a company every 20 seconds, so that you collect all the events for this period of time. At the end of the 20-second interval, the window “tumbles” and switches to a new 20-second observation interval. Figure 5.14 illustrates this situation.
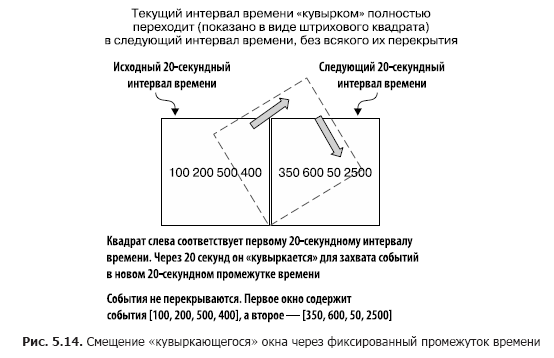
As you can see, all events received over the past 20 seconds are included in the window. At the end of this period of time, a new window is created.
Listing 5.6 shows the code that demonstrates using tumbling windows to capture exchange transactions every 20 seconds (you can find it in src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java).

Thanks to this small change to the call to the TimeWindows.of method, you can use the tumbling window. In this example, there is no call to the until () method, as a result of which the default save interval of 24 hours will be used.
Finally, it's time to move on to the last of the window options — hopping windows.
Sliding ("jumping") windows
Sliding / “hopping” windows are similar to “tumbling”, but with a slight difference. Sliding windows do not wait for the end of the time interval before creating a new window to handle recent events. They start new calculations after a wait interval shorter than the window duration.
To illustrate the differences between “somersaulting” and “jumping” windows, let us return to the example with the calculation of exchange transactions. Our goal, as before, is to count the number of transactions, but we would not want to wait all the time before updating the counter. Instead, we will update the counter at shorter intervals. For example, we will continue to count the number of transactions every 20 seconds, but to update the counter every 5 seconds, as shown in Fig. 5.15. At the same time, we have three result windows with overlapping data.
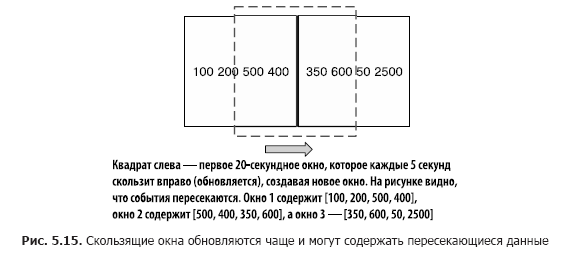
Listing 5.7 shows the code for specifying sliding windows (it can be found in src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java).

A tumbling window can be converted to a tumbling window by adding a call to the advanceBy () method. In the above example, the save interval is 15 minutes.
You saw in this section how to limit aggregation results to time windows. In particular, I would like you to remember the following three things from this section:
- the size of the session windows is not limited by the time interval, but by user activity;
- “Tumbling” windows give an idea of events within a given period of time;
- the duration of the “jumping” windows is fixed, but they are often updated and may contain overlapping entries in all windows.
Next, we will learn how to convert KTable back to KStream for connection.
5.3.3. Join KStream and KTable objects
In chapter 4, we discussed connecting two KStream objects. Now we have to learn how to connect KTable and KStream. This may be needed for the following simple reason. KStream is a stream of records, and KTable is a stream of record updates, but sometimes it may be necessary to add additional context to the stream of records using updates from KTable.
We take the data on the number of exchange transactions and combine them with exchange news on the relevant industries. Here's what you need to do to achieve this, given the existing code.
- Convert a KTable object with data on the number of exchange transactions to KStream, followed by replacing the key with a key that identifies the industry corresponding to this symbol of shares.
- Create a KTable object that reads data from a topic with exchange news. This new KTable will be categorized by industry.
- Combine news updates with information on the number of exchange transactions by industry.
Now let's see how to implement this action plan.
Convert KTable to KStream
To convert KTable to KStream, do the following.
- Call the KTable.toStream () method.
- Using the KStream.map method call, replace the key with the name of the industry, and then extract the TransactionSummary object from the Windowed instance.
We chain these operations in the following way (the code can be found in src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java) (Listing 5.8).

Since we perform the KStream.map operation, repeated partitioning for the returned KStream instance is performed automatically when it is used in the connection.
We completed the conversion process, then we need to create a KTable object for reading stock news.
Creating KTable for Stock Market News
Fortunately, a single line of code is enough to create a KTable object (this code can be found in src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java) (Listing 5.9).

It is worth noting that you do not need to specify any Serde objects, since the settings use string Serde. Also, by using the EARLIEST enumeration, the table is populated with entries at the very beginning.
Now we can move on to the final step - the union.
Link news updates to transaction numbers
Creating a connection is straightforward. We will use the left connection in case there is no exchange news for the relevant industry (the necessary code can be found in the file src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java) (Listing 5.10).

This leftJoin statement is quite simple. Unlike the connections in Chapter 4, the JoinWindow method is not used, because when you make a KStream-KTable, there is only one record for each key in KTable. Such a connection is not limited in time: the record is either in KTable or absent. The main conclusion: with the help of KTable objects, you can enrich KStream with less frequently updated reference data.
Now we’ll look at a more efficient way to enrich events from KStream.
5.3.4. GlobalKTable Objects
As you understand, there is a need to enrich the flow of events or add context to them. In chapter 4, you saw the connections of two KStream objects, and in the previous section, the connection of KStream and KTable. In all these cases, repeated partitioning of the data stream is necessary when mapping keys to a new type or value. Sometimes re-partitioning is done explicitly, and sometimes Kafka Streams does it automatically. Re-partitioning is necessary because the keys have changed and the records must be in new sections, otherwise the connection will be impossible (this was discussed in Chapter 4, in the section “Re-partitioning data” in Section 4.2.4).
Re-partitioning comes at a price
Repeated partitioning requires costs — additional resources for creating intermediate topics, storing duplicate data in another topic; it also means increased latency due to writing and reading from this topic. In addition, if you need to make a connection in more than one aspect or dimension, you need to organize the connections in a chain, display the records with the new keys and again carry out the process of re-partitioning.
Connect to smaller datasets
In some cases, the amount of reference data with which the connection is planned is relatively small, so that complete copies of them can fit locally on each of the nodes. For such situations, Kafka Streams provides the GlobalKTable class.
GlobalKTable instances are unique because the application replicates all the data to each node. And since all the data is present on each node, there is no need to partition the stream of events by the reference data key so that it is accessible to all sections. GlobalKTable objects can also perform keyless connections. Let's go back to one of the previous examples to demonstrate this feature.
Connecting KStream objects to GlobalKTable objects
In subsection 5.3.2, we performed window aggregation of exchange transactions by customers. The results of this aggregation looked something like this:
{customerId='074-09-3705', stockTicker='GUTM'}, 17
{customerId='037-34-5184', stockTicker='CORK'}, 16Although these results were consistent with the goal, it would be more convenient if the name of the client and the full name of the company were also displayed. To add a customer’s name and a company’s name, you can perform normal connections, but you will need to perform two key mappings and repeated partitioning. With GlobalKTable you can avoid the cost of such operations.
To do this, we will use the countStream object from Listing 5.11 (the corresponding code can be found in the src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java file), connecting it with two GlobalKTable objects.

We have already discussed this before, so I won’t repeat it. But I note that the code in the toStream (). Map function is abstracted into the function object for the sake of readability instead of the embedded lambda expression.
The next step is to declare two instances of GlobalKTable (the code shown can be found in src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java) (Listing 5.12).

Note that topic names are described using enumerated types.
Now that we have prepared all the components, it remains to write the code for the connection (which can be found in the src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java file) (Listing 5.13).

Although there are two compounds in this code, they are organized in a chain, since none of their results are used separately. Results are displayed at the end of the entire operation.
When you start the above connection operation, you will get the following results:
{customer='Barney, Smith' company="Exxon", transactions= 17}The essence has not changed, but these results look more clear.
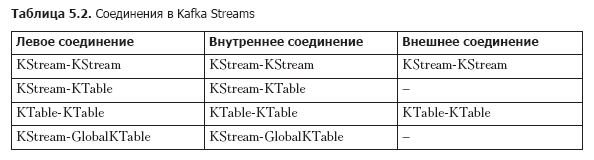
Counting Chapter 4, you've already seen several types of connections in action. They are listed in table. 5.2. This table reflects the connectivity relevant to version 1.0.0 of Kafka Streams; something will change in future releases.
In conclusion, I’ll remind you the main thing: you can connect event streams (KStream) and update streams (KTable) using the local state. In addition, if the size of the reference data is not too large, you can use the GlobalKTable object. GlobalKTable replicates all sections to each of the nodes of the Kafka Streams application, thereby ensuring the availability of all data regardless of which section the key corresponds to.
Next we will see the possibility of Kafka Streams, thanks to which you can observe state changes without consuming data from the Kafka topic.
5.3.5. Request Status
We have already performed several operations involving the state and always output the results to the console (for development purposes) or write them to the topic (for industrial operation). When writing results to a topic, you have to use the Kafka consumer to view them.
Reading data from these topics can be considered a kind of materialized views. For our tasks, we can use the definition of a materialized view from Wikipedia: “... a physical database object containing the results of a query. For example, it can be a local copy of deleted data, or a subset of the rows and / or columns of a table or join results, or a pivot table obtained using aggregation ”(https://en.wikipedia.org/wiki/Materialized_view).
Kafka Streams also allows you to perform interactive queries on state stores, which allows you to directly read these materialized views. It is important to note that the request to the state store is in the nature of a read-only operation. Thanks to this, you can not be afraid to accidentally make the state an application inconsistent during data processing.
The ability to directly query state stores is important. It means that you can create applications - dashboards without having to first receive data from a Kafka consumer. It increases the efficiency of the application, due to the fact that it is not required to record data again:
- due to the locality of the data, they can be accessed quickly;
- Duplication of data is excluded, since they are not written to external storage.
The main thing that I would like you to remember: you can directly execute state requests from the application. You can not overestimate the opportunities that this gives you. Instead of consuming data from Kafka and storing records in the database for the application, you can query state stores with the same result. Direct requests to state stores mean less code (no consumer) and less software (no need for a database table to store the results).
We have covered a considerable amount of information in this chapter, so we will temporarily stop our discussion of interactive queries to state stores. But don’t worry: in chapter 9 we will create a simple application - an information panel with interactive queries. To demonstrate interactive queries and the possibilities of adding them to Kafka Streams applications, it will use some of the examples from this and previous chapters.
Summary
- KStream objects represent event streams comparable to database inserts. KTable objects represent update streams, they are more similar to updates in the database. The size of the KTable object does not grow; old records are replaced with new ones.
- KTable objects are required for aggregation operations.
- Using window operations, you can break aggregated data into time baskets.
- Благодаря объектам GlobalKTable можно получить доступ к справочным данным в любой точке приложения, независимо от разбиения по секциям.
- Возможны соединения между собой объектов KStream, KTable и GlobalKTable.
So far, we have focused on creating Kafka Streams applications using the high-level KStream DSL. Although a high-level approach allows you to create neat and concise programs, its use is a definite compromise. Working with DSL KStream means increasing the conciseness of the code by reducing the degree of control. In the next chapter, we will look at the low-level API of the handler nodes and try other tradeoffs. Programs will become longer than they were until now, but we will have the opportunity to create almost any processing node that we may need.
→ The book can be found in more detail on the publisher’s website
→ For Khabrozhiteley 25% discount on coupon - Kafka Streams
→ Upon payment of the paper version of the book, an electronic book is sent by e-mail.