VM performance analysis in VMware vSphere. Part 2: Memory
- Tutorial

Part 1. About the CPU
Part 3. About Storage
In this article we will talk about the performance counters of random access memory (RAM) in vSphere.
It seems that the memory is more and more unambiguous than with the processor: if there are performance problems on the VM, it is difficult not to notice them. But if they appear, dealing with them is much more difficult. But first things first.
Bit of theory
The RAM of virtual machines is taken from the memory of the server on which the VMs are running. This is quite obvious :). If the server RAM is not enough for everyone, ESXi begins to apply memory reclamation techniques. Otherwise, the VM operating systems would crash with RAM access errors.
What techniques to use ESXi decides depending on the load of RAM:
| Memory status | Border | Actions |
| High | 400% of minFree | After reaching the upper limit, large pages of memory are divided into small ones (TPS works in standard mode). |
| Clear | 100% of minFree | Large pages of memory are divided into small, TPS works forcibly. |
| Soft | 64% of minFree | TPS + Balloon |
| Hard | 32% of minFree | TPS + Compress + Swap |
| Low | 16% of minFree | Compress + Swap + Block |
minFree source is the RAM needed for the hypervisor to work.
Prior to ESXi 4.1 inclusive, minFree was fixed by default - 6% of the server RAM (the percentage could be changed via the Mem.MinFreePct option on ESXi). In later versions, due to the increase in memory volumes on minFree servers, it began to be calculated based on the memory size of the host, and not as a fixed percentage value.
The minFree value (default) is calculated as follows:
| Percentage of memory reserved for minFree | Memory range |
| 6% | 0-4 GB |
| 4% | 4-12 GB |
| 2% | 12-28 GB |
| 1% | Remaining memory |
For example, for a server with 128 GB of RAM, the MinFree value will be:
MinFree = 245.76 + 327.68 + 327.68 + 1024 = 1925.12 MB = 1.88 GB The
actual value may differ by a couple of hundred MB, it depends from the server and RAM.
| Percentage of memory reserved for minFree | Memory range | Value for 128 GB |
| 6% | 0-4 GB | 245.76 MB |
| 4% | 4-12 GB | 327.68 MB |
| 2% | 12-28 GB | 327.68 MB |
| 1% | Remaining memory (100 GB) | 1024 MB |
Typically, for productive stands, only High can be considered normal. For test and development stands, Clear / Soft conditions may be acceptable. If the host memory has less than 64% MinFree left, then the VMs running on it will definitely experience performance problems.
In each state, certain memory reclamation techniques are applied starting with TPS, which practically does not affect the performance of the VM, ending with Swapping. I’ll tell you more about them.
Transparent Page Sharing (TPS). TPS is, roughly speaking, deduplication of the pages of RAM of virtual machines on a server.
ESXi searches for identical pages of virtual machine RAM, counting and comparing the hash-sum of pages, and removes duplicate pages, replacing them with links to the same page in the server’s physical memory. As a result, physical memory consumption is reduced, and some re-subscription of memory can be achieved with little or no performance loss.
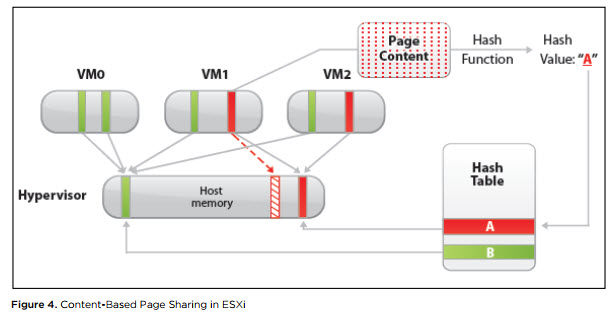
Source
This mechanism works only for 4 kB pages (small pages). Pages of 2 MB in size (large pages) the hypervisor does not even try to deduplicate: the chance to find identical pages of this size is not great.
By default, ESXi allocates memory to large pages. The breaking of large pages into small ones starts when the threshold of the High state is reached and is forced when the Clear state is reached (see the hypervisor state table).
If you want TPS to start working without waiting for the host RAM to fill up, in Advanced Options ESXi you need to set the “Mem.AllocGuestLargePage” value to 0 (default is 1). Then the allocation of large pages of memory for virtual machines will be disabled.
Since December 2014, in all ESXi releases, TPS between VMs has been disabled by default, since a vulnerability has been found that theoretically allows accessing the RAM of another VM from one VM. Details here. Information about the practical implementation of the exploitation of the TPS vulnerability I have not met.
TPS policy is controlled through the advanced option “Mem.ShareForceSalting” on ESXi:
0 - Inter-VM TPS. TPS works for pages of different VMs;
1 - TPS for VMs with the same value “sched.mem.pshare.salt” in VMX;
2 (default) - Intra-VM TPS. TPS works for pages inside a VM.
It definitely makes sense to turn off large pages and enable Inter-VM TPS on test benches. It can also be used for stands with a large number of VMs of the same type. For example, on stands with VDI, physical memory savings can reach tens of percent.
Memory Ballooning. Ballooning is no longer as harmless and transparent to the VM operating system as TPS. But with proper use with Ballooning you can live and even work.
Together with Vmware Tools, a special driver is installed on the VM, called the Balloon Driver (aka vmmemctl). When the hypervisor starts to run out of physical memory and enters the Soft state, ESXi asks the VM to return the unused RAM through this Balloon Driver. The driver, in turn, works at the operating system level and requests free memory from it. The hypervisor sees which pages of physical memory Balloon Driver has taken, takes the memory from the virtual machine, and returns it to the host. There are no problems with the operation of the OS, since at the OS level the memory is occupied by the Balloon Driver. By default, Balloon Driver can take up to 65% of VM memory.
If VMware Tools are not installed on the VM or Ballooning is disabled (I do not recommend, but there is KB:), the hypervisor immediately switches to more stringent techniques for removing memory. Conclusion: make sure that VMware Tools are on the VM.

Balloon Driver's operation can be checked from the OS via VMware Tools .
Memory compression This technique is used when the ESXi reaches Hard. As the name implies, ESXi is trying to compress 4 KB of RAM pages to 2 KB and thus free up some space in the server’s physical memory. This technique significantly increases the access time to the contents of the pages of the virtual memory of the VM, since the page must be uncleaned first. Sometimes not all pages can be compressed and the process itself takes some time. Therefore, this technique is not very effective in practice.
Memory swapping.After a short phase, Memory Compression ESXi almost inevitably (if the VMs did not go to other hosts or shut down) goes to Swapping. And if there is very little memory left (Low state), then the hypervisor also stops allocating VM pages of memory, which can cause problems in guest VMs.
This is how Swapping works. When you turn on the virtual machine, a file with the extension .vswp is created for it. In size, it is equal to the non-reserved RAM of the VM: this is the difference between configured and reserved memory. When working with Swapping, ESXi unloads the memory pages of the virtual machine into this file and starts working with it instead of the server’s physical memory. Of course, such such “RAM” memory is several orders of magnitude slower than real memory, even if .vswp is on fast storage.
Unlike Ballooning, when unused pages are selected from a VM, pages that are actively used by the OS or applications inside the VM can go to disk during Swapping. As a result, the performance of the VM drops until it hangs. VM formally works and at least it can be correctly disabled from the OS. If you will be patient;)
If the VMs went to Swap - this is an abnormal situation, which is best avoided if possible.
Basic virtual machine memory performance counters
So we got to the main thing. To monitor the memory status, the VM has the following counters:
Active - shows the amount of RAM (Kbytes) to which the VM gained access in the previous measurement period.
Usage is the same as Active, but as a percentage of the configured VM memory. It is calculated using the following formula: active ÷ virtual machine configured memory size.
High Usage and Active, respectively, are not always indicative of VM performance issues. If a VM aggressively uses memory (at least gets access to it), this does not mean that there is not enough memory. Rather, this is an occasion to see what happens in the OS.
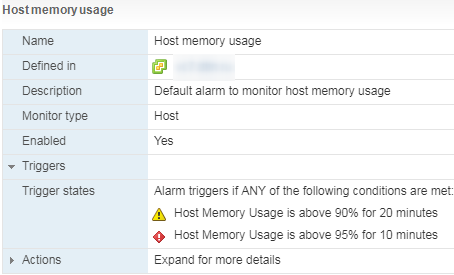
There is a standard Alarm on Memory Usage for VM:

Shared- the amount of RAM of the VM deduplicated using TPS (inside the VM or between VMs).
Granted - the amount of physical memory of the host (Kbytes) that was given to the VM. Includes Shared.
Consumed (Granted - Shared) - the amount of physical memory (Kbytes) that the VM consumes from the host. Does not include Shared.
If part of the VM’s memory is not allocated from the host’s physical memory, but from the swap file or the memory is taken from the VM through the Balloon Driver, this amount is not taken into account in Granted and Consumed.
High values of Granted and Consumed are perfectly normal. The operating system gradually takes away memory from the hypervisor and does not give back. Over time, with an actively working VM, the values of these counters approaches the amount of configured memory, and remain there.
Zero- the amount of RAM in the VM (Kbytes), which contains zeros. Such memory is considered free hypervisor and can be given to other virtual machines. After the guest OS got it written down to null memory, it goes to Consumed and doesn’t return back.
Reserved Overhead - the amount of RAM in the VM, (Kbytes) reserved by the hypervisor for the VM to work. This is a small amount, but it must be available on the host, otherwise the VM will not start.
Balloon - the amount of RAM (KB) seized from the VM using the Balloon Driver.
Compressed - the amount of RAM (KB) that was able to be compressed.
Swapped- the amount of RAM (KB), which for lack of physical memory on the server moved to disk.
Balloon and other memory reclamation techniques counters are zero.
This is how the graph with memory counters of a normally working VM with 150 GB of RAM looks like.
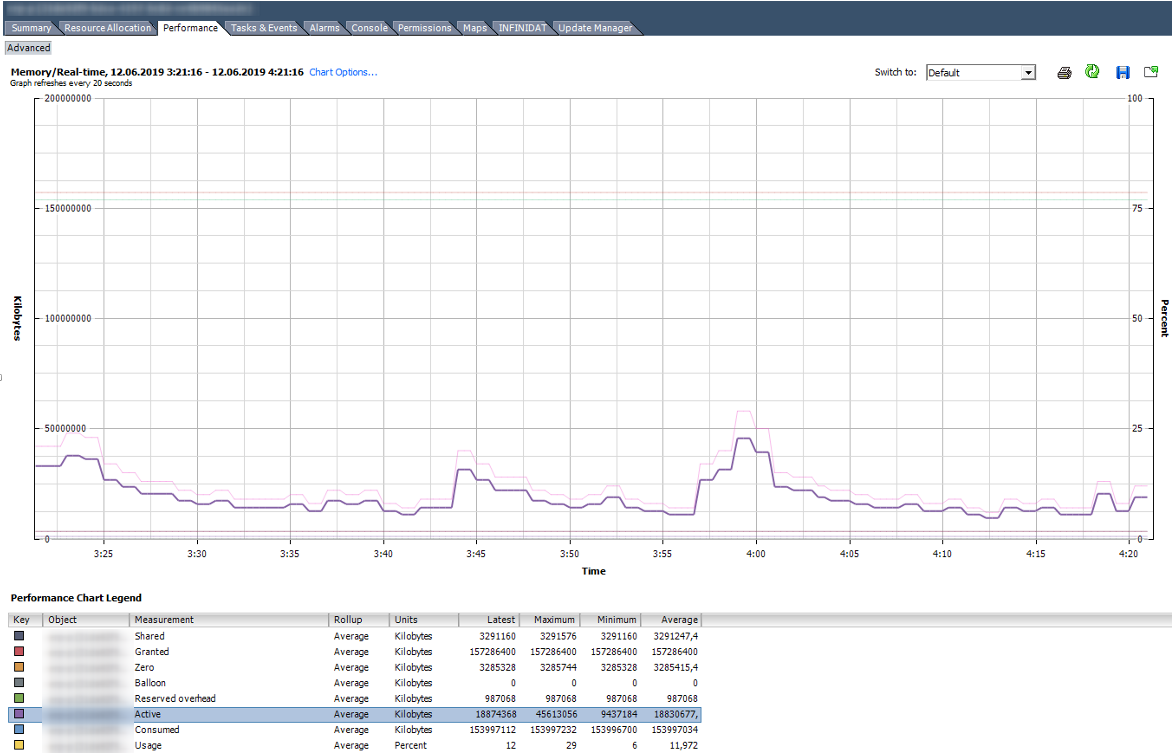
On the graph below, the VM has obvious problems. The graph shows that for this VM all the described techniques for working with RAM were used. Balloon for this VM is much larger than Consumed. In fact, the VM is more likely dead than alive.
ESXTOP
As with the CPU, if you want to quickly evaluate the situation on the host, as well as its dynamics with an interval of up to 2 seconds, it is worth using ESXTOP.
The ESXTOP memory screen is called with the “m” key and looks like this (the fields B, D, H, J, K, L, O are selected): The

following parameters will be interesting for us:
Mem overcommit avg - the average value of the memory subscription over the host for 1, 5 and 15 minutes. If above zero, then this is an occasion to see what happens, but not always an indicator of the presence of problems.
In the lines PMEM / MB and VMKMEM / MB - information about the physical memory of the server and the memory available to VMkernel. From the interesting here you can see the minfree value (in MB), the state of the host from memory (in our case, high).
In lineNUMA / MB, you can see the distribution of RAM by NUMA-nodes (sockets). In this example, the distribution is uneven, which in principle is not very good.
Next is the general server statistics for memory reclamation techniques:
PSHARE / MB - these are TPS statistics;
SWAP / MB - statistics on the use of Swap;
ZIP / MB - statistics of compression of memory pages;
MEMCTL / MB - Balloon Driver usage statistics.
For individual VMs, we may be interested in the following information. I hid the VM names so as not to embarrass the audience :). If the ESXTOP metric is similar to the counter in vSphere, I quote the corresponding counter.
MEMSZ is the amount of memory configured on the VM (MB).
MEMSZ = GRANT + MCTLSZ + SWCUR + untouched.
GRANT - Granted in MB.
TCHD - Active in MB.
MCTL? - is installed on VM Balloon Driver.
MCTLSZ - Balloon in MB.
MCTLGT is the amount of RAM (MB) that ESXi wants to remove from the VM through the Balloon Driver (Memctl Target).
MCTLMAX - the maximum amount of RAM (MB) that ESXi can remove from the VM through the Balloon Driver.
SWCUR - the current amount of RAM (MB) given to the VM from the Swap file.
SWGT - the amount of RAM (MB) that ESXi wants to give VMs from a Swap file (Swap Target).
Also through ESXTOP you can see more detailed information about the NUMA VM topology. To do this, select the fields D, G:
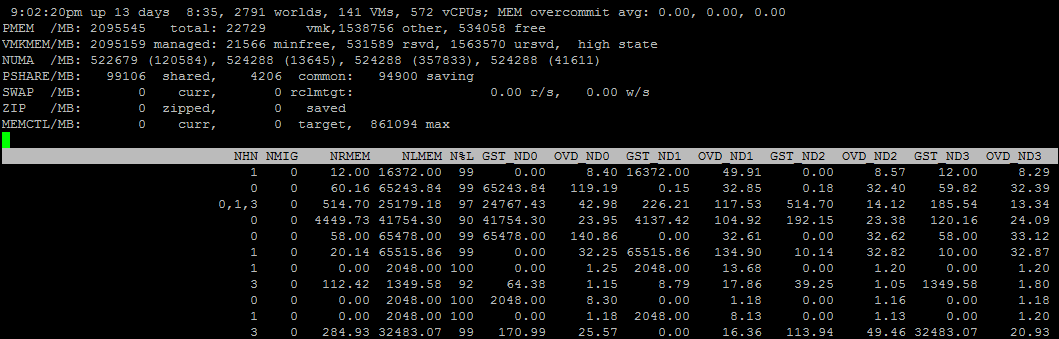
NHN - NUMA nodes on which the VM is located. Here you can immediately notice wide vm that do not fit on one NUMA node.
NRMEM - how many megabytes of memory the VM takes from the remote NUMA node.
NLMEM - how many megabytes of memory the VM takes from the local NUMA node.
N% L - percentage of VM memory on the local NUMA node (if less than 80%, performance problems may occur).
Memory on the hypervisor
If the CPU counters on the hypervisor are usually not of special interest, then the situation is the opposite with memory. A high Memory Usage on the VM does not always indicate a performance problem, but a high Memory Usage on the hypervisor just starts the memory management technician and causes problems with the VM's performance. Host Memory Usage alarms must be monitored and VMs not allowed to enter Swap.
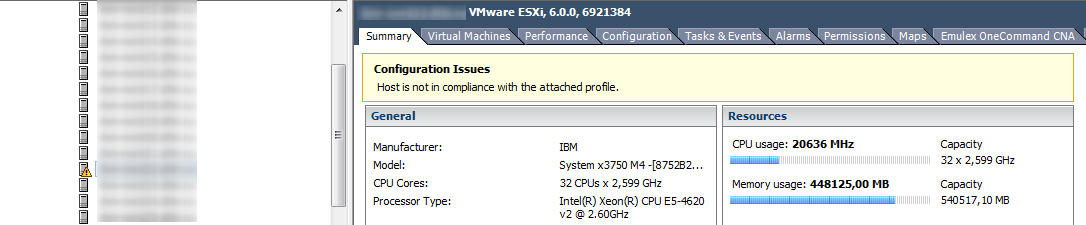
Unswap
If the VM got into Swap, its performance is greatly reduced. Ballooning and compression traces quickly disappear after the appearance of free RAM on the host, but the virtual machine is in no hurry to return from Swap to the server RAM.
Prior to ESXi 6.0, the only reliable and fast way to get VMs out of Swap was by rebooting (to be more precise, turning the container off / on). Starting with ESXi 6.0, a not-so-official, but working and reliable way to get VMs out of Swap appeared. At one of the conferences, I managed to talk with one of the VMware engineers responsible for the CPU Scheduler. He confirmed that the method is quite working and safe. In our experience, problems with him were also not noticed.
Actually the commands for outputting VMs from Swap describedDuncan Epping. I will not repeat the detailed description, just give an example of its use. As can be seen in the screenshot, some time after the execution of the specified Swap commands on the VM disappears.
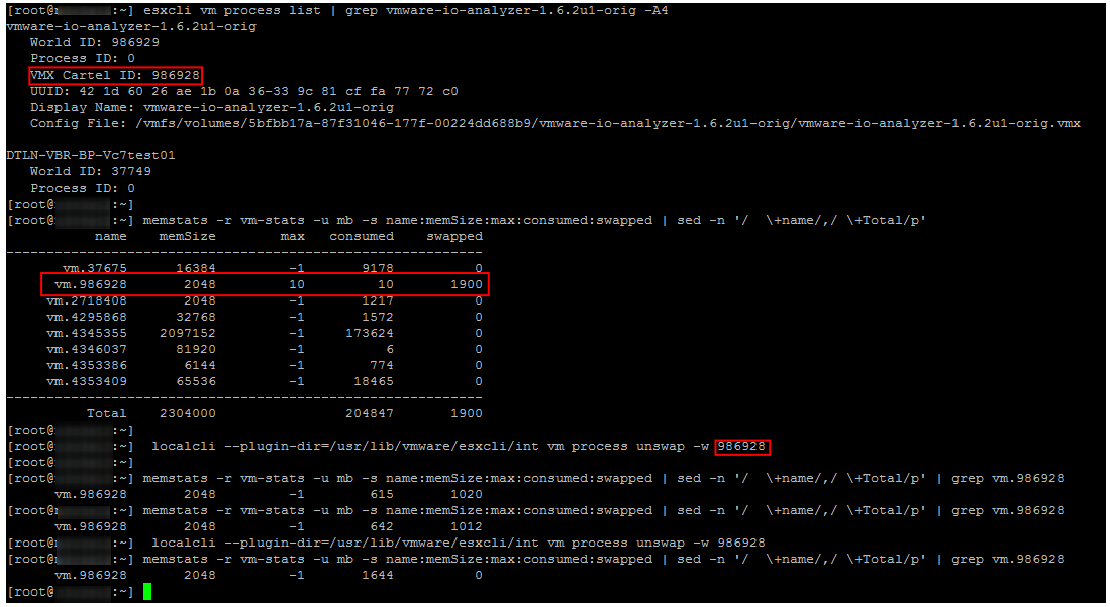
Tips for managing RAM on ESXi
In conclusion, I’ll give a few tips to help you avoid problems with VM performance due to RAM:
- Avoid oversubscribing in RAM in productive clusters. It is always advisable to have ~ 20-30% free memory in the cluster, so that DRS (and the administrator) has room for maneuver, and VMs do not go to Swap during migration. Also do not forget the margin for fault tolerance. It is unpleasant when, when one server fails and the VM is rebooted using HA, some of the machines also go to Swap.
- In highly consolidated infrastructures, try NOT to create VMs with more than half the host memory. This again will help DRS distribute the virtual machines across the cluster servers without any problems. This rule, of course, is not universal :).
- Watch out for Host Memory Usage Alarm.
- Do not forget to put VMware Tools on the VM and do not turn off Ballooning.
- Consider enabling Inter-VM TPS and disabling Large Pages in VDI and test environments.
- If the VM is experiencing performance problems, check to see if it is using memory from a remote NUMA node.
- Get VMs out of Swap as fast as possible! Among other things, if the VM is in Swap, for obvious reasons, the storage system suffers.
That's all for RAM. Below are related articles for those who want to delve into the details. The next article will be devoted to the story.
useful links
http://www.yellow-bricks.com/2015/03/02/what-happens-at-which-vsphere-memory-state/
http://www.yellow-bricks.com/2013/06/14/ how-does-mem-minfreepct-work-with-vsphere-5-0-and-up /
https://www.vladan.fr/vmware-transparent-page-sharing-tps-explained/
http: // www. yellow-bricks.com/2016/06/02/memory-pages-swapped-can-unswap/
https://kb.vmware.com/s/article/1002586
https://www.vladan.fr/what-is -vmware-memory-ballooning /
https://kb.vmware.com/s/article/2080735
https://kb.vmware.com/s/article/2017642
https://labs.vmware.com/vmtj/vmware -esx-memory-resource-management-swap
https://blogs.vmware.com/vsphere/2013/10/understanding-vsphere-active-memory.html
https://www.vmware.com/support/developer/converter-sdk/conv51_apireference/memory_counters.html
https://docs.vmware.com/en/VMware-vSphere/6.5/vsphere-esxi-vcenter-server-65 -monitoring-performance-guide.pdf
http://www.yellow-bricks.com/2013/06/14/ how-does-mem-minfreepct-work-with-vsphere-5-0-and-up /
https://www.vladan.fr/vmware-transparent-page-sharing-tps-explained/
http: // www. yellow-bricks.com/2016/06/02/memory-pages-swapped-can-unswap/
https://kb.vmware.com/s/article/1002586
https://www.vladan.fr/what-is -vmware-memory-ballooning /
https://kb.vmware.com/s/article/2080735
https://kb.vmware.com/s/article/2017642
https://labs.vmware.com/vmtj/vmware -esx-memory-resource-management-swap
https://blogs.vmware.com/vsphere/2013/10/understanding-vsphere-active-memory.html
https://www.vmware.com/support/developer/converter-sdk/conv51_apireference/memory_counters.html
https://docs.vmware.com/en/VMware-vSphere/6.5/vsphere-esxi-vcenter-server-65 -monitoring-performance-guide.pdf