High-level replication in the Tarantool DBMS
Hi, I am creating applications for the Tarantool DBMS - this is a platform developed by Mail.ru Group that combines a high-performance DBMS and an application server in Lua. The high speed of Tarantool-based solutions is achieved, in particular, by supporting in-memory DBMS mode and the ability to execute business application logic in a single address space with data. This ensures data persistence using ACID transactions (a WAL log is kept on the disk). Tarantool has built-in replication and sharding support. Starting with version 2.1, SQL queries are supported. Tarantool is open source and licensed under the Simplified BSD. There is also a commercial Enterprise version.

Feel the power! (... aka enjoy the performance)
All of the above makes Tarantool an attractive platform for creating highly loaded database applications. In such applications, data replication often becomes necessary.
As mentioned above, Tarantool has built-in data replication. The principle of its work is the sequential execution on replicas of all transactions contained in the wizard log (WAL). Typically, such replication (we will call it low-level below ) is used to provide fault tolerance of the application and / or to distribute the load of reading between the nodes of the cluster.
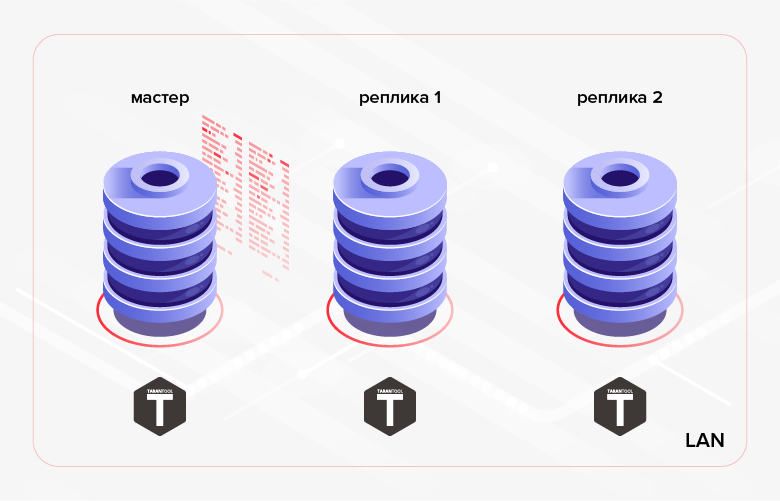
Fig. 1. Replication within the cluster
An example of an alternative scenario is the transfer of data created in one database to another database for processing / monitoring. In the latter case, a more convenient solution may be to use high-level replication — data replication at the business logic level of the application. Those. We do not use a ready-made solution built into the DBMS, but on our own we implement replication inside the application we are developing. This approach has both advantages and disadvantages. We list the pros.
1. Save traffic:
2. There are no difficulties with the implementation of exchange via HTTP, which allows you to synchronize remote databases.
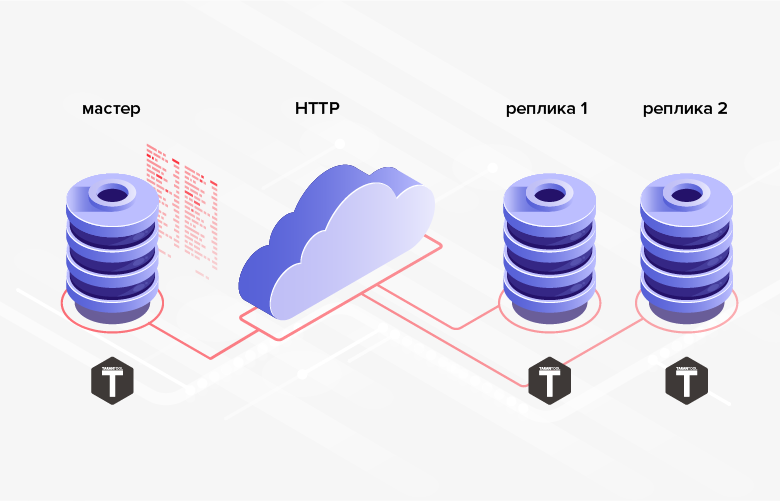
Fig. 2. Replication via HTTP
3. The database structures between which the data is transmitted do not have to be the same (moreover, in the general case, it is even possible to use different DBMSs, programming languages, platforms, etc.).
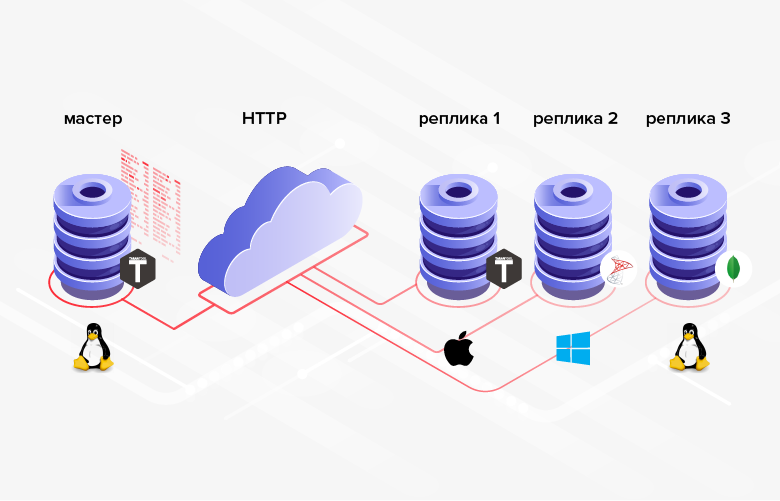
Fig. 3. Replication in heterogeneous systems The
disadvantage is that, on average, programming is more complicated / more expensive than configuration, and instead of setting up the built-in functionality, you have to implement your own.
If in your situation the above advantages play a decisive role (or are a necessary condition), then it makes sense to use high-level replication. Let's consider several ways to implement high-level data replication in the Tarantool DBMS.
So, one of the benefits of high-level replication is saving traffic. In order for this advantage to be fully manifested, it is necessary to minimize the amount of data transmitted during each exchange session. Of course, you should not forget that at the end of the session the data receiver must be synchronized with the source (at least for the part of the data that is involved in replication).
How to minimize the amount of data transferred during high-level replication? The solution "in the forehead" may be the selection of data by date-time. To do this, you can use the date-time field already in the table (if any). For example, a document “order” may have a field “required time for order execution” -
Another solution, more complex in terms of implementation, is to acknowledge receipt of data. In this case, at each exchange session, all data is transmitted, the receipt of which is not confirmed by the recipient. For implementation, you need to add a Boolean column to the source table (for example,
The method, devoid of the disadvantages above, is to add columns to the table to be transmitted to track changes in its rows. Such a column can be of the type date-time and must be set / updated by the application for the current time each time adding / changing records (atomically with adding / changing). As an example, let's call a column
You can increase the efficiency of data transfer by slightly improving the previous approach. To do this, we will use an integer type (long integer) as the values of the column fields for tracking changes. Name the column
The last proposed method of minimizing the amount of data transferred as part of high-level replication seems to me the most optimal and universal. Let us dwell on it in more detail.
In MS SQL Server, to implement this approach, there is a special column type -
First, a little terminology: tables in Tarantool are called space, and records are called tuple. In Tarantool, you can create sequences. Sequences are nothing more than named generators of ordered values of integers. Those. this is just what we need for our purposes. Below we will create such a sequence.
Before you perform any database operation in Tarantool, you must run the following command:
As a result, Tarantool will start writing snapshots and a transaction log to the current directory.
Create the sequence
The option
Let's create a space for an example.
Here we set the name of the space (
Tarantool auto-increment fields are also created using sequences. Create an auto-incremental primary key in the field
Tarantool supports several types of indexes. Most often, indexes of the TREE and HASH types are used, which are based on the structures corresponding to the name. TREE is the most versatile index type. It allows you to retrieve data in an ordered manner. But for the choice of equality, HASH is more suitable. Accordingly, it is advisable to use HASH for the primary key (which we did).
To use a column
The given trigger replaces the field value of the
In order to be able to retrieve data from the space
The index type is a tree (
Add some data to the space:
Because the first field is an auto-increment counter, we pass nil instead. Tarantool will automatically substitute the next value. Similarly,
Check the result of the insert:
As you can see, the first and last field were filled in automatically. Now it will be easy to write a function for paging unloading space changes
The function takes as a parameter the value of the
Data retrieval in Tarantool is done through indexes. The function
The iterator returns the tuples. In order to subsequently be able to transfer data via HTTP, it is necessary to convert the tuples to a structure convenient for subsequent serialization. In the example, the standard function is used for this.
The page size of the output data (the number of records in one portion) is determined by the variable
Put the function
To load the module, execute:
Let's execute the function
Take the field value
Once again:
As you can see, with this use, the function page-by-page returns all space records
We will make changes to the space:
We changed the field value
Repeat the last function call:
The function returned the changed and added records. Thus, the function
We leave the output of the results via HTTP in the form of JSON beyond the scope of this article. You can read about it here: https://habr.com/ru/company/mailru/blog/272141/
Consider what the implementation of the receiving side looks like. Create a space on the receiving side to store the downloaded data:
The structure of the space resembles the structure of the space in the source. But since we are not going to transfer the received data elsewhere, the column
In addition, we need a space to save the values
For each loaded space (field
Let's create a function for loading space data
We also need a library for json deserialization:
This is enough to create a data loading function:
The function performs an HTTP request at url, passes it
The function of saving the received data is as follows:
The cycle of storing data in the space is
Finally, the synchronization function of the local space
First, read the previously saved value
To protect against accidental loops (in case of an error in the program), the cycle
As a result of the function execution, the
Obviously, data deletion cannot be broadcast in this way. If such a need exists, you can use the deletion mark. We add a
Sequence
We examined an effective way of high-level data replication in applications using the Tarantool DBMS.
Feel the power! (... aka enjoy the performance)
All of the above makes Tarantool an attractive platform for creating highly loaded database applications. In such applications, data replication often becomes necessary.
As mentioned above, Tarantool has built-in data replication. The principle of its work is the sequential execution on replicas of all transactions contained in the wizard log (WAL). Typically, such replication (we will call it low-level below ) is used to provide fault tolerance of the application and / or to distribute the load of reading between the nodes of the cluster.
Fig. 1. Replication within the cluster
An example of an alternative scenario is the transfer of data created in one database to another database for processing / monitoring. In the latter case, a more convenient solution may be to use high-level replication — data replication at the business logic level of the application. Those. We do not use a ready-made solution built into the DBMS, but on our own we implement replication inside the application we are developing. This approach has both advantages and disadvantages. We list the pros.
1. Save traffic:
- you can transfer not all data, but only a part of it (for example, you can transfer only some tables, some of their columns or records that meet a certain criterion);
- unlike low-level replication, which is performed continuously in asynchronous (implemented in the current version of Tarantool - 1.10) or synchronous (to be implemented in future versions of Tarantool) mode, high-level replication can be performed by sessions (i.e., the application first performs data synchronization - exchange session data, then there is a pause in replication, after which the next exchange session occurs, etc.);
- if the record has changed several times, you can transfer only its latest version (as opposed to low-level replication, in which all changes made on the wizard will be sequentially played on the replicas).
2. There are no difficulties with the implementation of exchange via HTTP, which allows you to synchronize remote databases.
Fig. 2. Replication via HTTP
3. The database structures between which the data is transmitted do not have to be the same (moreover, in the general case, it is even possible to use different DBMSs, programming languages, platforms, etc.).
Fig. 3. Replication in heterogeneous systems The
disadvantage is that, on average, programming is more complicated / more expensive than configuration, and instead of setting up the built-in functionality, you have to implement your own.
If in your situation the above advantages play a decisive role (or are a necessary condition), then it makes sense to use high-level replication. Let's consider several ways to implement high-level data replication in the Tarantool DBMS.
Traffic minimization
So, one of the benefits of high-level replication is saving traffic. In order for this advantage to be fully manifested, it is necessary to minimize the amount of data transmitted during each exchange session. Of course, you should not forget that at the end of the session the data receiver must be synchronized with the source (at least for the part of the data that is involved in replication).
How to minimize the amount of data transferred during high-level replication? The solution "in the forehead" may be the selection of data by date-time. To do this, you can use the date-time field already in the table (if any). For example, a document “order” may have a field “required time for order execution” -
delivery_time. The problem with this solution is that the values in this field do not have to be in the sequence corresponding to the creation of orders. Thus, we cannot remember the maximum field value delivery_timetransmitted during the previous exchange session, and during the next exchange session, select all records with a higher field value delivery_time. In the interval between exchange sessions, records with a lower field value could be added delivery_time. Also, the order could undergo changes, which nevertheless did not affect the field delivery_time. In both cases, the changes will not be transmitted from the source to the receiver. To solve these problems, we will need to transmit data "overlap". Those. during each exchange session we will transfer all data with the field valuedelivery_timeexceeding some moment in the past (for example, N hours from the current moment). However, it is obvious that for large systems this approach is very redundant and can reduce the traffic savings that we are aiming for. In addition, the transmitted table may not have a date-time field. Another solution, more complex in terms of implementation, is to acknowledge receipt of data. In this case, at each exchange session, all data is transmitted, the receipt of which is not confirmed by the recipient. For implementation, you need to add a Boolean column to the source table (for example,
is_transferred). If the receiver confirms receipt of the record, the corresponding field takes the valuetrue, after which the record is no longer involved in exchanges. This implementation option has the following disadvantages. Firstly, for each transferred record, it is necessary to generate and send a confirmation. Roughly speaking, this can be comparable to doubling the amount of data transferred and leading to a doubling of the number of round trips. Secondly, there is no possibility of sending the same record to several receivers (the first receiver will confirm the receipt for themselves and for everyone else).The method, devoid of the disadvantages above, is to add columns to the table to be transmitted to track changes in its rows. Such a column can be of the type date-time and must be set / updated by the application for the current time each time adding / changing records (atomically with adding / changing). As an example, let's call a column
update_time. Having saved the maximum field value of this column for the transferred records, we can start the next exchange session from this value (select records with a field value update_timethat exceeds the previously saved value). The problem with the latter approach is that data changes can occur in batch mode. As a result, the field values in the columnupdate_timemay not be unique. Thus, this column cannot be used for batch (page) data output. For page-by-page data output, it will be necessary to invent additional mechanisms that are likely to have very low efficiency (for example, extracting from the database all records with a value update_timehigher than the specified one and issuing a certain number of records, starting at a certain offset from the start of the sample). You can increase the efficiency of data transfer by slightly improving the previous approach. To do this, we will use an integer type (long integer) as the values of the column fields for tracking changes. Name the column
row_ver. The field value of this column should still be set / updated each time a record is created / modified. But in this case, the field will be assigned not the current date-time, but the value of some counter increased by one. As a result, the column row_verwill contain unique values and can be used not only to output “delta” data (data added / changed after the end of the previous exchange session), but also for simple and effective pagination. The last proposed method of minimizing the amount of data transferred as part of high-level replication seems to me the most optimal and universal. Let us dwell on it in more detail.
Data transfer using row version counter
Server / master implementation
In MS SQL Server, to implement this approach, there is a special column type -
rowversion. Each database has a counter, which increases by one each time you add / change a record in a table that has a type column rowversion. The value of this counter is automatically assigned to the field of this column in the added / changed record. Tarantool DBMS does not have a similar built-in mechanism. However, in Tarantool, it is not difficult to implement it manually. Consider how this is done.First, a little terminology: tables in Tarantool are called space, and records are called tuple. In Tarantool, you can create sequences. Sequences are nothing more than named generators of ordered values of integers. Those. this is just what we need for our purposes. Below we will create such a sequence.
Before you perform any database operation in Tarantool, you must run the following command:
box.cfg{}As a result, Tarantool will start writing snapshots and a transaction log to the current directory.
Create the sequence
row_version:box.schema.sequence.create('row_version',
{ if_not_exists = true })The option
if_not_existsallows you to run the creation script multiple times: if the object exists, Tarantool will not try to recreate it. This option will be used in all subsequent DDL commands. Let's create a space for an example.
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
},
{
name = 'row_ver',
type = 'unsigned'
}
},
if_not_exists = true
})Here we set the name of the space (
goods), the names of the fields and their types. Tarantool auto-increment fields are also created using sequences. Create an auto-incremental primary key in the field
id:box.schema.sequence.create('goods_id',
{ if_not_exists = true })
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})Tarantool supports several types of indexes. Most often, indexes of the TREE and HASH types are used, which are based on the structures corresponding to the name. TREE is the most versatile index type. It allows you to retrieve data in an ordered manner. But for the choice of equality, HASH is more suitable. Accordingly, it is advisable to use HASH for the primary key (which we did).
To use a column
row_verto transmit changed data, you need to bind sequence values to the fields of this column row_ver. But unlike the primary key, the value of the column field row_vershould increase by one, not only when adding new records, but also when changing existing ones. To do this, you can use triggers. Tarantool has two types of space triggers:before_replaceand on_replace. Triggers are triggered every time data in the space is changed (for each tuple affected by the changes, the trigger function is triggered). In contrast on_replace, before_replace-triggers allow you to modify the data of the tuple for which the trigger is executed. Accordingly, the last type of triggers suits us.box.space.goods:before_replace(function(old, new)
return box.tuple.new({new[1], new[2], new[3],
box.sequence.row_version:next()})
end)The given trigger replaces the field value of the
row_verstored tuple with the next sequence value row_version. In order to be able to retrieve data from the space
goodsin the column row_ver, create an index:box.space.goods:create_index('row_ver', {
parts = { 'row_ver' },
unique = true,
type = 'TREE',
if_not_exists = true
})The index type is a tree (
TREE), because we need to retrieve the data in ascending order of values in the column row_ver. Add some data to the space:
box.space.goods:insert{nil, 'pen', 123}
box.space.goods:insert{nil, 'pencil', 321}
box.space.goods:insert{nil, 'brush', 100}
box.space.goods:insert{nil, 'watercolour', 456}
box.space.goods:insert{nil, 'album', 101}
box.space.goods:insert{nil, 'notebook', 800}
box.space.goods:insert{nil, 'rubber', 531}
box.space.goods:insert{nil, 'ruler', 135}Because the first field is an auto-increment counter, we pass nil instead. Tarantool will automatically substitute the next value. Similarly,
row_veryou can pass nil as the value of the column fields - or omit the value at all, because this column takes the last position in the space. Check the result of the insert:
tarantool> box.space.goods:select()
---
- - [1, 'pen', 123, 1]
- [2, 'pencil', 321, 2]
- [3, 'brush', 100, 3]
- [4, 'watercolour', 456, 4]
- [5, 'album', 101, 5]
- [6, 'notebook', 800, 6]
- [7, 'rubber', 531, 7]
- [8, 'ruler', 135, 8]
...As you can see, the first and last field were filled in automatically. Now it will be easy to write a function for paging unloading space changes
goods:local page_size = 5
local function get_goods(row_ver)
local index = box.space.goods.index.row_ver
local goods = {}
local counter = 0
for _, tuple in index:pairs(row_ver, { iterator = 'GT' }) do
local obj = tuple:tomap({ names_only = true })
table.insert(goods, obj)
counter = counter + 1
if counter >= page_size then
break
end
end
return goods
endThe function takes as a parameter the value of the
row_verlast record received (0 for the first call) and returns the next batch of changed data (if there is one, otherwise an empty array). Data retrieval in Tarantool is done through indexes. The function
get_goodsuses an index iterator row_verto retrieve the changed data. The iterator type is GT (Greater Than, more than). This means that the iterator will sequentially traverse the index values starting from the next value after the passed key. The iterator returns the tuples. In order to subsequently be able to transfer data via HTTP, it is necessary to convert the tuples to a structure convenient for subsequent serialization. In the example, the standard function is used for this.
tomap. Instead of using, tomapyou can write your own function. For example, we might want to rename a field name, not pass a field codeand add a field comment:local function unflatten_goods(tuple)
local obj = {}
obj.id = tuple.id
obj.goods_name = tuple.name
obj.comment = 'some comment'
obj.row_ver = tuple.row_ver
return obj
endThe page size of the output data (the number of records in one portion) is determined by the variable
page_size. In the example, the value page_sizeis 5. In a real program, page size usually matters more. It depends on the average size of the space tuple. The optimal page size can be selected empirically by measuring the time of data transfer. The larger the page, the smaller the number of round trips between the sending and receiving sides. So you can reduce the total time for uploading changes. However, if the page size is too large, we will take the server too long to serialize the selection. As a result, there may be delays in processing other requests that came to the server. Parameterpage_sizecan be downloaded from the configuration file. For each transmitted space, you can set your own value. However, for most spaces, the default value (for example, 100) may be suitable. Put the function
get_goodsin the module. Create a repl.lua file containing a description of the variable page_sizeand function get_goods. At the end of the file, add the export function:return {
get_goods = get_goods
}
To load the module, execute:
tarantool> repl = require('repl')
---
...
Let's execute the function
get_goods:tarantool> repl.get_goods(0)
---
- - row_ver: 1
code: 123
name: pen
id: 1
- row_ver: 2
code: 321
name: pencil
id: 2
- row_ver: 3
code: 100
name: brush
id: 3
- row_ver: 4
code: 456
name: watercolour
id: 4
- row_ver: 5
code: 101
name: album
id: 5
...Take the field value
row_verfrom the last line and call the function again:tarantool> repl.get_goods(5)
---
- - row_ver: 6
code: 800
name: notebook
id: 6
- row_ver: 7
code: 531
name: rubber
id: 7
- row_ver: 8
code: 135
name: ruler
id: 8
...Once again:
tarantool> repl.get_goods(8)
---
- []
...As you can see, with this use, the function page-by-page returns all space records
goods. The last page is followed by an empty selection. We will make changes to the space:
box.space.goods:update(4, {{'=', 6, 'copybook'}})
box.space.goods:insert{nil, 'clip', 234}
box.space.goods:insert{nil, 'folder', 432}We changed the field value
namefor one record and added two new records. Repeat the last function call:
tarantool> repl.get_goods(8)
---
- - row_ver: 9
code: 800
name: copybook
id: 6
- row_ver: 10
code: 234
name: clip
id: 9
- row_ver: 11
code: 432
name: folder
id: 10
...The function returned the changed and added records. Thus, the function
get_goodsallows you to receive data that has changed since its last call, which is the basis of the replication method under consideration. We leave the output of the results via HTTP in the form of JSON beyond the scope of this article. You can read about it here: https://habr.com/ru/company/mailru/blog/272141/
Implementation of the client / slave part
Consider what the implementation of the receiving side looks like. Create a space on the receiving side to store the downloaded data:
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
}
},
if_not_exists = true
})
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})The structure of the space resembles the structure of the space in the source. But since we are not going to transfer the received data elsewhere, the column
row_verin the receiver’s space is missing. The field idwill contain the identifiers of the source. Therefore, on the receiver side, there is no need to make it auto-increment. In addition, we need a space to save the values
row_ver:box.schema.space.create('row_ver', {
format = {
{
name = 'space_name',
type = 'string'
},
{
name = 'value',
type = 'string'
}
},
if_not_exists = true
})
box.space.row_ver:create_index('primary', {
parts = { 'space_name' },
unique = true,
type = 'HASH',
if_not_exists = true
})For each loaded space (field
space_name) we will save here the last loaded value row_ver(field value). The column is the primary key space_name. Let's create a function for loading space data
goodsvia HTTP. To do this, we need a library that implements an HTTP client. The following line loads the library and instantiates the HTTP client:local http_client = require('http.client').new()We also need a library for json deserialization:
local json = require('json')This is enough to create a data loading function:
local function load_data(url, row_ver)
local url = ('%s?rowVer=%s'):format(url,
tostring(row_ver))
local body = nil
local data = http_client:request('GET', url, body, {
keepalive_idle = 1,
keepalive_interval = 1
})
return json.decode(data.body)
endThe function performs an HTTP request at url, passes it
row_veras a parameter, and returns the deserialized result of the request. The function of saving the received data is as follows:
local function save_goods(goods)
local n = #goods
box.atomic(function()
for i = 1, n do
local obj = goods[i]
box.space.goods:put(
obj.id, obj.name, obj.code)
end
end)
endThe cycle of storing data in the space is
goodsplaced in a transaction (a function is used for this box.atomic) to reduce the number of disk operations. Finally, the synchronization function of the local space
goodswith the source can be implemented as follows:local function sync_goods()
local tuple = box.space.row_ver:get('goods')
local row_ver = tuple and tuple.value or 0
-- set your url here:
local url = 'http://127.0.0.1:81/test/goods/list'
while true do
local goods = load_goods(url, row_ver)
local count = #goods
if count == 0 then
return
end
save_goods(goods)
row_ver = goods[count].rowVer
box.space.row_ver:put({'goods', row_ver})
end
endFirst, read the previously saved value
row_verfor the space goods. If it is absent (the first exchange session), then we take as row_verzero. Next, in the loop, we paginate the modified data from the source to the specified url. At each iteration, we save the received data in the corresponding local space and update the value row_ver(in the space row_verand in the variable row_ver) - we take the value row_verfrom the last line of the loaded data. To protect against accidental loops (in case of an error in the program), the cycle
whilecan be replaced by for:for _ = 1, max_req do ...As a result of the function execution, the
sync_goodsspace goodsin the receiver will contain the latest versions of all space records goodsin the source. Obviously, data deletion cannot be broadcast in this way. If such a need exists, you can use the deletion mark. We add a
goodsBoolean field to the space is_deletedand instead of physically deleting the record, use logical deletion - set the field is_deletedvalue to value true. Sometimes, instead of a Boolean field, is_deletedit is more convenient to use a field deletedthat stores the date-time of the logical deletion of the record. After performing a logical deletion, the record marked for deletion will be transferred from the source to the receiver (according to the logic discussed above). Sequence
row_vercan be used to transfer data from other spaces: there is no need to create a separate sequence for each transmitted space. We examined an effective way of high-level data replication in applications using the Tarantool DBMS.
conclusions
- Tarantool DBMS is an attractive, promising product for creating highly loaded applications.
- High-level replication provides a more flexible approach to data transfer compared to low-level replication.
- The high-level replication method considered in the article allows one to minimize the amount of transmitted data by transferring only those records that have changed since the last exchange session.