DIY Black Mirror - teach a bot based on his chat history
In the “Black Mirror” there was a series (S2E1), in which they created robots similar to dead people, using the history of correspondence on social networks for training. I want to tell you how I tried to do something similar and what came of it. There will be no theory, only practice.

The idea was simple - to take the history of their chats from Telegram and, on their basis, to train the seq2seq network, which is capable of predicting its completion at the beginning of the dialogue. Such a network can operate in three modes:
- Predict user phrase completion based on conversation history
- Work in chatbot mode
- Synthesize entire conversation logs
That's what I got
Bot offers phrase completion
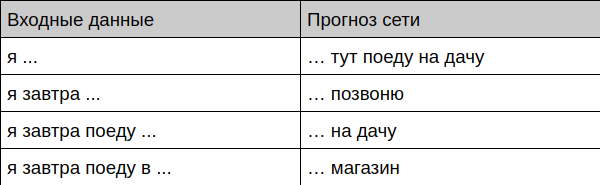
Bot offers completion of dialogue
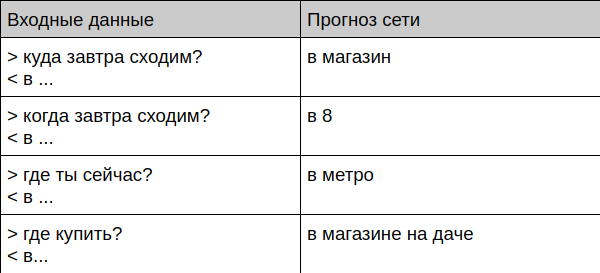
Bot communicates with a living person
User: привет
Bot: привет
User: как ты?
Bot: собираюсь
User: баг пофиксил?
Bot: нет
User: почему?
Bot: да не получается
User: ты сегодня когда дома будешь?
Bot: не знаю пока
User: ты занят?
Bot: в магазин еду Next I will tell you how to prepare the data and train such a bot yourself.
How to teach yourself
Data preparation
First of all, you need to get a lot of chats somewhere. I took all my correspondence in Telegram, since the client for the desktop allows downloading the full archive in JSON format. Then I threw away all the messages that contain quotes, links, and files, and transferred the remaining texts to lower case and threw out all the rare characters from there, leaving only a simple set of letters, numbers and punctuation marks - it’s easier to learn the network.
Then I brought the chats to this form:
===
> привет
< и тебе привет
> пока
< до встречи!
===
> как дела?
< хорошоHere, messages that begin with the symbol ">" is a question for me, the symbol "<" marks my answer accordingly, and the line "===" serves to separate the dialogs among themselves. The fact that one dialogue ended and the other started, I determined by time (if more than 15 minutes passed between messages, then we think that this is a new conversation. You can see the script for converting the story on github .
Since I have been actively using telegrams for a long time, there were a lot of messages in the end - there were 443 thousand lines in the final file.
Model selection
I promised that there would be no theory today, so I’ll try to explain as briefly as possible on my fingers.
I chose the classic seq2seq based on GRU. Such an input model receives the text letter by letter and also outputs one letter at a time. The learning process is based on the fact that we teach the network to predict the last letter of the text, such as the input we serve "pref" and expect that output will be issued "Rivet" .
To generate long texts, a simple trick is used - the result of the previous prediction is sent back to the network and so on until the necessary length of text is generated.
GRU modules can be very, very simplified as a "cunning perceptron with memory and attention", more details about them can be found, for example, here .
A well-known example of the task of generating Shakespeare's texts was chosen as the basis of the model .
Training
Anyone who has ever come across neural networks probably knows that learning them on the CPU is very boring. Fortunately, google comes to the rescue with their Colab service - in it you can run your code in jupyter notebook for free using a CPU, GPU and even TPU . In my case, training on the video card fits in 30 minutes, although sane results are available after 10. The main thing is to remember to switch the type of hardware (in the Runtime menu -> Change runtime type).
Testing
After training, you can proceed to model verification - I wrote several examples that allow you to access the model in different modes - from text generation to live chat. All of them are on github .
The method for generating text has a temperature parameter - the higher it is, the more diverse the text (and meaningless) will produce a bot. This parameter makes sense to configure hands for a specific task.
Further use
Why can such a network be used? The most obvious thing is to develop a bot (or smart keyboard) that can offer the user ready-made answers even before he writes them. A similar feature has long existed in Gmail and most keyboards, but it does not take into account the context of the conversation and the way a particular user conducts correspondence. Say, the G-Keyboard stably offers me completely meaningless options, for example, "I'm going with ... respect" in the place where I would like to get the option "I'm going from the dacha", which I definitely used many times.
Does the chat bot have a future? In its pure form, it is definitely not there, it has too much personal data, no one knows at what point it will give out to the interlocutor the number of your credit card that you once threw to a friend. Moreover, such a bot is not tuned at all, it is very difficult to get it to perform any specific tasks or correctly answer a specific question. Rather, such a chatbot could work in conjunction with other types of bots, providing a more connected dialogue "about nothing" - it copes well with this. (And yet, an external expert in the person of his wife said that the bot’s communication style is very similar to me. And the topics he cares about are clearly the same - bugs, fixes, commits, and other joys and sorrows of the developer constantly pop up in the texts).
What else advise you to try if this topic is interesting to you?
- Transfer learning (to train on a large body of other people's dialogues, and then finish on their own)
- Change model - increase, change type (for example, on LSTM).
- Try working with TPU. In its pure form, this model will not work, but it can be adapted. Theoretical acceleration of learning should be ten times.
- Port to a mobile platform, for example using Tensorflow mobile.