AI learned to create video from one frame. Old paintings can now be made alive

Technology from Harry Potter has survived to this day. Now, to create a full-fledged video of a person, one of his pictures or photographs is enough. Machine learning researchers from Skolkovo and the Samsung AI Center in Moscow published their work on creating such a system, along with a number of videos of celebrities and art objects that have received a new life.

The text of the scientific work can be read here . Everything is quite interesting there, with a lot of formulas, but the meaning is simple: their system is guided by "landmarks", sights of the face, like a nose, two eyes, two eyebrows, and a line of the chin. So she instantly catches what a person is. And then it can transfer everything else (color, face texture, mustache, stubble, etc.) to any other person’s video. Adapting the old face to new situations.
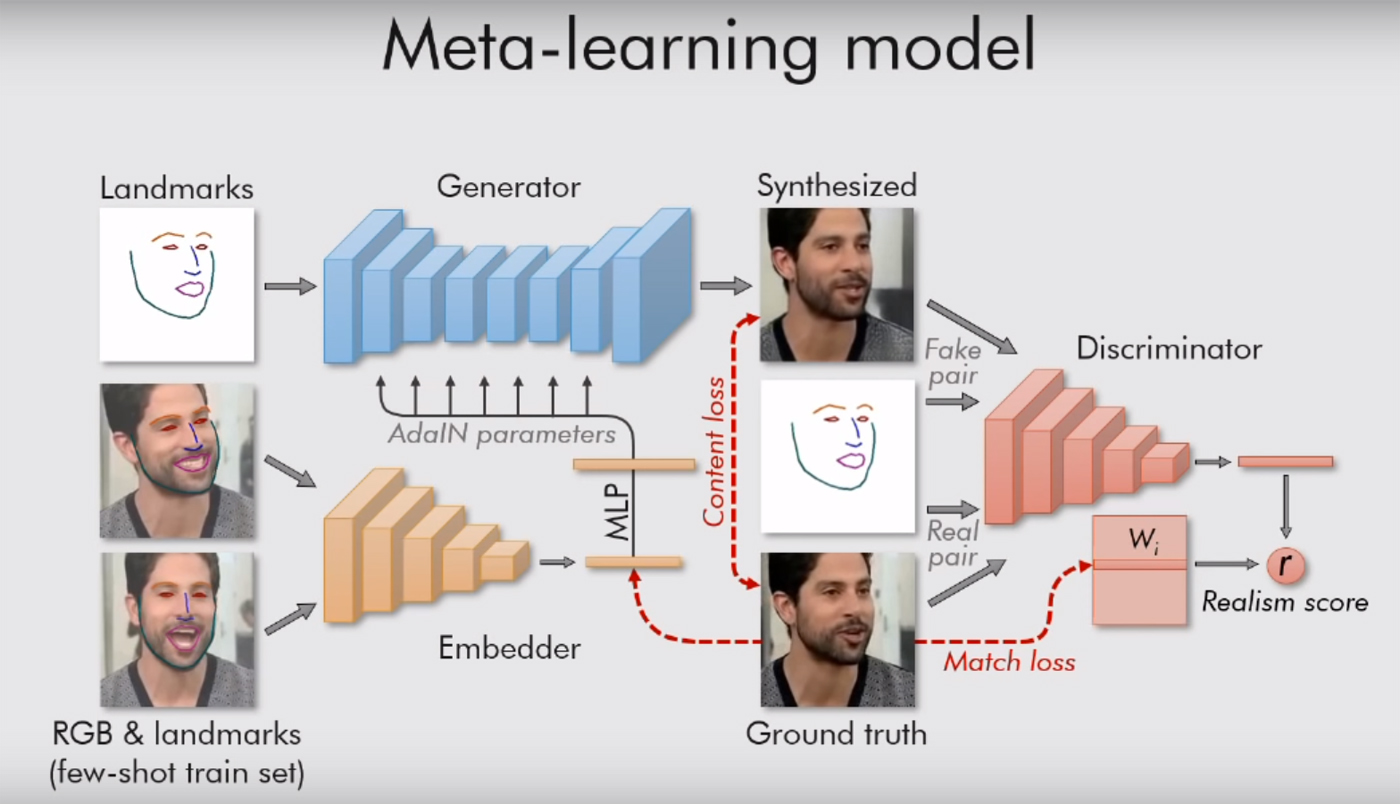
Of course, this only works on portraits. The model needs only one person, with a face turned towards us, so that he can at least see both eyes. Then the system can do anything with it, transmit any facial expressions to it. It is enough to give her a suitable video (with another person with his head in about the same position).
Earlier, AI had already learned how to make diphakes, and Internet users nobly mocked celebrities by inserting their faces into porn and making memes with Nicholas Cage. But for this, they had to train the algorithms in megabytes (or better - gigabytes) of data, find as many images and videos with the faces of celebrities as possible in order to produce a more or less decent result. The creator of Deepfakes himself said that it takes 8-12 hours to compile one short video. The new system generates the result instantly, and at the input it needs only one picture.
With the previous system, we would never be able to look at the living Mona Lisa, we have only one angle. Now, with benchmarking algorithms, this is becoming possible. The ideal is not achieved, but something is already close.

Moscow researchers also use a generative-adversarial network. Two models of the algorithm are fighting each other. Each tries to deceive the opponent, and prove to him that the video that she creates is real. In this way, a certain level of realism is achieved: a picture of a human face is not released “into the light” if the critic model is not more than 90% sure of its authenticity. As the authors say in their work, tens of millions of parameters are regulated in the images, but due to such a system, the work boils very quickly.

If there are several pictures, the result improves. Again, the easiest way is to work with celebrities who are already taken from all possible angles. To achieve “ideal realism” 32 shots are needed. In this case, the generated AI photos in low resolution will be indistinguishable from real human photos. Untrained people at this stage are no longer able to identify a fake - perhaps the chances remain with experts or with close relatives of the “experimental” from all these images.
If there is only one photo or picture, the result is not always the best. You can see artifacts on the video when the head is in motion without any problems. Researchers themselves say that their weakest point is the gaze. The model based on the landmarks of the face does not yet always understand how and where a person should look.
