Optimization of garbage collection in a highly loaded .NET service
Every day, tens of thousands of employees from several thousand organizations around the world work at Pyrus. We consider the responsiveness of the service (speed of processing requests) an important competitive advantage, since it directly affects the user experience. The key metric for us is the “percentage of slow queries”. Studying its behavior, we noticed that once a minute on the application servers there are pauses of about 1000 ms in length. At these intervals, the server does not respond and a queue of several dozen requests arises. The search for the causes and elimination of bottlenecks caused by garbage collection in the application will be discussed in this article.

Modern programming languages can be divided into two groups. In languages like C / C ++ or Rust, manual memory management is used, so programmers spend more time writing code, managing the lifetime of objects, and then debugging. At the same time, bugs due to improper use of memory are some of the most difficult to debug, so most modern development is conducted in languages with automatic memory management. These include, for example, Java, C #, Python, Ruby, Go, PHP, JavaScript, etc. Programmers save development time, but you have to pay extra runtime that the program regularly spends on garbage collection - freeing up memory occupied by objects to which there are no links left in the program. In small programs, this time is negligible,
Pyrus web servers run on the .NET platform, which uses automatic memory management. Most garbage collections are 'stop the world', i.e. at the time of their work stop all threads (threads) of the application. Non-blocking (background) assemblies actually stop all threads too, but for a very short period of time. During thread blocking, the server does not process requests, existing requests freeze, new ones are added to the queue. As a result, requests that were processed at the time of garbage collection are directly slowed down, and requests are processed more slowly immediately after garbage collection is completed due to accumulated queues. This worsens the metric "percentage of slow queries."
Armed with the recent Konrad Kokosa: Pro .NET Memory Management book (about how we brought its first copy to Russia in 2 days, you can write a separate post), which is entirely devoted to the topic of memory management in .NET, we began to study the problem.
To profile the Pyrus web server, we used the PerfView utility ( https://github.com/Microsoft/perfview ), sharpened for profiling .NET applications. The utility is based on the Event Tracing for Windows (ETW) engine and has a minimal impact on the performance of the profiled application, which allows it to be used on a combat server. In addition, the impact on performance depends on what types of events and what information we collect. We do not collect anything - the application works as usual. PerfView also requires neither recompilation nor restarting the application.
Run the PerfView trace with the / GCCollectOnly switch (trace time 1.5 hours). In this mode, it only collects garbage collection events and has minimal impact on performance. Let's look at the Memory Group / GCStats trace report, and in it a summary of the garbage collector events:
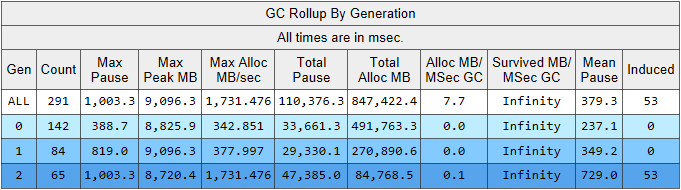
Here we see several interesting indicators at once:
Let us explain the observation about the number of garbage collections. The idea of dividing objects by their lifetime is based on the generational hypothesis): a significant part of the created objects dies quickly, and most of the rest live long (in other words, few objects that have an “average” lifetime). It is under this mode that the .NET garbage collector is imprisoned, and in this mode the second generation assemblies should be much smaller than the 0th generation. That is, for the optimal operation of the garbage collector, we must tailor the work of our application to the generational hypothesis. Let us formulate the rule as follows: objects must either die quickly, not living to the older generation, or to live to it and live there forever. This rule also applies to other platforms that use automatic memory management with generational separation, such as Java.
The data that is of interest to us can be extracted from another table in the GCStats report:

Here are some cases where an application tries to create a large object (in the .NET Framework objects> 85,000 bytes in size are created in the LOH - Large Object Heap), and it has to wait for the completion of the 2nd generation assembly, which takes place in parallel in the background. These pauses of the allocator are not as critical as the pauses of the garbage collector, since they affect only one thread. Before that, we used the .NET Framework version 4.6.1, and in version 4.7.1 Microsoft finalized the garbage collector, now it allows you to allocate memory in the Large Object Heap during the background generation of the 2nd generation: https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clr
Therefore, we updated to the latest version 4.7.2 at that time.
Why do we have so many builds of the older generation? The first assumption is that we have a memory leak. To test this hypothesis, let's look at the size of the second generation (we set up monitoring of the corresponding performance counters in Zabbix). From the graphs of the 2nd generation size for 2 Pyrus servers, it can be seen that its size first grows (mainly due to the filling of caches), but then stabilizes (large failures on the graph - regular restart of the web service to update the version):
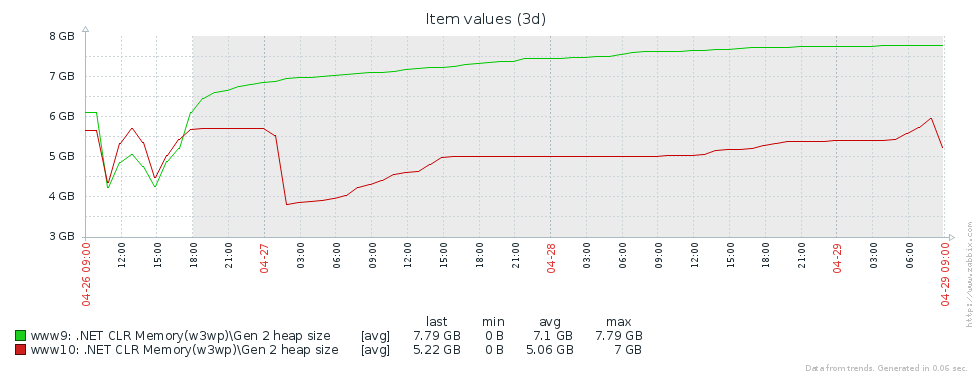
This means that there are no noticeable memory leaks, that is, a large number of 2nd generation assemblies occur for another reason. The next hypothesis is that there is a lot of memory traffic, i.e., many objects fall into the 2nd generation, and many objects die there. To find such objects in PerfView there is / GCOnly mode. From the trace reports, let's pay attention to the 'Gen 2 Object Deaths (Coarse Sampling) Stacks', which contains a selection of objects that die in the 2nd generation, along with call stacks of the places where these objects were created. Here we see the following results:
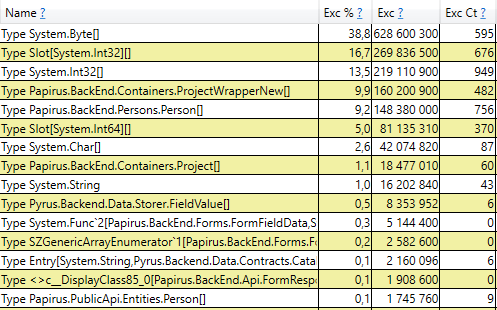
Having opened the line, inside we see the call stack of those places in the code that create objects that live up to the 2nd generation. Among them:
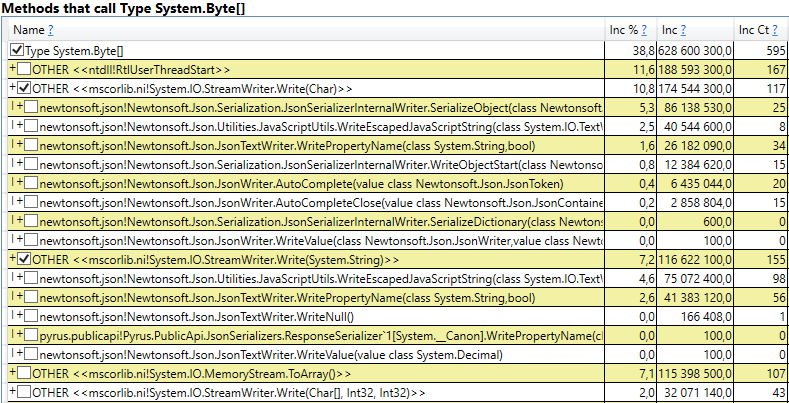

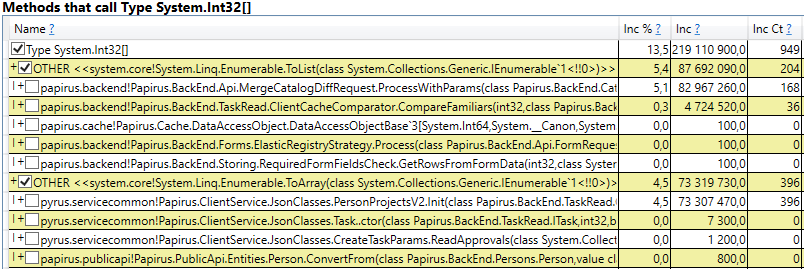
Interestingly, the buffers for JSON and for computing client caches are all temporary objects that live on the same request. Why do they live up to the 2nd generation? Note that all these objects are arrays of a rather large size. And at a size of> 85,000 bytes, the memory for them is allocated in the Large Object Heap, which is collected only together with the 2nd generation.
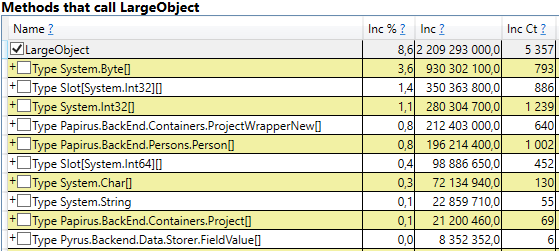
To check, open the section 'GC Heap Alloc Ignore Free (Coarse Sampling) stacks' in the perfview / GCOnly results. There we see the line LargeObject, in which PerfView groups the creation of large objects, and inside we see all the same arrays that we saw in the previous analysis. We acknowledge the root cause of the problems with the garbage collector: we create many temporary large objects.
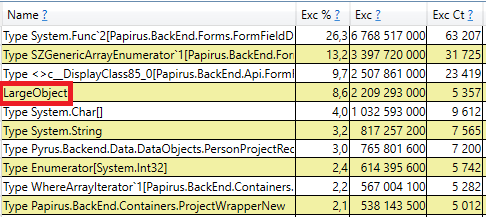
Based on the measurement results, we identified the main areas of further work: the fight against large objects when calculating client caches and serialization in JSON. There are several solutions to this problem:
Let us consider separately both cases of large objects - computing client caches and serializing in JSON.
The Pyrus web client and mobile applications cache the data available to the user (projects, forms, users, etc.) Caching is used to speed up work, it is also necessary for working in offline mode. Caches are computed on the server and transferred to the client. They are individual for each user, as they depend on their access rights, and are often updated, for example, when changing directories to which he has access.
Thus, a lot of client cache calculations are regularly performed on the server, and many temporary short-lived objects are created. If the user is a large organization, then he can get access to many objects, respectively, client caches for him will be large. That is why we saw the allocation of memory for large temporary arrays in the Large Object Heap.
Let us analyze the proposed options for getting rid of the creation of large objects:
We decided to go the 3rd way andinvent our bike to write List and HashSet, which do not load the Large Object Heap.
Our ChunkedList <T> implements standard interfaces, including IList <T>, which requires minimal changes to existing code. Yes, and the Newtonsoft.Json library we use is automatically able to serialize it, since it implements IEnumerable <T>:
The standard list <T> has the following fields: array for elements and the number of filled elements. In ChunkedList <T> there is an array of arrays of elements, the number of completely filled arrays, the number of elements in the last array. Each of the arrays of elements with less than 85,000 bytes:

Since the ChunkedList <T> is rather complicated, we wrote detailed tests on it. Any operation must be tested in at least 2 modes: in "small" when the whole list fits in one piece up to 85,000 bytes in size, and "large" when it consists of more than one piece. Moreover, for methods that change the size (for example, Add), the scenarios are even larger: “small” -> “small”, “small” -> “large”, “large” -> “large”, “large” -> “ little". Here there are quite a few confusing boundary cases that unit tests do well.
The situation is simplified by the fact that some of the methods from the IList interface are not used, and they can be omitted (such as Insert, Remove). Their implementation and testing would be quite overhead. In addition, writing unit tests is simplified by the fact that we do not need to come up with new functionality, ChunkedList <T> should behave the same as List <T>. That is, all tests are organized as follows: create a List <T> and ChunkedList <T>, carry out the same operations on them and compare the results.
We measured performance using the BenchmarkDotNet library to make sure that we do not slow down our code much when switching from List <T> to ChunkedList <T>. Let's test, for example, adding items to the list:
And the same test using List <T> for comparison. Results when adding 500 elements (everything fits in one array):
Results when adding 50,000 elements (split into several arrays):
If you look at the 'Mean' column, which displays the average test execution time, you can see that our implementation is slower than the standard by only 2-2.5 times. Considering that in the real code, operations with lists are only a small part of all the actions performed, this difference becomes insignificant. But the column 'Gen 2 / 1k op' (the number of assemblies of the 2nd generation for 1000 test runs) shows that we have achieved the goal: with a large number of elements, ChunkedList does not create garbage in the 2nd generation, which was our task.
Similarly, ChunkedHashSet <T> implements the ISet <T> interface. When writing the ChunkedHashSet <T>, we reused the small chunks logic already implemented in the ChunkedList. To do this, we took a ready-made implementation of HashSet <T> from the .NET Reference Source, available under the MIT license, and replaced arrays with ChunkedLists in it.
In unit tests, we also use the same trick as for lists: we will compare the behavior of ChunkedHashSet <T> with the reference HashSet <T>.
Finally, performance tests. The main operation that we use is the union of sets, which is why we are testing it:
And the exact same test for the standard HashSet. First test for small sets:
The second test for large sets that caused a problem with a bunch of large objects:
The results are similar to the listings. ChunkedHashSet is slower by 2-2.5 times, but at the same time on large sets it loads the 2nd generation 2 orders of magnitude less.
The Pyrus web server provides several APIs that use different serialization. We discovered the creation of large objects in the API used by bots and the synchronization utility (hereinafter referred to as the Public API). Note that basically the API uses its own serialization, which is not affected by this problem. We wrote about this in the article https://habr.com/en/post/227595/ , in the section “2. You don’t know where your application’s bottleneck is. ” That is, the main API is already working well, and the problem appeared in the Public API as the number of requests and the amount of data in the responses grew.
Let's optimize the Public API. Using the example of the main API, we know that you can return a response to the user in streaming mode. That is, you do not need to create intermediate buffers containing the entire response, but write the response immediately to the stream.
Upon closer inspection, we found out that in the process of serializing the response, we create a temporary buffer for the intermediate result ('content' is an array of bytes containing JSON in UTF-8 encoding):
Let’s see where content is used. For historical reasons, the Public API is based on WCF, for which XML is the standard request and response format. In our case, the XML response has a single 'Binary' element, inside which JSON encoded in Base64 is written:
Note that a temporary buffer is not needed here. JSON can be written immediately to the XmlWriter buffer that WCF provides us, encoding it in Base64 on the fly. Thus, we will go the first way, getting rid of memory allocation:
Here Base64Writer is a simple wrapper over XmlWriter that implements the Stream interface, which writes to XmlWriter as Base64. At the same time, from the entire interface, it is enough to implement only one Write method, which is called in StreamWriter:
Let's try to deal with mysterious induced garbage collections. We rechecked our code 10 times for GC.Collect calls, but this did not work. I managed to catch these events in PerfView, but the call stack is not very indicative (DotNETRuntime / GC / Triggered event):
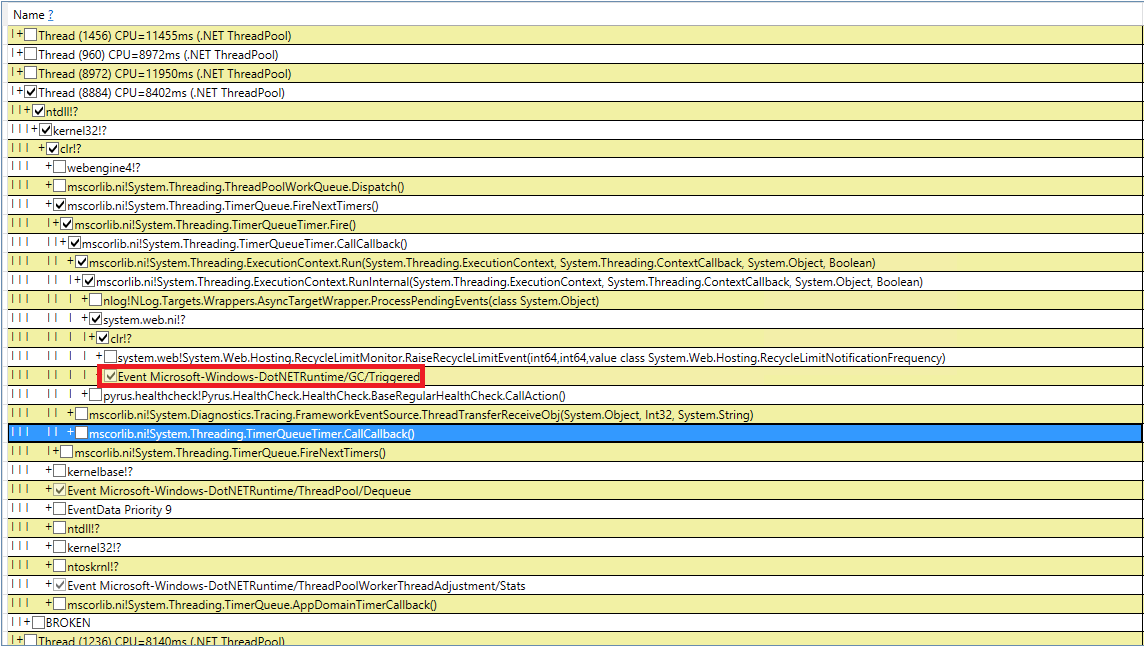
There is a small clue - calling RecycleLimitMonitor.RaiseRecycleLimitEvent before the induced garbage collection. Let's trace the stack of calls to the RaiseRecycleLimitEvent method:
The names of the methods correspond to their functions:
Further investigation shows that IObserver <RecycleLimitInfo> handlers are added in the RecycleLimitMonitor.Subscribe () method, which is called in the AspNetMemoryMonitor.Subscribe () method. Also, the default IObserver <RecycleLimitInfo> handler (the RecycleLimitObserver class) is hung in the AspNetMemoryMonitor class, which cleans ASP.NET caches and sometimes asks for garbage collection.
The riddle of the Induced GC is almost solved. It remains to find out the question of why this garbage collection is called. RecycleLimitMonitor monitors the use of IIS memory (more precisely, the number of private bytes), and when its use approaches a certain limit, it starts by a rather confusing algorithm to raise the RaiseRecycleLimitEvent event. The value of AspNetMemoryMonitor.ProcessPrivateBytesLimit is used as the memory limit, and in turn it contains the following logic:
The conclusion of the investigation is this: ASP.NET is nearing its memory limit and begins to regularly call garbage collection. The 'Private Memory Limit (KB)' was not set, so ASP.NET was limited to 60% of the physical memory. The problem was masked by the fact that on the Task Manager server it showed a lot of free memory and it seemed that it was enough. We have increased the 'Private Memory Limit (KB)' value in the Application Pool settings in IIS to 80% of the physical memory. This encourages ASP.NET to use more available memory. We also added monitoring of the performance counter '.NET CLR Memory / # Induced GC' so as not to miss the next time ASP.NET decides that it is approaching the memory usage limit.
Let's see what happened with the garbage collection after all these changes. Let's start with perfview / GCCollectOnly (trace time - 1 hour), GCStats report:
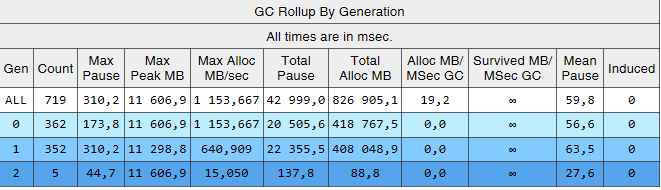
It can be seen that the 2nd generation assemblies are now 2 orders of magnitude smaller than the 0th and 1st. Also, the time of these assemblies decreased. Induced assemblies are no longer observed. Let's look at the list of assemblies of the 2nd generation:
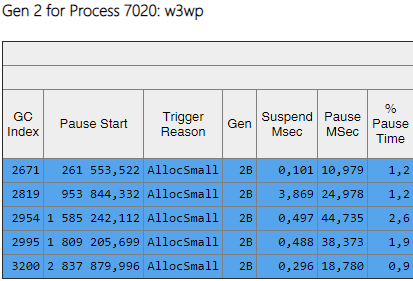
From the Gen column, it is clear that all assemblies of the 2nd generation have become background ('2B' means 2nd generation, Background). That is, most of the work is performed in parallel with the execution of the application, and all threads are blocked for a short time (column 'Pause MSec'). Let's look at the pauses when creating large objects:

It can be seen that the number of such pauses when creating large objects fell significantly.
Thanks to the changes described in the article, it was possible to significantly reduce the number and duration of assemblies of the 2nd generation. I managed to find the cause of the induced assemblies and get rid of them. The number of assemblies of the 0th and 1st generation increased, but their average duration decreased (from ~ 200 ms to ~ 60 ms). The maximum duration of assemblies of the 0th and 1st generation decreased, but not so noticeably. 2nd generation assemblies became faster, long pauses up to 1000ms are completely gone.
As for the key metric - “percentage of slow queries”, it decreased by 40% after all changes.
Thanks to our work, we realized what performance counters are needed to assess the situation with memory and garbage collection, adding them to Zabbix for continuous monitoring. Here is a list of the most important ones that we pay attention to and find out the reason (for example, an increased flow of requests, a large amount of transmitted data, a bug in the application):
Modern programming languages can be divided into two groups. In languages like C / C ++ or Rust, manual memory management is used, so programmers spend more time writing code, managing the lifetime of objects, and then debugging. At the same time, bugs due to improper use of memory are some of the most difficult to debug, so most modern development is conducted in languages with automatic memory management. These include, for example, Java, C #, Python, Ruby, Go, PHP, JavaScript, etc. Programmers save development time, but you have to pay extra runtime that the program regularly spends on garbage collection - freeing up memory occupied by objects to which there are no links left in the program. In small programs, this time is negligible,
Pyrus web servers run on the .NET platform, which uses automatic memory management. Most garbage collections are 'stop the world', i.e. at the time of their work stop all threads (threads) of the application. Non-blocking (background) assemblies actually stop all threads too, but for a very short period of time. During thread blocking, the server does not process requests, existing requests freeze, new ones are added to the queue. As a result, requests that were processed at the time of garbage collection are directly slowed down, and requests are processed more slowly immediately after garbage collection is completed due to accumulated queues. This worsens the metric "percentage of slow queries."
Armed with the recent Konrad Kokosa: Pro .NET Memory Management book (about how we brought its first copy to Russia in 2 days, you can write a separate post), which is entirely devoted to the topic of memory management in .NET, we began to study the problem.
Measurement
To profile the Pyrus web server, we used the PerfView utility ( https://github.com/Microsoft/perfview ), sharpened for profiling .NET applications. The utility is based on the Event Tracing for Windows (ETW) engine and has a minimal impact on the performance of the profiled application, which allows it to be used on a combat server. In addition, the impact on performance depends on what types of events and what information we collect. We do not collect anything - the application works as usual. PerfView also requires neither recompilation nor restarting the application.
Run the PerfView trace with the / GCCollectOnly switch (trace time 1.5 hours). In this mode, it only collects garbage collection events and has minimal impact on performance. Let's look at the Memory Group / GCStats trace report, and in it a summary of the garbage collector events:
Here we see several interesting indicators at once:
- The average build pause time in the 2nd generation is 700 milliseconds, and the maximum pause is about a second. This figure shows the time at which all threads in the .NET application stop, in particular, this pause will be added to all processed requests.
- The number of assemblies of the 2nd generation is comparable to the 1st generation and is slightly less than the number of assemblies of the 0th generation.
- The Induced column lists 53 assemblies in the 2nd generation. Induced assembly is the result of an explicit call to GC.Collect (). We did not find a single call to this method in our code, which means that some of the libraries used by our application is to blame.
Let us explain the observation about the number of garbage collections. The idea of dividing objects by their lifetime is based on the generational hypothesis): a significant part of the created objects dies quickly, and most of the rest live long (in other words, few objects that have an “average” lifetime). It is under this mode that the .NET garbage collector is imprisoned, and in this mode the second generation assemblies should be much smaller than the 0th generation. That is, for the optimal operation of the garbage collector, we must tailor the work of our application to the generational hypothesis. Let us formulate the rule as follows: objects must either die quickly, not living to the older generation, or to live to it and live there forever. This rule also applies to other platforms that use automatic memory management with generational separation, such as Java.
The data that is of interest to us can be extracted from another table in the GCStats report:
Here are some cases where an application tries to create a large object (in the .NET Framework objects> 85,000 bytes in size are created in the LOH - Large Object Heap), and it has to wait for the completion of the 2nd generation assembly, which takes place in parallel in the background. These pauses of the allocator are not as critical as the pauses of the garbage collector, since they affect only one thread. Before that, we used the .NET Framework version 4.6.1, and in version 4.7.1 Microsoft finalized the garbage collector, now it allows you to allocate memory in the Large Object Heap during the background generation of the 2nd generation: https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clr
Therefore, we updated to the latest version 4.7.2 at that time.
2nd Generation Builds
Why do we have so many builds of the older generation? The first assumption is that we have a memory leak. To test this hypothesis, let's look at the size of the second generation (we set up monitoring of the corresponding performance counters in Zabbix). From the graphs of the 2nd generation size for 2 Pyrus servers, it can be seen that its size first grows (mainly due to the filling of caches), but then stabilizes (large failures on the graph - regular restart of the web service to update the version):
This means that there are no noticeable memory leaks, that is, a large number of 2nd generation assemblies occur for another reason. The next hypothesis is that there is a lot of memory traffic, i.e., many objects fall into the 2nd generation, and many objects die there. To find such objects in PerfView there is / GCOnly mode. From the trace reports, let's pay attention to the 'Gen 2 Object Deaths (Coarse Sampling) Stacks', which contains a selection of objects that die in the 2nd generation, along with call stacks of the places where these objects were created. Here we see the following results:
Having opened the line, inside we see the call stack of those places in the code that create objects that live up to the 2nd generation. Among them:
- System.Byte [] If you look inside, we will see that more than half are buffers for serialization in JSON:
- Slot [System.Int32] [] (this is part of the HashSet implementation), System.Int32 [], etc. This is our code that calculates client caches - those directories, forms, lists, friends, etc. that this user sees and which are cached in his browser or mobile application:
Interestingly, the buffers for JSON and for computing client caches are all temporary objects that live on the same request. Why do they live up to the 2nd generation? Note that all these objects are arrays of a rather large size. And at a size of> 85,000 bytes, the memory for them is allocated in the Large Object Heap, which is collected only together with the 2nd generation.
To check, open the section 'GC Heap Alloc Ignore Free (Coarse Sampling) stacks' in the perfview / GCOnly results. There we see the line LargeObject, in which PerfView groups the creation of large objects, and inside we see all the same arrays that we saw in the previous analysis. We acknowledge the root cause of the problems with the garbage collector: we create many temporary large objects.
Changes in the Pyrus system
Based on the measurement results, we identified the main areas of further work: the fight against large objects when calculating client caches and serialization in JSON. There are several solutions to this problem:
- The simplest thing is not to create large objects. For example, if large buffer B is used in sequential data transformations A-> B-> C, then sometimes these transformations can be combined by turning them into A-> C and eliminating the creation of object B. This option is not always applicable, but it the simplest and most effective.
- Pool of objects. Instead of constantly creating new objects and throwing them away, loading the garbage collector, we can store a collection of free objects. In the simplest case, when we need a new object, we take it from the pool, or create a new one if the pool is empty. When we no longer need the object, we return it to the pool. A good example is ArrayPool in .NET Core, which is also available in the .NET Framework as part of the System.Buffers Nuget package.
- Use small objects instead of large ones.
Let us consider separately both cases of large objects - computing client caches and serializing in JSON.
Client Cache Calculation
The Pyrus web client and mobile applications cache the data available to the user (projects, forms, users, etc.) Caching is used to speed up work, it is also necessary for working in offline mode. Caches are computed on the server and transferred to the client. They are individual for each user, as they depend on their access rights, and are often updated, for example, when changing directories to which he has access.
Thus, a lot of client cache calculations are regularly performed on the server, and many temporary short-lived objects are created. If the user is a large organization, then he can get access to many objects, respectively, client caches for him will be large. That is why we saw the allocation of memory for large temporary arrays in the Large Object Heap.
Let us analyze the proposed options for getting rid of the creation of large objects:
- Complete disposal of large objects. This approach is not applicable, since data preparation algorithms use, among other things, sorting and union of sets, and they require temporary buffers.
- Using a pool of objects. This approach has difficulties:
- The variety of collections used and the types of elements in them: HashSet, List and Array are used (the latter 2 can be combined). Int32, Int64, as well as all kinds of data classes are stored in collections. For each type used, you will need your own pool, which will also store collections of different sizes.
- Difficult life time of collections. To take advantage of the pool, objects will have to be returned to it after use. This can be done if the object is used in one method. But in our case, the situation is more complicated, since many large objects travel between methods, are placed in data structures, are transferred to other structures, etc.
- Implementation. There is ArrayPool from Microsoft, but we still need List and HashSet. We did not find any suitable library, so we would have to implement the classes ourselves.
- The variety of collections used and the types of elements in them: HashSet, List and Array are used (the latter 2 can be combined). Int32, Int64, as well as all kinds of data classes are stored in collections. For each type used, you will need your own pool, which will also store collections of different sizes.
- Use of small objects. A large array can be divided into several small pieces, which I will not load the Large Object Heap, but will be created in the 0th generation, and then go along the standard path in the 1st and 2nd. We hope that they will not live up to the 2nd, but will be collected by the garbage collector in the 0th, or in extreme cases in the 1st generation. The advantage of this approach is that the changes to existing code are minimal. Difficulties:
- Implementation. We did not find any suitable libraries, so we would have to write the classes ourselves. The lack of libraries is understandable, since the scenario “collections that do not load Large Object Heap” is a very narrow scope.
We decided to go the 3rd way and
Piece list
Our ChunkedList <T> implements standard interfaces, including IList <T>, which requires minimal changes to existing code. Yes, and the Newtonsoft.Json library we use is automatically able to serialize it, since it implements IEnumerable <T>:
publicsealedclassChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T>
{The standard list <T> has the following fields: array for elements and the number of filled elements. In ChunkedList <T> there is an array of arrays of elements, the number of completely filled arrays, the number of elements in the last array. Each of the arrays of elements with less than 85,000 bytes:
private T[][] chunks;
privateint currentChunk;
privateint currentChunkSize;Since the ChunkedList <T> is rather complicated, we wrote detailed tests on it. Any operation must be tested in at least 2 modes: in "small" when the whole list fits in one piece up to 85,000 bytes in size, and "large" when it consists of more than one piece. Moreover, for methods that change the size (for example, Add), the scenarios are even larger: “small” -> “small”, “small” -> “large”, “large” -> “large”, “large” -> “ little". Here there are quite a few confusing boundary cases that unit tests do well.
The situation is simplified by the fact that some of the methods from the IList interface are not used, and they can be omitted (such as Insert, Remove). Their implementation and testing would be quite overhead. In addition, writing unit tests is simplified by the fact that we do not need to come up with new functionality, ChunkedList <T> should behave the same as List <T>. That is, all tests are organized as follows: create a List <T> and ChunkedList <T>, carry out the same operations on them and compare the results.
We measured performance using the BenchmarkDotNet library to make sure that we do not slow down our code much when switching from List <T> to ChunkedList <T>. Let's test, for example, adding items to the list:
[Benchmark]
public ChunkedList<int> ChunkedList()
{
var list = new ChunkedList<int>();
for (int i = 0; i < N; i++)
list.Add(i);
return list;
}And the same test using List <T> for comparison. Results when adding 500 elements (everything fits in one array):
| Method | Mean | Error | Stddev | Gen 0 / 1k Op | Gen 1 / 1k Op | Gen 2 / 1k Op | Allocated Memory / Op |
| Standardlist | 1.415 us | 0.0149 us | 0.0140 us | 0.6847 | 0.0095 | - | 4.21 KB |
| Chunkedlist | 3.728 us | 0.0238 us | 0.0222 us | 0.6943 | 0.0076 | - | 4.28 KB |
Results when adding 50,000 elements (split into several arrays):
| Method | Mean | Error | Stddev | Gen 0 / 1k Op | Gen 1 / 1k Op | Gen 2 / 1k Op | Allocated Memory / Op |
| Standardlist | 146.273 us | 3.1466 us | 4.8053 us | 124.7559 | 124.7559 | 124.7559 | 513.23 KB |
| Chunkedlist | 287.687 us | 1.4630 us | 1.2969 us | 41.5039 | 20.5078 | - | 256.75 KB |
Detailed description of columns in the results
BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5)
Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores
[Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0// * Hints *
Outliers
ListAdd.StandardList: Default -> 2 outliers were removed
ListAdd.ChunkedList: Default -> 1 outlier was removed
// * Legends *
Mean : Arithmetic mean of all measurements
Error : Half of 99.9% confidence interval
StdDev : Standard deviation of all measurements
Gen 0/1k Op : GC Generation 0 collects per 1k Operations
Gen 1/1k Op : GC Generation 1 collects per 1k Operations
Gen 2/1k Op : GC Generation 2 collects per 1k Operations
Allocated Memory/Op : Allocated memory per single operation (managed only, inclusive, 1KB = 1024B)
1 us : 1 Microsecond (0.000001 sec)If you look at the 'Mean' column, which displays the average test execution time, you can see that our implementation is slower than the standard by only 2-2.5 times. Considering that in the real code, operations with lists are only a small part of all the actions performed, this difference becomes insignificant. But the column 'Gen 2 / 1k op' (the number of assemblies of the 2nd generation for 1000 test runs) shows that we have achieved the goal: with a large number of elements, ChunkedList does not create garbage in the 2nd generation, which was our task.
Piece set
Similarly, ChunkedHashSet <T> implements the ISet <T> interface. When writing the ChunkedHashSet <T>, we reused the small chunks logic already implemented in the ChunkedList. To do this, we took a ready-made implementation of HashSet <T> from the .NET Reference Source, available under the MIT license, and replaced arrays with ChunkedLists in it.
In unit tests, we also use the same trick as for lists: we will compare the behavior of ChunkedHashSet <T> with the reference HashSet <T>.
Finally, performance tests. The main operation that we use is the union of sets, which is why we are testing it:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source)
{
varset = new ChunkedHashSet<int>();
foreach (var arr in source)
set.UnionWith(arr);
returnset;
}And the exact same test for the standard HashSet. First test for small sets:
var source = newint[][] {
Enumerable.Range(0, 300).ToArray(),
Enumerable.Range(100, 600).ToArray(),
Enumerable.Range(300, 1000).ToArray(),
}| Method | Mean | Error | Stddev | Gen 0 / 1k Op | Gen 1 / 1k Op | Gen 2 / 1k Op | Allocated Memory / Op |
| StandardHashSet | 30.16 us | 0.1046 us | 0.0979 us | 9.3079 | 1.6785 | - | 57.41 KB |
| ChunkedHashSet | 73.54 us | 0.5919 us | 0.5247 us | 9.5215 | 1.5869 | - | 58.84 KB |
The second test for large sets that caused a problem with a bunch of large objects:
var source = newint[][] {
Enumerable.Range(0, 30000).ToArray(),
Enumerable.Range(10000, 60000).ToArray(),
Enumerable.Range(30000, 100000).ToArray(),
}| Method | Mean | Error | Stddev | Gen 0 / 1k Op | Gen 1 / 1k Op | Gen 2 / 1k Op | Allocated Memory / Op |
| StandardHashSet | 3,031.30 us | 32.0797 us | 28.4378 us | 699.2188 | 667.9688 | 664.0625 | 4718.23 KB |
| ChunkedHashSet | 7,189.66 us | 25.6319 us | 23.9761 us | 539.0625 | 265.6250 | 7.8125 | 3280.71 KB |
The results are similar to the listings. ChunkedHashSet is slower by 2-2.5 times, but at the same time on large sets it loads the 2nd generation 2 orders of magnitude less.
Serialization in JSON
The Pyrus web server provides several APIs that use different serialization. We discovered the creation of large objects in the API used by bots and the synchronization utility (hereinafter referred to as the Public API). Note that basically the API uses its own serialization, which is not affected by this problem. We wrote about this in the article https://habr.com/en/post/227595/ , in the section “2. You don’t know where your application’s bottleneck is. ” That is, the main API is already working well, and the problem appeared in the Public API as the number of requests and the amount of data in the responses grew.
Let's optimize the Public API. Using the example of the main API, we know that you can return a response to the user in streaming mode. That is, you do not need to create intermediate buffers containing the entire response, but write the response immediately to the stream.
Upon closer inspection, we found out that in the process of serializing the response, we create a temporary buffer for the intermediate result ('content' is an array of bytes containing JSON in UTF-8 encoding):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...);
byte[] content;
var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false));
using (var writer = new Newtonsoft.Json.JsonTextWriter(sw))
{
serializer.Serialize(writer, result);
writer.Flush();
content = ms.ToArray();
}Let’s see where content is used. For historical reasons, the Public API is based on WCF, for which XML is the standard request and response format. In our case, the XML response has a single 'Binary' element, inside which JSON encoded in Base64 is written:
publicclassRawBodyWriter : BodyWriter
{
privatereadonlybyte[] _content;
publicRawBodyWriter(byte[] content)
: base(true)
{
_content = content;
}
protectedoverridevoidOnWriteBodyContents(XmlDictionaryWriter writer)
{
writer.WriteStartElement("Binary");
writer.WriteBase64(_content, 0, _content.Length);
writer.WriteEndElement();
}
}Note that a temporary buffer is not needed here. JSON can be written immediately to the XmlWriter buffer that WCF provides us, encoding it in Base64 on the fly. Thus, we will go the first way, getting rid of memory allocation:
protectedoverridevoidOnWriteBodyContents(XmlDictionaryWriter writer)
{
var serializer = Newtonsoft.Json.JsonSerializer.Create(...);
writer.WriteStartElement("Binary");
Stream stream = new Base64Writer(writer);
Var sw = new StreamWriter(stream, new UTF8Encoding(false));
using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw))
{
serializer.Serialize(jsonWriter, _result);
jsonWriter.Flush();
}
writer.WriteEndElement();
}Here Base64Writer is a simple wrapper over XmlWriter that implements the Stream interface, which writes to XmlWriter as Base64. At the same time, from the entire interface, it is enough to implement only one Write method, which is called in StreamWriter:
publicclassBase64Writer : Stream
{
privatereadonly XmlWriter _writer;
publicBase64Writer(XmlWriter writer)
{
_writer = writer;
}
publicoverridevoidWrite(byte[] buffer, int offset, int count)
{
_writer.WriteBase64(buffer, offset, count);
}
<...>
}Induced gc
Let's try to deal with mysterious induced garbage collections. We rechecked our code 10 times for GC.Collect calls, but this did not work. I managed to catch these events in PerfView, but the call stack is not very indicative (DotNETRuntime / GC / Triggered event):
There is a small clue - calling RecycleLimitMonitor.RaiseRecycleLimitEvent before the induced garbage collection. Let's trace the stack of calls to the RaiseRecycleLimitEvent method:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...)
RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...)
RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...)
RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)The names of the methods correspond to their functions:
- In the constructor of RecycleLimitMonitor.RecycleLimitMonitorSingleton, a timer is created that calls PBytesMonitorThread at a certain interval.
- PBytesMonitorThread collects statistics on memory usage and, under some conditions, calls CollectInfrequently.
- CollectInfrequently calls AlertProxyMonitors, gets a bool as a result, and calls GC.Collect () if it gets true. He also monitors the time elapsed since the last call to the garbage collector, and does not call it too often.
- AlertProxyMonitors goes through the list of running IIS web applications, for each raises the corresponding RecycleLimitMonitor object, and calls RaiseRecycleLimitEvent.
- RaiseRecycleLimitEvent raises the IObserver <RecycleLimitInfo> list. The handlers receive as a parameter RecycleLimitInfo, in which they can set the RequestGC flag, which returns to CollectInfrequently, causing an induced garbage collection.
Further investigation shows that IObserver <RecycleLimitInfo> handlers are added in the RecycleLimitMonitor.Subscribe () method, which is called in the AspNetMemoryMonitor.Subscribe () method. Also, the default IObserver <RecycleLimitInfo> handler (the RecycleLimitObserver class) is hung in the AspNetMemoryMonitor class, which cleans ASP.NET caches and sometimes asks for garbage collection.
The riddle of the Induced GC is almost solved. It remains to find out the question of why this garbage collection is called. RecycleLimitMonitor monitors the use of IIS memory (more precisely, the number of private bytes), and when its use approaches a certain limit, it starts by a rather confusing algorithm to raise the RaiseRecycleLimitEvent event. The value of AspNetMemoryMonitor.ProcessPrivateBytesLimit is used as the memory limit, and in turn it contains the following logic:
- If the Application Pool in IIS is set to 'Private Memory Limit (KB)', then the value in kilobytes is taken from there
- Otherwise, for 64-bit systems, 60% of physical memory is taken (for 32-bit systems, logic is more complicated).
The conclusion of the investigation is this: ASP.NET is nearing its memory limit and begins to regularly call garbage collection. The 'Private Memory Limit (KB)' was not set, so ASP.NET was limited to 60% of the physical memory. The problem was masked by the fact that on the Task Manager server it showed a lot of free memory and it seemed that it was enough. We have increased the 'Private Memory Limit (KB)' value in the Application Pool settings in IIS to 80% of the physical memory. This encourages ASP.NET to use more available memory. We also added monitoring of the performance counter '.NET CLR Memory / # Induced GC' so as not to miss the next time ASP.NET decides that it is approaching the memory usage limit.
Repeated measurements
Let's see what happened with the garbage collection after all these changes. Let's start with perfview / GCCollectOnly (trace time - 1 hour), GCStats report:
It can be seen that the 2nd generation assemblies are now 2 orders of magnitude smaller than the 0th and 1st. Also, the time of these assemblies decreased. Induced assemblies are no longer observed. Let's look at the list of assemblies of the 2nd generation:
From the Gen column, it is clear that all assemblies of the 2nd generation have become background ('2B' means 2nd generation, Background). That is, most of the work is performed in parallel with the execution of the application, and all threads are blocked for a short time (column 'Pause MSec'). Let's look at the pauses when creating large objects:
It can be seen that the number of such pauses when creating large objects fell significantly.
Summary
Thanks to the changes described in the article, it was possible to significantly reduce the number and duration of assemblies of the 2nd generation. I managed to find the cause of the induced assemblies and get rid of them. The number of assemblies of the 0th and 1st generation increased, but their average duration decreased (from ~ 200 ms to ~ 60 ms). The maximum duration of assemblies of the 0th and 1st generation decreased, but not so noticeably. 2nd generation assemblies became faster, long pauses up to 1000ms are completely gone.
As for the key metric - “percentage of slow queries”, it decreased by 40% after all changes.
Thanks to our work, we realized what performance counters are needed to assess the situation with memory and garbage collection, adding them to Zabbix for continuous monitoring. Here is a list of the most important ones that we pay attention to and find out the reason (for example, an increased flow of requests, a large amount of transmitted data, a bug in the application):
| Performance counter | Description | When to pay attention |
| \ Process (*) \ Private Bytes | The amount of memory allocated for the application | Values far exceed the threshold. As a threshold, you can take the median for 2 weeks from the maximum daily values. |
| \ .NET CLR Memory (*) \ # Gen 2 Collections | The amount of memory in the older generation | |
| \ .NET CLR Memory (*) \ Large Object Heap size | The amount of memory for large objects | |
| \ .NET CLR Memory (*) \% Time in GC | The percentage of time spent collecting garbage | The value is more than 5%. |
| \ .NET CLR Memory (*) \ # Induced GC | Number of induced assemblies | Value is greater than 0. |