How we develop # bigdataX5 and who is needed in Big Data
Our team in a short time went the distance from a dozen employees to an entire unit of almost 200 people and we want to share some milestones from this path. Plus, we will discuss who exactly is needed in big data right now and what is the real entry threshold.

Working with big data is a relatively new technological area, which, like everything, goes through the cycle of growing up as it develops.
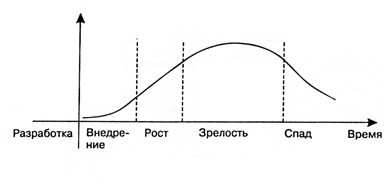
From the point of view of a particular specialist, work in the technological field at each stage of this cycle has its advantages and disadvantages.
Stage 1. Implementation
At the first stage, this is the brainchild of R&D units, which does not yet provide real profit.
From the pros: a lot of money is invested in it. Along with investments, hopes are growing for solving previously inaccessible tasks and returning investments.
Cons: any technology, no matter how promising it might look at the start, has its own limitations: it cannot be used to eliminate all existing problems. These limits are revealed as experiments with a new idea are carried out, which leads to a cooling of interest in technology after the so-called “peak of high expectations”.
Stage 2. Growth The
real take-off will be only for technology that will overcome the subsequent hollow of disappointments due to its real capabilities, and not marketing noise.
Pros: at this stage, the technology attracts long-term investments: not only money, but the time of specialists in the labor market. When it becomes clear that this is not just hype, but a new approach or even a market segment, it is time for specialists to integrate into the “trend”. This is an ideal moment for mastering promising technologies in terms of career take-off.
Cons: at this stage, the technology is still poorly documented.
Stage 3. Maturity
Mature technologies are real “workhorses” of the market.
Pros: as you grow older, the volume of accumulated documentation increases, trainings and courses appear, it becomes easier to enter the technology.
Cons: At the same time, competition in the labor market is growing.
Stage 4. Recession
The stage of decline (sunset) occurs in all technologies, although they continue to work.
Pros: at this point, the technology is already fully described, the boundaries are clear, a huge amount of documentation, courses are available.
Cons: from the point of view of acquiring new knowledge and prospects, it is no longer so attractive. In fact, this is an accompaniment.
The growth stage is the most attractive for everyone who wants to start working in a new technological field: both for young professionals and for already established professionals from related segments.
The development of big data is now just at this stage. High expectations remained behind. Business has already proven that big data can make a profit, and therefore there is a plateau of productivity ahead. This moment gives an excellent chance to specialists in the labor market.
Our story big data
The introduction of technology in any given company essentially repeats the general cycle of growing up. And our experience here is quite typical.
We started building our big data team in X5 a year and a half ago. Then it was only a small group of key specialists, and now there are almost 200 of us.
Our project teams went through several evolutionary stages, during which we got a deeper understanding of the roles and tasks. As a result, we have our own team format. We settled on the agile approach. The main idea is that the team had all the competencies to solve the problem, and how exactly they are distributed among the specialists is not so important. Based on this, the composition of the roles of teams was formed gradually, including taking into account the growth of technology. And now we have:

As we came to the dream team

Dream-not´dream, but, as I already said, the composition of the teams changed due to the maturity of big data analytics and its penetration into the daily life of X5 and our distribution networks.
“Quick start” - minimum roles, maximum speed.
The first team included only two roles:
Everything was quickly planned and manually implemented in the business.
“Do we think so?” - we learned to understand the business and produce the most useful result.
New roles have appeared for interacting with the business:
“Need more resources” - local computational tasks moved to the cluster and began to touch external systems.
To support scaling, it was required:
Now Data Analyst / Data Scientist could check several options for calculating the model on the cluster, although manual implementation in the business is still preserved.
“Loads continue to grow” - new data appears, new capacities are required to process them.
These changes could not be reflected in the command:
“Automation in everything” - the technology has taken root, it is time to automate the introduction of business.
At this stage, DevOps appeared in the team, who set up automatic assembly, testing and installation of functionality.
Key thoughts on team building
1. It’s not a fact that everything would have worked out if we hadn’t had the right specialists from whom we were able to build a team. This is the skeleton on which muscles began to grow.
2. The big data market is completely green, so there are not enough “ready-made” specialists for each of the roles. Of course, it would be very convenient to recruit a whole division of senior-s, but, obviously, such “star” teams cannot be built a lot. We decided not to chase only “ready-made” personnel. As we mentioned, adhering to agile, we should only care that the team as a whole has the competencies to solve a particular problem. In other words, we can take (and take) in one team professionals and beginners with a certain technical and mathematical base, so that together they form a set of competencies necessary to achieve the desired results.
3. Each of the roles implies an understanding of the principles of working with big data, requiring, however, its depth of this understanding. The greatest variability of roles that have direct analogies in the classical development - testers, analysts, etc. For them, there are tasks where belonging to big data is almost invisible, and tasks in which you need to dive a little deeper. One way or another, to start a career, a certain experience, an understanding of IT, a desire to learn and some theoretical knowledge about the tools used (which can be obtained by reading the articles) is enough.
4. Practice has shown that despite the fact that the technology is well-known and many would like to do it, not every specialist who would be suitable for starting a career in big data (and would like to work there at heart) really tries to come here .
Many excellent candidates believe that working in BigData teams is strictly Data Science. What is a cardinal change of activity with a high threshold of entry. However, they underestimate their competencies or simply do not know that people of various profiles are in demand in big data, and it would be easier to start a career in an alternative role - any of the above.
a. In fact, to start working in a mixed team on many roles, you do not need a narrow specialized education in the field of big data.
b. We actively expanded the team, adhering to the idea of building mixed structural units. And the most interesting thing is that people who came to our tasks, who had never before worked with big data, perfectly took root in the company, having coped with the tasks. They were able to quickly learn the practice of big data.
5. Without even having much experience, you can dive deeper, learn the necessary languages and tools, being motivated to grow in this segment in order to deal with more strategic tasks within the project. And the accumulated experience helps to switch to those roles where knowledge is required in big data and understanding the logic of this direction. By the way, in this sense, a mixed team helps a lot to accelerate development.
In our case, the idea of balanced teams of specialists of different levels “took off” - the group has already implemented more than one internal project. It seems to me that with a shortage of ready-made personnel and an increase in the business need for such teams, other companies will come to the same scenario.
If you seriously want to choose this direction, immersing yourself in Data Sciense - Kaggle, ODS and other specialized resources will help you. Moreover, if in the near future you do not see yourself in the role of Data Scientist, but you are interested in the direction in itself, you are still needed in Big Data!
To increase your value:
PS By the way, right now we are continuing to grow actively and are looking for a data engineer , testing specialist , React developer , and UI / UX specialist . On May 10-11, we will discuss including work in # bigdatax5 with everyone at our booth at DataFest .
Recipe for Success in a New Field
Working with big data is a relatively new technological area, which, like everything, goes through the cycle of growing up as it develops.
From the point of view of a particular specialist, work in the technological field at each stage of this cycle has its advantages and disadvantages.
Stage 1. Implementation
At the first stage, this is the brainchild of R&D units, which does not yet provide real profit.
From the pros: a lot of money is invested in it. Along with investments, hopes are growing for solving previously inaccessible tasks and returning investments.
Cons: any technology, no matter how promising it might look at the start, has its own limitations: it cannot be used to eliminate all existing problems. These limits are revealed as experiments with a new idea are carried out, which leads to a cooling of interest in technology after the so-called “peak of high expectations”.
Stage 2. Growth The
real take-off will be only for technology that will overcome the subsequent hollow of disappointments due to its real capabilities, and not marketing noise.
Pros: at this stage, the technology attracts long-term investments: not only money, but the time of specialists in the labor market. When it becomes clear that this is not just hype, but a new approach or even a market segment, it is time for specialists to integrate into the “trend”. This is an ideal moment for mastering promising technologies in terms of career take-off.
Cons: at this stage, the technology is still poorly documented.
Stage 3. Maturity
Mature technologies are real “workhorses” of the market.
Pros: as you grow older, the volume of accumulated documentation increases, trainings and courses appear, it becomes easier to enter the technology.
Cons: At the same time, competition in the labor market is growing.
Stage 4. Recession
The stage of decline (sunset) occurs in all technologies, although they continue to work.
Pros: at this point, the technology is already fully described, the boundaries are clear, a huge amount of documentation, courses are available.
Cons: from the point of view of acquiring new knowledge and prospects, it is no longer so attractive. In fact, this is an accompaniment.
The growth stage is the most attractive for everyone who wants to start working in a new technological field: both for young professionals and for already established professionals from related segments.
The development of big data is now just at this stage. High expectations remained behind. Business has already proven that big data can make a profit, and therefore there is a plateau of productivity ahead. This moment gives an excellent chance to specialists in the labor market.
Our story big data
The introduction of technology in any given company essentially repeats the general cycle of growing up. And our experience here is quite typical.
We started building our big data team in X5 a year and a half ago. Then it was only a small group of key specialists, and now there are almost 200 of us.
Our project teams went through several evolutionary stages, during which we got a deeper understanding of the roles and tasks. As a result, we have our own team format. We settled on the agile approach. The main idea is that the team had all the competencies to solve the problem, and how exactly they are distributed among the specialists is not so important. Based on this, the composition of the roles of teams was formed gradually, including taking into account the growth of technology. And now we have:
- Product Owner (product owner) - has an understanding of the subject area, formulates a general business idea and predicts how it can be monetized.
- Business Analyst (business analyst) - is working on this task.
- Data quality (data quality specialist) - checks if existing data can be used to solve the problem.
- Directly Data Science / Data Analyst (data scientist / data analyst) - builds mathematical models (there are different subspecies, including those that work only with spreadsheets).
- Test Managers.
- Developers
In our case, the infrastructure and data are used by all teams, and the following roles are implemented for teams as services: - Infrastructure
- ETL (data loading command).
As we came to the dream team
Dream-not´dream, but, as I already said, the composition of the teams changed due to the maturity of big data analytics and its penetration into the daily life of X5 and our distribution networks.
“Quick start” - minimum roles, maximum speed.
The first team included only two roles:
- Product Owner proposed a model, made recommendations.
- Data Analyst - collected statistics based on existing data.
Everything was quickly planned and manually implemented in the business.
“Do we think so?” - we learned to understand the business and produce the most useful result.
New roles have appeared for interacting with the business:
- Business Analyst - Described process requirements.
- Data Quality - conducted a check for data consistency.
- Depending on the task, Data Analyst / Data Scientist analyzed data statistics / performed model calculation on the local workstation.
“Need more resources” - local computational tasks moved to the cluster and began to touch external systems.
To support scaling, it was required:
- The infrastructure that raised the HADOOP server.
- Developers - they implemented integration with external IT systems, and they checked the user interfaces at this stage themselves.
Now Data Analyst / Data Scientist could check several options for calculating the model on the cluster, although manual implementation in the business is still preserved.
“Loads continue to grow” - new data appears, new capacities are required to process them.
These changes could not be reflected in the command:
- Infrastructure developed the HADOOP cluster under growing loads.
- The ETL team began regular data downloads and updates.
- Functional testing has appeared.
“Automation in everything” - the technology has taken root, it is time to automate the introduction of business.
At this stage, DevOps appeared in the team, who set up automatic assembly, testing and installation of functionality.
Key thoughts on team building
1. It’s not a fact that everything would have worked out if we hadn’t had the right specialists from whom we were able to build a team. This is the skeleton on which muscles began to grow.
2. The big data market is completely green, so there are not enough “ready-made” specialists for each of the roles. Of course, it would be very convenient to recruit a whole division of senior-s, but, obviously, such “star” teams cannot be built a lot. We decided not to chase only “ready-made” personnel. As we mentioned, adhering to agile, we should only care that the team as a whole has the competencies to solve a particular problem. In other words, we can take (and take) in one team professionals and beginners with a certain technical and mathematical base, so that together they form a set of competencies necessary to achieve the desired results.
3. Each of the roles implies an understanding of the principles of working with big data, requiring, however, its depth of this understanding. The greatest variability of roles that have direct analogies in the classical development - testers, analysts, etc. For them, there are tasks where belonging to big data is almost invisible, and tasks in which you need to dive a little deeper. One way or another, to start a career, a certain experience, an understanding of IT, a desire to learn and some theoretical knowledge about the tools used (which can be obtained by reading the articles) is enough.
4. Practice has shown that despite the fact that the technology is well-known and many would like to do it, not every specialist who would be suitable for starting a career in big data (and would like to work there at heart) really tries to come here .
Many excellent candidates believe that working in BigData teams is strictly Data Science. What is a cardinal change of activity with a high threshold of entry. However, they underestimate their competencies or simply do not know that people of various profiles are in demand in big data, and it would be easier to start a career in an alternative role - any of the above.
a. In fact, to start working in a mixed team on many roles, you do not need a narrow specialized education in the field of big data.
b. We actively expanded the team, adhering to the idea of building mixed structural units. And the most interesting thing is that people who came to our tasks, who had never before worked with big data, perfectly took root in the company, having coped with the tasks. They were able to quickly learn the practice of big data.
5. Without even having much experience, you can dive deeper, learn the necessary languages and tools, being motivated to grow in this segment in order to deal with more strategic tasks within the project. And the accumulated experience helps to switch to those roles where knowledge is required in big data and understanding the logic of this direction. By the way, in this sense, a mixed team helps a lot to accelerate development.
How to get into BigData?
In our case, the idea of balanced teams of specialists of different levels “took off” - the group has already implemented more than one internal project. It seems to me that with a shortage of ready-made personnel and an increase in the business need for such teams, other companies will come to the same scenario.
If you seriously want to choose this direction, immersing yourself in Data Sciense - Kaggle, ODS and other specialized resources will help you. Moreover, if in the near future you do not see yourself in the role of Data Scientist, but you are interested in the direction in itself, you are still needed in Big Data!
To increase your value:
- update your math knowledge. To solve ordinary problems of big data, a doctorate is not required, but basic knowledge in higher mathematics is still needed. Understanding the mechanisms underlying the statistics, it will be easier for you to be aware of the processes;
- Choose the roles that are closest to your current specialty. Find out what challenges you will face in this role (and in a particular company, where you want to go). And if you have solved similar problems before, they should be emphasized in the resume;
- tools specific to the selected role are very important, even if it seems that this is not relevant to big data. For example, when developing our internal solution, it turned out that we need a lot of front-end developers who work with complex interfaces;
- remember that the market is actively developing. Someone is building and pumping teams inside, while someone expects to find ready-made specialists in the labor market. If you are a beginner, try to get into a strong team, where there will be an opportunity to gain additional knowledge.
PS By the way, right now we are continuing to grow actively and are looking for a data engineer , testing specialist , React developer , and UI / UX specialist . On May 10-11, we will discuss including work in # bigdatax5 with everyone at our booth at DataFest .