[Translation] Envoy threading model
Hello, Habr! I present to you the translation of the article “Envoy threading model” by Matt Klein.
This article seemed quite interesting to me, and since Envoy is most often used as part of “istio” or simply as “ingress controller” kubernetes, therefore most people do not have the same direct interaction with it as for example with typical Nginx or Haproxy installations. However, if something breaks, it would be good to understand how it works from the inside. I tried to translate as much text as possible into Russian, including special words, for those who are painful to look at this, I left the originals in brackets. Welcome to cat.
The low-level technical documentation on the Envoy code base is currently quite scarce. To fix this, I plan to make a series of blog articles about the various Envoy subsystems. Since this is the first article, please let me know what you think and what you might be interested in in the following articles.
One of the most common technical questions I get about Envoy is a request for a low-level description of the threading model used. In this post, I will describe how Envoy maps connections to threads, as well as a description of the Thread Local Storage system, which is used internally to make the code more parallel and high-performance.
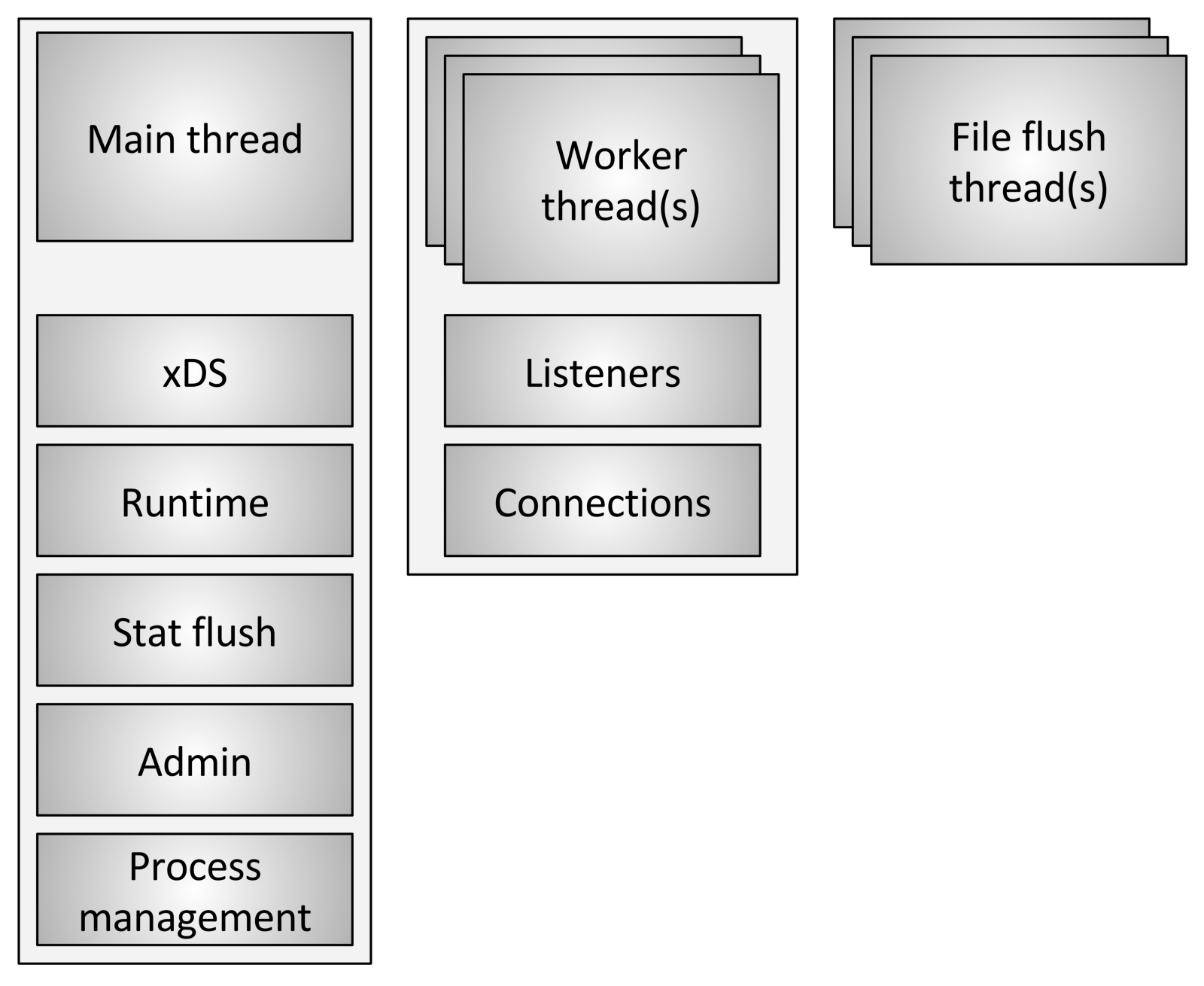
Envoy uses three different types of streams:
As discussed briefly above, all workflows listen to all listeners without any segmentation. Thus, the kernel is used to correctly send received sockets to worker threads. Modern kernels in general are very good at this, they use features such as increasing the priority of input-output (IO), to try to fill the thread with work, before starting to use other threads that also listen on the same socket, and also do not use circular lock (Spinlock) to handle each request.
Once a connection is accepted on a worker thread, it never leaves this thread. All further connection processing is fully processed in the worker thread, including any forwarding behavior.
This has several important consequences:
The term "non-blocking" has so far been used several times in discussing how the main and worker threads work. All code is written provided that nothing is ever blocked. However, this is not entirely true (which is not entirely true?).
Envoy uses several lengthy process locks:
Due to the way in which Envoy separates main thread responsibilities from workflow responsibilities, there is a requirement that complex processing can be performed on the main thread and then provided to each workflow with a high degree of concurrency. This section describes the Envoy Thread Local Storage (TLS) system at a high level. In the next section, I will describe how it is used to manage the cluster.

As already described, the main thread processes almost all the management functions and the functionality of the control plane in the Envoy process. The management plane is a bit overloaded here, but if you look at it within the Envoy process itself and compare it with the forwarding that workflows perform, this seems appropriate. As a general rule, the main thread process does some work, and then it needs to update each worker thread in accordance with the result of this work, while the worker thread does not need to set a lock on every access .
The TLS (Thread local storage) Envoy system works as follows:
Although this is a very simple and incredibly powerful paradigm, it is very similar to the concept of RCU blocking (Read-Copy-Update). In essence, workflows never see any data changes in the TLS slots at run time. Change only occurs during the rest period between work events.
Envoy uses this in two different ways:
In this section, I will describe how TLS (Thread local storage) is used to manage a cluster. Cluster management includes xDS and / or DNS API processing, as well as health checking.
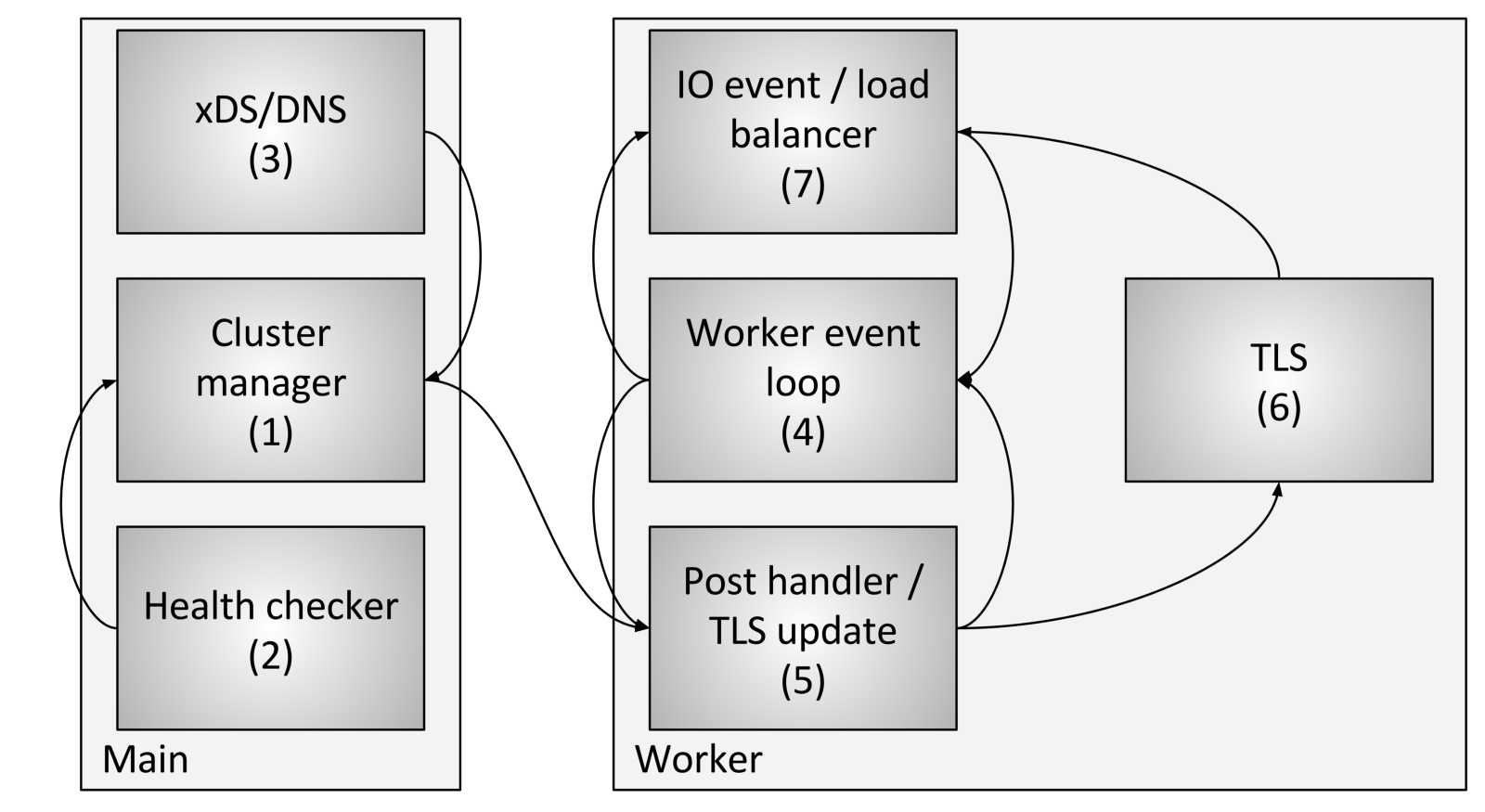
Cluster flow management includes the following components and steps:
Using the above procedure, Envoy can process each request without any locks (other than those described previously). Besides the complexity of the TLS code itself, most of the code does not need to understand how multithreading works, and it can be written in single-threaded mode. This makes it easier to write most of the code in addition to superior performance.
TLS (Thread local storage) and RCU (Read Copy Update) are widely used in Envoy.
Examples of using:
There are other cases, but previous examples should provide a good understanding of what TLS is used for.
Although Envoy works pretty well overall, there are a few well-known areas that need attention when it is used with very high concurrency and bandwidth:
The Envoy threading model is designed to provide ease of programming and massive concurrency through potentially wasteful use of memory and connections if they are not configured correctly. This model allows it to work very well with a very high number of threads and throughput.
As I briefly mentioned on Twitter, a design can also run on top of a fully featured network stack in user mode, such as the DPDK (Data Plane Development Kit), which can cause regular servers to process millions of requests per second with full L7 processing. It will be very interesting to see what will be built in the next few years.
One last quick comment: I have been asked many times why we chose C ++ for Envoy. The reason, as before, is that it is still the only widely spoken industrial-level language on which to build the architecture described in this post. C ++ is definitely not suitable for all or even for many projects, but for certain use cases it is still the only tool to get the job done (to get the job done).
Links to files with interfaces and header implementations discussed in this post:
This article seemed quite interesting to me, and since Envoy is most often used as part of “istio” or simply as “ingress controller” kubernetes, therefore most people do not have the same direct interaction with it as for example with typical Nginx or Haproxy installations. However, if something breaks, it would be good to understand how it works from the inside. I tried to translate as much text as possible into Russian, including special words, for those who are painful to look at this, I left the originals in brackets. Welcome to cat.
The low-level technical documentation on the Envoy code base is currently quite scarce. To fix this, I plan to make a series of blog articles about the various Envoy subsystems. Since this is the first article, please let me know what you think and what you might be interested in in the following articles.
One of the most common technical questions I get about Envoy is a request for a low-level description of the threading model used. In this post, I will describe how Envoy maps connections to threads, as well as a description of the Thread Local Storage system, which is used internally to make the code more parallel and high-performance.
Threading overview
Envoy uses three different types of streams:
- Main: This thread controls the start and end of the process, all processing of the XDS (xDiscovery Service) API, including DNS, health checking, general cluster management and service process (runtime), statistics reset, administration and general management processes - Linux signals, hot restart, etc. Everything that happens in this thread is asynchronous and non-blocking. In general, the main thread coordinates all critical processes of functionality, which do not require a large number of CPUs to complete. This allows most of the control code to be written as if it were single-threaded.
- Worker: By default, Envoy creates a worker thread for each hardware thread in the system, this can be controlled using the option
--concurrency. Each worker thread starts an “non-blocking” event loop, which is responsible for listening to each listener, at the time of writing (July 29, 2017) there is no sharding of the listener, receiving new ones connections, creating an instance of the filter stack to connect, and processing all the I / O operations over the lifetime of the connection. Again, this allows most of the connection processing code to be written as if it were single-threaded. - File flusher: Each file that Envoy writes, mainly access logs, currently has an independent blocking stream. This is due to the fact that writing to files cached by the file system, even when used
O_NONBLOCK, can sometimes be blocked (sigh). When worker threads need to write to a file, the data is actually moved to a buffer in memory, where it is eventually flushed through the file flush stream . This is one area of code where technically all worker threads can block the same lock while trying to fill the memory buffer.
Connection handling
As discussed briefly above, all workflows listen to all listeners without any segmentation. Thus, the kernel is used to correctly send received sockets to worker threads. Modern kernels in general are very good at this, they use features such as increasing the priority of input-output (IO), to try to fill the thread with work, before starting to use other threads that also listen on the same socket, and also do not use circular lock (Spinlock) to handle each request.
Once a connection is accepted on a worker thread, it never leaves this thread. All further connection processing is fully processed in the worker thread, including any forwarding behavior.
This has several important consequences:
- All connection pools in Envoy are in a workflow. Thus, although HTTP / 2 connection pools make only one connection to each upstream host at a time, if there are four worker threads, there will be four HTTP / 2 connections to the upstream host in a steady state.
- The reason Envoy works this way is that by storing everything in one workflow, almost all of the code can be written without blocking and as if it were single-threaded. This design makes writing a lot of code easier and scales incredibly well for an almost unlimited number of workflows.
- However, one of the main conclusions is that from the point of view of memory pool and connection efficiency, it is actually very important to configure the parameter
--concurrency. Having more worker threads than necessary will lead to memory loss, creating more inactive connections and slowing down the speed of getting into the connection pool. At Lyft, our envoy sidecar containers work with very low concurrency, so the performance is roughly equivalent to the services they sit next to. We run Envoy as an edge proxy (edge) only with maximum concurrency.
What does non-blocking means?
The term "non-blocking" has so far been used several times in discussing how the main and worker threads work. All code is written provided that nothing is ever blocked. However, this is not entirely true (which is not entirely true?).
Envoy uses several lengthy process locks:
- As already mentioned, when writing access logs, all worker threads get the same lock before filling the log buffer in memory. The lock hold time should be very low, but it is possible that this lock will be challenged with high concurrency and high throughput.
- Envoy uses a very sophisticated system for processing statistics that is local to the stream. This will be the topic of a separate post. However, I will briefly mention that as part of the local processing of flow statistics, it is sometimes required to obtain a lock for the central “statistics store”. This lock should not ever be required.
- The main thread periodically needs coordination with all workflows. This is done by “publishing” from the main thread to the worker threads, and sometimes from the worker threads back to the main thread. For sending, blocking is required so that the published message can be queued for subsequent delivery. These locks should never be subjected to serious competition, but they can still be technically blocked.
- When Envoy writes a log to the system error stream (standard error), it receives a lock on the entire process. In general, Envoy's local logging is considered terrible in terms of performance, so there is not much attention paid to its improvement.
- There are several other random locks, but none of them are performance critical and should never be disputed.
Thread local storage
Due to the way in which Envoy separates main thread responsibilities from workflow responsibilities, there is a requirement that complex processing can be performed on the main thread and then provided to each workflow with a high degree of concurrency. This section describes the Envoy Thread Local Storage (TLS) system at a high level. In the next section, I will describe how it is used to manage the cluster.
As already described, the main thread processes almost all the management functions and the functionality of the control plane in the Envoy process. The management plane is a bit overloaded here, but if you look at it within the Envoy process itself and compare it with the forwarding that workflows perform, this seems appropriate. As a general rule, the main thread process does some work, and then it needs to update each worker thread in accordance with the result of this work, while the worker thread does not need to set a lock on every access .
The TLS (Thread local storage) Envoy system works as follows:
- Code running in the main thread can allocate a TLS slot for the entire process. Although this is abstracted, in practice it is an index in a vector that provides O (1) access.
- The main stream can set arbitrary data in its slot. When this is done, the data is published in each workflow as a regular event loop event.
- Worker threads can read from their TLS slot and retrieve any local thread data available there.
Although this is a very simple and incredibly powerful paradigm, it is very similar to the concept of RCU blocking (Read-Copy-Update). In essence, workflows never see any data changes in the TLS slots at run time. Change only occurs during the rest period between work events.
Envoy uses this in two different ways:
- By storing various data on each workflow, access to this data is carried out without any blocking.
- By storing a global pointer to global data in read-only mode on each worker thread. Thus, each workflow has a data reference counter, which cannot be reduced during the execution of the work. Only when all workers calm down and upload new shared data will the old data be destroyed. It is identical to RCU.
Cluster update threading
In this section, I will describe how TLS (Thread local storage) is used to manage a cluster. Cluster management includes xDS and / or DNS API processing, as well as health checking.
Cluster flow management includes the following components and steps:
- Cluster Manager is a component within Envoy that manages all known cluster upstream, CDS (Cluster Discovery Service) APIs, SDS (Secret Discovery Service) and EDS (Endpoint Discovery Service) APIs, DNS and active external checks health (health checking). He is responsible for creating an “ultimately consistent” representation of each upstream cluster that includes the discovered hosts, as well as the health status.
- The health checker performs an active health check and reports on changes in the health state to the cluster manager.
- CDS (Cluster Discovery Service) / SDS (Secret Discovery Service) / EDS (Endpoint Discovery Service) / DNS are performed to determine cluster membership. The state change is returned to the cluster manager.
- Each worker thread continuously runs an event loop.
- When the cluster manager determines that the state for the cluster has changed, it creates a new read-only cluster snapshot and sends it to each worker thread.
- During the next dormant period, the workflow will update the snapshot in the dedicated TLS slot.
- During an I / O event that the host should determine for load balancing, the load balancer will request a TLS slot (Thread local storage) to obtain host information. No locks are required for this. Note also that TLS can also trigger events during an upgrade, so load balancers and other components can recount caches, data structures, etc. This is beyond the scope of this post, but is used in various places in the code.
Using the above procedure, Envoy can process each request without any locks (other than those described previously). Besides the complexity of the TLS code itself, most of the code does not need to understand how multithreading works, and it can be written in single-threaded mode. This makes it easier to write most of the code in addition to superior performance.
Other subsystems that make use of TLS
TLS (Thread local storage) and RCU (Read Copy Update) are widely used in Envoy.
Examples of using:
- The mechanism of changing functionality during execution: The current list of enabled functionality is calculated in the main thread. Each workflow is then provided with a read-only snapshot using RCU semantics.
- Replacing route tables : for route tables provided by RDS (Route Discovery Service), route tables are created in the main thread. A read-only snapshot will later be provided to each workflow using RCU semantics (Read Copy Update). This makes modifying route tables atomically efficient.
- HTTP Header Caching: As it turns out, calculating the HTTP header for each request (when executing ~ 25K + RPS per core) is quite expensive. Envoy centrally calculates the header approximately every half second and provides it to every employee through TLS and RCU.
There are other cases, but previous examples should provide a good understanding of what TLS is used for.
Known performance pitfalls
Although Envoy works pretty well overall, there are a few well-known areas that need attention when it is used with very high concurrency and bandwidth:
- As already described in this article, currently all worker threads receive a lock when they write to the access log memory buffer. With high concurrency and high throughput, it will be necessary to package access logs for each workflow due to unordered delivery when writing to the final file. Alternatively, you can create a separate access log for each workflow.
- Although the statistics are very optimized, with very high concurrency and throughput, there will probably be atomic competition on individual statistics. The solution to this problem is counters per worker thread with periodic resetting of the central counters. This will be discussed in a subsequent post.
- The existing architecture will not work well if Envoy is deployed in a scenario in which there are very few connections that require significant processing resources. There is no guarantee that communications will be evenly distributed between workflows. This can be solved by balancing work connections, in which the ability to exchange connections between work flows will be realized.
Conclusion
The Envoy threading model is designed to provide ease of programming and massive concurrency through potentially wasteful use of memory and connections if they are not configured correctly. This model allows it to work very well with a very high number of threads and throughput.
As I briefly mentioned on Twitter, a design can also run on top of a fully featured network stack in user mode, such as the DPDK (Data Plane Development Kit), which can cause regular servers to process millions of requests per second with full L7 processing. It will be very interesting to see what will be built in the next few years.
One last quick comment: I have been asked many times why we chose C ++ for Envoy. The reason, as before, is that it is still the only widely spoken industrial-level language on which to build the architecture described in this post. C ++ is definitely not suitable for all or even for many projects, but for certain use cases it is still the only tool to get the job done (to get the job done).
Links to code
Links to files with interfaces and header implementations discussed in this post:
- github.com/lyft/envoy/blob/master/include/envoy/thread_local/thread_local.h
- github.com/lyft/envoy/blob/master/source/common/thread_local/thread_local_impl.h
- github.com/lyft/envoy/blob/master/include/envoy/upstream/cluster_manager.h
- github.com/lyft/envoy/blob/master/source/common/upstream/cluster_manager_impl.h